Conéctate fácilmente con las principales plataformas de inteligencia artificial y machine learning. Inicia una prueba gratuita en el cloud para explorar las capacidades de IA generativa de Elastic o pruébalo en tu máquina ahora mismo.
Con Elasticsearch sin estado, estamos invirtiendo en construir una nueva arquitectura completamente nativa en la nube para llevar al límite la escala y la velocidad. En este blog, exploramos dónde empezamos, el futuro de Elasticsearch con la introducción de una arquitectura sin estado y los detalles de esta arquitectura.
Donde empezamos
La primera versión de Elasticsearch se lanzó en 2010 como un motor de búsqueda distribuido y escalable que permite a los usuarios buscar rápidamente y mostrar información crítica. Doce años y más de 65.000 commits después, Elasticsearch sigue ofreciendo a los usuarios soluciones probadas para una amplia variedad de problemas de búsqueda. Gracias al esfuerzo de más de 1.500 colaboradores, incluidos cientos de empleados a tiempo completo de Elastic, Elasticsearch evolucionó constantemente para afrontar los nuevos retos que surgen en el campo de la búsqueda.
Al principio de la vida de Elasticsearch, cuando surgieron preocupaciones sobre la pérdida de datos, el equipo de Elastic llevó a cabo un esfuerzo de varios años para reescribir el sistema de coordinación del clúster y garantizar que los datos reconocidos se almacenen de forma segura. Cuando quedó claro que gestionar índices en grandes clústeres era un engorro, el equipo trabajó en la implementación de una solución ILM extensa para automatizar este trabajo permitiendo a los usuarios predefinir patrones de índices y acciones del ciclo de vida. A medida que los usuarios notaron la necesidad de almacenar cantidades significativas de datos métricos y de seriales temporales, se agregaron varias características como una mejor compresión para reducir el tamaño de los datos. A medida que aumentaba el costo de almacenamiento de buscar grandes cantidades de datos fríos, invertimos en crear Instantáneas Buscables como una forma de buscar datos de usuario directamente en almacenes de objetos de bajo costo.
Estas inversiones sentan las bases para la siguiente evolución de Elasticsearch. Con el crecimiento de los servicios nativos en la nube y los nuevos sistemas de orquestación, decidimos que es hora de evolucionar Elasticsearch para mejorar la experiencia al trabajar con sistemas nativos en la nube. Creemos que estos cambios presentan oportunidades para mejoras operativas, de rendimiento y de costos al ejecutar Elasticsearch en Elastic Cloud.
Hacia dónde vamos — Adoptar una arquitectura sin estado
Uno de los principales retos al operar u orquestar Elasticsearch es que depende de numerosas piezas de estado persistente, por lo que es un sistema con estado. Las tres piezas principales son el translog, el almacenamiento de índices y los metadatos del clúster. Este estado significa que el almacenamiento debe ser persistente y no puede perder durante un resetear o reemplazo de nodo.
La arquitectura existente de Elasticsearch en Elastic Cloud debe duplicar la indexación en múltiples zonas de disponibilidad para proporcionar redundancia en caso de caídas. Nuestra intención es trasladar la persistencia de estos datos de los discos locales a un almacén de objetos, como AWS S3. Al depender de servicios externos para almacenar estos datos, eliminaremos la necesidad de replicación indexada, reduciendo significativamente el hardware asociado a la ingestión. Esta arquitectura también ofrece garantías de durabilidad muy altas debido a la forma en que los almacenes de objetos en la nube como AWS S3, GCP Cloud Storage y Azure Blob Storage replican los datos entre zonas de disponibilidad.
Transferir el almacenamiento indexado a un servicio externo también nos permitirá reestructurar Elasticsearch separando las responsabilidades de indexación y búsqueda. En lugar de que las instancias primarias y réplicas gestionen ambas cargas de trabajo, pretendemos tener un nivel de indexación y un nivel de búsqueda. Separar estas cargas de trabajo permitirá escalarlas de forma independiente y seleccionar el hardware más dirigido a los casos de uso respectivos. También ayuda a resolver un reto de larga duración en el que la carga de búsqueda e indexación puede afectar mutuamente.
