LLM が情報検索の基本的なプロセスをどのように変えてきたかについての (かなり広範囲にわたる)背景を踏まえて、LLM がデータのクエリ方法をどのように変えてきたかを見てみましょう。
データと対話する新しい方法
ジェネレーティブ (genAI) AI とエージェント AI は、従来の検索とは異なる処理を行います。かつて私たちが情報を調べ始める方法は検索(「グーグルで検索してみます…」)でしたが、gen AI とエージェントの両方にとって、開始アクションは通常、チャット インターフェースに入力された自然言語を通じて行われます。チャット インターフェースは、意味理解を使用して質問を簡潔な回答、つまりあらゆる種類の情報に関する幅広い知識を持つ予言者から出されたような要約された応答に変換する LLM とのディスカッションです。本当に売れているのは、LLM が表面化した知識の断片をつなぎ合わせて首尾一貫した思慮深い文章を生成する能力です。たとえそれが不正確であったり完全に幻覚的であったりしても、そこには真実味があります。
私たちが使い慣れている古い検索バーは、私たち自身が推論エージェントであったときに使用した RAG エンジンと考えることができます。現在では、インターネット検索エンジンでさえ、使い古された「ハント・アンド・ペック」という語彙検索エクスペリエンスを、クエリに対する結果の要約で答える AI 主導の概要へと変えつつあり、ユーザーがクリックして個々の結果を自分で評価する必要がないようにしています。
生成AIとRAG
生成 AI は、世界の意味理解を活用してチャット リクエストを通じて表明された主観的な意図を解析し、推論能力を使用して専門的な回答を即座に作成します。生成 AI インタラクションにはいくつかの部分があります。ユーザーの入力/クエリから始まり、チャット セッションでの以前の会話が追加のコンテキストとして使用でき、LLM に推論方法と応答の構築手順を指示する指示プロンプトがあります。プロンプトは、「5 歳児に説明するように説明してください」という単純なタイプのガイダンスから、リクエストを処理する方法の完全な詳細へと進化しました。これらの内訳には、AI のペルソナ/役割、生成前の推論/内部思考プロセス、客観的な基準、制約、出力形式、対象者、および期待される結果を示すのに役立つ例の詳細を説明する個別のセクションが含まれることがよくあります。
ユーザーのクエリとシステム プロンプトに加えて、検索拡張生成 (RAG) は、「コンテキスト ウィンドウ」と呼ばれる追加のコンテキスト情報を提供します。RAG はアーキテクチャへの重要な追加機能であり、世界の意味理解において欠落している部分を LLM に通知するために使用します。
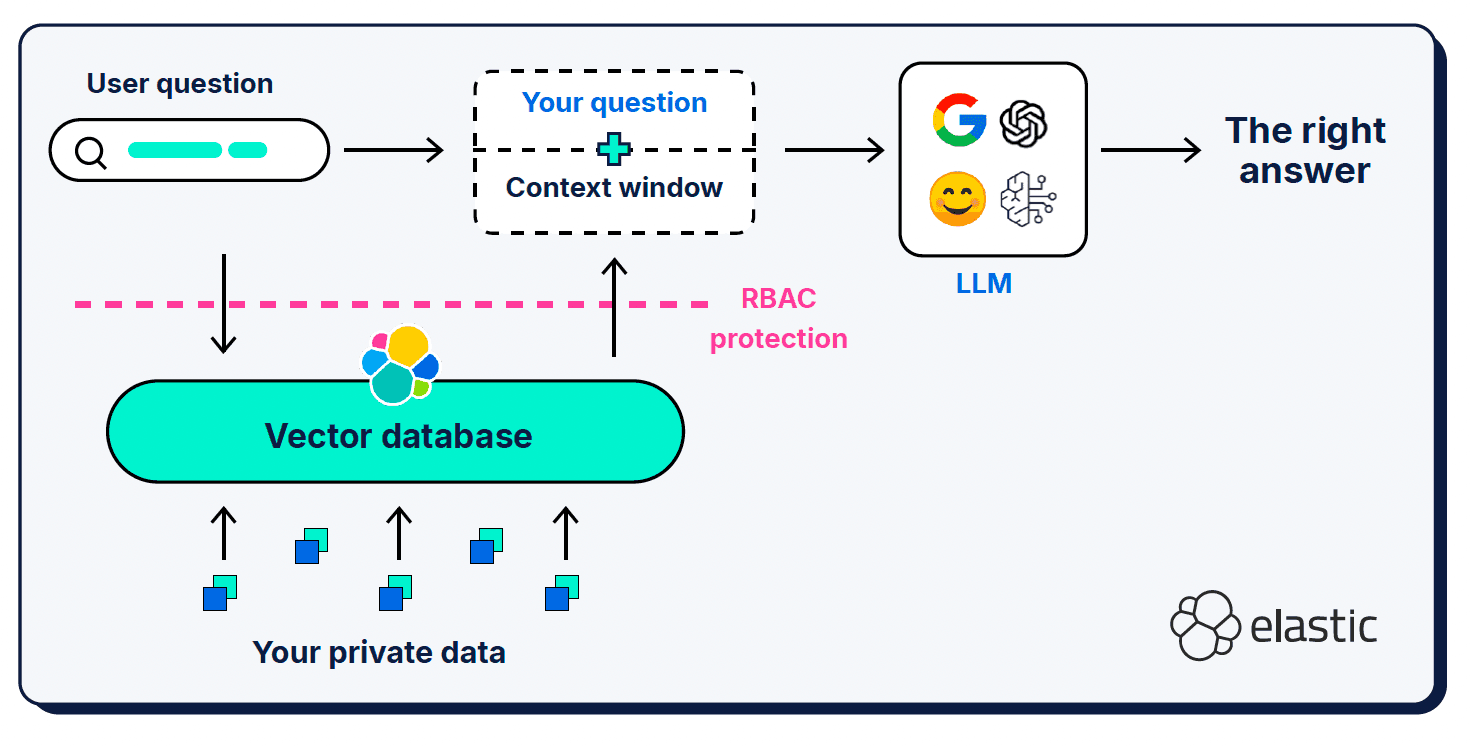
コンテキスト ウィンドウは、何を、どこに、どれだけ与えるかという点では、かなり細かい指定が必要になる場合があります。もちろん、どのコンテキストが選択されるかは非常に重要ですが、提供されたコンテキストの信号対雑音比やウィンドウの長さも重要です。
情報が少なすぎる
