Nahtlose Verbindung mit führenden KI- und Machine-Learning-Plattformen. Starten Sie eine kostenlose Cloud-Testversion, um die Funktionen der generativen KI von Elastic zu erkunden, oder testen Sie sie jetzt auf Ihrem Rechner.
Mit Stateless Elasticsearch investieren wir in den Aufbau einer neuen, vollständig Cloud-nativen Architektur, um die Grenzen von Skalierbarkeit und Geschwindigkeit zu erweitern. In diesem Blogbeitrag gehen wir der Frage nach, wo wir angefangen haben, der Zukunft von Elasticsearch mit der Einführung einer zustandslosen Architektur und den Details dieser Architektur.
Wo wir angefangen haben
Die erste Version von Elasticsearch wurde 2010 als verteilte, skalierbare Suchmaschine veröffentlicht, die es Benutzern ermöglicht, schnell nach wichtigen Erkenntnissen zu suchen und diese anzuzeigen. Zwölf Jahre und über 65.000 Commits später bietet Elasticsearch seinen Nutzern weiterhin praxiserprobte Lösungen für eine Vielzahl von Suchproblemen. Dank des Engagements von über 1.500 Mitwirkenden, darunter Hunderte von festangestellten Elastic-Mitarbeitern, hat sich Elasticsearch ständig weiterentwickelt, um den neuen Herausforderungen im Bereich der Suche gerecht zu werden.
In der Frühphase von Elasticsearch, als Bedenken hinsichtlich Datenverlusten aufkamen, unternahm das Elastic-Team über mehrere Jahre hinweg Anstrengungen , das Cluster-Koordinationssystem neu zu schreiben, um zu gewährleisten, dass bestätigte Daten sicher gespeichert werden. Als deutlich wurde, dass die Verwaltung von Indizes in großen Clustern mühsam ist, arbeitete das Team an der Implementierung einer umfassenden ILM-Lösung , um diese Arbeit zu automatisieren, indem es den Benutzern ermöglicht, Indexmuster und Lebenszyklusaktionen vorzudefinieren. Da die Nutzer den Bedarf erkannten, große Mengen an Metrik- und Zeitreihendaten zu speichern, wurden verschiedene Funktionen wie eine bessere Komprimierung hinzugefügt, um die Datengröße zu reduzieren. Da die Speicherkosten für die Suche in großen Mengen kalter Daten stiegen, investierten wir in die Entwicklung von durchsuchbaren Snapshots , um Benutzerdaten direkt in kostengünstigen Objektspeichern durchsuchen zu können.
Diese Investitionen legen den Grundstein für die nächste Entwicklungsstufe von Elasticsearch. Angesichts des Wachstums cloudnativer Dienste und neuer Orchestrierungssysteme haben wir beschlossen, Elasticsearch weiterzuentwickeln, um die Benutzerfreundlichkeit bei der Arbeit mit cloudnativen Systemen zu verbessern. Wir sind überzeugt, dass diese Änderungen Möglichkeiten zur Verbesserung des Betriebsablaufs, der Leistung und der Kosten beim Betrieb von Elasticsearch auf Elastic Cloud bieten.
Wohin wir gehen – Die Einführung einer staatenlosen Architektur
Eine der größten Herausforderungen beim Betrieb oder der Orchestrierung von Elasticsearch besteht darin, dass es von zahlreichen persistenten Zuständen abhängt und daher ein zustandsbehaftetes System ist. Die drei Hauptbestandteile sind das Translog, der Indexspeicher und die Cluster-Metadaten. Dieser Zustand bedeutet, dass die Daten persistent sein müssen und bei einem Neustart oder Austausch eines Knotens nicht verloren gehen dürfen.
