Vor diesem (ziemlich ausführlichen) Hintergrund zu den Veränderungen, die LLMs den zugrundeliegenden Prozessen der Informationswiedergewinnung zugeschrieben haben, wollen wir uns nun ansehen, wie sie auch die Art und Weise verändert haben, wie wir nach Daten suchen.
Eine neue Art der Interaktion mit Daten
Generative KI (genAI) und agentenbasierte KI gehen anders vor als die traditionelle Suche. Während wir früher mit der Informationssuche durch eine Suche begannen („Lass mich das mal googeln…“), erfolgt die erste Aktion sowohl bei generischer KI als auch bei Agenten in der Regel durch die Eingabe von natürlicher Sprache in eine Chat-Oberfläche. Die Chat-Oberfläche ist eine Diskussion mit einem LLM, der sein semantisches Verständnis nutzt, um unsere Frage in eine destillierte Antwort umzuwandeln, eine zusammenfassende Antwort, die scheinbar von einem Orakel stammt, das über ein breites Wissen über alle Arten von Informationen verfügt. Was den LLM wirklich auszeichnet, ist seine Fähigkeit, kohärente, durchdachte Sätze zu formulieren, die die einzelnen Wissensfragmente miteinander verknüpfen – selbst wenn diese ungenau oder völlig realitätsfern sind, steckt doch ein Körnchen Wahrheit darin.
Die alte Suchleiste, mit der wir so vertraut geworden sind, kann man sich als die Ampelmaschine vorstellen, die wir benutzt haben, als wir selbst der denkende Agent waren. Inzwischen wandeln sogar Internet-Suchmaschinen unsere altbekannte, mühsame Suche nach Wörtern in KI-gesteuerte Übersichten um, die die Anfrage mit einer Zusammenfassung der Ergebnisse beantworten und den Nutzern so die Notwendigkeit ersparen, sich durch die einzelnen Ergebnisse zu klicken und diese selbst zu bewerten.
Generative KI & RAG
Generative KI versucht, mithilfe ihres semantischen Verständnisses der Welt die in einer Chatanfrage geäußerte subjektive Absicht zu analysieren und anschließend mithilfe ihrer Schlussfolgerungsfähigkeiten spontan eine Expertenantwort zu erstellen. Eine generative KI-Interaktion besteht aus mehreren Teilen: Sie beginnt mit der Eingabe/Anfrage des Benutzers, frühere Konversationen in der Chat-Sitzung können als zusätzlicher Kontext verwendet werden, und die Anweisung gibt dem LLM vor, wie er argumentieren und welche Verfahren er bei der Erstellung der Antwort befolgen soll. Die Hilfestellungen haben sich von einfachen Erklärungen im Stil von „Erkläre es mir so, als wäre ich fünf Jahre alt“ zu vollständigen Anleitungen für die Bearbeitung von Anfragen weiterentwickelt. Diese Aufschlüsselungen enthalten oft separate Abschnitte, die Details zur Persona/Rolle der KI, zum vor der Generierung stattfindenden Denkprozess/internen Denkprozess, zu objektiven Kriterien, Einschränkungen, zum Ausgabeformat, zur Zielgruppe sowie Beispiele zur Veranschaulichung der zu erwartenden Ergebnisse beschreiben.
Zusätzlich zur Benutzeranfrage und der Systemaufforderung liefert Retrieval Augmented Generation (RAG) weitere Kontextinformationen in einem sogenannten „Kontextfenster“. RAG war eine entscheidende Ergänzung der Architektur; wir nutzen es, um das LLM über die fehlenden Puzzleteile in seinem semantischen Verständnis der Welt zu informieren.
