これは、JavaScript で Elasticsearch を使用する方法を説明するシリーズの最初の記事です。このシリーズでは、JavaScript 環境で Elasticsearch を使用する方法の基本を学習し、検索アプリを作成するための最も関連性の高い機能とベスト プラクティスを確認します。最後には、JavaScript を使用して Elasticsearch を実行するために必要なすべてのことを理解できるようになります。
この最初の部分では、次の点を確認します。
ここで 例付きのソースコードを確認できます 。
Elasticsearch Node.js クライアントとは何ですか?
Elasticsearch Node.js クライアントは、Elasticsearch API からの HTTP REST 呼び出しを JavaScript に配置する JavaScript ライブラリです。これにより、処理が容易になり、ドキュメントのインデックス作成などのタスクを一括で簡素化するヘルパーが利用できるようになります。
環境
フロントエンド、バックエンド、それともサーバーレス?
JavaScript クライアントを使用して検索アプリを作成するには、Elasticsearch クラスターとクライアントを実行する JavaScript ランタイムという少なくとも 2 つのコンポーネントが必要です。
JavaScript クライアントはすべての Elasticsearch ソリューション (クラウド、オンプレミス、サーバーレス) をサポートしており、クライアントがすべてのバリエーションを内部で処理するため、ソリューション間に大きな違いはありません。そのため、どれを使用するかについて心配する必要はありません。
ただし、JavaScript ランタイムはブラウザから直接ではなく、サーバーから実行する必要があります。
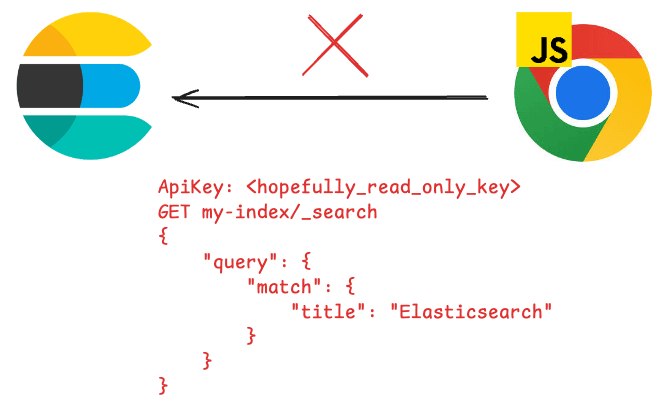
これは、ブラウザから Elasticsearch を呼び出すと、ユーザーがクラスター API キー、ホスト、クエリ自体などの機密情報を取得する可能性があるためです。Elasticsearch では、クラスターをインターネットに直接公開せず、このすべての情報を抽象化する中間層を使用して、ユーザーがパラメータのみを確認できるようにすることを推奨しています。このトピックの詳細については、ここ をご覧ください。
次のようなスキーマを使用することをお勧めします。