Die bestehende Elasticsearch-Architektur auf Elastic Cloud muss die Indizierung über mehrere Verfügbarkeitszonen hinweg duplizieren, um im Falle von Ausfällen Redundanz zu gewährleisten. Wir beabsichtigen, die Speicherung dieser Daten von lokalen Festplatten in einen Objektspeicher wie AWS S3 zu verlagern. Durch die Nutzung externer Dienste zur Speicherung dieser Daten entfällt die Notwendigkeit der Indexierungsreplikation, wodurch der mit der Datenerfassung verbundene Hardwareaufwand erheblich reduziert wird. Diese Architektur bietet zudem sehr hohe Garantien für die Datenbeständigkeit, da Cloud-Objektspeicher wie AWS S3, GCP Cloud Storage und Azure Blob Storage Daten über Verfügbarkeitszonen hinweg replizieren.
Durch die Auslagerung der Indexspeicherung in einen externen Dienst können wir Elasticsearch auch neu strukturieren, indem wir die Verantwortlichkeiten für Indizierung und Suche trennen. Anstatt primäre und Replikatinstanzen für beide Arbeitslasten zu verwenden, planen wir eine Indexierungsebene und eine Suchebene. Durch die Trennung dieser Arbeitslasten können diese unabhängig voneinander skaliert werden, und die Hardwareauswahl kann gezielter auf die jeweiligen Anwendungsfälle abgestimmt werden. Es hilft auch dabei, eine seit langem bestehende Herausforderung zu lösen, bei der sich die Such- und Indexierungslast gegenseitig beeinflussen kann.
Nach einer mehrmonatigen Machbarkeits- und Versuchsphase sind wir davon überzeugt, dass diese Objektspeicherdienste die Anforderungen erfüllen, die wir an die Speicherung von Indizes und Cluster-Metadaten stellen. Unsere Tests und Benchmarks zeigen, dass diese Speicherdienste die hohen Indexierungsanforderungen der größten Cluster, die wir in Elastic Cloud gesehen haben, erfüllen können. Darüber hinaus reduziert die Speicherung der Daten im Objektspeicher die Indizierungskosten und ermöglicht eine einfache Optimierung der Suchleistung. Zur Datensuche nutzt Elasticsearch das bewährte Searchable Snapshots-Modell, bei dem die Daten dauerhaft im Cloud-nativen Objektspeicher abgelegt werden und lokale Festplatten als Cache für häufig abgerufene Daten dienen.

Um die Unterschiede zu verdeutlichen, bezeichnen wir unser bestehendes Modell als „Knoten-zu-Knoten“-Replikation. In der Hot-Tier-Ebene dieses Modells übernehmen sowohl der primäre als auch der Replikat-Shard die gleiche rechenintensive Aufgabe bei der Verarbeitung und Beantwortung von Suchanfragen. Diese Knoten sind „zustandsbehaftet“, da sie sich auf ihre lokalen Festplatten verlassen, um die Daten für die von ihnen gehosteten Shards sicher zu speichern. Darüber hinaus kommunizieren primäre und Replikat-Shards ständig miteinander, um synchron zu bleiben. Dies geschieht, indem die auf dem primären Shard durchgeführten Operationen auf den Replikat-Shard repliziert werden, was bedeutet, dass die Kosten dieser Operationen (hauptsächlich CPU) für jedes angegebene Replikat anfallen. Die gleichen Shards und Nodes, die für die Datenaufnahme zuständig sind, bedienen auch Suchanfragen, daher müssen Bereitstellung und Skalierung beide Arbeitslasten berücksichtigen.
Neben der Suche und dem Datenimport übernehmen Shards im Node-to-Node-Replikationsmodell weitere rechenintensive Aufgaben, wie beispielsweise das Zusammenführen von Lucene-Segmenten. Dieses Design hat zwar seine Vorzüge, aber wir sahen viele Möglichkeiten, die sich aus unseren Erfahrungen mit Kunden im Laufe der Jahre und der Entwicklung des gesamten Cloud-Ökosystems ergaben.