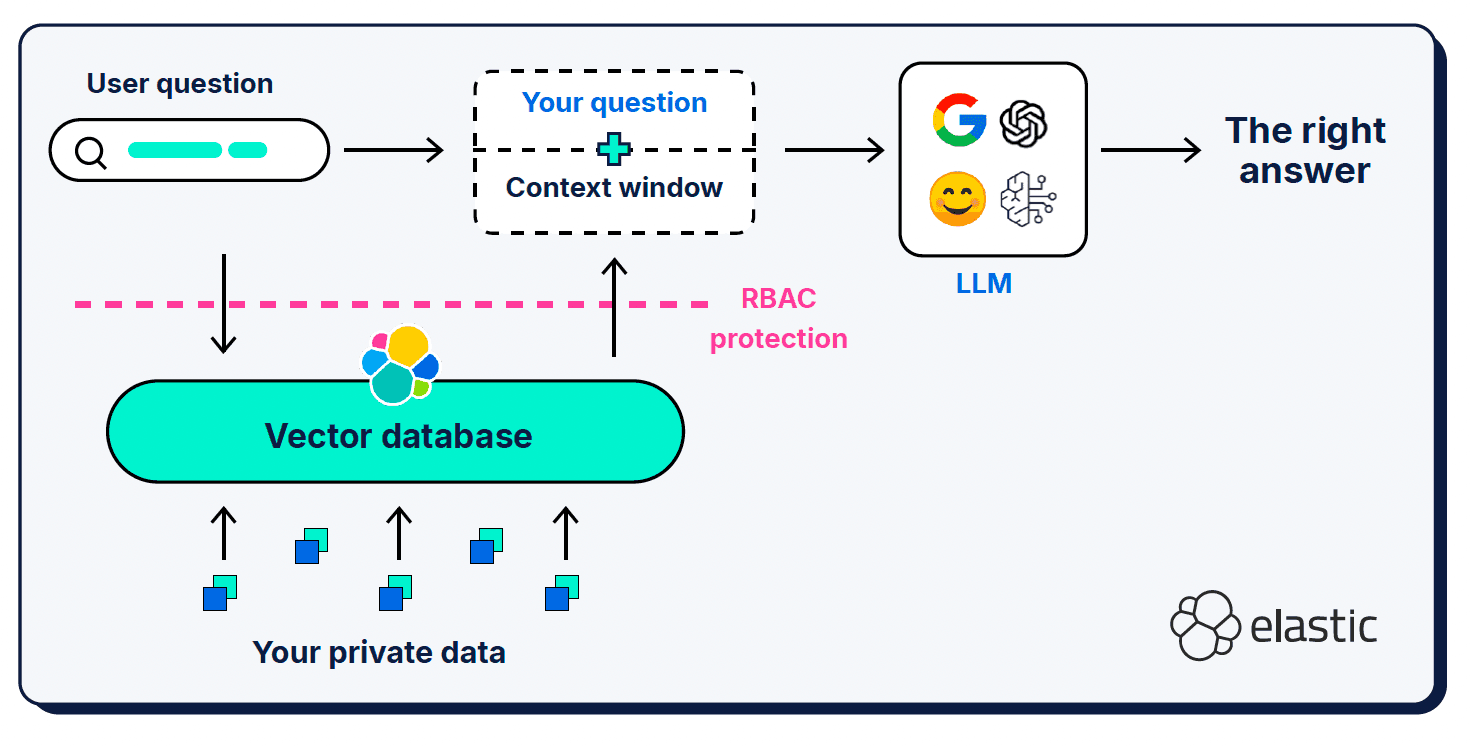
Kontextfenster können ziemlich pingelig sein, wenn es darum geht, was, wo und wie viel man ihnen gibt. Welcher Kontext ausgewählt wird, ist natürlich sehr wichtig, aber auch das Signal-Rausch-Verhältnis des bereitgestellten Kontexts sowie die Länge des Fensters spielen eine Rolle.
Zu wenige Informationen
Werden in einer Abfrage, einer Eingabeaufforderung oder einem Kontextfenster zu wenige Informationen angegeben, kann dies zu Halluzinationen führen, da das LLM den korrekten semantischen Kontext für die Generierung einer Antwort nicht genau bestimmen kann. Es gibt auch Probleme mit der Vektorähnlichkeit der Dokumentabschnittsgrößen – eine kurze, einfache Frage passt möglicherweise nicht semantisch zu den umfangreichen, detaillierten Dokumenten in unseren vektorisierten Wissensdatenbanken. Es wurden Techniken zur Erweiterung von Anfragen entwickelt, wie zum Beispiel Hypothetical Document Embeddings (HyDE) , die LLMs verwenden, um eine hypothetische Antwort zu generieren, die reichhaltiger und ausdrucksstärker ist als die kurze Anfrage. Die Gefahr hierbei ist natürlich, dass das hypothetische Dokument selbst eine Halluzination ist, die den LLM noch weiter vom richtigen Kontext entfernt.
