Eine große Herausforderung bei der Verwendung von Learning-to-Rank- Modellen besteht darin, eine qualitativ hochwertige Beurteilungsliste zu erstellen, mit der das Modell trainiert werden kann. Traditionell beinhaltet dieser Prozess eine manuelle Bewertung der Relevanz von Suchanfrage und Dokument, um jedem Dokument eine Note zuzuweisen. Dies ist ein langsamer Prozess, der sich nicht gut skalieren lässt und schwer zu pflegen ist (stellen Sie sich vor, Sie müssten eine Liste mit Hunderten von Einträgen manuell aktualisieren).
Was wäre, wenn wir die Interaktionen realer Nutzer mit unserer Suchanwendung nutzen könnten, um diese Trainingsdaten zu erstellen? Die Nutzung von UBI -Daten ermöglicht uns genau das. Entwicklung eines automatischen Systems, das unsere Suchanfragen, Klicks und sonstige Interaktionen erfassen und nutzen kann, um eine Bewertungsliste zu erstellen. Dieser Prozess lässt sich viel einfacher skalieren und wiederholen als eine manuelle Interaktion und führt tendenziell zu besseren Ergebnissen. In diesem Blogbeitrag werden wir untersuchen, wie wir in Elasticsearch gespeicherte UBI-Daten abfragen können, um aussagekräftige Signale zu berechnen und so einen Trainingsdatensatz für ein LTR- Modell zu generieren.
Das vollständige Experiment finden Sie hier.
Warum UBI-Daten für das Training Ihres LTR-Modells nützlich sein können
UBI-Daten bieten gegenüber einer manuellen Annotation mehrere Vorteile:
- Volumen: Da die Daten zum bedingungslosen Grundeinkommen aus realen Interaktionen stammen, können wir viel mehr Daten sammeln, als wir manuell generieren könnten. Dies setzt natürlich voraus, dass wir über genügend Traffic verfügen, um diese Daten zu generieren.
- Tatsächliche Nutzerabsicht: Traditionell basiert eine manuelle Beurteilungsliste auf der Auswertung der verfügbaren Daten durch Experten. Andererseits spiegeln UBI-Daten das tatsächliche Nutzerverhalten wider. Das bedeutet, dass wir bessere Trainingsdaten generieren können, die die Genauigkeit unseres Suchsystems verbessern, da sie darauf basieren, wie Benutzer tatsächlich mit Ihren Inhalten interagieren und einen Nutzen darin finden, anstatt auf theoretischen Annahmen darüber, was relevant sein sollte.
- Kontinuierliche Aktualisierungen: Beurteilungslisten müssen von Zeit zu Zeit aktualisiert werden. Wenn wir sie aus UBI-Daten erstellen, erhalten wir aktuelle Daten, die zu aktualisierten Urteilslisten führen.
- Kosteneffizienz: Da keine manuelle Erstellung einer Beurteilungsliste erforderlich ist, kann der Prozess beliebig oft effizient wiederholt werden.
- Natürliche Abfrageverteilung: UBI-Daten repräsentieren reale Benutzerabfragen, die tiefgreifendere Veränderungen bewirken können. Nutzen unsere Nutzer beispielsweise natürliche Sprache, um in unserem System zu suchen? In diesem Fall sollten wir möglicherweise einen semantischen Suchansatz oder einen hybriden Suchansatz implementieren.
Es gibt allerdings auch einige Warnhinweise:
- Verzerrungsverstärkung: Beliebte Inhalte erhalten mit größerer Wahrscheinlichkeit Klicks, einfach weil sie mehr Aufmerksamkeit erregen. Dies könnte dazu führen, dass beliebte Artikel verstärkt werden und bessere Alternativen möglicherweise in den Hintergrund treten.
- Unvollständige Abdeckung: Neuen Inhalten fehlen jegliche Interaktionen, daher ist es schwierig für sie, in den Suchergebnissen weit oben zu erscheinen. Bei seltenen Anfragen können zudem nicht genügend Datenpunkte vorhanden sein, um aussagekräftige Trainingsdaten zu erzeugen.
- Saisonale Schwankungen: Wenn Sie erwarten, dass sich das Nutzerverhalten im Laufe der Zeit drastisch ändert, geben historische Daten möglicherweise nicht viel Aufschluss darüber, was ein gutes Ergebnis ist.
- Aufgabenunklarheit: Ein Klick garantiert nicht immer, dass der Nutzer gefunden hat, wonach er gesucht hat.
