通过无状态 Elasticsearch,我们正在投资建设一个全新的完全云本地架构,以推动规模和速度的发展。在本博客中,我们将探讨我们的起点、引入无状态架构后 Elasticsearch 的未来以及该架构的细节。
我们的起点
Elasticsearch的第一个版本于 2010 年发布,它是一个分布式可扩展搜索引擎,允许用户快速搜索并浮现关键见解。十二年过去了,Elasticsearch 的提交次数已超过 65,000 次,它将继续为用户提供久经考验的解决方案,以解决各种搜索问题。在包括数百名 Elastic 全职员工在内的 1,500 多名贡献者的努力下,Elasticsearch 不断发展,以应对搜索领域出现的新挑战。
在 Elasticsearch 诞生之初,当数据丢失的问题被提出时,Elastic 团队经过多年的努力,重写了集群协调系统,以确保确认的数据得到安全存储。当发现在大型集群中管理索引是一件麻烦事时,团队开始实施广泛的ILM 解决方案,通过允许用户预先定义索引模式和生命周期操作来实现这项工作的自动化。由于用户发现需要存储大量的度量和时间序列数据,因此增加了各种功能,如更好的压缩功能,以减少数据量。由于搜索大量冷数据的存储成本越来越高,我们投资创建了可搜索快照,作为在低成本对象存储上直接搜索用户数据的一种方式。
这些投资为 Elasticsearch 的下一步发展奠定了基础。随着云原生服务和新协调系统的发展,我们决定是时候对 Elasticsearch 进行进化,以改善使用云原生系统时的体验。我们相信,这些变化为在 Elastic Cloud 上运行 Elasticsearch 带来了改进运行、性能和成本的机会。
我们的目标--采用无状态架构
运行或协调 Elasticsearch 时面临的主要挑战之一是,它依赖于大量持久状态,因此是一个有状态的系统。这三个主要部分是 translog、索引存储和集群元数据。这种状态意味着存储必须是持久的,不会在节点重启或更换时丢失。
Elastic Cloud 上现有的 Elasticsearch 架构必须在多个可用性区域内重复索引,以便在发生故障时提供冗余。我们打算将这些数据的持久性从本地磁盘转移到对象存储,如 AWS S3。通过依靠外部服务来存储这些数据,我们将不再需要进行索引复制,从而大大减少了与摄取相关的硬件。由于 AWS S3、GCP Cloud Storage 和 Azure Blob Storage 等云对象存储跨可用区复制数据的方式,这种架构还能提供非常高的耐用性保证。
将索引存储卸载到外部服务中还能让我们通过分离索引和搜索职责来重新构建 Elasticsearch。我们打算建立一个索引层和一个搜索层,而不是让主实例和副本实例同时处理这两种工作负载。将这些工作负载分开,可以使它们独立扩展,并使硬件选择更有针对性,以满足各自的使用情况。它还有助于解决一个长期存在的难题,即搜索和索引负载会相互影响。
经过为期数月的概念验证和实验阶段,我们确信这些对象存储服务能够满足我们对索引存储和集群元数据的要求。我们的测试和基准测试表明,这些存储服务可以满足我们在 Elastic Cloud 中看到的最大集群的高索引需求。此外,将数据备份到对象存储区可降低索引成本,并可对搜索性能进行简单调整。为了搜索数据,Elasticsearch 将使用久经考验的可搜索快照(Searchable Snapshots)模型,在该模型中,数据永久保存在云原生对象存储中,而本地磁盘则用作频繁访问数据的缓存。