Zu viele Informationen
Genau wie bei uns Menschen kann eine zu große Informationsmenge in einem Kontextfenster auch einen LLM überfordern und verwirren, sodass er nicht mehr weiß, was die wichtigen Teile sein sollen. Kontextüberlauf (oder „ Kontextverfall“) beeinträchtigt die Qualität und Leistung generativer KI-Operationen; er wirkt sich stark auf das „Aufmerksamkeitsbudget“ (das Arbeitsgedächtnis) des LLM aus und verwässert die Relevanz über viele konkurrierende Token hinweg. Zum Konzept der „Kontextverrottung“ gehört auch die Beobachtung, dass LLMs tendenziell eine Positionsverzerrung aufweisen – sie bevorzugen den Inhalt am Anfang oder Ende eines Kontextfensters gegenüber dem Inhalt im mittleren Abschnitt.
Ablenkende oder widersprüchliche Informationen
Je größer das Kontextfenster wird, desto größer ist die Wahrscheinlichkeit, dass es überflüssige oder widersprüchliche Informationen enthält, die das LLM davon ablenken können, den richtigen Kontext auszuwählen und zu verarbeiten. In gewisser Hinsicht wird es zu einem Problem von Müll rein/Müll raus: Wenn man einfach eine Reihe von Dokumentenergebnissen in ein Kontextfenster einfügt, erhält das LLM eine Menge Informationen zum Verarbeiten (möglicherweise zu viele), aber je nachdem, wie der Kontext ausgewählt wurde, besteht eine größere Wahrscheinlichkeit, dass widersprüchliche oder irrelevante Informationen einfließen.
Agentische KI
Ich hatte es Ihnen ja gesagt, es gäbe noch viel zu besprechen, aber wir haben es geschafft – wir sprechen jetzt endlich über agentenbasierte KI-Themen! Agentic AI ist eine sehr spannende neue Anwendung von LLM-Chat-Schnittstellen, die die Fähigkeit generativer KI (können wir sie schon als „Legacy“ bezeichnen?) erweitert, Antworten auf der Grundlage ihres eigenen Wissens und der von Ihnen bereitgestellten Kontextinformationen zu synthetisieren. Mit zunehmender Reife der generativen KI wurde uns bewusst, dass es ein gewisses Maß an Aufgaben und Automatisierung gibt, die LLMs übernehmen können, zunächst beschränkt auf mühsame, risikoarme Tätigkeiten, die leicht von einem Menschen überprüft/validiert werden können. Innerhalb kurzer Zeit erweiterte sich dieser anfängliche Umfang: Ein LLM-Chatfenster kann nun der Funke sein, der einen KI-Agenten dazu veranlasst, autonom zu planen, auszuführen und iterativ zu evaluieren und anzupassen, um sein festgelegtes Ziel zu erreichen. Die Agenten haben Zugriff auf die Schlussfolgerungen ihrer LLMs, den Chatverlauf und das Denkvermögen (sofern vorhanden) und verfügen außerdem über spezielle Werkzeuge, die sie zu diesem Zweck einsetzen können. Wir sehen jetzt auch Architekturen, die es einem übergeordneten Agenten ermöglichen, als Orchestrator mehrerer Unteragenten zu fungieren, von denen jeder über eigene Logikketten, Befehlssätze, Kontext und Werkzeuge verfügt.
Die Agenten sind der Einstiegspunkt in einen weitgehend automatisierten Arbeitsablauf: Sie arbeiten selbstständig, indem sie mit einem Benutzer chatten und dann mithilfe von „Logik“ ermitteln, welche Tools zur Beantwortung der Frage des Benutzers zur Verfügung stehen. Werkzeuge gelten im Vergleich zu Agenten üblicherweise als passiv und sind darauf ausgelegt, nur eine bestimmte Art von Aufgabe zu erfüllen. Die Aufgaben , die ein Tool ausführen kann, sind quasi unbegrenzt (was wirklich spannend ist!), aber eine Hauptaufgabe von Tools besteht darin, Kontextinformationen zu sammeln, die ein Agent bei der Ausführung seines Arbeitsablaufs berücksichtigen kann.
