Como todos hoy en día, aquí en Elastic apostamos por completo a Chat, Agents y RAG. En el departamento de búsqueda, estuvimos trabajando recientemente en un Constructor de Agentes y un Registro de Herramientas, todo con la intención de hacer que sea trivial "chatear" con tus datos en Elasticsearch.
Lee el blog Construiendo flujos de trabajo agentes con IA con Elasticsearch para más información sobre la "visión global" de ese esfuerzo, o Tu primer agente elástico: de una sola consulta a un chat impulsado por IA para una introducción más práctica.
Sin embargo, en este blog vamos a hacer un poco de zoom para ver una de las primeras cosas que ocurren cuando empiezas a charlar y para guiarte por algunas de las mejoras recientes que hicimos.
¿Qué está pasando aquí?

Cuando chateas con tus datos de Elasticsearch, nuestro agente de IA predeterminado te guía a través de este flujo estándar:
- Revisa el enunciado.
- Identifica qué índice es probable que contenga las respuestas a esa pregunta.
- Genera una consulta para ese índice, basada en el prompt.
- Busca en ese índice con esa consulta.
- Sintetiza los resultados.
- ¿Pueden los resultados responder al prompt? Si es así, responde. Si no, repite, pero prueba algo diferente.
Esto no debería parecer demasiado novedoso: es simplemente Generación Aumentada por Recuperación (RAG). Y como era de esperar, la calidad de tus respuestas depende mucho de la relevancia de tus resultados iniciales. Así que, mientras trabajamos en mejorar la calidad de nuestra respuesta, estuvimos prestando mucha atención a las consultas que generábamos en el paso 3 y ejecutábamos en el paso 4. Y notamos un patrón interesante.
A menudo, cuando nuestras primeras respuestas eran "malas", no era porque hicimos una consulta mala. Fue porque elegimos el índice equivocado para hacer la consulta. Los pasos 3 y 4 normalmente no eran nuestro problema, sino el paso 2.
¿Qué estábamos haciendo?
Nuestra implementación inicial fue sencilla. Creamos una herramienta (llamada index_explorer) que efectivamente hacía un _cat/indices para listar todos los índices disponibles y luego pedir al LLM que identificara cuál de estos índices era el mejor para el mensaje/pregunta/prompt del usuario. Puedes ver esta implementación original aquí.
¿Qué tal funcionaba? ¡No estábamos seguros! Teníamos ejemplos claros de que no funcionaba bien, pero nuestro verdadero primer reto fue cuantificar nuestro estado actual.
Establecimiento de una línea base
Todo empieza con los datos
Lo que necesitábamos era un conjunto de datos dorado para medir la eficacia de una herramienta a la hora de seleccionar el índice adecuado dado un prompt del usuario y un conjunto preexistente de índices. Y no disponíamos de un conjunto de datos así. Así que generamos uno.
Agradecimiento: Esto no es "buena práctica", lo sabemos. Pero a veces, es mejor seguir adelante que abandonar la bicicleta. Progreso, perfección SIMPLE.