この場合、クライアントは検索用語とサーバーの認証キーのみを送信し、サーバーはクエリと Elasticsearch との通信を完全に制御します。
クライアントの接続
まず、次の手順に従って API キーを作成します。
前の例に従って、シンプルな Express サーバーを作成し、Node.JS サーバーからのクライアントを使用してそのサーバーに接続します。
NPM を使用してプロジェクトを初期化し、Elasticsearch クライアントとExpress をインストールします。後者は、Node.js でサーバーを起動するためのライブラリです。Express を使用すると、HTTP 経由でバックエンドと対話できます。
プロジェクトを初期化しましょう:
npm init -y
依存関係をインストールします:
npm install @elastic/elasticsearch express split2 dotenv
詳しく説明しましょう:
- @elastic/elasticsearch : 公式Node.jsクライアントです
- express : 軽量なNode.jsサーバーを立ち上げてElasticsearchを公開できるようになります
- split2 : テキスト行をストリームに分割します。ndjsonファイルを1行ずつ処理するのに便利です
- dotenv : .env を使用して環境変数を管理できるようにしますファイル
.envを作成するプロジェクトのルートにあるファイルを作成し、次の行を追加します。
この方法では、 dotenvパッケージを使用してこれらの変数をインポートできます。
server.jsファイルを作成します:
このコードは、ポート 3000 をリッスンし、認証用の API キーを使用して Elasticsearch クラスターに接続する基本的な Express.js サーバーをセットアップします。これには、GET リクエストを介してアクセスすると、Elasticsearch クライアントの.info()メソッドを使用して Elasticsearch クラスターに基本情報を照会する /ping エンドポイントが含まれています。
クエリが成功した場合は、クラスター情報が JSON 形式で返され、それ以外の場合はエラー メッセージが返されます。サーバーは、JSON リクエスト本体を処理するために body-parser ミドルウェアも使用します。
ファイルを実行してサーバーを起動します。
node server.js
答えは次のようになるはずです:
それでは、エンドポイント/pingを参照して、Elasticsearch クラスターのステータスを確認しましょう。
文書のインデックス作成
接続すると、セマンティック検索用のsemantic_textやフルテキストクエリ用の text などのマッピングを使用してドキュメントのインデックスを作成できます。これら 2 つのフィールド タイプを使用すると、ハイブリッド検索も実行できます。
マッピングを生成し、ドキュメントをアップロードするために、新しいload.jsファイルを作成します。
Elasticsearchクライアント
まずクライアントをインスタンス化して認証する必要があります。
セマンティックマッピング
動物病院に関するデータを含むインデックスを作成します。飼い主様、ペット様、訪問の詳細に関する情報を保存します。
名前や説明など、全文検索を実行するデータはテキストとして保存されます。動物の種や品種などのカテゴリのデータは、キーワードとして保存されます。
さらに、すべてのフィールドの値を semantic_text フィールドにコピーして、その情報に対してもセマンティック検索を実行できるようにします。
バルクヘルパー
クライアントのもう 1 つの利点は、一括ヘルパーを使用してインデックスを一括で作成できることです。バルク ヘルパーを使用すると、同時実行、再試行、関数を通過して成功または失敗した各ドキュメントの処理などを簡単に処理できます。
このヘルパーの魅力的な機能は、ストリームを操作できることです。この機能を使用すると、ファイル全体をメモリに保存して Elasticsearch に一度に送信するのではなく、ファイルを 1 行ずつ送信できます。
Elasticsearch にデータをアップロードするには、プロジェクトのルートに data.ndjson というファイルを作成し、以下の情報を追加します (または、ここからデータセットを含むファイルをダウンロードすることもできます)。
バルク ヘルパーがファイル行を Elasticsearch に送信する間、split2 を使用してファイル行をストリーミングします。
上記のコードは.ndjsonを読み取りますファイルを 1 行ずつ読み込み、 helpers.bulkメソッドを使用して各 JSON オブジェクトを指定された Elasticsearch インデックスに一括インデックスします。createReadStreamとsplit2を使用してファイルをストリーミングし、各ドキュメントのインデックス メタデータを設定し、処理に失敗したドキュメントをログに記録します。完了すると、正常にインデックスが作成されたアイテムの数を記録します。
indexData関数を使用する代わりに、Kibana を使用して UI 経由でファイルを直接アップロードし、データ ファイルのアップロード UI を使用することもできます。
ファイルを実行して、ドキュメントを Elasticsearch クラスターにアップロードします。
node load.js
Elasticsearchでのデータ検索