Als Technologie steckt agentenbasierte KI noch in den Kinderschuhen und ist anfällig für das LLM-Äquivalent einer Aufmerksamkeitsdefizitstörung – sie vergisst leicht, was sie tun sollte, und macht oft andere Dinge, die überhaupt nicht Teil der Aufgabenstellung waren. Hinter der scheinbaren Magie verbergen sich die „logischen“ Fähigkeiten von LLMs, die darauf beruhen, das nächste wahrscheinlichste Token in einer Sequenz vorherzusagen. Damit logisches Denken (oder eines Tages künstliche allgemeine Intelligenz (AGI)) zuverlässig und vertrauenswürdig wird, müssen wir überprüfen können, ob es bei der Bereitstellung korrekter und aktueller Informationen so argumentiert, wie wir es erwarten (und uns vielleicht noch das kleine Quäntchen mehr liefert, an das wir selbst nicht gedacht hätten). Damit dies gelingt, benötigen agentenbasierte Architekturen die Fähigkeit, klar zu kommunizieren (Protokolle), sich an die von uns vorgegebenen Arbeitsabläufe und Einschränkungen zu halten (Leitplanken), sich zu merken, wo sie sich in einer Aufgabe befinden (Zustand), ihren verfügbaren Speicherplatz zu verwalten und zu überprüfen, ob ihre Antworten korrekt sind und die Aufgabenkriterien erfüllen.
Sprich mit mir in einer Sprache, die ich verstehen kann.
Wie es in neuen Entwicklungsbereichen üblich ist (insbesondere in der Welt der LLMs), gab es anfänglich eine ganze Reihe von Ansätzen für die Kommunikation zwischen Agent und Werkzeug, aber sie einigten sich schnell auf das Model Context Protocol (MCP) als De-facto-Standard. Die Definition des Model Context Protocol steckt bereits im Namen – es ist das Protokoll, das ein Modell verwendet, um Kontextinformationen anzufordern und zu empfangen. MCP fungiert als universeller Adapter für LLM-Agenten, um Verbindungen zu externen Tools und Datenquellen herzustellen; es vereinfacht und standardisiert die APIs, sodass verschiedene LLM-Frameworks und -Tools problemlos interoperabel sind. Das macht MCP zu einer Art Dreh- und Angelpunkt zwischen der Orchestrierungslogik und den Systemaufforderungen, die einem Agenten zur autonomen Ausführung im Dienste seiner Ziele gegeben werden, und den Operationen, die an Werkzeuge gesendet werden, um sie isolierter auszuführen (zumindest isoliert in Bezug auf den initiierenden Agenten).
Dieses Ökosystem ist so neu, dass sich jede Expansionsrichtung wie ein neues Terrain anfühlt. Wir verfügen über ähnliche Protokolle für Agent-zu-Agent-Interaktionen (Agent2Agent (A2A) natürlich!) sowie über andere Projekte zur Verbesserung des Agenten-Schlussfolgerungsgedächtnisses (ReasoningBank), zur Auswahl des besten MCP-Servers für die jeweilige Aufgabe (RAG-MCP) und zur Verwendung semantischer Analysen wie Zero-Shot-Klassifizierung und Mustererkennung bei Ein- und Ausgaben als Leitplanken , um zu steuern, worauf ein Agent zugreifen darf.
Möglicherweise ist Ihnen aufgefallen, dass das zugrundeliegende Ziel jedes dieser Projekte darin besteht, die Qualität und Kontrolle der Informationen zu verbessern, die an ein Agenten-/genAI-Kontextfenster zurückgegeben werden? Während das agentenbasierte KI-Ökosystem seine Fähigkeit zur besseren Verarbeitung dieser Kontextinformationen stetig weiterentwickelt (um sie zu kontrollieren, zu verwalten und darauf zu reagieren), wird es immer notwendig sein, die relevantesten Kontextinformationen als Grundlage für die Aktionen des Agenten abzurufen.
Willkommen im Kontext-Engineering!
