Neu bei Elasticsearch? Nehmen Sie an unserem Webinar „Erste Schritte mit Elasticsearch“ teil. Sie können jetzt auch eine kostenlose Cloud-Testversion starten oder Elastic auf Ihrem Rechner testen.
Die Heap-Größe ist die Menge an RAM, die der Java Virtual Machine eines Elasticsearch-Knotens zugewiesen wird.
Ab Version 7.11 passt Elasticsearch die JVM-Heap-Größe standardmäßig automatisch an die Rollen und den Gesamtspeicher eines Knotens an. Für die meisten Produktionsumgebungen wird die Verwendung der Standarddimensionierung empfohlen. Wenn Sie jedoch die Größe Ihres JVM-Heaps manuell festlegen möchten, sollten Sie in der Regel -Xms und -Xmx auf den gleichen Wert setzen, der 50 % Ihres gesamten verfügbaren RAMs betragen sollte, maximal jedoch (ungefähr) 31 GB.
Eine größere Heap-Größe stellt Ihrem Knoten mehr Speicher für Indizierungs- und Suchvorgänge zur Verfügung. Allerdings benötigt Ihr Knoten auch Speicher für das Caching, daher sorgt die Verwendung von 50 % für ein gesundes Gleichgewicht zwischen den beiden. Aus demselben Grund sollten Sie im Produktivbetrieb vermeiden, andere speicherintensive Prozesse auf demselben Knoten wie Elasticsearch auszuführen.
Typischerweise folgt die Haufennutzung einem Sägezahnmuster und schwankt zwischen etwa 30 und 70 % der maximal genutzten Haufengröße. Dies liegt daran, dass die JVM den Heap-Nutzungsprozentsatz stetig erhöht, bis der Garbage-Collection-Prozess wieder Speicher freigibt. Eine hohe Heap-Speicherbelegung tritt auf, wenn der Garbage-Collection-Prozess nicht hinterherkommt. Ein Indikator für eine hohe Heap-Speicherbelegung ist, wenn die Garbage Collection nicht in der Lage ist, die Heap-Speicherbelegung auf etwa 30 % zu reduzieren.