Generamos índices semilla para varios dominios diferentes usando este prompt. Luego, para cada dominio generado, generamos algunos índices más usando este prompt (el objetivo aquí es sembrar confusión para el LLM con negativos duros y ejemplos difíciles de clasificar). Después, editamos manualmente cada índice generado y sus descripciones. Finalmente, generamos consultas de prueba usando este prompt. Esto nos dejó con datos de muestra como:

y casos de prueba como:
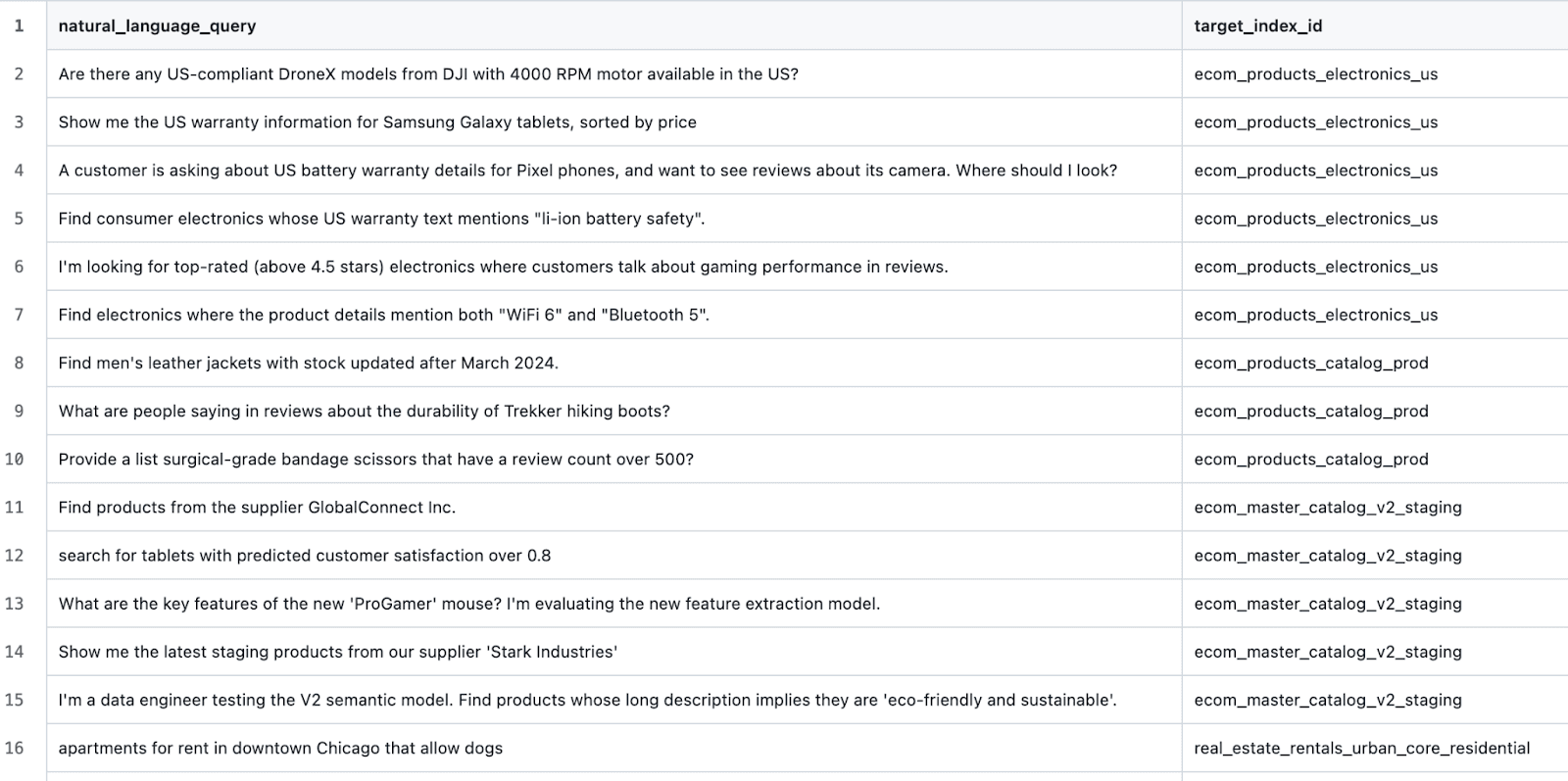
Elaboración de un arnés de prueba
El proceso a partir de aquí fue muy sencillo. Crea un script para una herramienta que pueda:
- Establece una hoja limpia con un clúster objetivo de Elasticsearch.
- Crea todos los índices definidos en el conjunto de datos objetivo.
- Para cada escenario de prueba, ejecuta la herramienta i
ndex_explorer(prácticamente tenemos una API de Herramienta de Ejecución). - Comparar el índice de resultados con el índice esperado y capturar el resultado.
- Luego de terminar todos los escenarios de prueba, tabula los resultados.
La encuesta dice...
Los resultados iniciales fueron, como era de esperar, mediocres.
