Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
La búsqueda vectorial proporciona la base al implementar la búsqueda semántica de texto o la búsqueda de similitud de imágenes, videos o audio. Con la búsqueda vectorial, los vectores son representaciones matemáticas de datos que pueden ser enormes y, a veces, lentos. Better Binary Quantization (en lo sucesivo, BBQ) funciona como un método de compresión para vectores. Le permite encontrar las coincidencias correctas mientras reduce los vectores para que sean más rápidos de buscar y procesar. Este artículo cubrirá BBQ y rescore_vector, un campo solo disponible para índices cuantificados que vuelve a calificar automáticamente los vectores.
Todas las consultas y salidas completas mencionadas en este artículo se pueden encontrar en nuestro repositorio de código de Elasticsearch Labs.
¿Por qué implementar Better Binary Quantization (BBQ) en tu caso de uso?
Nota: para una comprensión profunda de cómo funcionan las matemáticas detrás del asado, consulte la sección "Aprendizaje adicional" a continuación. Para los propósitos de este blog, la atención se centra en la implementación.
Aunque las matemáticas son interesantes, son cruciales si quieres comprender completamente por qué tus búsquedas vectoriales siguen siendo precisas. En última instancia, todo esto se reduce a la compresión, ya que resulta que con los algoritmos actuales de búsqueda vectorial estás limitado por la velocidad de lectura de los datos. Por lo tanto, si puedes meter todos esos datos en la memoria, obtienes un aumento significativo de velocidad en comparación con leer desde el almacenamiento (la memoria es aproximadamente 200 veces más rápida que los SSD).
Hay algunas cosas a tener en cuenta:
