Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Elasticsearch DiskBBQ already speeds up Better Binary Quantization (BBQ) vector operations through block-based layouts. Elasticsearch 9.4 adds native single instruction, multiple data (SIMD) kernels that improve throughput to almost 3x from single vector operations. Here’s how the format works.
DiskBBQ reads vector bytes directly from memory-mapped index files using dense, sequential block layouts. This keeps heap usage low and allows the engine to operate on datasets much larger than available RAM. Within these block layouts, DiskBBQ encodes doc ID blocks to reduce disk space while keeping decoding costs low. Here we walk through the posting list layout, doc ID packing modes, and why bulk scoring is fast.
How DiskBBQ stores vector posting lists on disk
At the start of each posting list, we write a centroid score correction, the vector count, and the overall doc ID encoding method. Then we write doc IDs and vectors in subsequent blocks. The blocks and the internals are in ascending doc ID order. This respects segment doc ID order, which preserves index sort order. Filters aligned with that order are more likely to include or exclude whole blocks at a time. After the doc IDs, we store the quantized vector bytes and then all the corrections for the vectors in that block.

The layout of a posting list. Starting with a metadata header and then each block. The blocks have bulk_size doc IDs, and then quantized vector bytes, followed up by the quantized correction values.
How DiskBBQ compresses doc IDs to reduce disk space
To ensure fast decoding of doc ID blocks, DiskBBQ encodes every block with the same encoding format. DiskBBQ computes the required encoding for each block and then uses the most space-expensive encoding required by any block for the posting list, which is used for all the document blocks. At the time of writing, there are five compression options for doc ID storage. Each option starts with a full delta encoding of the doc ID values. Then one of the following encoding types is applied on top of the delta encoded doc IDs.
| Encoding type | Condition | Bytes saved (example) |
|---|---|---|
| Continuous | IDs are sequential (max−min+1 == len) | 16 bytes → 4 bytes |
| Delta 16 | All deltas fit in 16 bits | 64 bytes → 33 bytes |
| 21 bits per value | Values fit in 21 bits | 12 bytes → 8 bytes |
| 24 bits per value | Values fit in 24 bits | 64 bytes → 48 bytes |
| Fallback (full int) | Any other case | No reduction |
The most efficient is continuous. This is used when max(doc_block) - min(doc_block) + 1 == len(doc_block), meaning, the delta encoding only needs to worry about storing the minimum value, and the doc IDs can be reconstituted by adding one to each subsequent value. An example would be the IDs [4858192, 4858193, 4858194, 4858195]. Instead of writing four individual int values, which is 16 bytes, we only need to write a single value: 4858192.

Continuous encoding; only needs to write a single integer.
Next is delta 16. It applies when every delta fits in 16 bits, which can be stored in two bytes. Assume we have doc_ids = [1000, 1003, 1010, 1020, 1041, 1055, 1070, 1090, 1100, 1125, 1200, 1300, 2000, 4000, 16000, 66000]. This then means our min = 1000 and results in deltas = [0, 3, 10, 20, 41, 55, 70, 90, 100, 125, 200, 300, 1000, 3000, 15000, 65000]. These 16 deltas can be packed into eight int32 values (32 bytes), plus the min value, cutting the byte usage by almost 2x.

Delta 16; writes the minimum value and then packs two 16-bit deltas into each 32-bit integer.
The next step up is 21 bits per value. This results in a fairly complex scheme where each triplet set of values is compressed into 64 bit values and a tail of 3 bytes for any remaining values. A concrete example would be doc_ids=[1000, 70000, 140000], which get compressed into a single 64 bit value doc0 | (doc1 << 21) | (doc2 << 42), the end result being three raw integer values, which comprise 12 bytes, get compressed into 8 bytes.

Twenty-one bits per value, a fairly complex scheme combining triplet compressed 64-bit values with a 3-byte tail.
The second-to-last compression option packs integer values that require at most 24 bits. Since an int requires 32 bits of space, 24 leaves an entire byte completely unused. We cannot leave a single byte of real estate to waste. We want to fully fill as many bytes as we can, so this scheme compresses by filling in that empty byte. For example, docs_ids = [1000, 70000, 140000, 300000, 500000, 800000, 1000000, 1300000, 1600000, 1900000, 2200000, 3000000, 4000000, 8000000, 12000000, 16000000] will compress the final four integer values into the “free byte” in the prior integers, thus storing 16 integers, which usually cost 64 bytes, into 48 bytes.