Notenberechnung
Noten für LTR-Schulung
Um LTR-Modelle zu trainieren, benötigen wir eine numerische Darstellung, die angibt, wie relevant ein Dokument für eine Suchanfrage ist. In unserer Implementierung handelt es sich bei dieser Zahl um einen kontinuierlichen Wert von 0,0 bis 5,0+, wobei höhere Werte eine höhere Relevanz anzeigen.
Um zu veranschaulichen, wie dieses Bewertungssystem funktioniert, betrachten Sie folgendes manuell erstellte Beispiel:
| Abfrage | Dokumentinhalt | Grad | Erläuterung |
|---|---|---|---|
| "bestes Pizza-Rezept" | "Authentisches italienisches Pizzateigrezept mit Schritt-für-Schritt-Fotos" | 4.0 | Äußerst relevant, genau das, wonach der Nutzer sucht. |
| "bestes Pizza-Rezept" | „Geschichte der Pizza in Italien“ | 1.0 | Es passt zwar thematisch, es geht um Pizza, ist aber kein Rezept. |
| "bestes Pizza-Rezept" | "Schnelles 15-Minuten-Pizza-Rezept für Anfänger" | 3.0 | Relevant, ein gutes Ergebnis, aber es verfehlt vielleicht das Ziel, das „beste“ Rezept zu sein. |
| "bestes Pizza-Rezept" | "Autowartungsleitfaden" | 0,0 | Überhaupt nicht relevant, steht in keinem Zusammenhang mit der Anfrage. |
Wie wir hier sehen können, ist die Bewertung eine numerische Darstellung der Relevanz eines Dokuments für unsere Beispielanfrage nach dem „besten Pizza-Rezept“. Anhand dieser Werte kann unser LTR-Modell lernen, welche Dokumente in den Ergebnissen weiter oben angezeigt werden sollten.
Die Berechnung der Noten ist der Kern unseres Trainingsdatensatzes. Hierfür gibt es verschiedene Ansätze , jeder mit seinen eigenen Stärken und Schwächen. Wir könnten beispielsweise eine binäre Bewertung vergeben: 1 für relevant, 0 für nicht relevant. Oder wir könnten einfach die Anzahl der Klicks in einem Ergebnisdokument für jede Suchanfrage zählen.
In diesem Blogbeitrag werden wir einen anderen Ansatz verfolgen, indem wir das Nutzerverhalten als Eingabe betrachten und eine Note als Ausgabe berechnen. Wir werden auch Verzerrungen korrigieren, die dadurch entstehen könnten, dass höhere Ergebnisse tendenziell häufiger angeklickt werden, unabhängig von der Relevanz des Dokuments.
Notenberechnung – COEC-Algorithmus
Der COEC-Algorithmus (Clicks over Expected Clicks) ist eine Methode zur Berechnung von Beurteilungsnoten aus den Klicks der Nutzer.
Wie bereits erwähnt, neigen Nutzer dazu, auf weiter oben positionierte Ergebnisse zu klicken, selbst wenn das Dokument nicht das relevanteste für die Suchanfrage ist; dies wird als Positionsbias bezeichnet. Die Grundidee des COEC-Algorithmus besteht darin, dass nicht alle Klicks gleich wichtig sind; ein Klick auf ein Dokument an Position 10 deutet darauf hin, dass das Dokument für die Suchanfrage viel relevanter ist als ein Klick auf ein Dokument an Position 1. Um die Forschungsarbeit zum COEC-Algorithmus (siehe Link oben) zu zitieren:
„Es ist bekannt, dass die Klickrate (CTR) von Suchergebnissen oder Anzeigen je nach Position der Ergebnisse deutlich abnimmt.“
Mehr zum Thema Positionsbias können Sie hier lesen.
Um dies mit dem COEC-Algorithmus zu lösen, gehen wir wie folgt vor:
1. Festlegung von Positionsbaselines: Wir berechnen die Klickrate (CTR) für jede Suchposition von 1 bis 10. Das bedeutet, wir ermitteln, welcher Prozentsatz der Nutzer typischerweise auf Position 1, Position 2 usw. klickt. Dieser Schritt erfasst die natürliche Positionsverzerrung der Nutzer.
Wir berechnen die CTR wie folgt:
Wo:
p = Position. Von 1 bis 10
Cp = Gesamtzahl der Klicks (auf beliebige Dokumente) an Position p über alle Abfragen hinweg
Ip = Gesamteindrücke: Wie oft ein Dokument an Position p über alle Suchanfragen hinweg erschienen ist.