Die neue Architektur ermöglicht zahlreiche sofortige und zukünftige Verbesserungen, darunter:
- Sie können den Datendurchsatz auf derselben Hardware deutlich erhöhen, oder anders ausgedrückt, die Effizienz bei gleicher Datenerfassungslast deutlich verbessern. Diese Steigerung resultiert aus der Beseitigung der Duplizierung von Indexierungsvorgängen für jede Replik. Die rechenintensiven Indexierungsvorgänge müssen nur einmal auf der Indexierungsebene durchgeführt werden, die anschließend die resultierenden Segmente an einen Objektspeicher sendet. Von dort aus können die Daten direkt von der Suchschicht verwendet werden.
- Sie können Rechenleistung und Speicher trennen, um Ihre Clustertopologie zu vereinfachen. Elasticsearch verfügt heute über mehrere Datenebenen (Content, Hot, Warm, Cold und Frozen), um Daten mit Hardwareprofilen abzugleichen. Die Hot-Tier-Kategorie dient der Suche in nahezu Echtzeit, die Frozen-Tier-Kategorie der Suche nach weniger häufig gesuchten Daten. Diese Ebenen bieten zwar einen Mehrwert, erhöhen aber auch die Komplexität. In der neuen Architektur werden Datenebenen nicht mehr benötigt, was die Konfiguration und den Betrieb von Elasticsearch vereinfacht. Wir trennen außerdem die Indizierung von der Suche, was die Komplexität weiter reduziert und es uns ermöglicht, beide Arbeitslasten unabhängig voneinander zu skalieren.
- Sie können die Speicherkosten auf der Indexierungsebene senken, indem Sie die Menge der Daten reduzieren, die auf einer lokalen Festplatte gespeichert werden müssen. Aktuell muss Elasticsearch für Indexierungszwecke eine vollständige Shard-Kopie auf den Hot Nodes (sowohl primären als auch Replikaten) speichern. Bei dem zustandslosen Ansatz, direkt auf den Objektspeicher zuzugreifen, wird nur ein Teil dieser lokalen Daten benötigt. Bei reinen Anfüge-Anwendungsfällen müssen nur bestimmte Metadaten zur Indizierung gespeichert werden. Dadurch wird der für die Indizierung benötigte lokale Speicherplatz erheblich reduziert.
- Sie können die mit Suchanfragen verbundenen Speicherkosten senken. Indem das Searchable Snapshots-Modell zum nativen Modus der Datensuche gemacht wird, werden die mit Suchanfragen verbundenen Speicherkosten deutlich reduziert. Je nach den Anforderungen der Benutzer an die Suchlatenz ermöglicht Elasticsearch Anpassungen, um das lokale Caching häufig angeforderter Daten zu erhöhen.
Benchmarking – 75 % Verbesserung des Indexierungsdurchsatzes
Um diesen Ansatz zu validieren, haben wir einen umfangreichen Machbarkeitsnachweis erbracht, bei dem die Daten nur auf einem einzigen Knoten indiziert und die Replikation über Cloud-Objektspeicher realisiert wurde. Wir stellten fest, dass wir eine Verbesserung des Indexierungsdurchsatzes um 75 % erreichen konnten, indem wir die Notwendigkeit beseitigten, Hardware für die Indexierungsreplikation zu dedizieren. Darüber hinaus waren die CPU-Kosten für das einfache Abrufen von Daten aus dem Objektspeicher wesentlich geringer als für das Indizieren der Daten und das lokale Schreiben, wie es heutzutage für die Hot-Tier-Ebene erforderlich ist. Dies bedeutet, dass die Suchknoten ihre gesamte CPU-Leistung der Suche widmen können.
Diese Leistungstests wurden auf einem Zwei-Knoten-Cluster gegen alle drei großen Public-Cloud-Anbieter (AWS, GCP und Azure) durchgeführt. Wir beabsichtigen, im Zuge unserer Bemühungen um eine zustandslose Produktionsimplementierung weiterhin größere Benchmarks zu entwickeln.