- Los índices basados en gráficos como HNSW (Hierarchical Navigable Small World) son los más rápidos para la recuperación de vectores.
- HNSW: Un algoritmo de búsqueda aproximado del vecino más cercano que construye una estructura de gráficos multicapa para permitir búsquedas eficientes de similitud de alta dimensión.
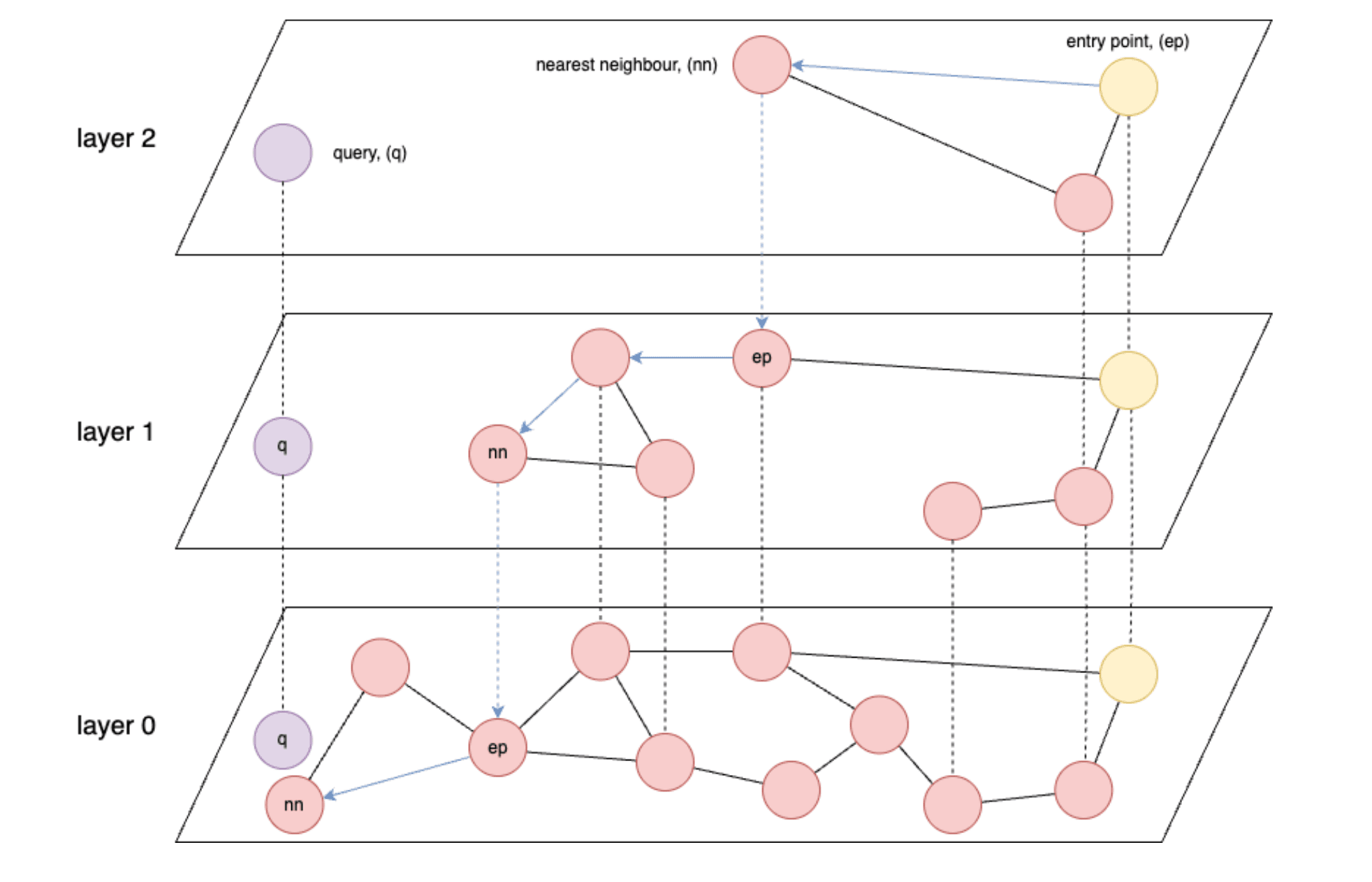
- HNSW está fundamentalmente limitado en velocidad por la velocidad de lectura de datos de la memoria o, en el peor de los casos, del almacenamiento.
- Idealmente, desea poder cargar todos sus vectores almacenados en la memoria.
- Los modelos de incrustación generalmente producen vectores con precisión float32, 4 bytes por número de punto flotante.
- Y finalmente, dependiendo de cuántos vectores y / o dimensiones tenga, puede quedar sin memoria muy rápidamente para mantener todos sus vectores.
Dando esto por sentado, ve que surge un problema rápidamente una vez que comienza a ingerir millones o incluso miles de millones de vectores, cada uno con potencialmente cientos o incluso miles de dimensiones. La sección titulada "Números aproximados en las relaciones de compresión" proporciona algunos números aproximados.
¿Qué necesitas para empezar?
Para comenzar, necesitará lo siguiente:
- Si usas Elastic Cloud o en las instalaciones, necesitarás una versión de Elasticsearch superior a la 8.18. Si bien BBQ se introdujo en 8.16, en este artículo, usará
vector_rescore, que se introdujo en 8.18. - Además, también deberá cerciorar de que haya un nodo de aprendizaje automático (ML) en el clúster. (Nota: se necesita un nodo de ML con un mínimo de 4 GB para cargar el modelo, pero es probable que necesite nodos mucho más grandes para cargas de trabajo de producción completas).
- Si emplea Serverless, deberá seleccionar una instancia optimizada para vectores.