クエリ、プロンプト、またはコンテキスト ウィンドウに提供される情報が少なすぎると、LLM が応答を生成するための正しいセマンティック コンテキストを正確に判断できないため、幻覚が発生する可能性があります。また、ドキュメント チャンク サイズのベクトル類似性にも問題があります。つまり、短くて単純な質問は、ベクトル化された知識ベースにある豊富で詳細なドキュメントと意味的に一致しない可能性があります。Hypothetical Document Embeddings (HyDE)などのクエリ拡張手法が開発され、LLM を使用して、短いクエリよりも豊富で表現力豊かな仮説的な回答を生成します。もちろん、ここでの危険は、仮説文書自体が LLM を正しい文脈からさらに逸脱させる幻覚であるということです。
情報が多すぎる
私たち人間と同じように、コンテキスト ウィンドウに情報が多すぎると、LLM は重要な部分が何であるのかについて混乱し、圧倒されてしまう可能性があります。コンテキスト オーバーフロー (または「コンテキスト ロット」) は、生成 AI 操作の品質とパフォーマンスに影響します。LLM の「注意予算」(作業メモリ) に大きな影響を与え、競合する多くのトークン間の関連性を薄めます。「コンテキスト腐敗」の概念には、LLM が位置の偏りを持つ傾向があるという観察も含まれます。つまり、LLM はコンテキスト ウィンドウの中央セクションのコンテンツよりも、コンテキスト ウィンドウの先頭または末尾のコンテンツを優先します。
気が散ったり矛盾したりする情報
コンテキスト ウィンドウが大きくなるほど、LLM が正しいコンテキストを選択して処理する妨げとなる余分な情報や矛盾した情報が含まれる可能性が高くなります。ある意味、これは「ガベージ イン/ガベージ アウト」の問題になります。つまり、ドキュメント結果セットをコンテキスト ウィンドウにダンプするだけで、LLM に処理すべき大量の情報が提供されます (多すぎる可能性があります)。ただし、コンテキストの選択方法によっては、矛盾した情報や無関係な情報が入り込む可能性が高くなります。
エージェント型AI
カバーすべき内容がたくさんあると言いましたが、ついにエージェント AI のトピックについて話すことができました。エージェント AI は、LLM チャット インターフェイスの非常にエキサイティングな新しい使用法であり、独自の知識とユーザーが提供するコンテキスト情報に基づいて応答を合成する生成 AI (すでに「レガシー」と呼んでもいいでしょうか?) の機能を拡張します。生成 AI が成熟するにつれて、当初は人間が簡単に確認/検証できる、面倒でリスクの低いアクティビティに限定されていた、一定レベルのタスク処理と自動化を LLM に実行させることができることに気付きました。短期間で、当初のスコープは拡大しました。LLM チャット ウィンドウは、AI エージェントが自律的に計画、実行し、指定された目標を達成するためにその計画を反復的に評価および適応させるきっかけとなることができるようになりました。エージェントは、LLM 自身の推論、チャット履歴、思考メモリ (現状のまま) にアクセスでき、その目標達成に向けて活用できる特定のツールも利用できます。また、トップレベルのエージェントが、それぞれ独自のロジック チェーン、命令セット、コンテキスト、ツールを持つ複数のサブエージェントのオーケストレーターとして機能することを可能にするアーキテクチャも登場しています。