Tras realizar una fase de prueba de concepto y experimental de varios meses, estamos convencidos de que estos servicios de almacenamiento de objetos cumplen los requisitos que prevemos para el almacenamiento de índices y los metadatos de clústeres. Nuestras pruebas y benchmarks indican que estos servicios de almacenamiento pueden satisfacer las altas necesidades de indexación de los clústeres más grandes que vimos en Elastic Cloud. Además, respaldar los datos en el almacén de objetos reduce los costos de indexación y permite un ajuste sencillo del rendimiento de la búsqueda. Para buscar datos, Elasticsearch empleará el modelo Searchable Snapshots, probado en batalla, donde los datos persisten permanentemente en el almacén de objetos nativos de la nube y los discos locales se emplean como cachés para los datos frecuentemente consultados.

Para ayudar a diferenciar, describimos nuestro modelo existente como replicación "nodo a nodo". En el nivel caliente de este modelo, tanto los fragmentos primarios como los réplica hacen el mismo trabajo pesado para gestionar las solicitudes de búsqueda de ingesta y servicio. Estos nodos son "con estado" en el sentido de que dependen de sus discos locales para conservar de forma segura los datos de los fragmentos que alojan. Además, los fragmentos primarios y réplica están constantemente comunicar para mantener sincronizados. Lo hacen replicando las operaciones realizadas en el shard principal al shard réplica, lo que significa que el costo de esas operaciones (principalmente CPU) se incurre por cada réplica especificada. Los mismos fragmentos y nodos que realizan este trabajo para la ingesta también están atendiendo las solicitudes de búsqueda, por lo que el aprovisionamiento y el escalado deben hacer teniendo en cuenta ambas cargas de trabajo.
Más allá de buscar e ingerir, los fragmentos en el modelo de replicación nodo a nodo gestionan otras responsabilidades intensivas, como fusionar segmentos Lucene. Aunque este diseño tiene sus méritos, vimos muchas oportunidades basadas en lo que aprendimos con los clientes a lo largo de los años y en la evolución del ecosistema cloud más amplio.
La nueva arquitectura permite muchas mejoras inmediatas y futuras, incluyendo:
- Puedes aumentar significativamente el rendimiento de ingesta en el mismo hardware o, dicho de otra manera, mejorar significativamente la eficiencia para la misma carga de trabajo de ingestión. Este aumento se debe a eliminar la duplicación de operaciones de indexación para cada réplica. Las operaciones de indexación intensivas en CPU solo necesitan realizar una vez en el nivel de indexación, que entonces transporta los segmentos resultantes a un almacén de objetos. A partir de ahí, los datos están listos para ser consumidos tal cual por el nivel de búsqueda.
- Puedes separar el cálculo del almacenamiento para simplificar la topología de tu clúster. Hoy en día, Elasticsearch dispone de múltiples niveles de datos (contenido, caliente, caliente, frío y congelado) para emparejar datos con el perfil de hardware. El hot tier es para búsquedas casi en tiempo real y el congelado es para datos menos frecuentemente buscados. Aunque estos niveles aportan valor, también aumentan la complejidad. En la nueva arquitectura, los niveles de datos dejarán de ser necesarios, lo que simplificará la configuración y funcionamiento de Elasticsearch. También estamos separando la indexación de la búsqueda, lo que reduce aún más la complejidad y nos permite escalar ambas cargas de trabajo de forma independiente.
- Puedes experimentar una mejora en los costos de almacenamiento en el nivel de indexación al reducir la cantidad de datos que deben almacenar en un disco local. Actualmente, Elasticsearch debe almacenar una copia completa del fragmento en nodos calientes (tanto primarios como réplicas) para fines de indexación. Con el enfoque sin estado de indexar directamente al almacén de objetos, solo se requiere una parte de esos datos locales. Para casos de uso solo de anexo, solo ciertos metadatos deberán almacenar para indexar. Esto reducirá significativamente el almacenamiento local necesario para la indexación.
- Puedes reducir los costos de almacenamiento asociados a las búsquedas. Al convertir el modelo de Instantáneas Buscables en el modo nativo de búsqueda de datos, el costo de almacenamiento asociado a las consultas de búsqueda disminuirá significativamente. Dependiendo de las necesidades de latencia de búsqueda de los usuarios, Elasticsearch permitirá ajustes para aumentar la caché local en los datos aplicar con frecuencia.
