Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Elasticsearch as a vector database offers comprehensive quantization techniques like Better Binary Quantization (BBQ). BBQ and other similarly modern quantization techniques compress vectors down to as little as a single bit per dimension, reducing memory use while retaining impressively accurate distance approximation. For vectors generated from deep learning models, such as Cohere models, this works really well; however, for other kinds of vectors, such as image data or histogram features, recall can be impacted heavily. Preconditioning fixes this by applying a random orthogonal rotation to your vectors before quantization, redistributing variance evenly across dimensions so every bit captures meaningful signal, in some cases improving recall by almost 75%.
Here, we’ll provide some intuition about the problem and how preconditioning solves it.
The problem
BBQ quantizes each dimension of a vector independently: Values above the mean become 1, values below it become 0. This works well when every dimension carries roughly the same amount of information. Transformer-based embeddings tend to have this property naturally such that their dimensions are learned representations that distribute variance evenly.
But there are lots of real-world vectors that aren’t like this. Consider a 784-dimension vector representing a grayscale image, like in the Fashion-MNIST dataset. Some pixels near the center of the image, where the clothing actually appears, vary a lot across the dataset. However, other pixels, such as those near the corners, are mostly one color and barely vary at all. When BBQ quantizes these vectors, the high-variance dimensions lose precision because a single bit can't capture their range, while the low-variance dimensions become useless. The resulting quantized vectors are poor approximations of the originals, and recall suffers.

Picture of a representation of Fashion-MNIST images. (credit: geeksforgeeks.org)
Precondition
To fix the problem, we want to spread the information more evenly across dimensions so that each bit captures roughly the same amount of information.
Preconditioning applies a linear transformation to every vector before quantization. The transformation is an orthogonal rotation that reshuffles how information is distributed across dimensions without changing the distances between vectors. If you want to dig into the math, take a look at this in-depth analysis on optimized scalar quantization (OSQ) with preconditioners.
Here’s a graphic to help illustrate how preconditioning can help when applying quantization. This simplified two-dimensional diagram illustrates the idea that the orthogonal rotation helps to increase the spread, or range, of information that was previously quite compressed. While this two-dimensional animation is not an exact representation of preconditioning, it gives a good intuition for what roughly happens in higher dimensions where buckets of dimensions are transformed independently and a random projection can greatly improve the distribution. Imagine that the y-axis represents one pixel of our Fashion-MNIST corners that are primarily one shade with very low variance and the x-axis represents a pixel of clothing at the center of the image with very high variance. Without preconditioning, quantizing vectors to a single representative point is not a particularly good discriminator.

Let’s look at the data
Today, preconditioning is supported in DiskBBQ. Here’s a benchmark showing the impact when visiting different percentages of the total vector dataset.
Fashion-MNIST Recall (784 dimensions, 60K docs, 5x oversample, k: 10)
| Vectors visited | Baseline recall | Preconditioned recall | % Improvement |
|---|---|---|---|
| 0.5% | 0.45 | 0.77 | 71% |
| 3% | 0.49 | 0.77 | 57% |
| 5% | 0.50 | 0.87 | 74% |
| 10% | 0.55 | 0.91 | 65% |
GIST (960 dimensions, 1M docs, 5x oversample, k: 10)
| Vectors visited | Baseline recall | Preconditioned recall | % Improvement |
|---|---|---|---|
| 0.1% | 0.49 | 0.69 | 41% |
| 0.2% | 0.70 | 0.77 | 10% |
| 0.3% | 0.73 | 0.85 | 16% |
| 0.5% | 0.78 | 0.88 | 13% |
SIFT (128 dimensions, 1M documents, 5x oversample, k: 10)
| Vectors visited | Baseline recall | Preconditioned recall | % Improvement |
|---|---|---|---|
| 0.5% | 0.48 | 0.60 | 25% |
| 1% | 0.59 | 0.71 | 20% |
| 3% | 0.71 | 0.87 | 23% |
| 7% | 0.72 | 0.90 | 25% |
That’s a nice boost in recall; however, this boost comes with a cost. Applying it to all embeddings blindly is inefficient, causing ~2–4% overhead in query latencies with no improvement in recall for datasets that don’t need to be preconditioned. And upwards of 20% additional overhead at index time. For production use cases where you see initially low recall, you may want to evaluate the impact of preconditioning with your specific model and dataset.
Here’s the how
Preconditioning is available for the bbq_disk index type. Simply set precondition to true in the index_options, like so:
Take a look at the dense vector mapping docs for more details.
Conclusion
BBQ is highly effective for deep learning embeddings, but it can be less effective with embeddings that have uneven variance across dimensions, as can occur in feature-engineered vectors. Preconditioning redistributes that variance so quantization can be more effective. On some datasets, like Fashion-MNIST, we see as much as a 74% improvement in recall!
For now, we’ve made preconditioning optional. Hopefully, you feel more capable of knowing when it may be beneficial so you try it out yourself. In the future, we plan to iterate on performance and automatically detect when to apply preconditioning.
関連記事