server.jsファイルに戻って、語彙検索、セマンティック検索、ハイブリッド検索を実行するためのさまざまなエンドポイントを作成します。
簡単に言えば、これらのタイプの検索は相互に排他的ではありませんが、回答する必要がある質問の種類によって異なります。
| クエリタイプ | 使用事例 | 例題 |
|---|---|---|
| 語彙クエリ | 質問内の単語または語根は、索引文書に表示される可能性があります。質問とドキュメント間のトークンの類似性。 | 青いスポーツTシャツを探しています。 |
| セマンティッククエリ | 質問内の単語は文書には表示されない可能性があります。質問とドキュメント間の概念的な類似性。 | 寒い季節用の服を探しています。 |
| ハイブリッド検索 | 質問には語彙や意味の要素が含まれています。質問とドキュメント間のトークンと意味の類似性。 | ビーチでの結婚式用にSサイズのドレスを探しています。 |
質問の語彙部分はタイトルや説明、またはカテゴリ名の一部である可能性が高く、意味部分はそれらの分野に関連する概念です。青はおそらくカテゴリ名または説明の一部であり、ビーチウェディングはそうではないかもしれませんが、意味的にはリネンの衣服に関連している可能性があります。
語彙クエリ (/search/lexic?q=<query_term>)
語彙検索 (フルテキスト検索とも呼ばれる) とは、トークンの類似性に基づいて検索することを意味します。つまり、分析後、検索内のトークンを含むドキュメントが返されます。
語彙検索の実践チュートリアルは、こちらでご覧いただけます。
爪切りでテストする
答え:
セマンティッククエリ (/search/semantic?q=<query_term>)
セマンティック検索は、語彙検索とは異なり、ベクトル検索を通じて検索用語の意味に類似した結果を見つけます。
セマンティック検索の実践チュートリアルは、こちらでご覧いただけます。
テスト対象:誰がペディキュアをしましたか?
答え:
ハイブリッド クエリ (/search/hybrid?q=<query_term>)
ハイブリッド検索により、セマンティック検索と語彙検索を組み合わせることができるため、両方の長所を活用できます。つまり、トークンによる検索の精度と、セマンティック検索の意味の近似性の両方が得られます。
「ペディキュアや歯科治療を受けた人はいますか?」という質問をしてテストします。
対応:
まとめ
このシリーズの最初の部分では、クライアント/サーバーのベストプラクティスに従って、環境を設定し、さまざまな検索エンドポイントを持つサーバーを作成し、Elasticsearch ドキュメントをクエリする方法を説明しました。シリーズのパート 2では、本番環境のベスト プラクティスと、サーバーレス環境で Elasticsearch Node.js クライアントを実行する方法について学習します。
よくあるご質問
Node.js クライアントとは何ですか?
Node.jsクライアントは、Elasticsearch APIからのHTTP REST呼び出しをJavaScriptに変換するJavaScriptライブラリです。バッチで文書をインデキシングする作業を簡素化してくれるヘルパーが使いやすくなります。
フロントエンドからElasticsearchを呼び出す代わりに、サーバー側のNode.js環境を使用する必要があるのはなぜですか?
Securityが主な利点です。クライアントをバックエンド環境(Node.js with Expressなど)で実行することで、Cluster APIキー、ホストURL、内部クエリロジックなどの機密情報がブラウザに露出することを防止します。
Node.jsでElasticsearchの「Bulk Helper」を使う利点は何ですか?
Node.jsでElasticsearchの「Bulk Helper」を使用する主な利点は以下の通りです。 バッチインデキシング:文書を一つずつではなくグループでインデキシングする際の複雑さを自動的に処理します。 ストリームのサポート:split2のようなツールを使うと、ファイル(.ndjsonなど)を一行ずつストリーミングできます。これにより、サーバーのメモリにデータセット全体をロードすることなく、大規模なファイルを処理できます。
関連記事

2025年11月14日
Azure AKS Automatic に Elasticsearch をデプロイする方法
部分的に管理された Elasticsearch セットアップ構成のために、AKS Automatic と ECK を使用して Azure に Kibana とともに Elasticsearch をデプロイする方法を学習します。

2025年11月11日
Elasticsearch で構造化ドキュメントの再帰チャンクを構成する
チャンク サイズ、セパレーター グループ、カスタム セパレーター リストを使用して Elasticsearch で再帰チャンクを設定し、構造化ドキュメントのインデックスを最適に作成する方法を学びます。

Kibana に Elasticsearch クエリルール UI を導入
Elasticsearch クエリ ルール UI を使用して、オーガニック ランキングに影響を与えずに Kibana のカスタマイズ可能なルールセットを使用して検索クエリにドキュメントを追加または除外する方法を学びます。

2025年10月3日
AWS MarketplaceでElasticsearchをデプロイする方法
このステップバイステップガイドでは、AWSマーケットプレイスでElastic Cloudサービスを使用してElasticsearchをセットアップし、実行する方法を学びます。
