Elasticsearch tiene integraciones nativas con las herramientas y proveedores líderes en la industria de IA generativa. Echa un vistazo a nuestros webinars sobre cómo ir más allá de los conceptos básicos de RAG o crear apps listas para la producción con la base de datos vectorial de Elastic.
Para crear las mejores soluciones de búsqueda para tu caso de uso, inicia una prueba gratuita en el cloud o prueba Elastic en tu máquina local ahora mismo.
La plantilla del agente de recuperación de LangGraph es un proyecto inicial desarrollado por LangChain para facilitar la creación de sistemas de respuesta a preguntas basados en la recuperación empleando LangGraph en LangGraph Studio. Esta plantilla está preconfigurada para integrar perfectamente con Elasticsearch, lo que permite a los desarrolladores crear rápidamente agentes que puedan indexar y recuperar documentos de manera eficiente.
Este blog se centra en la ejecución y personalización de la plantilla del agente de recuperación de LangChain mediante LangGraph Studio y LangGraph CLI. La plantilla proporciona un marco para crear aplicaciones de generación aumentada de recuperación (RAG), aprovechando varios backends de recuperación como Elasticsearch.
Te guiaremos a través de la instalación, la configuración del entorno y la ejecución de la plantilla de manera eficiente con Elastic mientras personalizas el flujo del agente.
Prerrequisitos
Antes de continuar, cerciorar de tener instalado lo siguiente:
- Despliegue de Elasticsearch Cloud o despliegue de Elasticsearch local (o crea una prueba gratis de 14 días en Elastic Cloud) - Versión 8.0.0 o superior
- Python 3.9+
- Acceso a un proveedor de LLM como Cohere (empleado en esta guía), OpenAI o Anthropic/Claude
Creación de la aplicación LangGraph
1. Instalar la CLI de LangGraph
2. Crear la aplicación LangGraph a partir de retrieval-agent-template
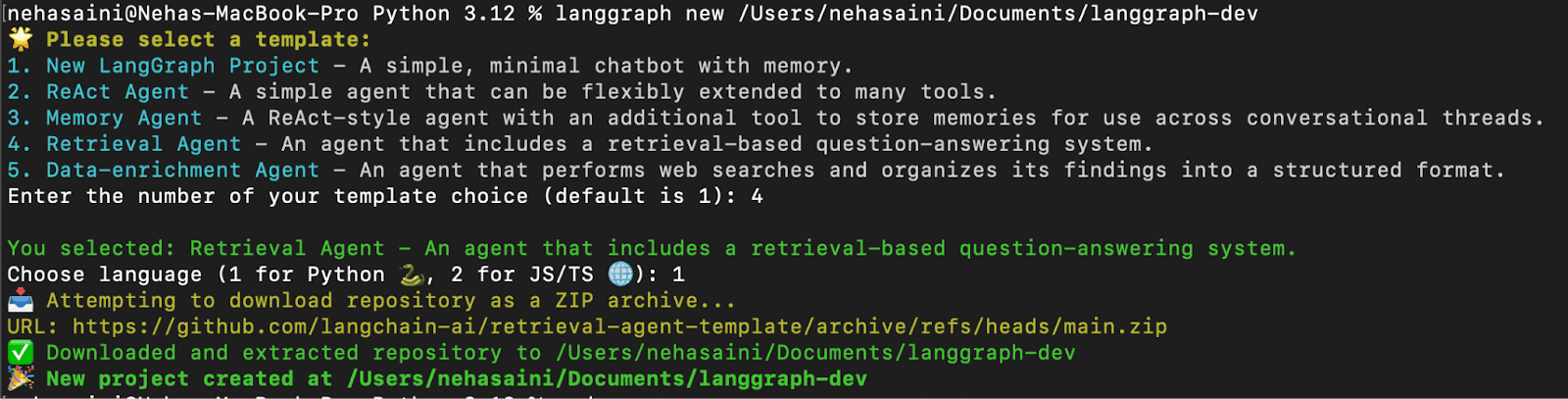
Se le presentará un menú interactivo que le permitirá elegir entre una lista de plantillas disponibles. Seleccione 4 para el Agente de recuperación y 1 para Python, como se muestra a continuación:
- Solución de problemas: Si encuentra el error "urllib.error.URLError: error <urlopen [SSL: CERTIFICATE_VERIFY_FAILED] error de verificación del certificado: no se puede obtener el certificado del emisor local (_ssl.c:1000)> “
Ejecute el comando Instalar certificado de Python para resolver el problema, como se muestra a continuación.