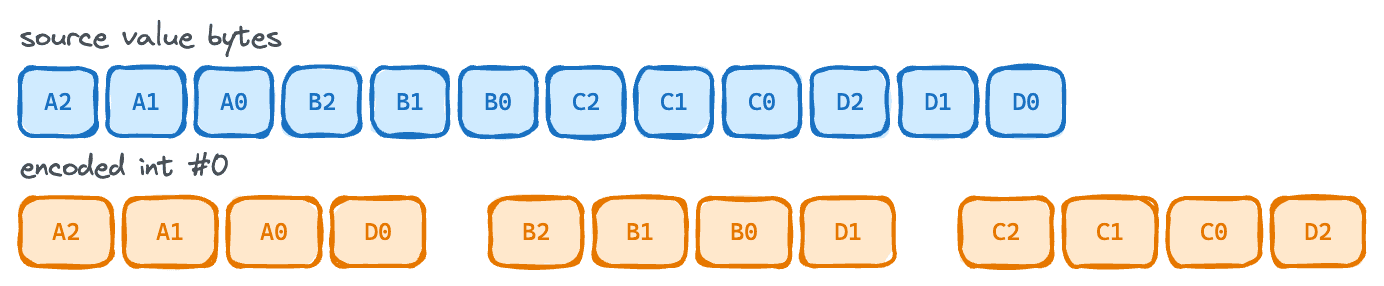
This shows an example 24 bits per value where the final set of bytes is packed in the first. It’s taking advantage of that free byte of real estate.
The final option is the fallback. DiskBBQ will store each doc ID as a full fidelity integer, providing no disk reduction. Given that the doc ID values are delta encoded before compression, the fallback is exceptionally rare.
Why DiskBBQ bulk scoring is faster: SIMD and CPU cache saturation
Storing the vectors in blocks allows SIMD-optimized bulk scoring. This keeps CPU cache lines saturated with vector bytes and allows quantization corrections to be applied with SIMD-optimized kernels. If vectors were stored inline with their corrections, after each vector score, the corrections would have to be applied. This loses valuable throughput and any opportunity for optimizing the correction application.
Here’s a benchmark showing how the throughput improves with different optimizations. This is a JMH benchmark run on an M1Max MacBook with Java 25. The vector dimensions were 1024, and each operation in the benchmark was 10 queries executed over 10 blocks of 32 vectors.
Here’s a description of each of the benchmarks run above:
- Float32Scalar: This is the pure JVM doing floating point operations. No hand-optimized SIMD.
- Float32PanamaVector: Here some SIMD-optimized code paths are actually written and used.
- BBQIndividual: These are the individual bit-wise BBQ operations. Each vector is taken onto the JVM heap individually and scored and corrected.
- BBQBulkPartial: This is off-heap bulk scoring with Panama Vector operations reading directly from MMAP’d file segments. The corrections are then applied on the JVM Heap.
- BBQBULK: This is full off-heap bulk scoring where vectors and corrections are SIMD-optimized Java Vector API functions reading directly from MMAP files.
- BBQBulkNative: This is what’s in Elasticsearch 9.4. Full native bulk vector operations reading bytes directly from the index files.
These results show the evolution of throughput, starting with the bare minimum of individual floating point operations. Switching to SIMD (hand-optimized with the Vector API) for floating point increases throughput ~3x, but even then, it's slower than the auto-vectorized individual bit-wise operations in BBQ. Then, the switch to bulk scoring almost increases BBQ throughput by 2x. Adding our new optimized native SIMD kernels in Elasticsearch 9.4, we get yet another significant improvement, adding up to almost 3x improvement from individual bitwise scoring and an incredible 66x improvement over float32 operations.