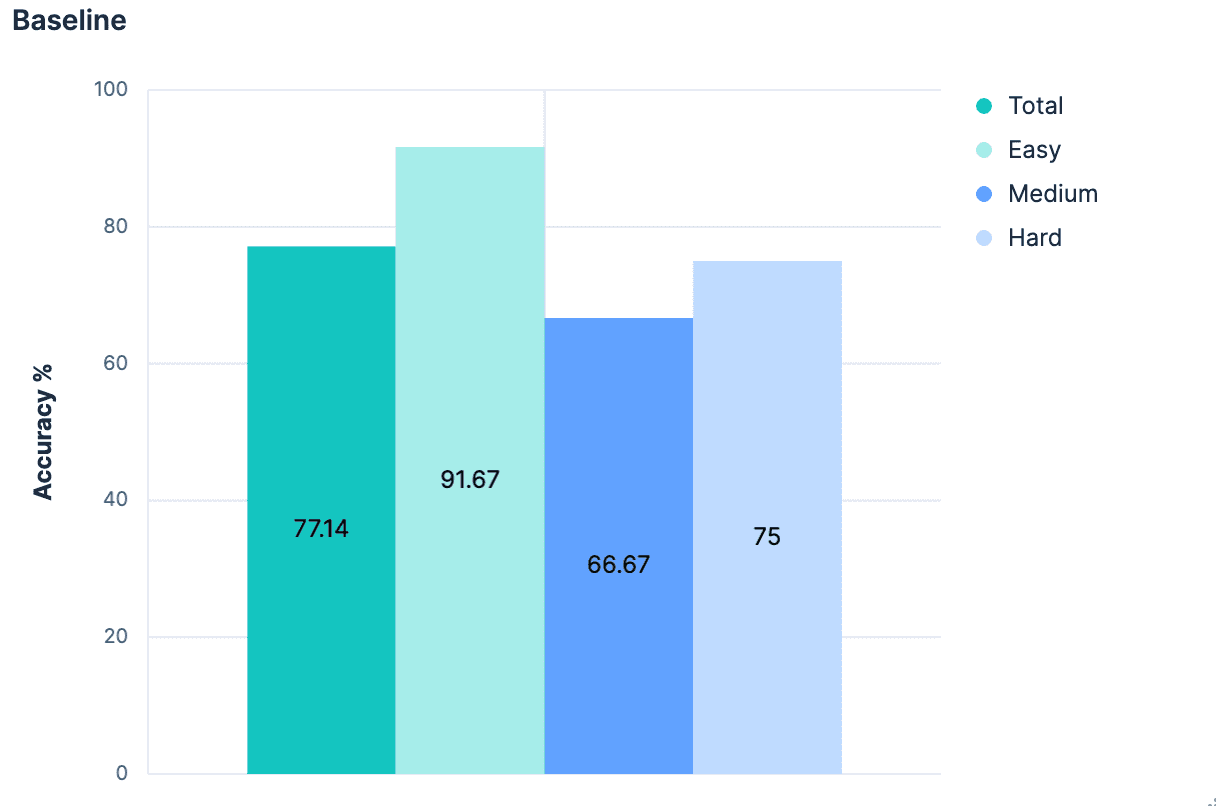
En general, un 77,14% de precisión para identificar el índice adecuado. Y esto fue en un escenario "mejor escenario", donde todos los índices tienen buenos nombres semánticamente significativos. Cualquiera que hizo alguna vez un 'PUT test2/_doc/foo {...}' sabe que tus índices no siempre tienen nombres significativos.
Así que tenemos una línea de base, y muestra mucho margen de mejora. ¡Ahora era hora de hacer algo de ciencia! 🧪
Experimentación
Hipótesis 1: Los mapeos ayudarán
El objetivo aquí es identificar un índice que contenga datos relevantes para la consigna original. Y la parte de un índice que mejor describe los datos que contiene son los mapeos del índice. Incluso sin obtener muestras del contenido del índice, saber que el índice tiene un campo de precios de tipo doble implica que los datos representan algo que se puede vender. Un campo autor de texto tipográfico implica algunos datos de lenguaje no estructurados. Ambos juntos podrían implicar que los datos son libros/relatos/poemas. Hay muchas pistas semánticas que podemos derivar simplemente conociendo las propiedades de un índice. Así que en una sucursal local, ajusté nuestro '.index_explorer' herramienta para enviar los mapeos completos de un índice (junto con su nombre) al LLM para tomar su decisión.
El resultado (de los registros de Kibana):
Los autores iniciales de la herramienta ya lo habían anticipado. Aunque el mapeo de un índice es una mina de oro de información, también es un bloque bastante extenso de JSON. Y en un escenario realista donde comparas numerosos índices (nuestro conjunto de datos de evaluación define 20), estos blobs JSON suman. Así que queremos dar al LLM más contexto para su decisión que solo los nombres de índices de todas las opciones, pero no tanto como los mapeos completos de cada una.