3. Instalar dependencias
En la raíz de su nueva aplicación LangGraph, cree un entorno virtual e instale las dependencias en modo edit para que el servidor emplee sus cambios locales:
Configuración del entorno
1. Crear un entorno .. archivo
El archivo .env contiene claves y configuraciones de API para que la aplicación pueda conectarse al proveedor de recuperación y LLM elegido. Genere un nuevo archivo .env duplicando la configuración de ejemplo:
2. Configurar el .env archivo
El archivo .env viene con un conjunto de configuraciones predeterminadas. Puede actualizarlo agregando las claves y los valores de API necesarios según su configuración. Las claves que no sean relevantes para tu caso de uso se pueden dejar sin cambios o quitar.
- Ejemplo
.envarchivo (con Elastic Cloud y Cohere)
A continuación, se muestra un ejemplo de configuración .env para usar Elastic Cloud como proveedor de recuperación y Cohere como LLM, como se muestra en este blog:
Nota: Si bien esta guía usa Cohere tanto para la generación de respuestas como para las incrustaciones, puede usar otros proveedores de LLM como OpenAI, Claudeo incluso un modelo de LLM local, según su caso de uso. Cerciorar de que cada tecla que desea emplear esté presente y configurada correctamente en el archivo.env.
3. Actualizar archivo de configuración -configuration.py
Luego de configurar tu archivo .env con las claves de API adecuadas, el siguiente paso es actualizar la configuración del modelo predeterminado de tu aplicación. La actualización de la configuración garantiza que el sistema use los servicios y modelos que especificó en el archivo .env .
Vaya al archivo de configuración:
El archivo configuration.py contiene la configuración predeterminada del modelo empleada por el agente de recuperación para tres tareas principales:
- Modelo de incrustación : convierte documentos en representaciones vectoriales
- Modelo de consulta : procesa la consulta del usuario en un vector
- Modelo de respuesta : genera la respuesta final
De forma predeterminada, el código emplea modelos de OpenAI (por ejemplo, openai/text-embedding-3-small) y Anthropic (por ejemplo, anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307).
En este blog, estamos cambiando al uso de modelos Cohere. Si ya está empleando OpenAI o Anthropic, no se necesitan cambios.