Hier gehen wir davon aus, dass höhere Positionen mehr Klicks erhalten.
2. Berechnung der erwarteten Klicks (EC):
Diese Kennzahl legt fest, wie viele Klicks ein Dokument basierend auf seinen Platzierungspositionen und der Klickrate (CTR) für diese Positionen hätte erhalten sollen. Wir berechnen EC wie folgt:
Wo:
Qd = Alle Anfragen, bei denen das Dokument d vorkam
pos(d,q) = Position des Dokuments d in den Abfrageergebnissen q
3. Tatsächliche Klicks zählen: Wir zählen die tatsächliche Gesamtzahl der Klicks, die ein Dokument über alle Suchanfragen hinweg erhalten hat, bei denen es erschien, im Folgenden A(d) genannt.
4. Berechnen Sie den COEC-Wert: Dies ist das Verhältnis der tatsächlichen Klicks (A(d)) zu den erwarteten Klicks (EC(d)):
Diese Metrik normalisiert Positionsverzerrungen folgendermaßen:
- Ein Wert von 1,0 bedeutet, dass das Dokument angesichts seiner Positionen genau wie erwartet funktioniert hat.
- Ein Wert über 1,0 bedeutet, dass das Dokument im Vergleich zu den bisherigen Ergebnissen besser abgeschnitten hat. Dieses Dokument ist daher für die Anfrage relevanter.
- Ein Wert unter 1,0 bedeutet, dass das Dokument im Vergleich zu den bisherigen Ergebnissen schlechter abgeschnitten hat. Dieses Dokument ist daher für die Anfrage weniger relevant.
Das Endergebnis ist eine Bewertungszahl, die das widerspiegelt, wonach die Nutzer suchen, wobei positionsbezogene Erwartungen berücksichtigt werden, die aus realen Interaktionen mit unserem Suchsystem abgeleitet wurden.
Technische Umsetzung
Wir werden ein Skript erstellen, um eine Beurteilungsliste zu generieren, mit der ein LTR-Modell trainiert werden kann.
Die Eingabe für dieses Skript sind die in Elastic indexierten UBI-Daten (Abfragen und Ereignisse).
Das Ergebnis ist eine Beurteilungsliste in einer CSV-Datei, die aus diesen UBI-Dokumenten mithilfe des COEC-Algorithmus generiert wird. Diese Beurteilungsliste kann mit Eland verwendet werden, um relevante Merkmale zu extrahieren und ein LTR-Modell zu trainieren.
Schnellstart
Um aus den Beispieldaten in diesem Blog eine Bewertungsliste zu erstellen, können Sie folgende Schritte befolgen:
1. Klonen Sie das Repository:
2. Installieren Sie die erforderlichen Bibliotheken
Für dieses Skript benötigen wir die folgenden Bibliotheken:
- pandas: um die Urteilsliste zu speichern
- elasticsearch: Um die UBI-Daten aus unserer Elastic-Bereitstellung zu erhalten
Wir benötigen außerdem Python 3.11.
3. Aktualisieren Sie die Umgebungsvariablen für Ihre Elastic-Bereitstellung in einer .env-Datei.
- ES_HOST
- API-Schlüssel
Um die Umgebungsvariablen hinzuzufügen, verwenden Sie:
4. Erstellen Sie die Indizes ubi_queries und ubi_events und laden Sie die Beispieldaten hoch. Führen Sie die Datei setup.py aus:
5. Führen Sie das Python-Skript aus:
Wenn Sie diese Schritte befolgen, sollte eine neue Datei namens judgement_list.csv erscheinen, die folgendermaßen aussieht:
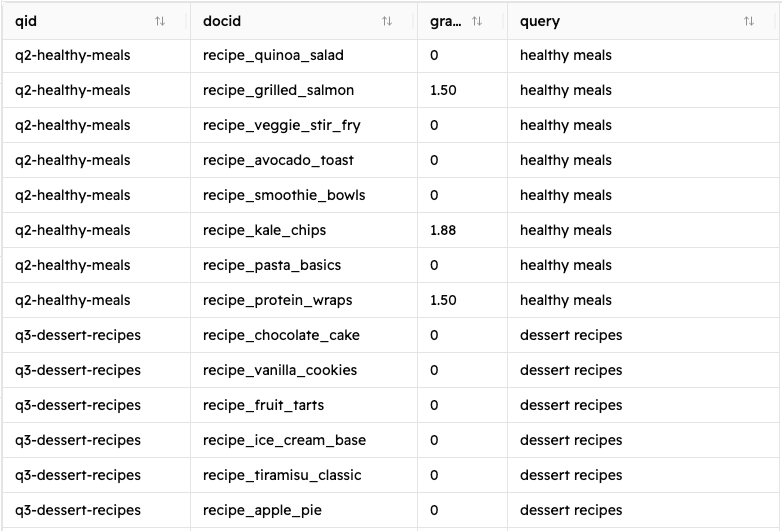
Dieses Skript berechnet die Noten unter Anwendung des zuvor erläuterten COEC-Algorithmus mithilfe der unten gezeigten Funktion calculate_relevance_grade() .