Wer mit Begriffen aus dem Bereich der generativen KI vertraut ist, hat wahrscheinlich schon von „Prompt Engineering“ gehört – mittlerweile ist es fast schon eine eigene Pseudowissenschaft. Prompt Engineering wird eingesetzt, um die besten und effizientesten Wege zu finden, die Verhaltensweisen, die das LLM bei der Generierung seiner Antwort verwenden soll, proaktiv zu beschreiben. „Context Engineering “ erweitert die Techniken des „Prompt Engineering“ über die Agentenseite hinaus und umfasst auch verfügbare Kontextquellen und -systeme auf der Werkzeugseite des MCP-Protokolls sowie die umfassenden Themen Kontextmanagement, -verarbeitung und -generierung:
- Kontextmanagement – Bezieht sich auf die Aufrechterhaltung der Zustands- und Kontexteffizienz in langlaufenden und/oder komplexeren agentenbasierten Arbeitsabläufen. Iterative Planung, Nachverfolgung und Orchestrierung von Aufgaben und Werkzeugaufrufen zur Erreichung der Ziele des Agenten. Da Agenten nur über ein begrenztes „Aufmerksamkeitsbudget“ verfügen, befasst sich das Kontextmanagement hauptsächlich mit Techniken, die dazu beitragen, das Kontextfenster so zu verfeinern, dass sowohl der größtmögliche Umfang als auch die wichtigsten Kontextinformationen erfasst werden (Präzision versus Trefferquote!). Zu den Techniken gehören Komprimierung, Zusammenfassung und Beibehaltung des Kontextes aus vorherigen Schritten oder Werkzeugaufrufen, um im Arbeitsspeicher Platz für zusätzlichen Kontext in nachfolgenden Schritten zu schaffen.
- Kontextverarbeitung – Die logischen und hoffentlich größtenteils programmatischen Schritte zur Integration, Normalisierung oder Verfeinerung des aus unterschiedlichen Quellen gewonnenen Kontextes, damit der Agent den gesamten Kontext auf eine einigermaßen einheitliche Weise verarbeiten kann. Die grundlegende Aufgabe besteht darin, Kontext aus allen Quellen (Eingabeaufforderungen, RAG-System, Speicher usw.) so aufzubereiten, dass er vom Agenten möglichst effizient genutzt werden kann.
- Kontextgenerierung – Wenn es bei der Kontextverarbeitung darum geht, den abgerufenen Kontext für den Agenten nutzbar zu machen, dann gibt die Kontextgenerierung dem Agenten die Möglichkeit, diese zusätzlichen Kontextinformationen nach Belieben, aber auch unter bestimmten Einschränkungen, anzufordern und zu empfangen.