Benchmarking — Mejora del 75% en el rendimiento de la indexación
Para validar este enfoque, implementamos una prueba de concepto extensa en la que los datos solo se indexaban en un solo nodo y la replicación se realizaba mediante almacenes de objetos en la nube. Descubrimos que podíamos lograr una mejora del 75% en el rendimiento de indexación eliminando la necesidad de dedicar hardware a la replicación de indexación. Además, el costo de CPU asociado simplemente a extraer datos del object store era mucho menor que indexar los datos y escribirlos localmente, como es necesario para la fase caliente hoy en día. Esto significa que los nodos de búsqueda podrán dedicar completamente su CPU a la búsqueda.
Estas pruebas de rendimiento se realizaron en un clúster de dos nodos contra los tres principales proveedores de nube pública (AWS, GCP y Azure). Tenemos la intención de seguir desarrollando benchmarks más amplios mientras buscamos una implementación sin estado en producción.
Rendimiento de indexación


Uso de la CPU
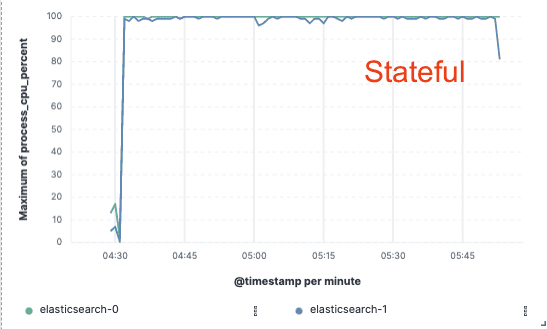
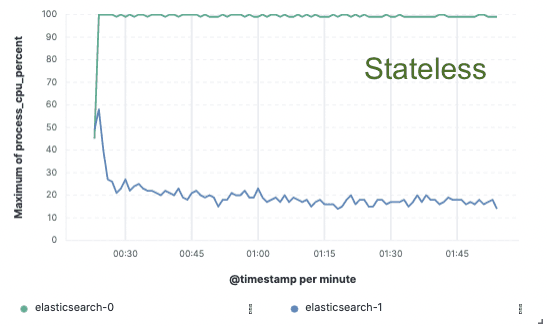
Apátrida para nosotros, ahorros para ti
La arquitectura sin estado de Elastic Cloud te permitirá reducir la sobrecarga de indexación, escalar de forma independiente la ingesta y la búsqueda, simplificar la gestión de los niveles de datos y acelerar operaciones, como escalar o actualizar. Este es el primer hito hacia una modernización sustancial de la plataforma Elastic Cloud.
Forma parte de nuestra visión sin estado de Elasticsearch
¿Te interesa probar esta solución antes que nadie? Puedes contactarnos en Discuss o en nuestro canal comunitario de Slack. Nos encantaría recibir vuestros comentarios para ayudar a definir la dirección de nuestra nueva arquitectura.
Contenido relacionado
18 de mayo de 2026
Una búsqueda, múltiples proyectos de Elasticsearch Serverless: presentación de la búsqueda entre proyectos
La búsqueda entre proyectos en Elastic Cloud Serverless te permite buscar datos entre proyectos aislados en un solo Elasticsearch o ES|QL: sin duplicación, sin peering de red y sin egreso de costos por copiar logs.

20 de abril de 2026
Introducción de claves API unificadas para Elastic Cloud Serverless y Elasticsearch
Aprende cómo Elastic unificó la autenticación del plano de control y del plano de datos en Serverless con una arquitectura de IAM distribuida globalmente. Usa una sola clave de API para las API de Cloud y de Elasticsearch.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

24 de marzo de 2026
Réplicas de Elasticsearch para balanceo de carga en Serverless
Aprende cómo Elastic Cloud Serverless ajusta automáticamente las réplicas del índice según la carga de búsqueda, lo que garantiza un rendimiento óptimo de búsqueda sin configuración manual.
22 de enero de 2026
Agent Builder ya está disponible para el público en general: envía agentes según el contexto en cuestión de minutos
Agent Builder ahora está disponible para el público en general. Aprende cómo te permite desarrollar rápidamente agentes de IA basados en el contexto.