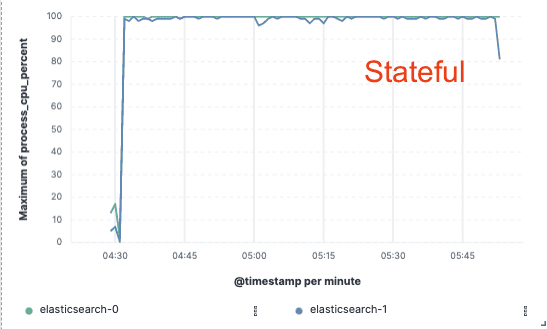
为了帮助区分,我们将现有模型描述为"节点对节点" 复制。在该模型的热层中,主分片和副本分片都承担着处理摄取和提供搜索请求的重任。这些节点是"有状态的" ,因为它们依靠本地磁盘安全地持久化所托管分片的数据。此外,主分片和副本分片不断进行通信,以保持同步。它们的做法是将主分区上执行的操作复制到副本分区上,这意味着这些操作的成本(主要是 CPU 成本)会在指定的每个副本上产生。同样的分片和节点在为收录工作提供服务的同时,也在为搜索请求提供服务,因此在进行配置和扩展时必须考虑到这两种工作负载。
除了搜索和摄取,节点到节点复制模型中的分片还负责处理其他密集型任务,如合并 Lucene 片段。虽然这种设计有其优点,但根据我们多年来从客户那里了解到的情况以及更广泛的云生态系统的演变,我们看到了很多机会。
新架构可实现许多直接和未来的改进,包括
- 在相同的硬件上,你可以大幅提高摄取吞吐量,或者换个角度看,在相同的摄取工作负载下,大幅提高效率。这一增长来自于消除了每个副本的重复索引操作。CPU 密集型的索引操作只需在索引层上进行一次,然后将生成的段传送到对象存储区。这样,搜索层就可以按原样使用数据了。
- 您可以将计算与存储分开,以简化集群拓扑结构。如今,Elasticsearch 拥有多个数据层(内容层、热层、温层、冷层和冻结层),可将数据与硬件配置文件相匹配。热层用于近实时搜索,冷冻层用于搜索频率较低的数据。这些层级在提供价值的同时,也增加了复杂性。在新架构中,不再需要数据层,从而简化了 Elasticsearch 的配置和操作。我们还将索引与搜索分离开来,这进一步降低了复杂性,并使我们能够独立扩展这两种工作负载。
- 通过减少必须存储在本地磁盘上的数据量,索引层的存储成本可以得到改善。目前,Elasticsearch 必须在热节点(主节点和副本节点)上存储完整的分片副本,以便编制索引。采用无状态方法,直接在对象存储区建立索引,只需要部分本地数据。对于只进行追加的用例,只需存储某些元数据以编制索引。这将大大减少索引所需的本地存储空间。
- 您可以降低与搜索查询相关的存储成本。通过将 "可搜索快照 "模式作为搜索数据的本机模式,与搜索查询相关的存储成本将大大降低。根据用户对搜索延迟的需求,Elasticsearch 将允许对频繁请求的数据进行调整,以增加本地缓存。
基准测试 - 75% 索引吞吐量改进
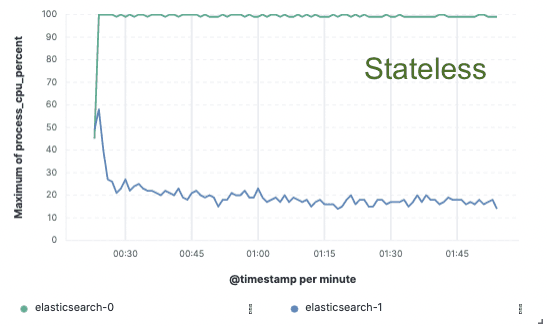
为了验证这种方法,我们实施了一个广泛的概念验证,其中数据仅在单个节点上编制索引,并通过云对象存储实现复制。我们发现,通过消除对索引复制专用硬件的需求,我们可以将索引吞吐量提高 75% 。此外,仅从对象存储中提取数据所需的 CPU 成本远低于编制数据索引和本地写入数据的成本,而这正是目前热层所必需的。这意味着搜索节点可以将其 CPU 全部用于搜索。
这些性能测试是在一个双节点集群上针对三大公共云提供商(AWS、GCP 和 Azure)进行的。我们打算在实现无状态生产的过程中,继续建立更大的基准。
索引吞吐量


CPU 使用率
我们无国籍,你们有储蓄
Elastic Cloud 上的无状态架构可让您减少索引开销,独立扩展摄取和搜索,简化数据层管理,并加快扩展或升级等操作。这是实现弹性云平台实质性现代化的第一个里程碑。
成为 Elasticsearch 无状态愿景的一部分
有兴趣抢先尝试这种解决方案吗?您可以在讨论区或我们的社区休闲频道与我们联系。我们希望您能提供反馈意见,帮助我们确定新架构的方向。
相关内容
2026年5月18日
一次查询,多个 Elasticsearch Serverless 项目:隆重推出跨项目搜索
Elastic Cloud Serverless 中的跨项目搜索允许您在单个 Elasticsearch 或 ES|QL 请求中查询跨隔离项目的数据:无需重复、无需网络对等,也无需因复制日志而产生出口成本。

2026年4月20日
为 Elastic Cloud Serverless 和 Elasticsearch 引入统一的 API 密钥。
了解 Elastic 如何通过全局分布式 IAM 架构,在 Serverless 中统一控制平面与数据平面的身份验证。使用同一 API 密钥访问 Cloud 和 Elasticsearch API。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。

2026年3月24日
在无服务器环境中实现负载均衡的 Elasticsearch 副本
了解 Elastic Cloud Serverless 如何根据搜索负载自动调整索引副本,无需手动配置即可确保最佳查询性能。