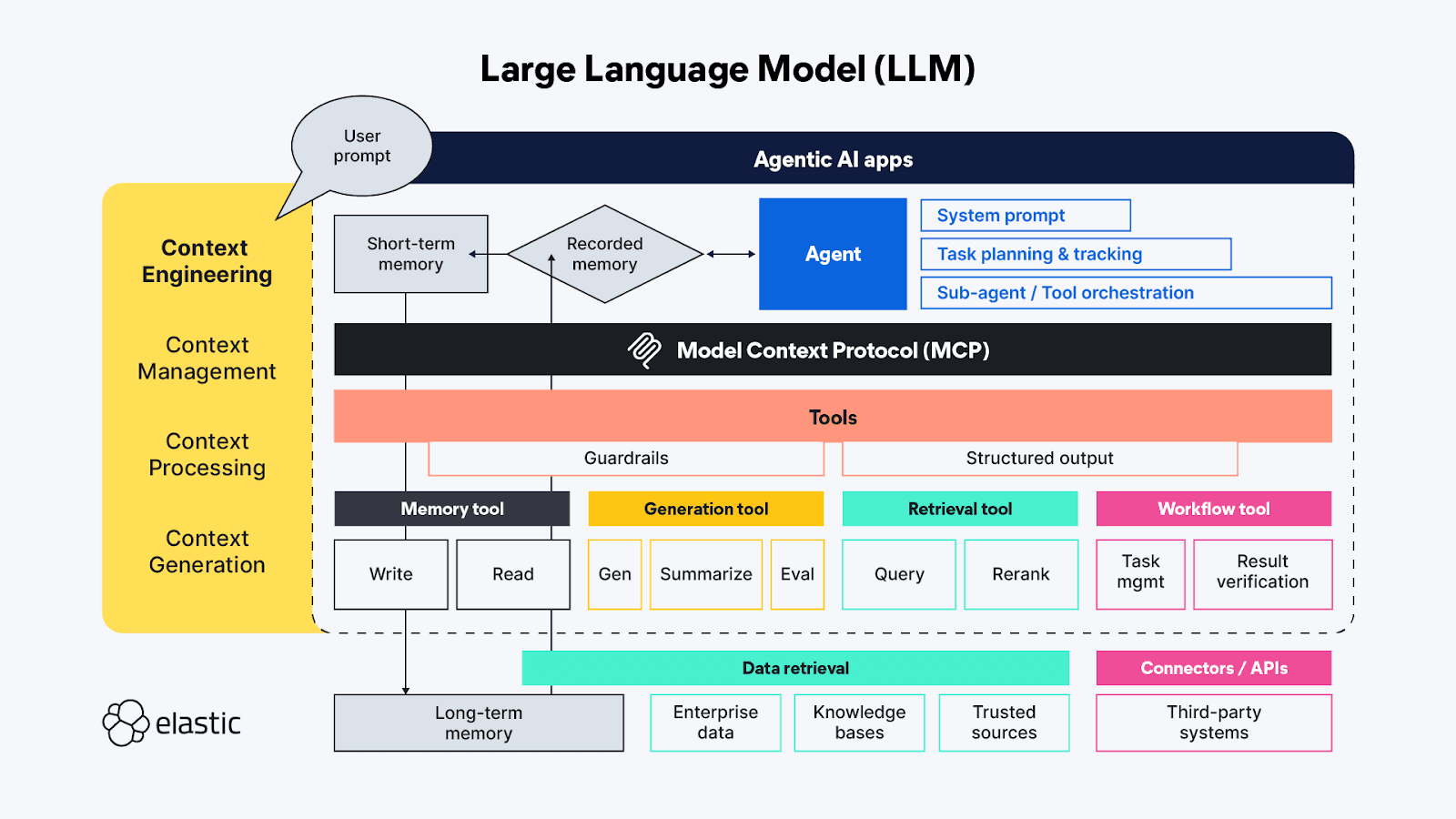
Die verschiedenen Elemente von LLM-Chatanwendungen lassen sich direkt (und manchmal auch überlappend) auf jene übergeordneten Funktionen des Kontextmanagements abbilden:
- Anweisungen / Systemaufforderung - Die Aufforderungen dienen als Gerüst dafür, wie die generative (oder agentenbasierte) KI-Aktivität ihr Denken auf die Erreichung des Ziels des Benutzers ausrichtet. Eingabeaufforderungen stellen einen eigenen Kontext dar; sie sind nicht nur tonale Anweisungen – sie beinhalten häufig auch Logik zur Aufgabenausführung und Regeln für Dinge wie „Schritt für Schritt nachdenken“ oder „tief durchatmen“, bevor man antwortet, um sicherzustellen, dass die Antwort die Anfrage des Benutzers vollständig erfüllt. Jüngste Tests haben gezeigt, dass Auszeichnungssprachen sehr effektiv sind, um die verschiedenen Teile einer Aufgabenstellung zu strukturieren. Es sollte jedoch darauf geachtet werden, die Anweisungen so zu formulieren, dass sie weder zu vage noch zu spezifisch sind; wir wollen dem LLM genügend Anweisungen geben, um den richtigen Kontext zu finden, aber nicht so präskriptiv sein, dass es unerwartete Erkenntnisse verpasst.
- Kurzzeitgedächtnis (Zustand/Verlauf) - Das Kurzzeitgedächtnis umfasst im Wesentlichen die Interaktionen der Chat-Sitzung zwischen dem Benutzer und dem LLM. Diese sind nützlich, um den Kontext in Live-Sitzungen zu verfeinern, und können zur späteren Verwendung und Fortsetzung gespeichert werden.
- Langzeitgedächtnis – Das Langzeitgedächtnis sollte Informationen enthalten, die über mehrere Sitzungen hinweg nützlich sind. Und es geht nicht nur um domänenspezifische Wissensdatenbanken, auf die über RAG zugegriffen wird; neuere Forschungen nutzen die Ergebnisse vorheriger agentischer/generativer KI-Anfragen, um innerhalb aktueller agentischer Interaktionen zu lernen und darauf zu verweisen. Zu den interessantesten Innovationen im Bereich des Langzeitgedächtnisses gehören solche, die die Art und Weise der Speicherung und Verknüpfung von Zuständen so anpassen, dass Agenten dort weitermachen können, wo sie aufgehört haben.