Im obigen Bild ist ein normales Sägezahnmuster des JVM-Heaps zu sehen.
Sie werden auch feststellen, dass es zwei Arten von Müllabfuhr gibt, die junge und die alte Müllabfuhr.
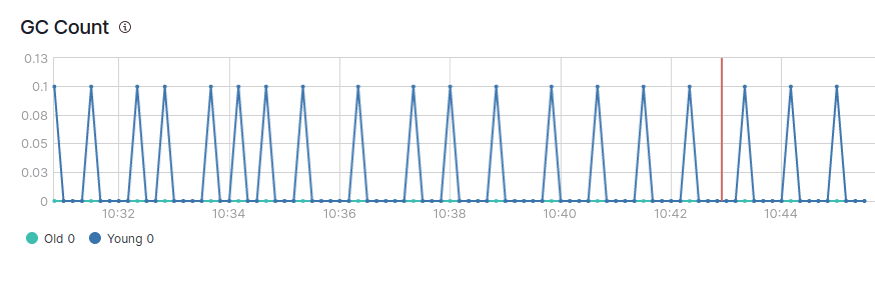
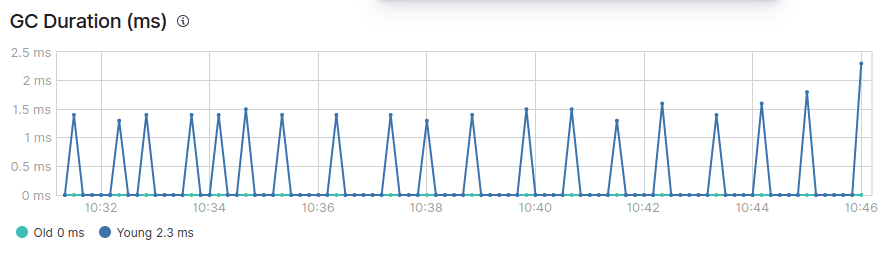
In einer gesunden JVM sollte die Speicherbereinigung idealerweise die folgenden Bedingungen erfüllen:
- Young GC wird schnell verarbeitet (innerhalb von 50 ms).
- Young GC wird nicht häufig ausgeführt (etwa alle 10 Sekunden).
- Der alte GC wird schnell verarbeitet (innerhalb von 1 Sekunde).
- Die alte Garbage Collection wird nicht häufig ausgeführt (einmal alle 10 Minuten oder seltener).
Wie lässt sich das Problem beheben, wenn die Heap-Speichernutzung zu hoch ist oder die JVM-Leistung nicht optimal ist?
Es kann verschiedene Gründe geben, warum die Heap-Speicherbelegung ansteigen kann:
Übersharding
Das Dokument zum Thema Oversharding finden Sie hier.
Große Aggregationsgrößen
Um große Aggregationsgrößen zu vermeiden, halten Sie die Anzahl der Aggregations-Buckets (Größe) in Ihren Abfragen so gering wie möglich.
Sie können die Protokollierung langsamer Abfragen (Slow Logs) verwenden und sie auf einem bestimmten Index mit den folgenden Mitteln implementieren.
Anfragen, deren Beantwortung lange dauert, sind wahrscheinlich ressourcenintensiv.
Übermäßige Größe des Massenindex
Wenn Sie große Anfragen senden, kann dies zu einem hohen Heap-Verbrauch führen. Versuchen Sie, die Größe der Massenindexierungsanfragen zu reduzieren.
Kartierungsprobleme
Insbesondere wenn Sie „fielddata: true“ verwenden, kann dies einen erheblichen Teil Ihres JVM-Heaps beanspruchen.
Die Haufengröße wurde falsch eingestellt.
Die Heap-Größe kann manuell definiert werden durch:
Festlegen der Umgebungsvariablen:
Bearbeiten der Datei jvm.options in Ihrem Elasticsearch-Konfigurationsverzeichnis:
Die Einstellung der Umgebungsvariablen hat Vorrang vor der Dateieinstellung.
Der Knoten muss neu gestartet werden, damit die Einstellung übernommen wird.
Das neue JVM-Verhältnis wurde falsch eingestellt
Im Allgemeinen ist es NICHT notwendig, dies festzulegen, da Elasticsearch diesen Wert standardmäßig setzt. Dieser Parameter definiert das Verhältnis des verfügbaren Speicherplatzes für Objekte der „neuen Generation“ und der „alten Generation“ in der JVM.
Wenn Sie feststellen, dass old GC sehr häufig vorkommt, können Sie versuchen, diesen Wert in der Datei jvm.options in Ihrem Elasticsearch-Konfigurationsverzeichnis explizit festzulegen.
Was sind die besten Vorgehensweisen für die Verwaltung der Heap-Speicherbelegung und der JVM-Garbage-Collection in einem großen Elasticsearch-Cluster?
Die besten Vorgehensweisen für die Verwaltung der Heap-Speicherbelegung und der JVM-Garbage-Collection in einem großen Elasticsearch-Cluster bestehen darin, sicherzustellen, dass die Heap-Größe auf maximal 50 % des verfügbaren RAMs eingestellt ist und dass die JVM-Garbage-Collection-Einstellungen für den jeweiligen Anwendungsfall optimiert sind. Es ist wichtig, die Heap-Größe und die Garbage-Collection-Metriken zu überwachen, um sicherzustellen, dass der Cluster optimal läuft. Insbesondere ist es wichtig, die JVM-Heap-Größe, die Garbage-Collection-Zeit und die Garbage-Collection-Pausen zu überwachen. Darüber hinaus ist es wichtig, die Anzahl der Müllabfuhrzyklen und die für die Müllabfuhr aufgewendete Zeit zu überwachen. Durch die Überwachung dieser Kennzahlen können potenzielle Probleme mit der Heap-Größe oder den Einstellungen für die Speicherbereinigung erkannt und gegebenenfalls Korrekturmaßnahmen ergriffen werden.
Zugehörige Inhalte

14. November 2025
So stellen Sie Elasticsearch auf Azure AKS Automated bereit
Erfahren Sie, wie Sie Elasticsearch mit Kibana auf Azure mithilfe von AKS Automatic und ECK für eine teilweise verwaltete Elasticsearch-Setup-Konfiguration bereitstellen.

11. November 2025
Konfiguration der rekursiven Segmentierung für strukturierte Dokumente in Elasticsearch
Erfahren Sie, wie Sie rekursives Chunking in Elasticsearch mit Chunk-Größe, Trenngruppen und benutzerdefinierten Trennlisten für eine optimale strukturierte Dokumentenindizierung konfigurieren.

7. November 2025
Einführung der Elasticsearch-Abfrageregeln-Benutzeroberfläche in Kibana
Erfahren Sie, wie Sie mit der Elasticsearch Query Rules UI Dokumente mithilfe anpassbarer Regelsätze in Kibana zu Suchanfragen hinzufügen oder ausschließen können, ohne das organische Ranking zu beeinträchtigen.

3. Oktober 2025
So stellen Sie Elasticsearch auf dem AWS Marketplace bereit
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie Elasticsearch mithilfe des Elastic Cloud Service auf dem AWS Marketplace einrichten und ausführen.

14. August 2025
Elasticsearch-Shards und -Replikate: Ein praktischer Leitfaden
Machen Sie sich mit den Konzepten von Elasticsearch-Shards und -Replikaten vertraut und lernen Sie, wie Sie diese optimieren können.