Datenarchitektur
Ubi-Anfragen
Unser UBI-Abfrageindex enthält Informationen über die in unserem Suchsystem ausgeführten Abfragen. Dies ist ein Beispieldokument:
Hier sehen wir Daten vom Benutzer (client_id), aus den Ergebnissen der Abfrage (query_response_object_ids) und die Abfrage selbst (timestamp, user_query).
Ubi-Klickereignisse
Unser ubi_events-Index enthält Daten von jedem Klick eines Nutzers auf ein Dokument in den Suchergebnissen. Dies ist ein Beispieldokument:
Skript zur Generierung der Urteilsliste
Allgemeine Skriptübersicht
Dieses Skript automatisiert die Generierung der Beurteilungsliste mithilfe von UBI-Daten aus Abfragen und Klickereignissen, die in Elasticsearch gespeichert sind. Es führt folgende Aufgaben aus:
- Ruft die UBI-Daten in Elasticsearch ab und verarbeitet sie.
- Korreliert UBI-Ereignisse mit seinen Abfragen.
- Berechnet die Klickrate (CTR) für jede Position.
- Berechnet die erwarteten Klicks (EC) für jedes Dokument.
- Zählt die tatsächlichen Klicks für jedes Dokument.
- Berechnet den COEC-Score für jedes Abfrage-Dokument-Paar.
- Erstellt eine Bewertungsliste und speichert diese in einer CSV-Datei.
Lassen Sie uns die einzelnen Funktionen durchgehen:
connect_to_elasticsearch()
Diese Funktion gibt ein Elasticsearch-Clientobjekt unter Verwendung des Hosts und des API-Schlüssels zurück.
fetch_ubi_data()
Diese Funktion ist die Datenextraktionsschicht; sie stellt eine Verbindung zu Elasticsearch her, um UBI-Abfragen mittels einer match_all-Abfrage abzurufen und filtert UBI-Ereignisse, um nur 'CLICK_THROUGH'-Ereignisse zu erhalten.
process_ubi_data()
Diese Funktion ist für die Generierung der Urteilsliste zuständig. Die Verarbeitung der UBI-Daten beginnt mit der Verknüpfung von UBI-Ereignissen und -Abfragen. Anschließend wird für jedes Dokument-Abfrage-Paar die Funktion calculate_relevance_grade() aufgerufen, um die Einträge für die Bewertungsliste zu erhalten. Schließlich gibt es die resultierende Liste als Pandas-DataFrame zurück.
calculate_relevance_grade()
Dies ist die Funktion, die den COEC-Algorithmus implementiert. Es berechnet die Klickrate (CTR) für jede Position, vergleicht dann die tatsächlichen Klicks für ein Dokument-Abfrage-Paar und berechnet schließlich den tatsächlichen COEC-Wert für jedes Paar.
generate_judgment_statistics()
Es generiert nützliche Statistiken aus der Bewertungsliste, wie z. B. die Gesamtzahl der Anfragen, die Gesamtzahl der eindeutigen Dokumente oder die Notenverteilung. Dies dient lediglich der Information und hat keinen Einfluss auf die endgültige Urteilsliste.