- También necesitará un nivel básico de conocimiento sobre bases de datos vectoriales. Si aún no estás familiarizado con los conceptos de búsqueda vectorial en Elastic, es posible que desees consultar primero los siguientes recursos:
Mejor implementación de cuantización binaria (BBQ)
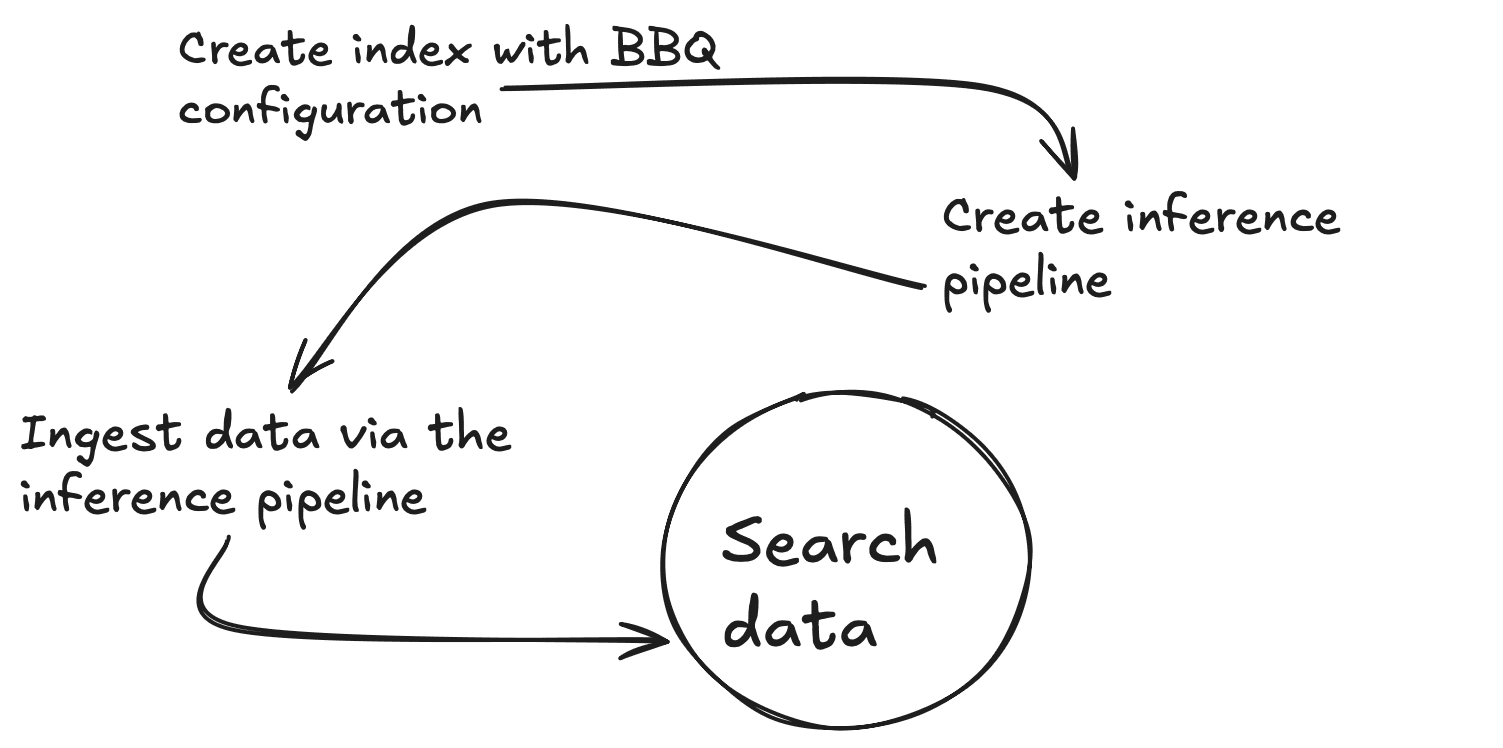
Para simplificar este blog, empleará funciones integradas cuando estén disponibles. En este caso, tienes el modelo de incrustación de vectores .multilingual-e5-small que se ejecutará directamente dentro de Elasticsearch en un nodo de aprendizaje automático. Tenga en cuenta que puede reemplazar el modelo text_embedding con el incrustador de su elección (OpenAI, Google AI Studio, Cohere y muchos más). Si su modelo preferido aún no está integrado, también puede traer sus propias incrustaciones de vectores densos).