Ejemplos de cambios (usando Cohere):
Abra configuration.py y modifique los valores predeterminados del modelo como se muestra a continuación:
Ejecutando el agente de recuperación con la CLI de LangGraph
1. Inicie el servidor LangGraph
Esto iniciará el servidor de la API de LangGraph localmente. Si esto se ejecuta correctamente, debería ver algo como:
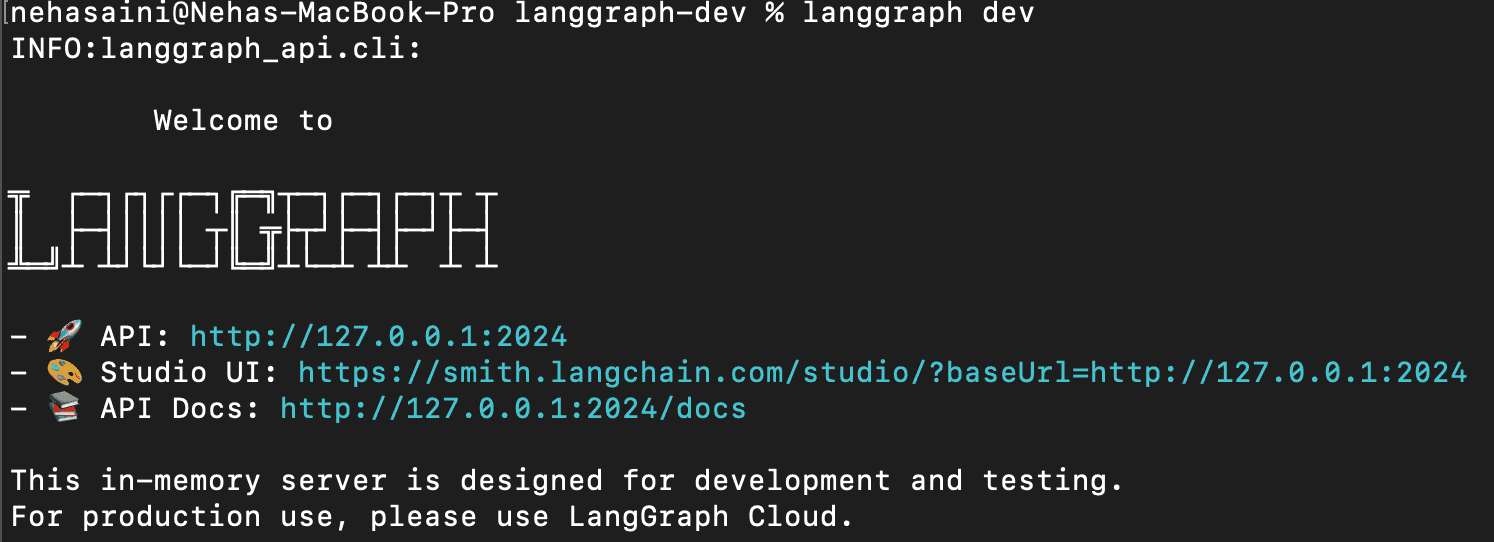
Abra la URL de la interfaz de usuario de Studio.
Hay dos gráficos disponibles:
- Gráfico de recuperación: Recupera datos de Elasticsearch y responde a la consulta usando un LLM.
- Gráfico indexador: Indexa documentos en Elasticsearch y genera incrustaciones usando un LLM.

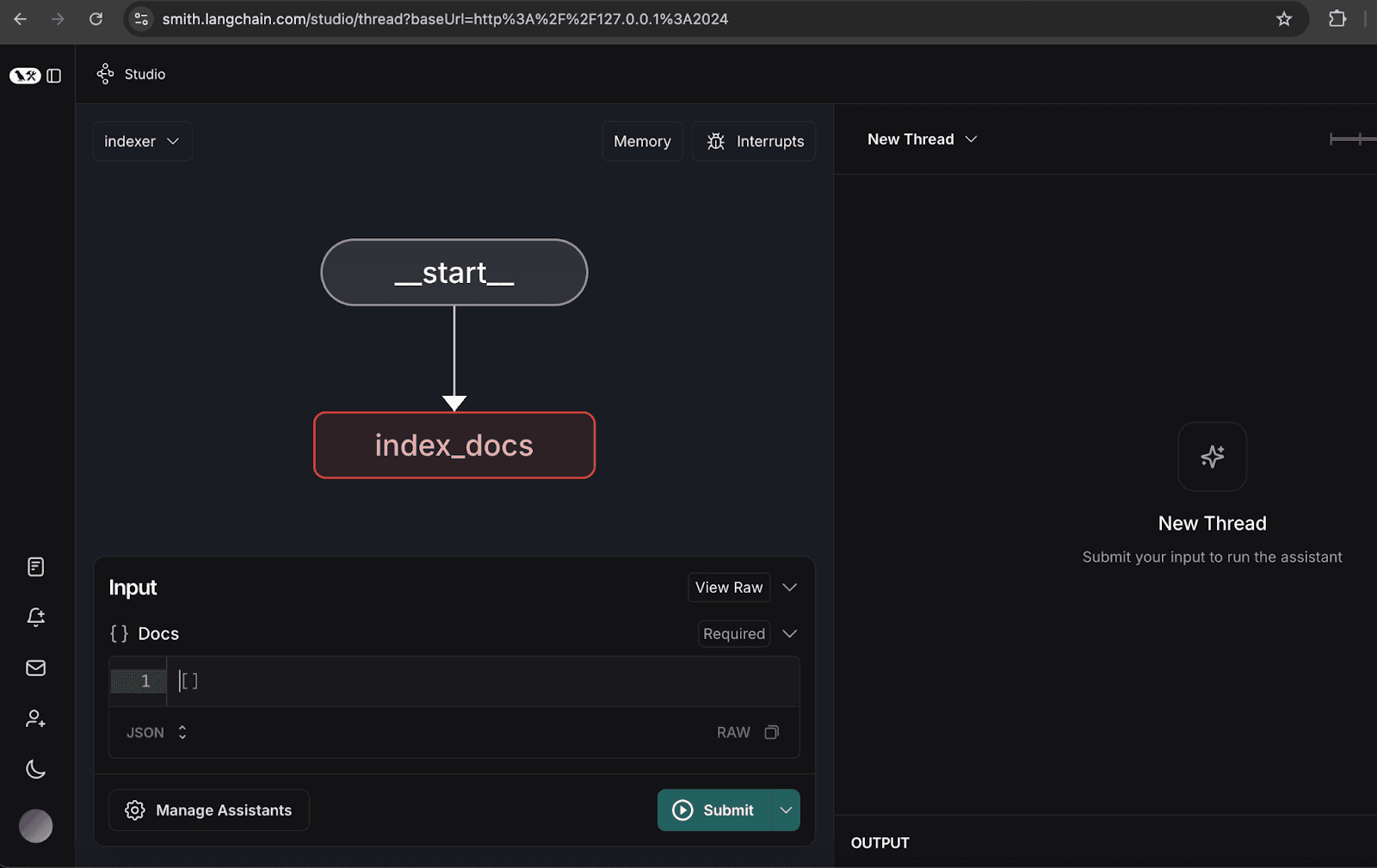
2. Configuración del grafo indexador
- Abre el gráfico del indexador.
- Haz clic en gestionar asistentes.
- Haz clic en 'Agregar nuevo asistente', introduce los datos del usuario según lo especificado y luego cierra la ventana.


3. Indexación de documentos de muestra
- Indexe los siguientes documentos de muestra, que representan un reporte trimestral hipotético para la organización NoveTech:
Una vez indexados los documentos, verá un mensaje de eliminación en el hilo, como se muestra a continuación.

4. Ejecutar el grafo de recuperación
- Cambia al gráfico de recuperación.
- Introduzca la siguiente consulta de búsqueda:

El sistema devolverá los documentos relevantes y proporcionará una respuesta exacta basada en los datos indexados.