2026年6月24日
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

2026年6月18日
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.
2026年6月16日
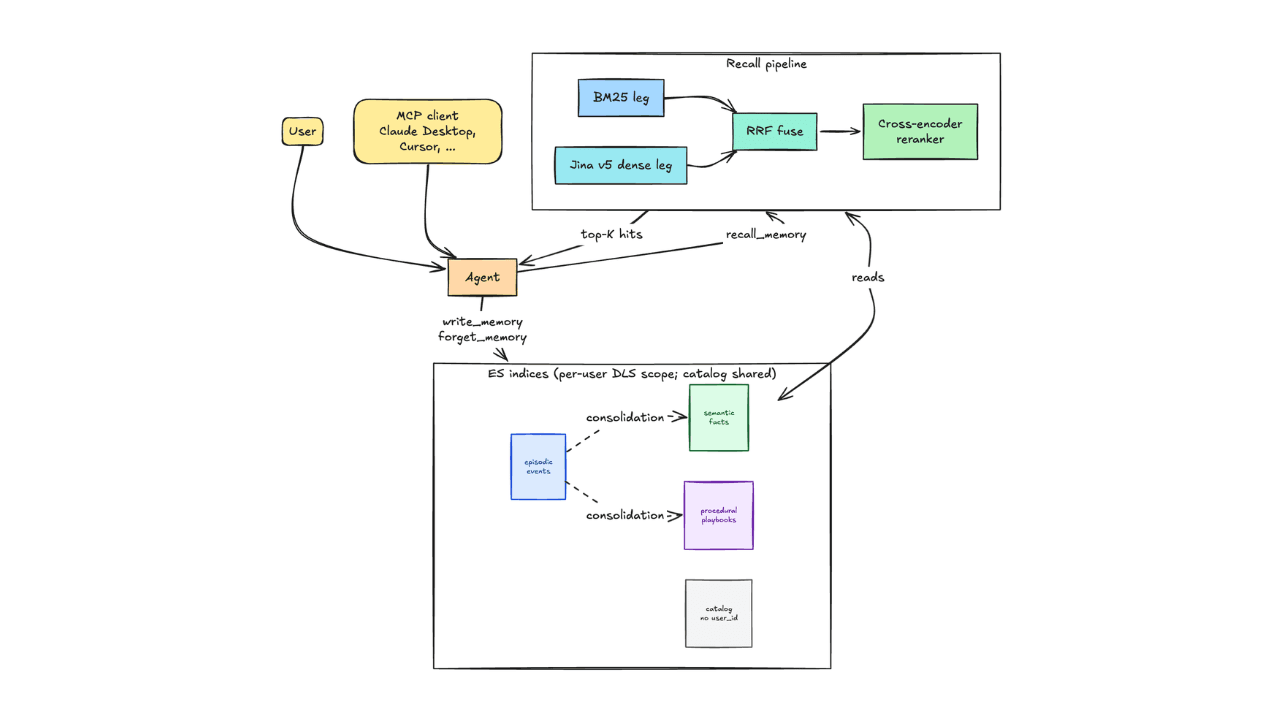
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.