Ergebnisse und Auswirkungen
Wenn Sie die Anweisungen im Abschnitt „Schnellstart“ befolgen, sollte eine CSV-Datei mit einer Urteilsliste mit 320 Einträgen angezeigt werden (ein Beispiel finden Sie im Repository). Mit diesen Feldern:
- qid: eindeutige ID der Abfrage
- docid: eindeutige Kennung für ein resultierendes Dokument
- Note: die berechnete Note für das Abfrage-Dokument-Paar
- Anfrage: Die Benutzeranfrage
Schauen wir uns die Ergebnisse der Suchanfrage „Italienische Rezepte“ an:
| qid | docid | Grad | Abfrage |
|---|---|---|---|
| q1-italienische-rezepte | Grundrezept für Pasta | 0,0 | Italienische Rezepte |
| q1-italienische-rezepte | Rezept_Pizza_Margherita | 3,333333 | Italienische Rezepte |
| q1-italienische-rezepte | Rezept-Risotto-Anleitung | 10.0 | Italienische Rezepte |
| q1-italienische-rezepte | Rezept_französisches_Croissant | 0,0 | Italienische Rezepte |
| q1-italienische-rezepte | Rezept_spanische_Paella | 0,0 | Italienische Rezepte |
| q1-italienische-rezepte | Rezept_griechische_Moussaka | 1,875 | Italienische Rezepte |
Aus den Ergebnissen geht hervor, dass für die Suchanfrage „Italienische Rezepte“ Folgendes gilt:
- Das Risotto-Rezept ist definitiv das beste Ergebnis der Suchanfrage und erhielt zehnmal mehr Klicks als erwartet.
- Auch die Pizza Margherita ist ein hervorragendes Ergebnis.
- Die griechische Moussaka erzielt (überraschenderweise) ebenfalls ein gutes Ergebnis und schneidet besser ab, als ihre Platzierung in der Ergebnisliste vermuten lässt. Das bedeutet, dass einige Nutzer, die nach italienischen Rezepten suchten, stattdessen an diesem Rezept interessiert waren. Vielleicht interessieren sich diese Nutzer generell für mediterrane Gerichte. Letztendlich bedeutet dies, dass es sich um ein gutes Ergebnis handeln könnte, das unter den beiden anderen, oben besprochenen, "besseren" Treffern angezeigt werden könnte.
Fazit
Die Verwendung von UBI-Daten ermöglicht es uns, das Training von LTR-Modellen zu automatisieren und so qualitativ hochwertige Beurteilungslisten aus unseren eigenen Nutzern zu erstellen. Die UBI-Daten liefern einen großen Datensatz, der die Nutzung unseres Suchsystems widerspiegelt. Durch die Verwendung des COEC-Algorithmus zur Generierung der Noten berücksichtigen wir inhärente Verzerrungen und spiegeln gleichzeitig wider, was ein Benutzer als besseres Ergebnis ansieht. Die hier beschriebene Methode kann auf reale Anwendungsfälle angewendet werden, um ein besseres Sucherlebnis zu bieten, das sich mit den tatsächlichen Nutzungstrends weiterentwickelt.
Zugehörige Inhalte

4. November 2025
Multimodale Suche nach Berggipfeln mit Elasticsearch und SigLIP-2
Lernen Sie, wie Sie die multimodale Suche von Text zu Bild und von Bild zu Bild mithilfe von SigLIP-2-Einbettungen und der Elasticsearch kNN-Vektorsuche implementieren. Projektschwerpunkt: Auffinden von Fotos des Gipfels des Mount Ama Dablam während einer Everest-Trekkingtour.

Geodaten-Suche mit Elasticsearch und ES|QL
Geodaten-Suche in der Elasticsearch Query Language (ES|QL). Elasticsearch verfügt über leistungsstarke Geodaten-Suchfunktionen, die nun in ES|QL integriert werden, um die Benutzerfreundlichkeit und OGC-Vertrautheit deutlich zu verbessern.

16. Juli 2024
Bewertung der Suchrelevanz Teil 1 – Der BEIR-Benchmark
Lernen Sie, Ihr Suchsystem im Zusammenhang mit einem besseren Verständnis des BEIR-Benchmarks zu bewerten, mit Tipps und Techniken zur Verbesserung Ihrer Suchbewertungsprozesse.

19. Dezember 2023
KI-Plagiat: Plagiatserkennung mit Elasticsearch
Hier erfahren Sie, wie Sie mithilfe von Elasticsearch auf KI-Plagiate prüfen können. Der Schwerpunkt liegt dabei auf Anwendungsfällen mit NLP-Modellen und Vektorsuche.

3. Oktober 2023
Lexikalische und semantische Suche mit Elasticsearch
In diesem Blogbeitrag werden wir verschiedene Ansätze zur Informationsbeschaffung mit Elasticsearch untersuchen, wobei wir uns auf die lexikalische und semantische Suche konzentrieren.