- Strukturierte Ausgabe - Kognition erfordert Anstrengung, daher ist es wohl keine Überraschung, dass LLMs (genau wie Menschen) selbst mit Denkfähigkeiten beim Denken weniger Anstrengung aufwenden wollen, und in Ermangelung einer definierten API oder eines Protokolls ist eine Karte (ein Schema) für das Lesen der von einem Toolaufruf zurückgegebenen Daten äußerst hilfreich. Die Einbeziehung strukturierter Ausgaben in das agentenbasierte Framework trägt dazu bei, diese Interaktionen zwischen Maschinen schneller und zuverlässiger zu gestalten, wodurch weniger gedankengesteuertes Parsen erforderlich wird.
- Verfügbare Tools – Tools können die unterschiedlichsten Aufgaben übernehmen, von der Erfassung zusätzlicher Informationen (z. B. durch Abfragen von Unternehmensdatenbanken mittels RAG-Code oder über Online-APIs) bis hin zur Durchführung automatisierter Aktionen im Auftrag des Agenten (z. B. durch Buchung eines Hotelzimmers auf Basis der Kriterien der Anfrage des Agenten). Werkzeuge könnten auch Unteragenten mit eigenen agentenbasierten Verarbeitungsketten sein.
- Retrieval Augmented Generation (RAG) – Mir gefällt die Beschreibung von RAG als „dynamische Wissensintegration“ sehr gut. Wie bereits erwähnt, ist RAG die Technik, um die zusätzlichen Informationen bereitzustellen, auf die das LLM beim Training keinen Zugriff hatte, oder es ist eine Wiederholung der Ideen, die wir für am wichtigsten halten, um die richtige Antwort zu erhalten – diejenige, die am relevantesten für unsere subjektive Anfrage ist.
Phänomenale kosmische Energie, winziger Wohnraum!
Agentic AI bietet so viele faszinierende und aufregende neue Welten zum Erkunden! Es gibt zwar noch viele der alten, traditionellen Probleme der Datenbeschaffung und -verarbeitung zu lösen, aber auch ganz neue Herausforderungen, die erst jetzt im neuen Zeitalter der LLMs ans Licht der Öffentlichkeit treten. Viele der aktuellen Probleme, mit denen wir uns heute auseinandersetzen, hängen mit Kontextgestaltung zusammen, also damit, wie man Lernlern die zusätzlichen Kontextinformationen bereitstellt, die sie benötigen, ohne ihren begrenzten Arbeitsgedächtnisraum zu überlasten.
Die Flexibilität von halbautonomen Agenten, die Zugriff auf eine Reihe von Werkzeugen (und andere Agenten) haben, führt zu so vielen neuen Ideen für die Implementierung von KI, dass es schwer ist, sich die verschiedenen Möglichkeiten vorzustellen, wie wir die einzelnen Teile zusammensetzen könnten. Der Großteil der aktuellen Forschung fällt in den Bereich des Kontext-Engineerings und konzentriert sich auf den Aufbau von Speichermanagementstrukturen, die größere Mengen an Kontext verarbeiten und verfolgen können – denn die tiefgründigen Denkprobleme, die wir mit LLMs lösen wollen, weisen eine erhöhte Komplexität und länger andauernde, mehrphasige Denkprozesse auf, bei denen das Erinnern von extrem großer Bedeutung ist.
Viele der laufenden Experimente auf diesem Gebiet versuchen, die optimale Aufgabenverwaltung und Werkzeugkonfigurationen zu finden, um den agentenbasierten Schlund zu füttern. Jeder Werkzeugaufruf in der Argumentationskette eines Agenten verursacht kumulative Kosten, sowohl hinsichtlich des Rechenaufwands zur Ausführung der Funktion dieses Werkzeugs als auch der Auswirkungen auf das begrenzte Kontextfenster. Einige der neuesten Techniken zur Kontextverwaltung für LLM-Agenten haben unbeabsichtigte Ketteneffekte wie den „ Kontextkollaps“ verursacht, bei dem die Komprimierung/Zusammenfassung des akkumulierten Kontexts für langlaufende Aufgaben zu verlustbehaftet wird. Das angestrebte Ergebnis sind Werkzeuge, die einen prägnanten und genauen Kontext liefern, ohne dass überflüssige Informationen in den wertvollen Speicherplatz des Kontextfensters eindringen.