2026年6月11日
How Elasticsearch cut metrics storage by 41% by dropping sequence numbers after replication
Find out how Elasticsearch trims sequence numbers at merge time to cut TSDS storage by 41%, what you give up, and why it's safe for metrics workloads.
2026年6月10日
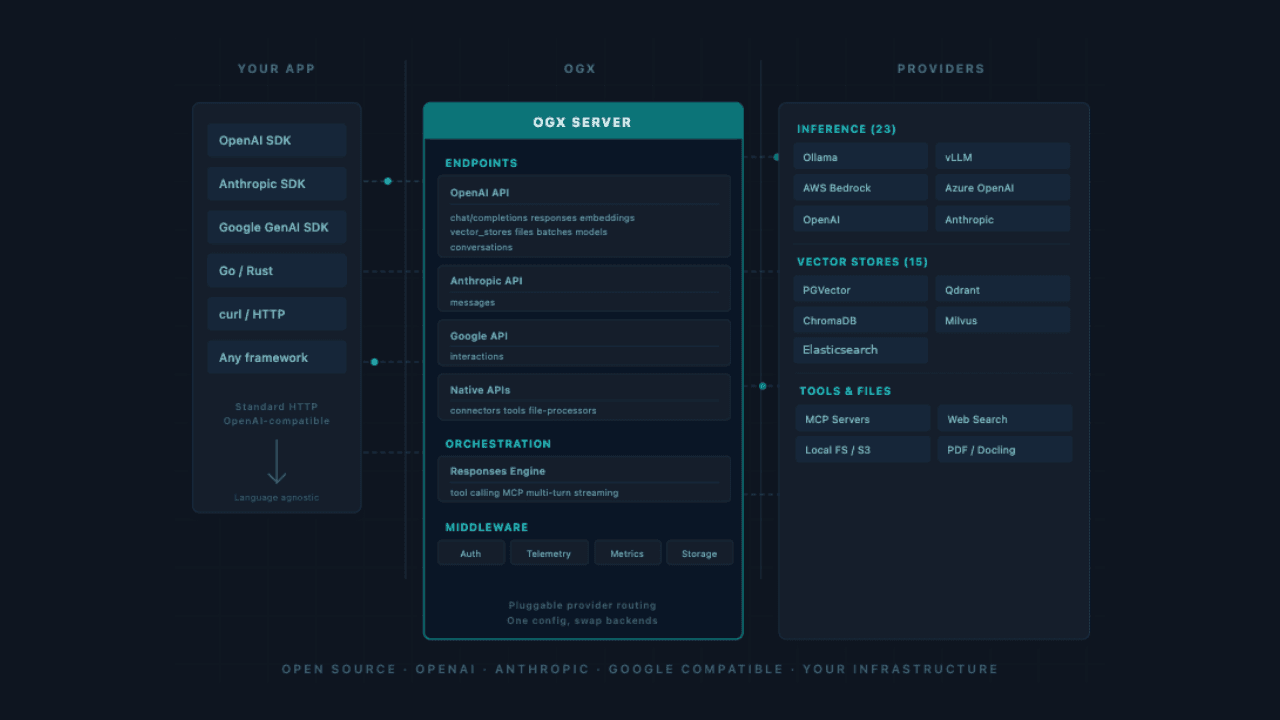
Your AI agent reads the fine print: building a RAG pipeline over EU regulations with Elasticsearch and OGX
Learn how to configure Elasticsearch as an OGX vector store, ingest EU regulation PDFs and build a Python RAG agent that runs hybrid BM25 and vector search with source-level citations.