エージェントは、ほぼ自動化されたワークフローへのエントリ ポイントです。エージェントは自己主導型であり、ユーザーとチャットしてから「ロジック」を使用して、ユーザーの質問に答えるために使用できるツールを決定します。ツールは通常、エージェントに比べて受動的であると考えられており、1 種類のタスクを実行するために構築されています。ツールが実行できるタスクの種類はほぼ無限です (これは本当に素晴らしいことです!) が、ツールが実行する主なタスクは、エージェントがワークフローを実行する際に考慮するコンテキスト情報を収集することです。
技術としては、エージェント AI はまだ初期段階にあり、注意欠陥障害に相当する LLM になりがちです。つまり、指示されたことをすぐに忘れてしまい、指示にまったく含まれていない他の作業に走り出してしまうことがよくあります。一見魔法のように見えますが、LLM の「推論」機能は、シーケンス内で次に最も可能性の高いトークンを予測することに基づいています。推論(あるいは将来的には、汎用人工知能(AGI))が信頼できるものになるためには、正確で最新の情報が与えられたときに、私たちが期待する通りに推論してくれるか(そしておそらく、私たち自身では考えつかなかったようなちょっとした追加情報を提供してくれるか)を検証できなければなりません。これを実現するには、エージェント アーキテクチャに、明確に通信する機能 (プロトコル)、指定されたワークフローと制約を順守する機能 (ガードレール)、タスク内の位置を記憶する機能 (状態)、使用可能なメモリ領域を管理する機能、応答が正確でありタスクの基準を満たしていることを検証する機能が必要になります。
私に理解できる言語で話してください
新しい開発分野ではよくあることですが (特に LLM の世界ではそうです)、当初はエージェントとツール間の通信にはかなり多くのアプローチがありましたが、すぐにモデル コンテキスト プロトコル (MCP) が事実上の標準として採用されました。モデル コンテキスト プロトコルの定義はまさにその名前の通りで、 モデルが コンテキスト 情報を要求および受信するために使用する プロトコル です。MCP は、LLM エージェントが外部ツールやデータ ソースに接続するためのユニバーサル アダプタとして機能し、さまざまな LLM フレームワークやツールが簡単に相互運用できるように API を簡素化および標準化します。そのため、MCP は、エージェントが目的を達成するために自律的に実行するために与えられるオーケストレーション ロジックとシステム プロンプトと、より分離された形式 (少なくとも開始エージェントに関しては分離された形式) で実行するためにツールに送信される操作との間の、一種のピボット ポイントになります。