Hipótesis 2: Mapeos "aplanados" (listas de campos) como compromiso
Partimos de la suposición de que los creadores de índices usarán nombres de índices semánticamente significativos. ¿Y si extendemos esa suposición también a los nombres de campos? Nuestro experimento anterior falló porque el mapeo JSON incluye MUCHOS metadatos y datos basurales y un estándar estándar.
El bloque anterior, por ejemplo, tiene 236 caracteres y define solo un campo en un mapeo de Elasticsearch. Mientras que la cadena "description_text" tiene solo 16 caracteres. Eso supone casi un aumento de 15 veces en el recuento de caracteres, sin una mejora semántica significativa en la descripción de lo que ese campo implica sobre los datos disponibles. ¿Y si recogiéramos los mapeos de todos los índices, pero antes de enviarlos al LLM, los "aplanáramos" solo en una lista con sus nombres de campo?
Lo probamos.

¡Esto es genial! Mejoras en todos los ámbitos. ¿Pero podríamos hacerlo mejor?
Hipótesis 3: Descripciones en el _meta de cartografía
Si solo los nombres de campos sin contexto adicional causaran un salto tan grande, ¡supongo que agregar un contexto sustancial sería aún mejor! No es necesariamente convencional que cada índice tenga una descripción adjunta, pero sí es posible agregar metadatos a nivel de índice de cualquier tipo al objeto _meta del mapeo. Volvimos a nuestros índices generados y agregamos descripciones para cada índice de nuestro conjunto de datos. Mientras las descripciones no sean demasiado largas, deberían usar menos tokens que el mapeo completo y proporcionar una visión significativamente mejor sobre qué datos se incluyen en el índice. Nuestro experimento validó esta hipótesis.
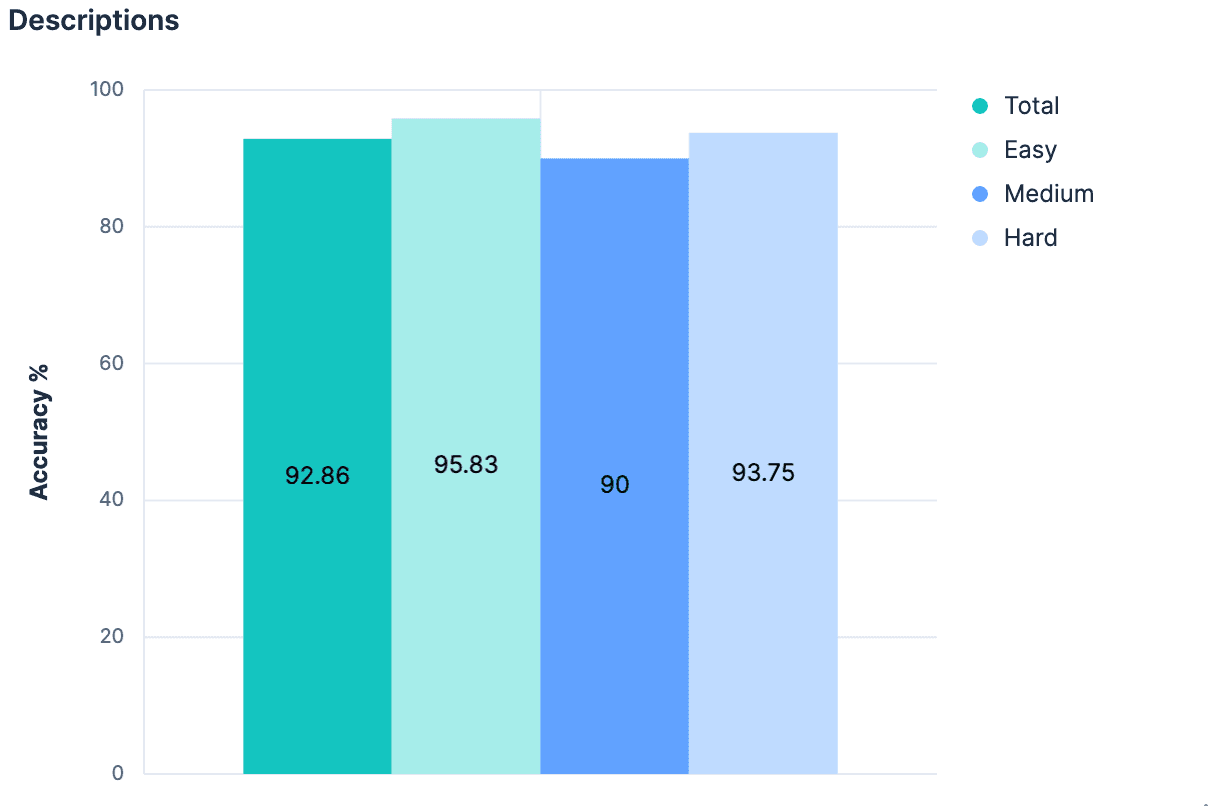
Una mejora modesta, y ahora somos >90% precisos en todos los aspectos.