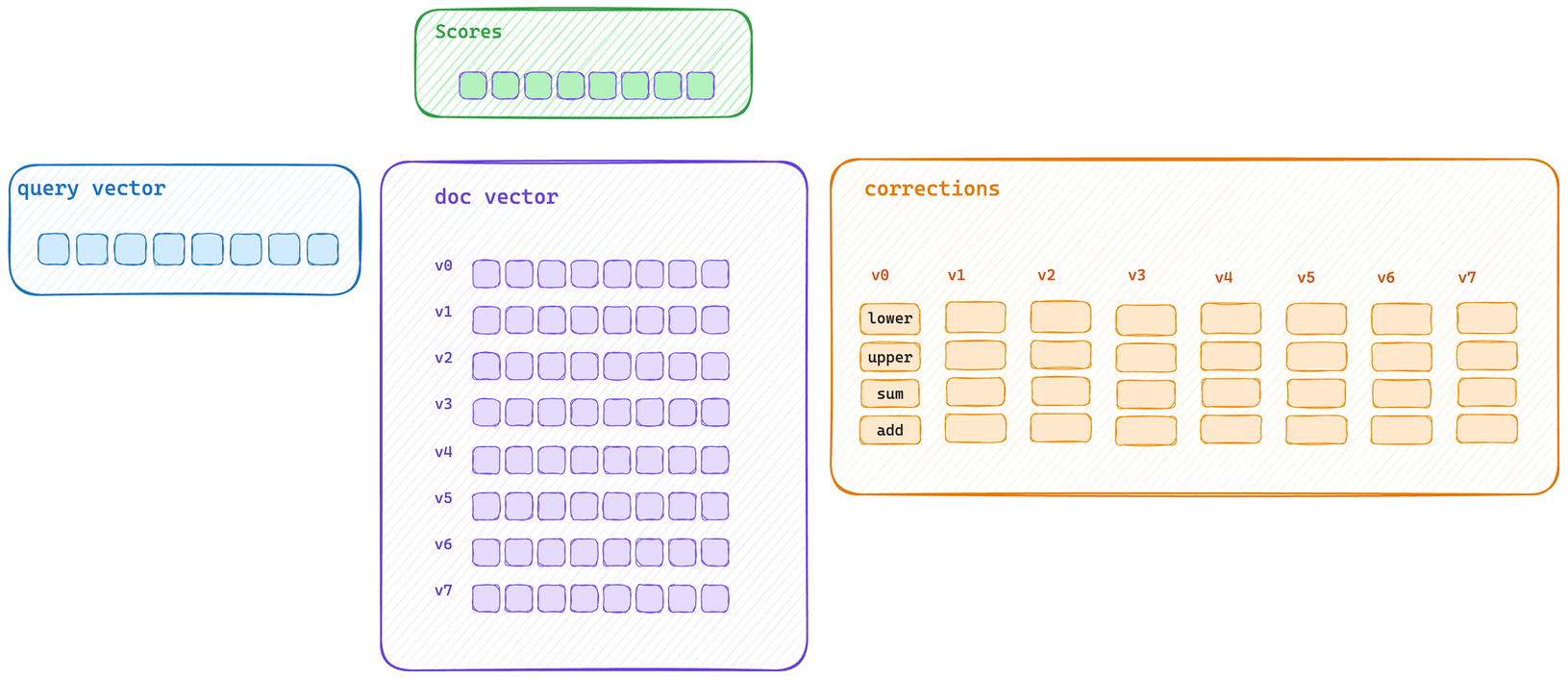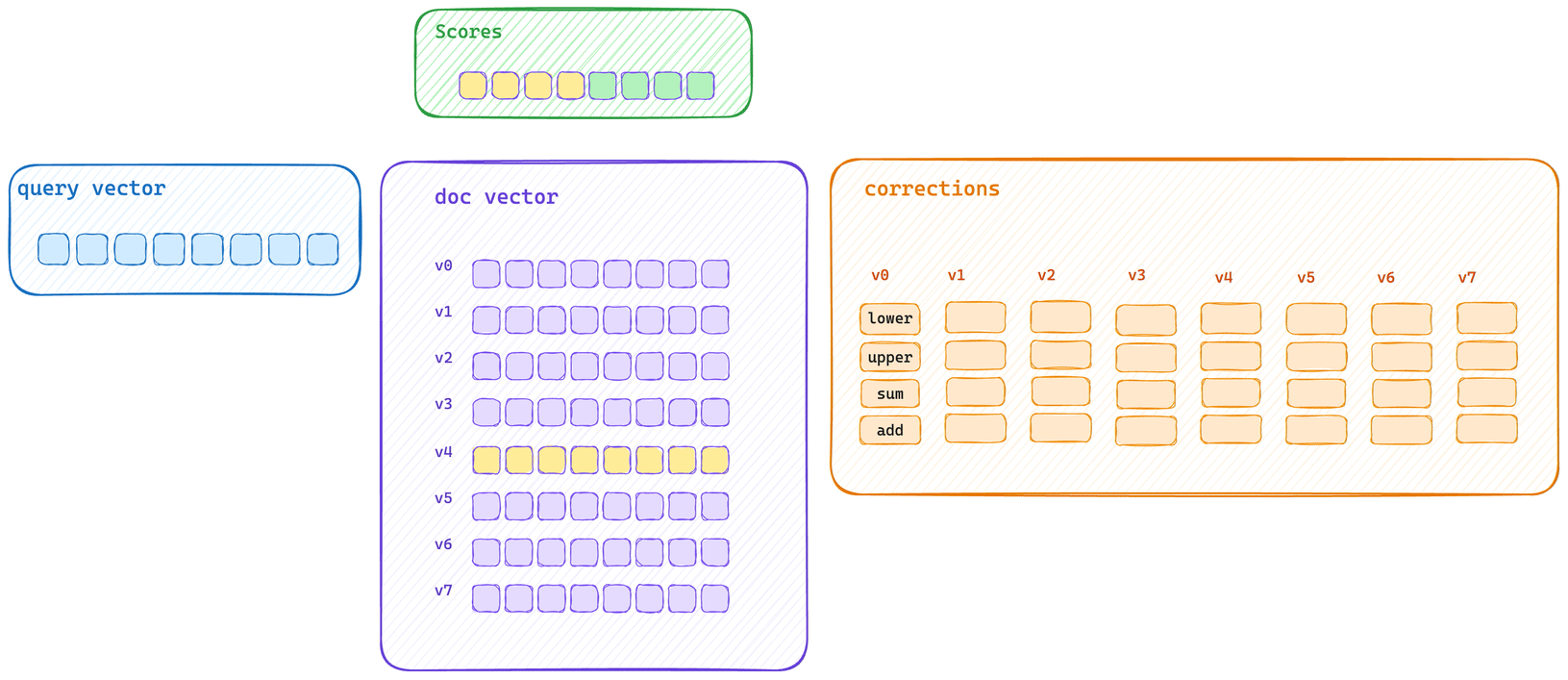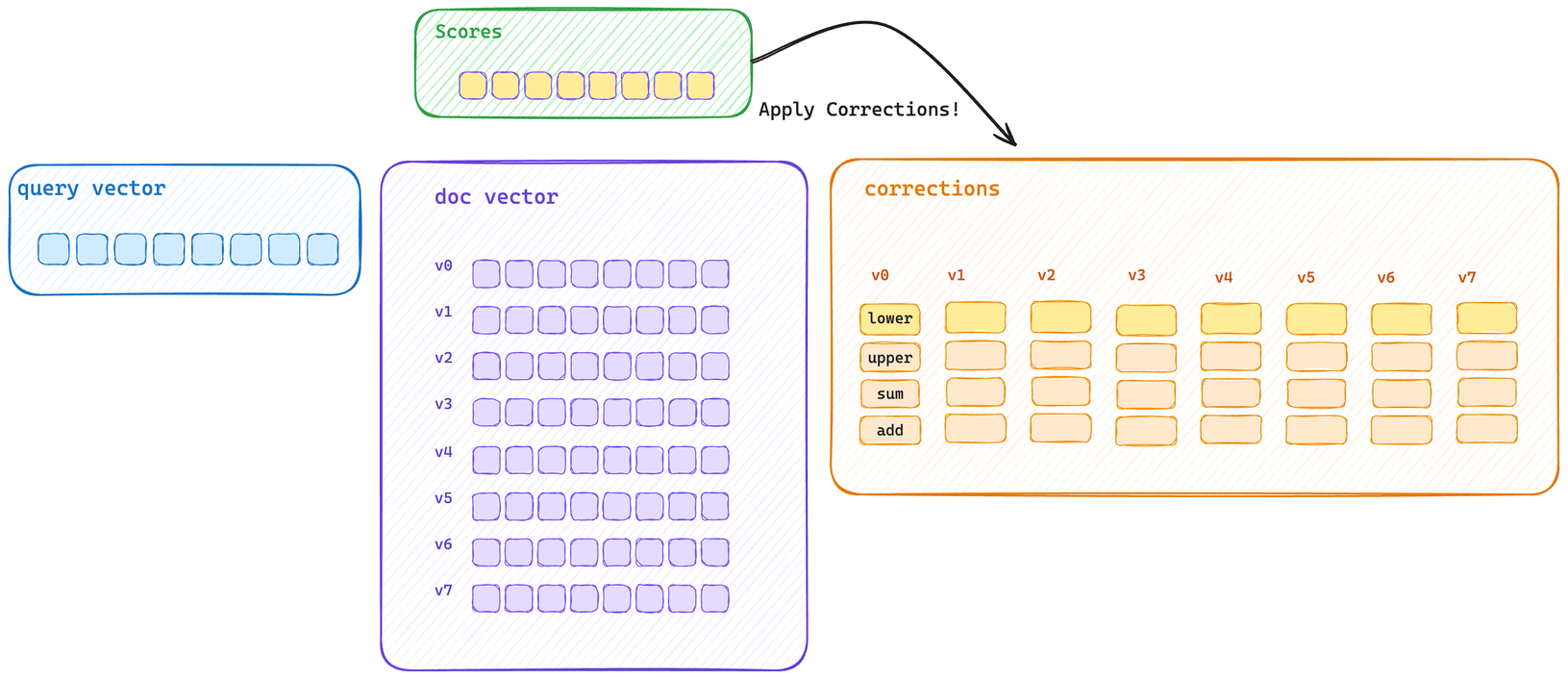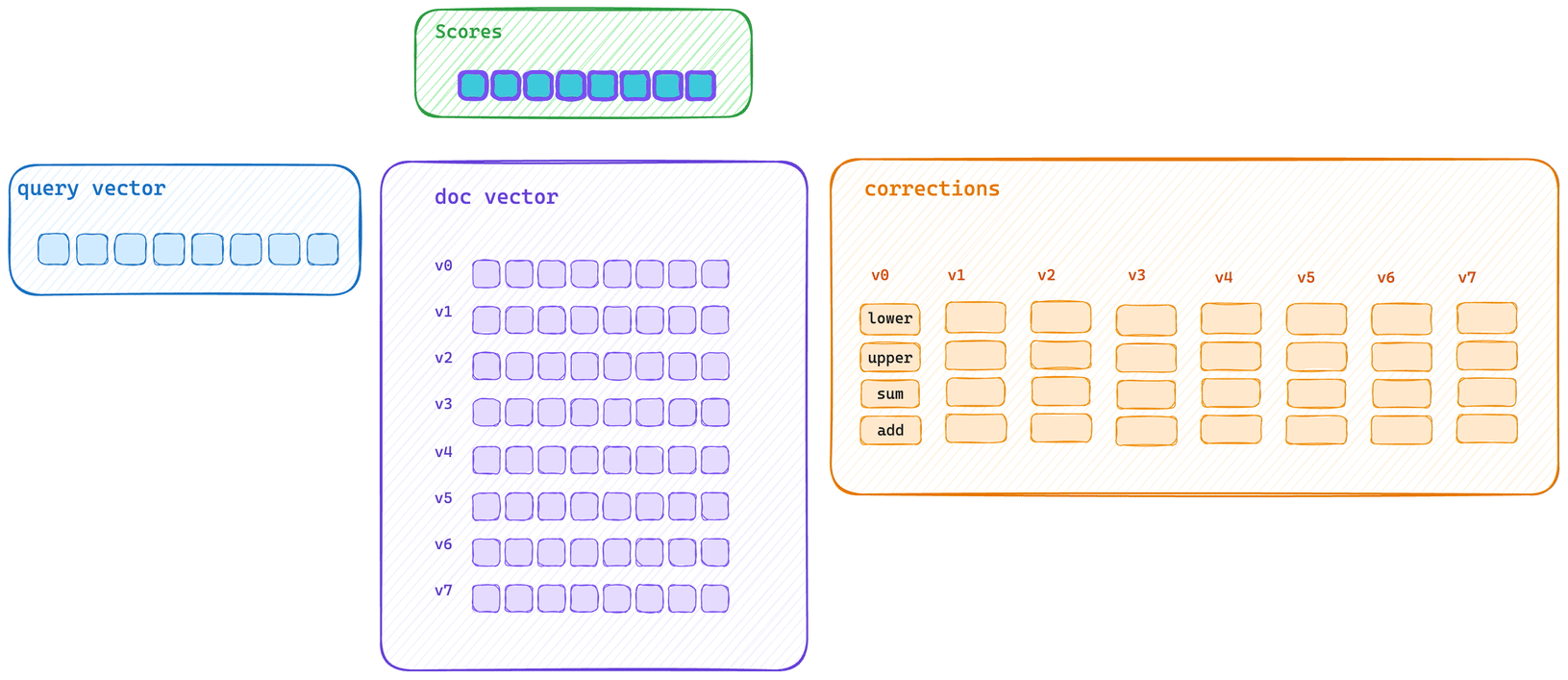
This shows the typical bulk scoring path. The query vector calculates initial score