So viele/zu viele Möglichkeiten
Wir wollen eine klare Aufgabentrennung mit der Flexibilität, Werkzeuge/Komponenten wiederzuverwenden. Daher ist es absolut sinnvoll, dedizierte Agentenwerkzeuge für die Verbindung mit bestimmten Datenquellen zu entwickeln – jedes Werkzeug kann sich auf die Abfrage eines bestimmten Repository-Typs, eines bestimmten Datenstroms oder sogar eines bestimmten Anwendungsfalls spezialisieren. Aber Vorsicht: Im Bestreben, Zeit/Geld zu sparen/zu beweisen, dass etwas möglich ist, wird die Versuchung groß sein, LLMs als Instrument der Föderation zu nutzen… Versuchen Sie, das zu vermeiden, wir haben das schon einmal erlebt ! Die föderierte Abfrage fungiert als „universeller Übersetzer“, der eine eingehende Abfrage in die Syntax umwandelt, die das entfernte Repository versteht, und anschließend die Ergebnisse aus mehreren Quellen zu einer kohärenten Antwort zusammenführen muss. Die Federation als Technik funktioniert im kleinen Maßstab ganz gut , aber im großen Maßstab und insbesondere bei multimodalen Daten versucht die Federation, Lücken zu schließen, die einfach zu groß sind.
In der agentenbasierten Welt wäre der Agent der Föderator und die Werkzeuge (über MCP) wären die manuell definierten Verbindungen zu unterschiedlichen Ressourcen. Der Einsatz spezieller Tools zur Erfassung unverbundener Datenquellen mag zwar ein vielversprechender neuer Ansatz sein, um verschiedene Datenströme dynamisch pro Abfrage zu vereinen, doch die Verwendung von Tools, um dieselbe Frage an mehrere Quellen zu stellen, wird wahrscheinlich mehr Probleme verursachen als lösen. Bei jeder dieser Datenquellen handelt es sich wahrscheinlich um einen anderen Typ von Datenspeicher, der jeweils über eigene Funktionen zum Abrufen, Sortieren und Sichern der darin enthaltenen Daten verfügt. Diese Abweichungen oder „Impedanzfehlanpassungen“ zwischen den Repositories erhöhen natürlich die Verarbeitungslast. Außerdem können sie widersprüchliche Informationen oder Signale einbringen, wobei etwas so scheinbar Harmloses wie eine Fehlausrichtung der Bewertung die Bedeutung, die einem Teil des zurückgegebenen Kontextes beigemessen wird, stark beeinträchtigen und letztendlich die Relevanz der generierten Antwort beeinflussen kann.
Auch für Computer ist der Kontextwechsel schwierig.
Wenn man einen Agenten auf eine Mission schickt, besteht seine erste Aufgabe oft darin, alle relevanten Daten zu finden, auf die er Zugriff hat. Genau wie bei Menschen entsteht auch bei uns eine kognitive Belastung, wenn jede Datenquelle, mit der der Agent eine Verbindung herstellt, unterschiedliche und disaggregierte Antworten liefert. Diese Belastung entsteht durch das Herausfiltern der relevanten Kontextinformationen aus den abgerufenen Inhalten. Das braucht Zeit/Rechenleistung, und jedes kleine bisschen summiert sich in der agentenbasierten Logikkette. Daraus lässt sich schließen, dass, ähnlich wie bei MCP, die meisten agentenbasierten Werkzeuge sich eher wie APIs verhalten sollten – isolierte Funktionen mit bekannten Ein- und Ausgaben, die auf die Bedürfnisse verschiedener Agententypen abgestimmt sind. Wir stellen sogar fest, dass LLMs Kontext für Kontext benötigen – sie sind viel besser darin, die semantischen Punkte zu verbinden, insbesondere wenn es um eine Aufgabe wie die Übersetzung von natürlicher Sprache in strukturierte Syntax geht, wenn sie ein Schema haben, auf das sie sich beziehen können (RTFM in der Tat!).
Pause im 7. Inning!
Wir haben nun die Auswirkungen von LLMs auf das Abrufen und Abfragen von Daten sowie die Entwicklung des Chatfensters hin zu einer agentenbasierten KI-Erfahrung behandelt. Lasst uns die beiden Themen miteinander verknüpfen und sehen, wie wir unsere neuartigen Such- und Abruffunktionen nutzen können, um unsere Ergebnisse im Bereich Context Engineering zu verbessern. Weiter zu Teil III: Die Leistungsfähigkeit der hybriden Suche im Kontext-Engineering!
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.