Hipótesis 4: La suma es mayor que sus partes
Los nombres de campos aumentaron nuestros resultados. Las descripciones aumentaron nuestros resultados. Así que, empleando tanto descripciones COMO nombres de campos debería dar resultados aún mejores, ¿no?
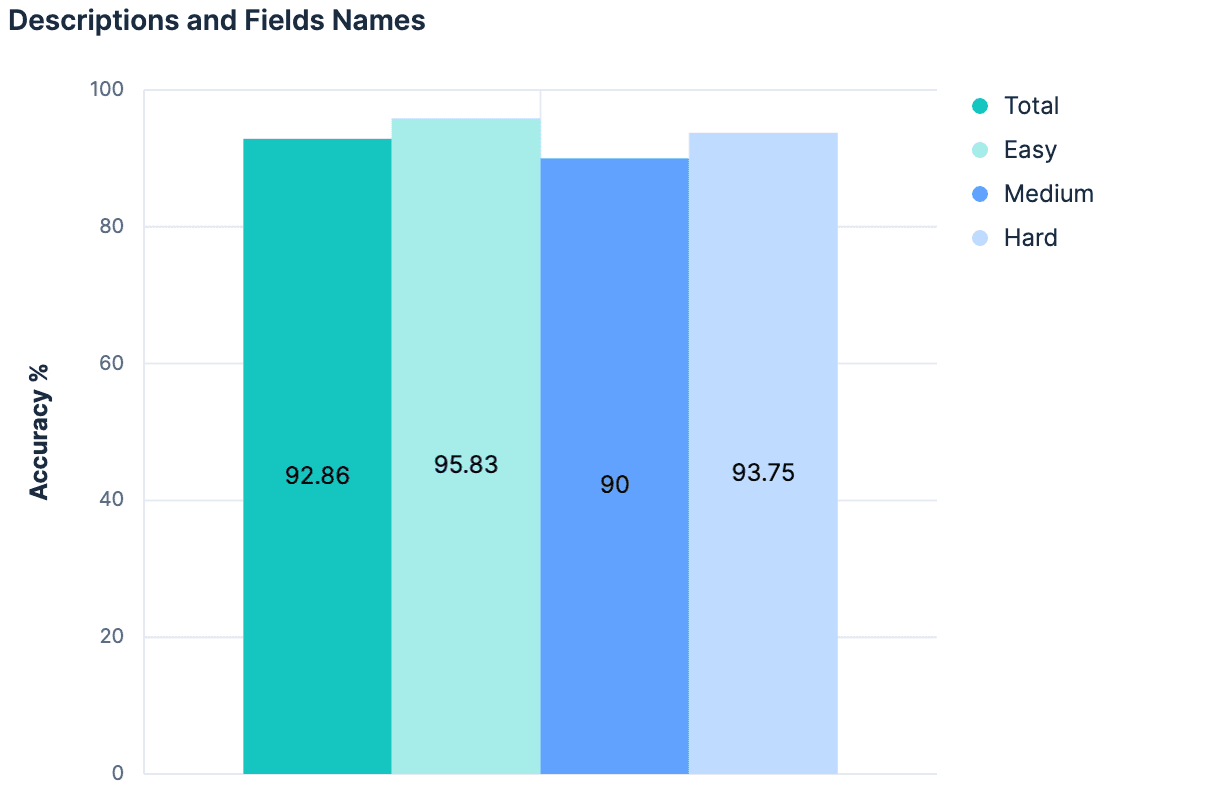
Los datos decían "no" (sin cambios respecto al experimento anterior). La teoría principal aquí era que, dado que las descripciones se generaron a partir de los campos índice/mapeos desde el principio, no hay suficiente información diferente entre estos dos contextos para ayudar a agregar algo "nuevo" al combinarlos. Además, la carga útil que enviamos para nuestros 20 índices de prueba está creciendo bastante. El hilo de pensamiento que seguimos hasta ahora no es escalable. De hecho, hay buenas razones para creer que ninguno de nuestros experimentos hasta ahora funcionaría en clústeres de Elasticsearch donde hay cientos o miles de índices para elegir. Cualquier enfoque que aumente linealmente el tamaño del mensaje enviado al LLM a medida que aumenta el número total de índices probablemente no será una estrategia generalizable.