information for every vector in the block and then applies each correction with an optimized SIMD block operation.
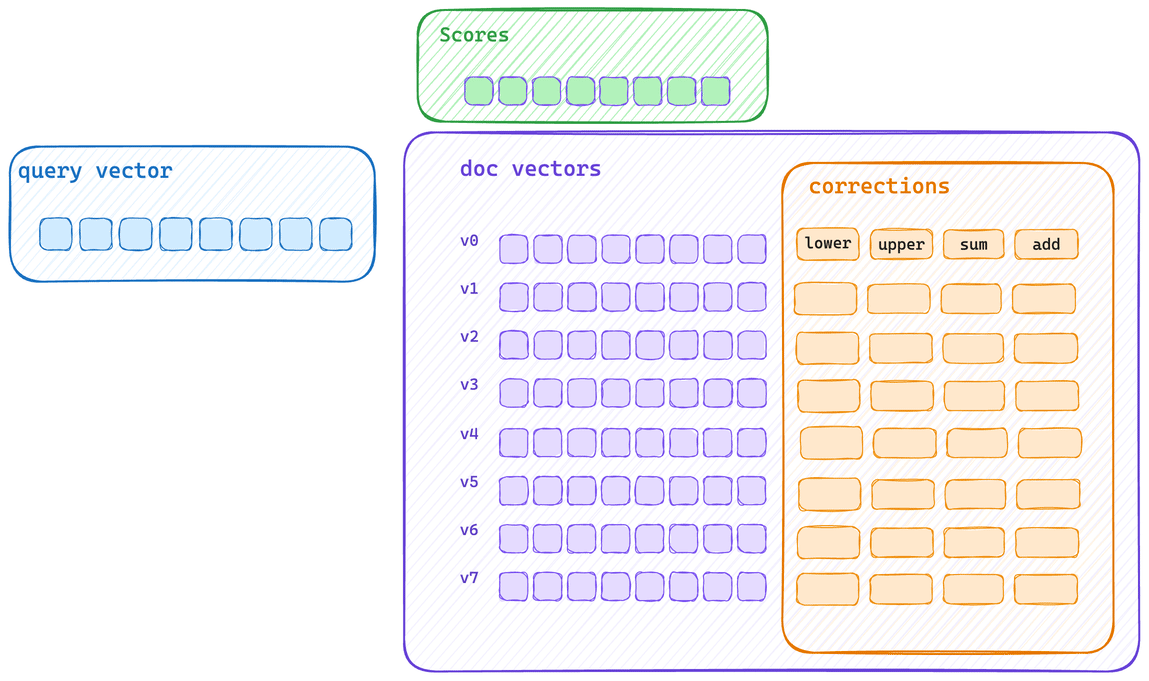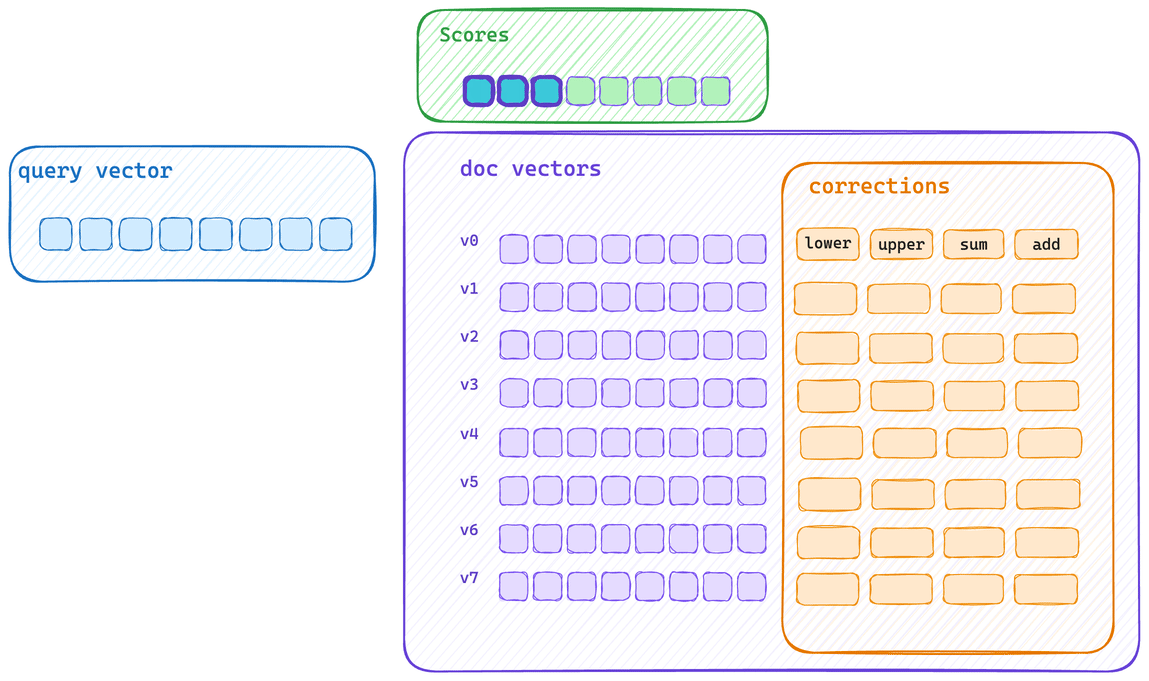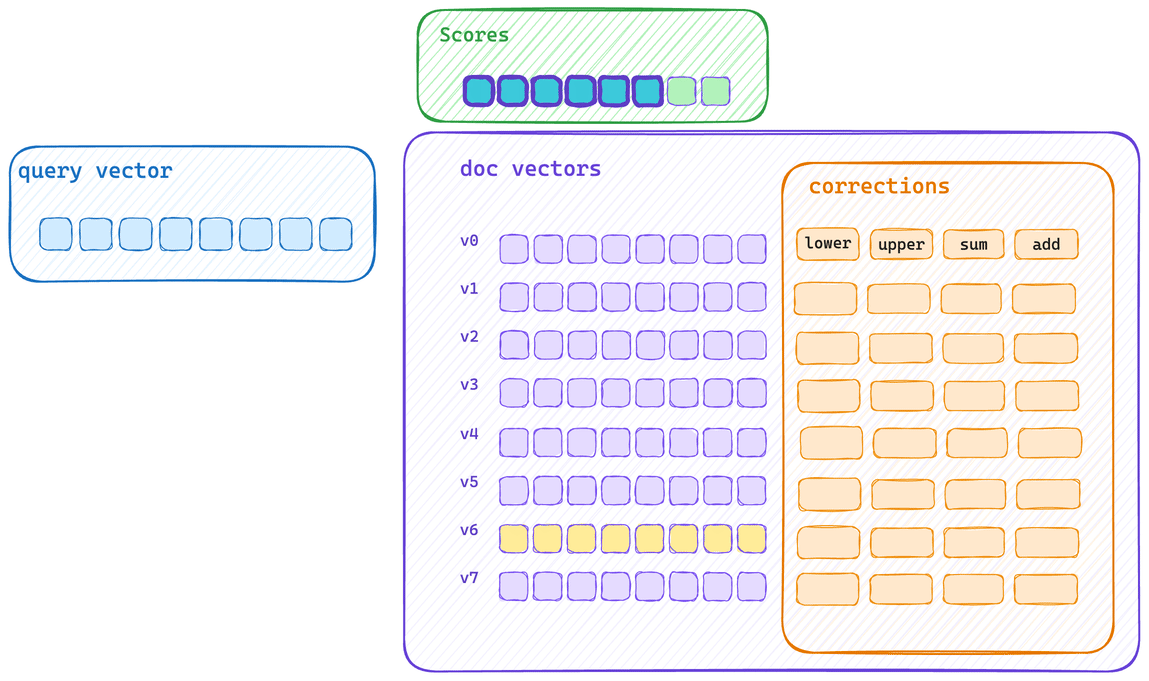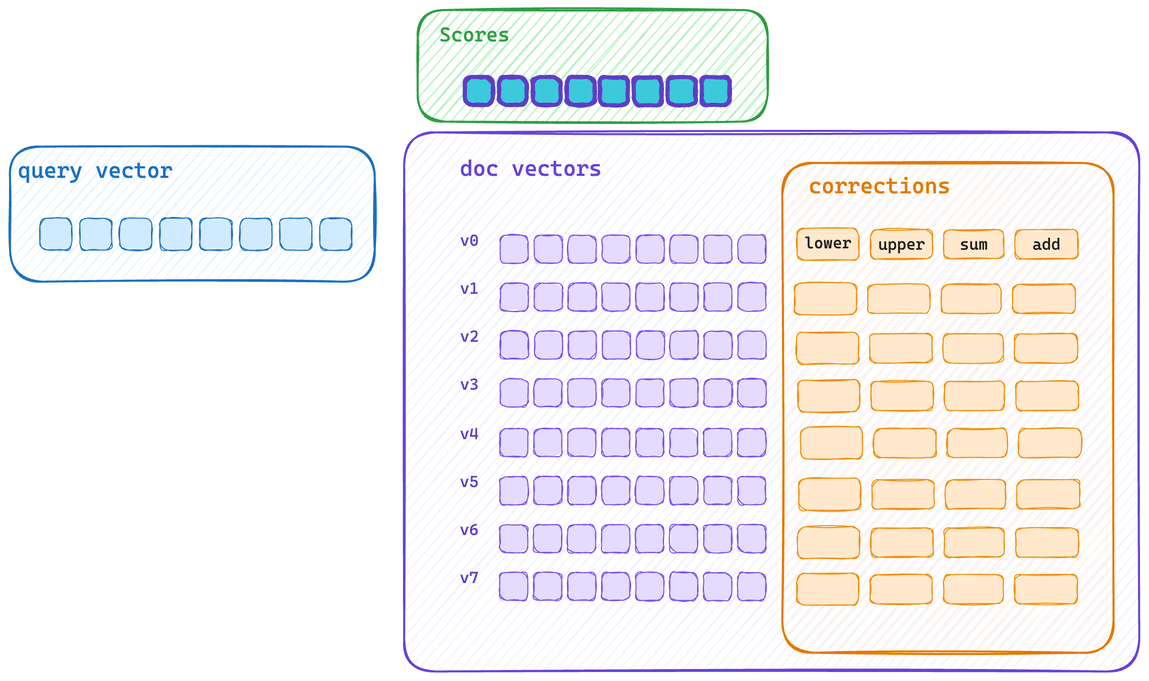
Here’s the typical single scoring path. Each vector is scored and then its corrections applied. This means that vector bytes don’t get to saturate CPU cache, and correction applications cannot be applied with the same SIMD block operation.
DiskBBQ vector search performance: what native SIMD means in practice
Native SIMD kernels in Elasticsearch 9.4 deliver nearly 3x faster BBQ vector scoring and 66x the throughput of float32 operations. We aren’t done; there are always ways to improve, but this native SIMD block scoring pattern works well on all CPU architectures, allowing DiskBBQ to be fast no matter where it's deployed.
Zugehörige Inhalte

10. Juli 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

7. Juli 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

2. Juli 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

24. Juni 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

18. Juni 2026
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.