Personalizar el agente de recuperación
Para mejorar la experiencia del usuario, introducimos un paso de personalización en el gráfico de recuperación para predecir las siguientes tres preguntas que un usuario podría hacer. Esta predicción se basa en:
- Contexto de los documentos recuperados
- Interacciones anteriores de los usuarios
- Última consulta de usuario
Se requieren los siguientes cambios de código para implementar la función de predicción de consultas:
1. Actualización graph.py
- Agregue
predict_queryfunción:
- Modifique
respondfunción para devolverresponseObject , en lugar de message:
- Actualice la estructura del gráfico para agregar un nuevo nodo y borde para predict_query:
2. Actualización prompts.py
- Prompt de creación para predicción de guery en
prompts.py:
3. Actualización configuration.py
- Agregar
predict_next_question_prompt:
4. Actualización state.py
- Agregue los siguientes atributos:
5. Volver a ejecutar el grafo de recuperación
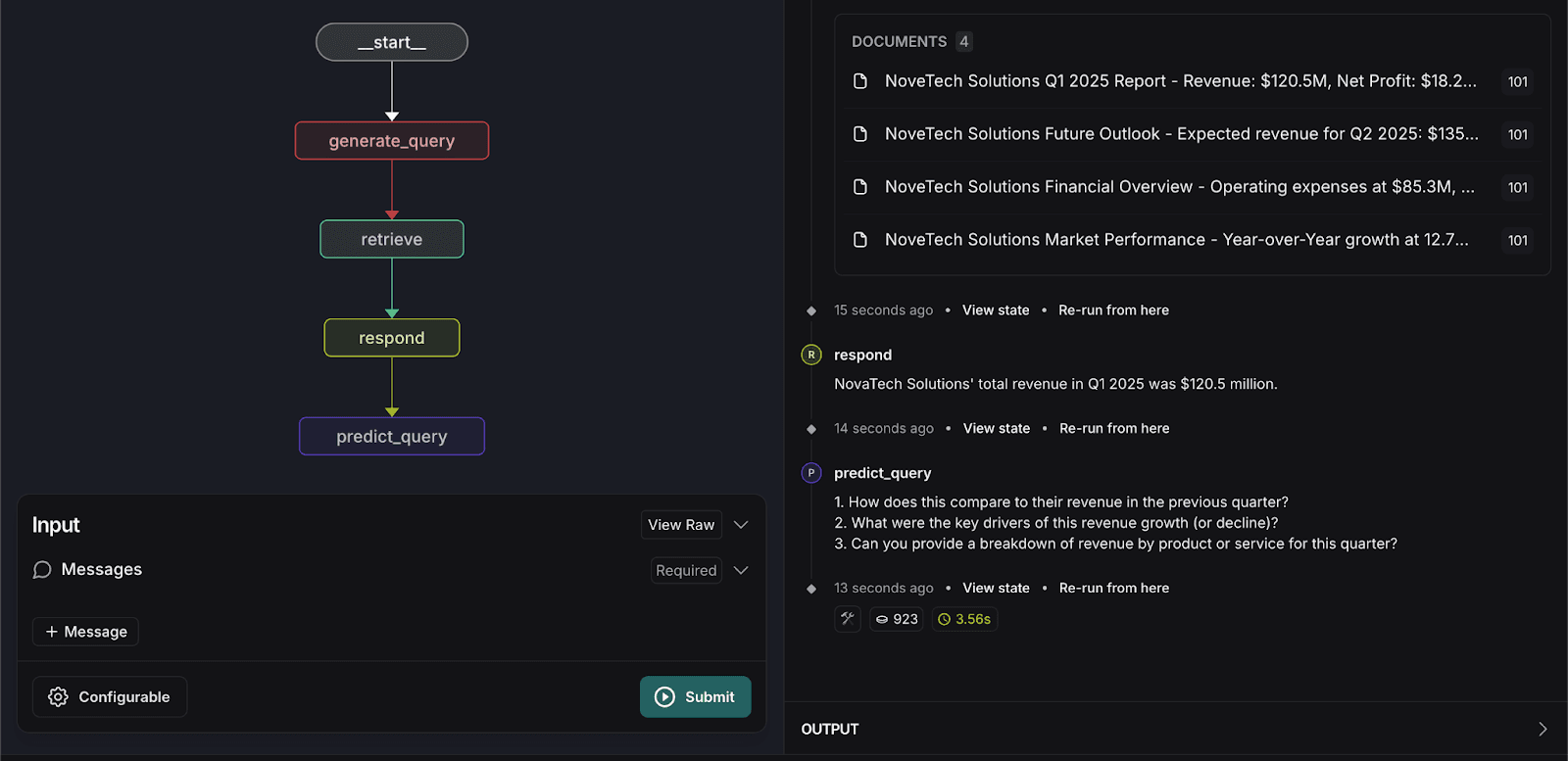
- Vuelva a introducir la siguiente consulta de búsqueda:
El sistema procesará la entrada y predecirá tres preguntas relacionadas que los usuarios podrían hacer, como se muestra a continuación.