このエコシステムは非常に新しいため、あらゆる方向への拡大が新たなフロンティアのように感じられます。エージェント間のインタラクション(もちろんAgent2Agent (A2A) )用の類似プロトコルのほか、エージェントの推論メモリを改善するプロジェクト( ReasoningBank )、手元のジョブに最適な MCP サーバーを選択するプロジェクト( RAG-MCP )、ゼロショット分類や入力と出力のパターン検出などのセマンティック分析をガードレールとして使用してエージェントが操作できる内容を制御するプロジェクトもあります。
これらの各プロジェクトの根本的な目的は、エージェント/genAI コンテキスト ウィンドウに返される情報の品質と制御を向上させることであることにお気づきでしょうか。エージェント AI エコシステムは、コンテキスト情報をより適切に処理する (制御、管理、操作する) 能力の開発を継続していますが、エージェントが処理するための最も関連性の高いコンテキスト情報を取得する必要性は常に存在します。
コンテキストエンジニアリングへようこそ!
生成 AI の用語に詳しい方なら、おそらく「プロンプト エンジニアリング」という言葉を聞いたことがあるでしょう。現時点では、プロンプト エンジニアリングはそれ自体がほぼ疑似科学となっています。プロンプト エンジニアリングは、LLM が応答を生成する際に使用する動作を積極的に記述するための最良かつ最も効率的な方法を見つけるために使用されます。「コンテキスト エンジニアリング」は、「プロンプト エンジニアリング」の手法をエージェント側を超えて拡張し、MCP プロトコルのツール側で利用可能なコンテキスト ソースとシステムもカバーし、コンテキストの管理、処理、生成という幅広いトピックを扱います。
- コンテキスト管理- 長時間実行される、またはより複雑なエージェント ワークフロー全体で状態とコンテキストの効率を維持することに関連します。エージェントの目標を達成するために、タスクとツールの呼び出しを繰り返し計画、追跡、オーケストレーションします。エージェントが動作しなければならない「注意予算」は限られているため、コンテキスト管理は主に、コンテキスト ウィンドウを絞り込んでコンテキストの最大限の範囲と最も重要な部分 (精度と再現率) の両方をキャプチャするのに役立つ手法に関係しています。技術には、圧縮、要約、前のステップまたはツール呼び出しからのコンテキストを永続化して、後続のステップで追加のコンテキストのために作業メモリ内にスペースを確保することが含まれます。
- コンテキスト処理- エージェントがすべてのコンテキストをある程度統一された方法で推論できるように、異なるソースから取得したコンテキストを統合、正規化、または調整するための論理的かつできればほとんどプログラム的な手順。基本的な作業は、すべてのソース (プロンプト、RAG、メモリなど) からのコンテキストを、エージェントが可能な限り効率的に使用できるようにすることです。