Lo que realmente necesitamos es un enfoque que nos ayude a reducir un gran número de candidatos a las opciones más relevantes...
Lo que tenemos aquí es un problema de búsqueda.
Hipótesis 5: Selección mediante búsqueda semántica
Si el nombre de un índice tiene significado semántico, entonces puede almacenar como un vector y buscar semánticamente.
Si los nombres de campos de un índice tienen significado semántico, entonces pueden almacenar como vectores y buscar semánticamente.
Si un índice tiene una descripción con significado semántico, también puede almacenar como vector y buscar semánticamente.
Hoy en día, los índices de Elasticsearch no hacen que ninguna de esta información sea buscable (¡quizá deberíamos!), pero fue bastante trivial improvisar algo que pudiera superar esa brecha. Usando el framework de conectores de Elastic, construí un conector que generaba un documento para cada índice de un clúster. Los documentos de salida serían algo así:
Envié estos documentos a un nuevo índice donde definí manualmente el mapeo como:
Esto crea un solo campo semantic_content, donde todos los demás campos con significado semántico se fragmentan e indexan. Buscar en este índice se vuelve trivial, simplemente:
La herramienta de index_explorer modificada es ahora mucho más rápida, ya que no necesita hacer una solicitud a un LLM, sino que puede aplicar una única incrustación para la consulta dada y realizar una operación eficiente de búsqueda vectorial. Tomando el resultado más alto como índice seleccionado, obtuvimos resultados de:

Este enfoque es escalable. Este enfoque es eficiente. Pero este enfoque es apenas mejor que nuestra línea base. Sin embargo, esto no es sorprendente; El enfoque de búsqueda aquí es increíblemente ingenuo. No hay matices. No hay reconocimiento de que el nombre y la descripción de un índice deban tener más peso que un nombre arbitrario de campo que contiene el índice. No hay posibilidad de ponderar coincidencias léxicas exactas sobre coincidencias sinónimas. Sin embargo, construir una consulta muy matizada requeriría asumir MUCHO sobre los datos disponibles. Hasta ahora, ya hicimos algunas grandes suposiciones sobre que los nombres de índices y campos tienen significado semántico, pero tendríamos que ir un paso más allá y empezar a suponer cuánto significado tienen y cómo se relacionan entre sí. Sin hacerlo, probablemente no podamos identificar de forma fiable la mejor coincidencia como nuestro resultado principal, pero es más probable que digamos que la mejor coincidencia está en algún lugar de los primeros N resultados. Necesitamos algo que pueda consumir información semántica en el contexto en el que existe, comparando con otra entidad que pueda representar a sí misma de manera semánticamente distinta, y juzgar entre ellas. Como un LLM.
Hipótesis 6: Reducción de conjuntos candidatos
Hubo bastantes experimentos más que voy a pasar por alto, pero el avance clave fue dejar de lado el deseo de elegir la mejor coincidencia únicamente a partir de una búsqueda semántica, y en su lugar emplear la búsqueda semántica como filtro para eliminar índices irrelevantes de la consideración del LLM. Combinamos Retrievers Lineales, Búsqueda Híbrida con RRF y semantic_text para nuestra búsqueda, limitando los resultados a los 5 principales índices de coincidencia.