Conclusión
La integración de la plantilla del agente de recuperación dentro de LangGraph Studio y CLI proporciona varios beneficios clave:
- Desarrollo acelerado: las herramientas de plantilla y visualización agilizan la creación y depuración de flujos de trabajo de recuperación, lo que reduce el tiempo de desarrollo.
- Implementación perfecta: la compatibilidad integrada con las API y el escalado automático garantiza una implementación fluida en todos los entornos.
- Actualizaciones fáciles: Modificar los flujos de trabajo, agregar nuevas funcionalidades e integrar nodos adicionales es simple, lo que facilita escalar y mejorar el proceso de recuperación.
- Memoria persistente: el sistema conserva los estados y el conocimiento de los agentes, lo que mejora la coherencia y la confiabilidad.
- Modelado de flujo de trabajo flexible: los desarrolladores pueden personalizar la lógica de recuperación y las reglas de comunicación para casos de uso específicos.
- Interacción y depuración en tiempo real: la capacidad de interactuar con los agentes en ejecución permite realizar pruebas y resolver problemas de manera eficiente.
Al aprovechar estas características, las organizaciones pueden crear sistemas de recuperación poderosas, eficientes y escalables que mejoren la accesibilidad de los datos y la experiencia del usuario.
El código fuente completo de este proyecto está disponible en GitHub.
Preguntas frecuentes
¿Qué es un flujo de trabajo RAG?
Un flujo de trabajo RAG (Generación Aumentada por Recuperación) es una forma de dar a un modelo de IA acceso a tus datos privados para que pueda ofrecer respuestas precisas y basadas en hechos en lugar de "alucinar".
¿Por qué usar Elasticsearch como base de datos para un agente LangGraph?
Elasticsearch actúa como la "memoria a largo plazo" del agente. A diferencia de una base de datos estándar, está diseñada para la búsqueda híbrida: combinar búsqueda vectorial (entender el significado) con búsqueda por palabras clave (encontrar términos exactos). Esto garantiza que, ya sea que pidas "ingresos del primer trimestre" o "crecimiento financiero", Elasticsearch proporcione los documentos más relevantes para que LangGraph los procese.
¿Puedo construir un sistema multiusuario con la plantilla de agente de recuperación LangGraph?
Sí. El artículo lo demuestra mediante la configuración del grafo indexador usando un user_id (como "101"). Esto permite etiquetar documentos con propietarios específicos, permitiendo que el agente de recuperación encuentre solo la información que un usuario específico está autorizado a ver.
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

13 de marzo de 2026
Resolución de entidades con Elasticsearch, parte 4: el desafío final
Resolver y evaluar los desafíos de resolución de entidades en sets de datos de "desafío final" altamente diversos, diseñados para prevenir atajos.

26 de febrero de 2026
Resolución de entidades con Elasticsearch y LLMs, parte 2: emparejamiento de entidades con evaluación de LLM y búsqueda semántica
Usar la búsqueda semántica y las evaluaciones transparentes de LLM para la resolución de entidades en Elasticsearch.

2 de enero de 2026
Automatización del análisis de logs en Streams con ML.
Descubre cómo un enfoque híbrido de ML logró un 94 % de precisión en el análisis de logs y un 91 % en la partición de logs mediante experimentos de automatización con huellas digitales de formato de registro en Streams.

15 de diciembre de 2025
Primeros pasos con Elastic Agent Builder y Strands Agents SDK
Aprende a crear un agente con Elastic Agent Builder y, a continuación, descubre cómo utilizar el agente a través del protocolo A2A orquestado con el SDK de Strands Agents.