- コンテキスト生成- コンテキスト処理が、取得したコンテキストをエージェントが使用できるようにすることであるならば、コンテキスト生成は、追加のコンテキスト情報を自由に、しかし制約付きで要求して受け取るための範囲をエージェントに提供します。
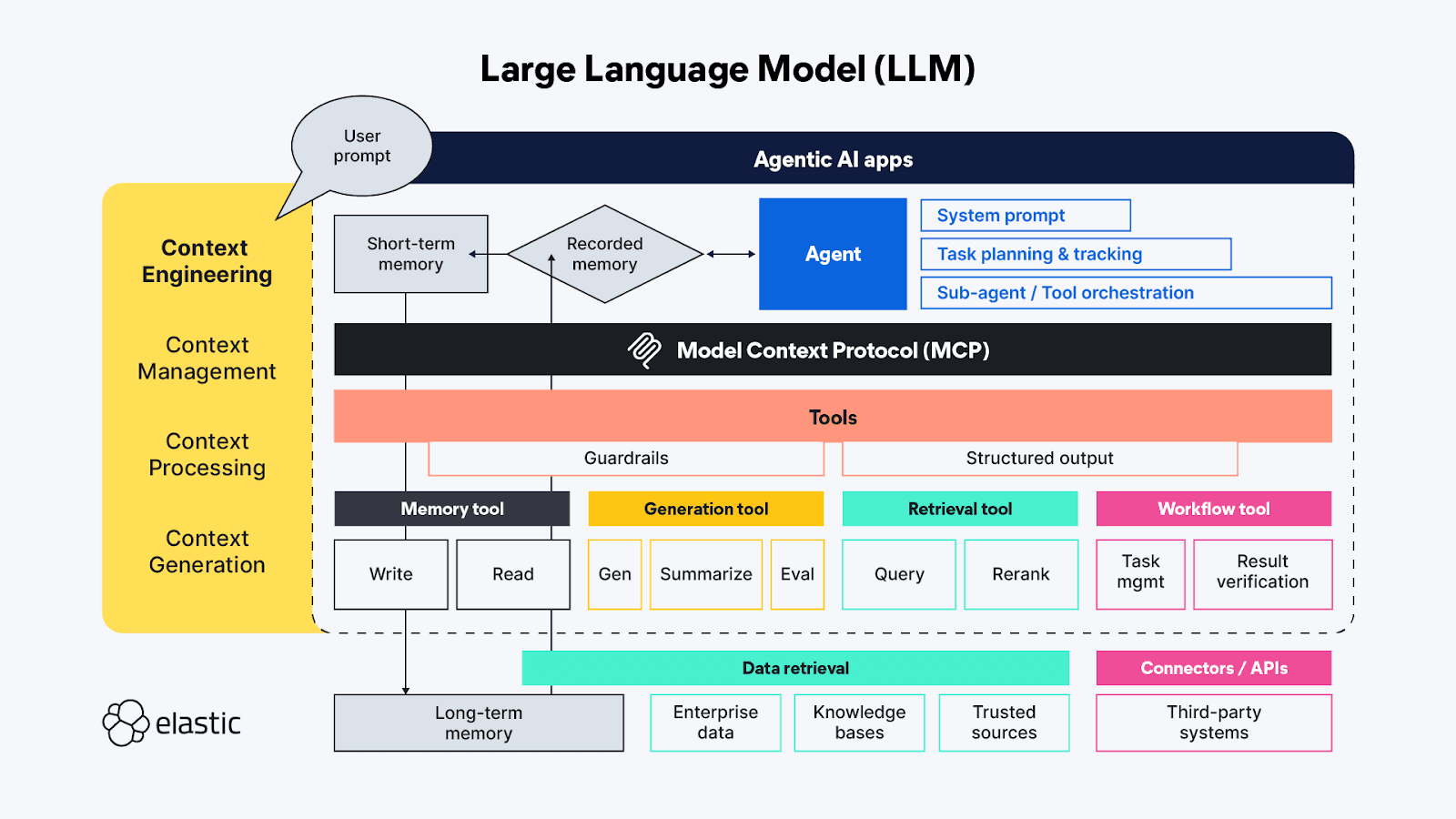
LLM チャット アプリケーションのさまざまな一時的な機能は、コンテキスト エンジニアリングの高レベル機能に直接 (場合によっては重複して) マッピングされます。
- 指示 / システム プロンプト- プロンプトは、生成的 (またはエージェント的) AI アクティビティがユーザーの目標を達成するためにどのように思考を導くかを示す足場です。プロンプトはそれ自体がコンテキストです。単なる音声による指示ではなく、回答がユーザーの要求に完全に応えているかどうかを確認するために、応答する前に「段階的に考える」や「深呼吸する」などのタスク実行ロジックやルールも含まれることがよくあります。最近のテストでは、マークアップ言語はプロンプトのさまざまな部分を組み立てるのに非常に効果的であることが示されていますが、指示を曖昧になりすぎず、具体的になりすぎないように注意して調整する必要があります。LLM が適切なコンテキストを見つけるのに十分な指示を与える必要がありますが、予期しない洞察を見逃すほど規範的であってはなりません。
- 短期記憶(状態/履歴) - 短期記憶は、基本的にユーザーと LLM 間のチャット セッションのやり取りです。これらはライブ セッションのコンテキストを絞り込むのに役立ち、将来の取得や続行のために保存できます。
- 長期記憶- 長期記憶は、複数のセッションにわたって役立つ情報で構成されている必要があります。また、RAG を通じてアクセスされるのはドメイン固有の知識ベースだけではありません。最近の研究では、以前のエージェント/生成 AI 要求の結果を使用して、現在のエージェントのやり取り内で学習および参照を行っています。長期記憶領域における最も興味深い革新のいくつかは、エージェントが中断したところから再開できるように、状態がどのように保存され、リンクされるかを調整することに関係しています。
- 構造化された出力- 認知には努力が必要なので、推論能力があっても、LLM が (人間と同じように) 考えるときにあまり努力を費やしたくないのは当然です。また、定義された API やプロトコルがない場合、ツール呼び出しから返されたデータを読み取る方法のマップ (スキーマ) を持つことは非常に役立ちます。構造化出力をエージェント フレームワークの一部として組み込むと、思考主導の解析の必要性が減り、マシン間のやり取りがより高速かつ信頼性が高くなるようになります。
- 利用可能なツール- ツールは、追加情報の収集 (エンタープライズ データ リポジトリへの RAG クエリの発行、またはオンライン API 経由の RAG クエリの発行など) から、エージェントに代わって自動アクションを実行すること (エージェントからのリクエストの基準に基づいてホテルの部屋を予約するなど) まで、さまざまな処理を実行できます。ツールは、独自のエージェント処理チェーンを持つサブエージェントになることもできます。