En primer lugar, deberá crear un punto de enlace de inferencia para generar vectores para un fragmento de texto determinado. Ejecutarás todos estos comandos desde la consola de herramientas de desarrollo de Kibana. Este comando descargará el .multilingual-e5-small. Si aún no existe, configurará su punto final; Esto puede tardar un minuto en ejecutar. Puede ver la salida esperada en el archivo 01-create-an-inference-endpoint-output.json en la carpeta Salidas.
Una vez que esto regresó, su modelo se configurará y podrá probar que el modelo funciona como se espera con el siguiente comando. Puede ver el resultado esperado en el archivo 02-embed-text-output.json en la carpeta Salidas.
Si tiene problemas relacionados con el modelo capacitado que no se asigna a ningún nodo, es posible que deba iniciar el modelo manualmente.
Ahora vamos a crear una nueva asignación con 2 propiedades, un campo de texto estándar (my_field) y un campo vectorial denso (my_vector) con 384 dimensiones para que coincida con la salida del modelo de incrustación. También anulará el index_options.type to bbq_hnsw. Puede ver el resultado esperado en el archivo 03-create-byte-qauntized-index-output.json en la carpeta Salidas.
Para cerciorarte de que Elasticsearch genere tus vectores, puedes usar una canalización de ingesta. Esta canalización requerirá 3 cosas: el punto final, (model_id), el input_field para el que desea crear vectores y el output_field en el que almacenar esos vectores. El primer comando siguiente creará una canalización de ingesta de inferencia, que usa el servicio de inferencia en segundo plano, y el segundo probará que la canalización funciona correctamente. Puede ver la salida esperada en el archivo 04-create-and-simulate-ingest-pipeline-output.json en la carpeta Salidas.
Ahora está listo para agregar algunos documentos con los primeros 2 comandos a continuación y para probar que sus búsquedas funcionan con el 3er comando. Puede desproteger el resultado esperado en el archivo 05-bbq-index-output.json en la carpeta Salidas.
Como se recomienda en esta publicación, se recomienda volver a puntuar y sobremuestrear cuando se escala a cantidades no triviales de datos porque ayudan a mantener una alta precisión de recuperación mientras se benefician de los beneficios de la compresión. A partir de la versión 8.18 de Elasticsearch, puedes hacerlo de esta manera usando rescore_vector. La salida esperada se encuentra en el archivo 06-bbq-search-8-18-output.json en la carpeta Outputs.
¿Cómo se comparan estos puntajes con los que obtendría por los datos sin procesar? Si vuelves a hacer todo lo anterior pero con index_options.type: hnsw, verás que los puntajes son muy comparables. Puede ver el resultado esperado en el archivo 07-raw-vector-output.json en la carpeta Salidas.
Números aproximados en las relaciones de compresión
Los requisitos de almacenamiento y memoria pueden convertir rápidamente en un desafío importante cuando se trabaja con la búsqueda vectorial. El siguiente desglose ilustra cómo las diferentes técnicas de cuantificación reducen significativamente la huella de memoria de los datos vectoriales.
| Vectores (V) | Dimensiones (D) | sin procesar (V x P x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0.5 + 4)) | asado (V x (D x 0.125 + 4)) |
|---|---|---|---|---|---|
| 10,000,000 | 384 | 14,31 GB | 3,61 GB | 1,83 GB | 0,58 GB |
| 50,000,000 | 384 | 71,53 GB | 18,07 GB | 9,13 GB | 2,89 GB |
| 100,000,000 | 384 | 143,05 GB | 36,14 GB | 18,25 GB | 5,77 GB |
Conclusión
BBQ es una optimización que puede aplicar a sus datos vectoriales para la compresión sin sacrificar la precisión. Funciona convirtiendo vectores en bits, lo que le permite buscar los datos de manera efectiva y le permite escalar sus flujos de trabajo de IA para acelerar las búsquedas y optimizar el almacenamiento de datos.
Aprendizaje adicional
Si está interesado en obtener más información sobre el asado, cerciorar de consultar los siguientes recursos:
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.