Luego, para cada coincidencia, agregamos el nombre, la descripción y los nombres de campos del índice a un mensaje para el LLM. Los resultados fueron fantásticos:
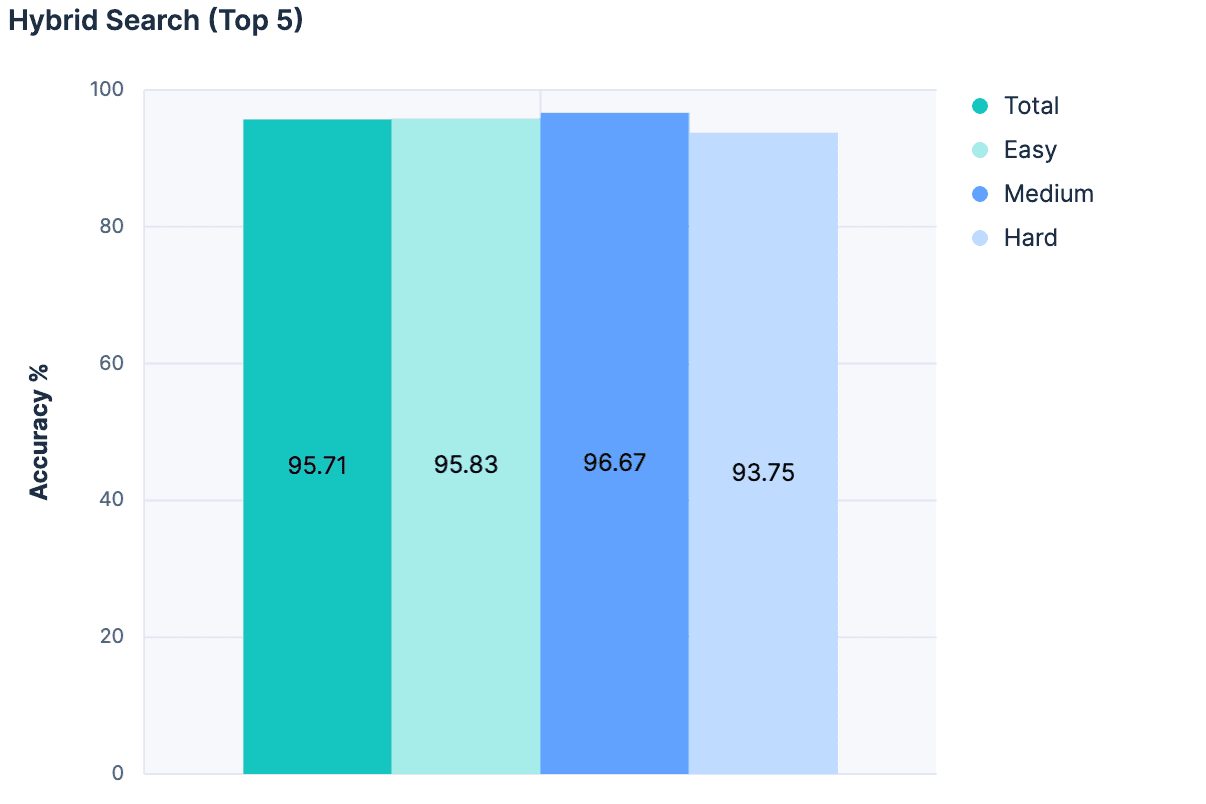
¡La mayor precisión de cualquier experimento hasta ahora! Y como este enfoque no aumenta el tamaño del mensaje proporcional al número total de índices, es mucho más escalable.