- 検索拡張生成 (RAG) - RAG の「動的な知識統合」という説明がとても気に入っています。前述のように、RAG は LLM がトレーニング時にアクセスできなかった追加情報を提供するための手法であり、主観的なクエリに最も関連性の高い正しい答えを得るために最も重要だと考えられるアイデアを繰り返し述べたものです。
驚異的な宇宙のパワー、小さな居住空間!
エージェント AI には、探索すべき魅力的でエキサイティングな新しい領域が数多くあります。解決すべき従来のデータ検索および処理の問題はまだたくさんありますが、LLM の新時代に初めて日の目を見るようになったまったく新しい種類の課題もあります。私たちが現在取り組んでいる差し迫った問題の多くは、コンテキスト エンジニアリング、つまり、LLM の限られた作業メモリ空間を圧迫することなく、必要な追加のコンテキスト情報を取得することに関係しています。
さまざまなツール (および他のエージェント) にアクセスできる半自律エージェントの柔軟性により、AI を実装するための非常に多くの新しいアイデアが生まれ、さまざまな方法でそれらを組み合わせることができるのかを推測するのは困難です。現在の研究のほとんどはコンテキスト エンジニアリングの分野に属し、大量のコンテキストを処理および追跡できるメモリ管理構造の構築に重点を置いています。これは、LLM に解決してほしい深い思考の問題には、記憶することが極めて重要となる、複雑さが増し、実行時間が長く、多段階の思考ステップが含まれるためです。
この分野で現在行われている多くの実験では、エージェントの口を満たすための最適なタスク管理とツール構成を見つけようとしています。エージェントの推論チェーンにおける各ツール呼び出しは、そのツールの機能を実行するための計算と、制限されたコンテキスト ウィンドウへの影響の両方の点で累積的なコストを発生させます。LLM エージェントのコンテキストを管理する最新の技術の一部は、長時間実行されるタスクの蓄積されたコンテキストを圧縮/要約すると損失が 大きくなりすぎる 「 コンテキストの崩壊 」などの意図しない連鎖効果を引き起こしています。望ましい結果は、貴重なコンテキスト ウィンドウのメモリ領域に余分な情報が漏れることなく、簡潔で正確なコンテキストを返すツールです。
可能性が多すぎる
私たちはツール/コンポーネントを再利用するための柔軟性を備えた職務の分離を望んでいるため、特定のデータ ソースに接続するための専用のエージェント ツールを作成することは完全に理にかなっています。各ツールは、1 つのタイプのリポジトリ、1 つのタイプのデータ ストリーム、または 1 つのユース ケースのクエリに特化できます。しかし、注意してください。時間や費用を節約し、何かが可能であると証明しようとすると、LLM をフェデレーション ツールとして使用する強い誘惑に駆られるでしょう... やめてください。私たちは以前にもその道を歩んだことがあります。フェデレーション クエリは、受信したクエリをリモート リポジトリが理解できる構文に変換する「ユニバーサル トランスレータ」のように機能し、その後、複数のソースからの結果を何らかの方法で合理化して一貫した応答を生成する必要があります。技術としてのフェデレーションは小規模では 問題なく 機能します が、大規模で、特にデータがマルチモーダルである場合、フェデレーションは大きすぎるギャップを埋めようとします。