Indexierungsdurchsatz


CPU-Auslastung
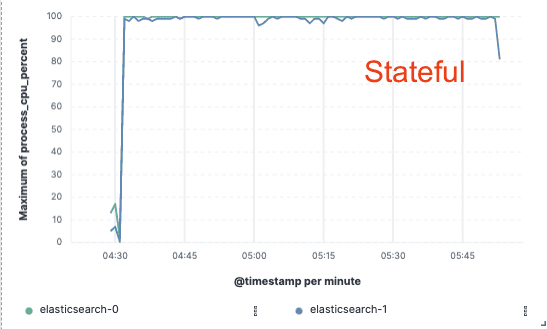
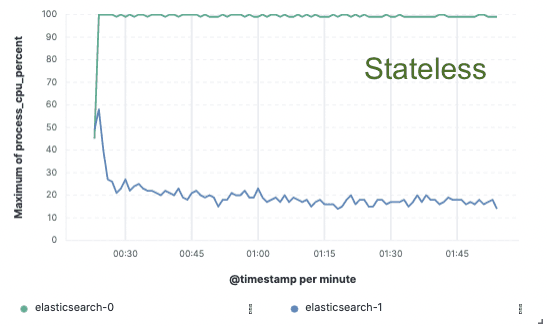
Staatenlos für uns, Ersparnisse für Sie
Die zustandslose Architektur von Elastic Cloud ermöglicht es Ihnen, den Indexierungsaufwand zu reduzieren, die Datenerfassung und -suche unabhängig voneinander zu skalieren, die Verwaltung der Datenebenen zu vereinfachen und Vorgänge wie Skalierung oder Upgrade zu beschleunigen. Dies ist der erste Meilenstein hin zu einer umfassenden Modernisierung der Elastic Cloud-Plattform.
Werden Sie Teil unserer Vision für zustandsloses Elasticsearch.
Haben Sie Interesse, diese Lösung vor allen anderen auszuprobieren? Sie können uns über die Diskussionsseite oder unseren Community-Slack-Kanal erreichen. Wir würden uns über Ihr Feedback freuen, um die Ausrichtung unserer neuen Architektur mitzugestalten.
Zugehörige Inhalte
18. Mai 2026
Eine Abfrage, mehrere Elasticsearch Serverless-Projekte: Einführung der projektübergreifenden Suche
Die projektübergreifende Suche in Elastic Cloud Serverless ermöglicht es Ihnen, Daten aus isolierten Projekten mit einer einzigen Elasticsearch- oder ES|QL-Anfrage abzufragen: keine Duplizierung, kein Netzwerk-Peering und keine Kosten für ausgehende Daten durch das Kopieren von Protokollen.

20. April 2026
Einführung einheitlicher API-Schlüssel für Elastic Cloud Serverless und Elasticsearch
Erfahren Sie, wie Elastic die Authentifizierung von Steuerebenen und Datenebenen in Serverless mit einer global verteilten IAM-Architektur vereint. Verwenden Sie einen API-Schlüssel für Cloud- und Elasticsearch-APIs.

24. März 2026
Elasticsearch-Replikate für den Lastausgleich in Serverless
Erfahren Sie, wie Elastic Cloud Serverless die Indexreplikate automatisch an die Suchlast anpasst und so eine optimale Abfrageleistung ohne manuelle Konfiguration gewährleistet.
22. Januar 2026
Agent Builder jetzt GA: Versenden Sie kontextabhängige Agenten in wenigen Minuten
Agent Builder ist jetzt allgemein verfügbar (GA). Erfahren Sie, wie Sie damit schnell kontextgesteuerte KI-Agenten entwickeln können.

14. Januar 2026
Höherer Durchsatz und geringere Latenz: Elastic Cloud Serverless auf AWS erhält einen deutlichen Leistungsschub.
Wir haben die AWS-Infrastruktur für Elasticsearch Serverless auf neuere, schnellere Hardware upgegradet. Erfahren Sie, wie dieser enorme Leistungsschub schnellere Abfragen, besseres Skalieren und niedrigere Kosten liefert.