Resultados
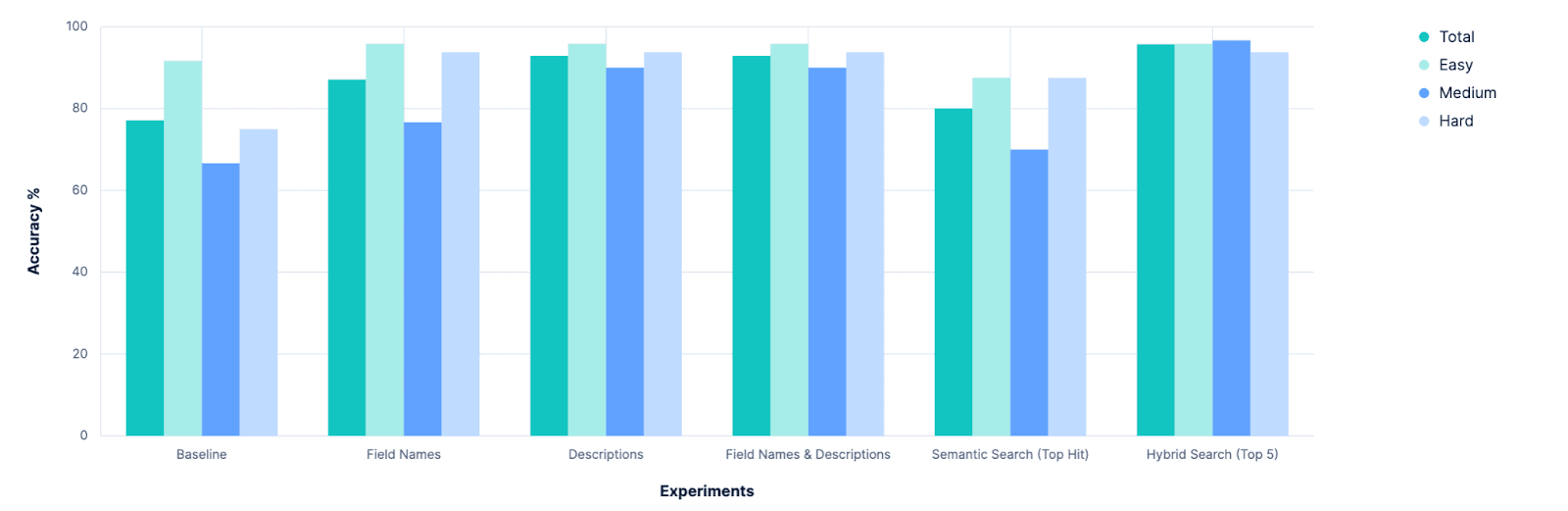
El primer resultado claro fue que nuestra línea base puede mejorar. Esto parece obvio en retrospectiva, pero antes de que comenzara la experimentación, hubo un debate serio sobre si deberíamos abandonar por completo nuestra herramienta de index_explorer y confiar en la configuración explícita del usuario para limitar el espacio de búsqueda. Aunque sigue siendo una opción viable y válida, esta investigación muestra que existen caminos prometedores para automatizar la selección de índices cuando dichas entradas de usuario no están disponibles.
El siguiente resultado claro fue que simplemente agregar más personajes descriptivos al problema tiene rendimientos decrecientes. Antes de esta investigación, debatimos si deberíamos invertir en ampliar la capacidad de Elasticsearch para almacenar metadatos a nivel de campo. Hoy en día, estos valores de meta están limitados a 50 caracteres, y se asumía que tendríamos que aumentar este valor para poder obtener una comprensión semántica de nuestros campos. Claramente no es así, y el LLM parece funcionar bastante bien solo con los nombres de campos. Puede que investiguemos esto más adelante, pero ya no nos parece urgente.
Por el contrario, esto dio evidencia clara de la importancia de tener metadatos de índice "buscables". Para estos experimentos, hackeamos un índice de índices. Pero esto es algo que podríamos explorar integrando directamente en Elasticsearch, creando APIs para gestionar, o al menos estableciendo una convención en torno a ella. Estaremos valorando nuestras opciones y hablando internamente, así que estad atentos.
Por último, este esfuerzo confirmó el valor de que nos tomemos nuestro tiempo para experimentar y tomar decisiones basadas en datos. De hecho, nos ayudó a reafirmar que nuestro producto Agent Builder va a necesitar capacidades robustas de evaluación dentro del producto. Si necesitamos construir un arnés de pruebas completo solo para una herramienta que selecciona índices, nuestros clientes necesitarán absolutamente formas de evaluar cualitativamente sus herramientas personalizadas mientras hacen ajustes iterativos.
Estoy deseando ver qué construiremos, ¡y espero que tú también!
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

26 de marzo de 2026
Anuncio de los permisos de solo lectura para los dashboards de Kibana
Presentamos los dashboards de solo lectura en Kibana, que ofrecen a los creadores de dashboards controles granulares para compartir y mantener los resultados precisos y protegidos de cambios no deseados.