エージェントの世界では、エージェントがフェデレーターとなり、ツール (MCP 経由) がさまざまなリソースへの手動で定義された接続となります。専用のツールを使用して接続されていないデータ ソースにアクセスすることは、クエリごとにさまざまなデータ ストリームを動的に統合する強力な新しい方法のように思えるかもしれませんが、ツールを使用して複数のソースに同じ質問をすると、解決するよりも多くの問題が発生する可能性があります。これらのデータ ソースはそれぞれ、その下にある異なるタイプのリポジトリである可能性があり、それぞれが内部のデータを取得、ランク付け、保護するための独自の機能を備えています。もちろん、リポジトリ間のこうした差異、つまり「インピーダンスの不一致」により、処理負荷が増加します。また、矛盾する情報やシグナルが生じる可能性があり、スコアの不一致のように一見無害に見えるものでも、返されたコンテキストの重要性が大きく損なわれ、最終的に生成された応答の関連性に影響する可能性があります。
コンテキストスイッチはコンピュータにとっても難しい
エージェントを任務に送り出す場合、多くの場合、最初の任務はエージェントがアクセスできるすべての関連データを見つけることです。人間の場合と同様に、エージェントが接続する各データ ソースが類似していない分散した応答を返すと、取得したコンテンツから重要なコンテキスト ビットを抽出することに関連する認知負荷 (まったく同じ種類ではありませんが) が発生します。これには時間と計算がかかり、エージェントのロジック チェーンでは少しずつ蓄積されていきます。このことから、 MCPについて議論されているように、ほとんどのエージェント ツールは、API (既知の入力と出力を持つ分離された関数で、さまざまな種類のエージェントのニーズをサポートするように調整された) のように動作する必要があるという結論に至ります。実際、 LLM にはコンテキストのためのコンテキストが必要であることにも気づき始めています。特に、自然言語を構造化構文に翻訳するようなタスクでは、参照できるスキーマがあれば、LLM は意味の点と点を結びつけるのがはるかに上手です (まさに RTFM!)。
7回裏ストレッチ!
ここでは、 LLM がデータの取得とクエリに与えた影響と、チャット ウィンドウがエージェント AI エクスペリエンスへとどのように成熟しているかについて説明しました。これら 2 つのトピックを組み合わせて、最新の検索機能と取得機能を使用してコンテキスト エンジニアリングの結果を改善する方法を見てみましょう。パート III へ進みます: コンテキスト エンジニアリングにおけるハイブリッド検索の威力!
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。