在构建可靠的人工智能代理和架构方面,情境工程正变得越来越重要。随着模型越来越完善,其有效性和可靠性已不再依赖于训练有素的数据,而更多地取决于模型在正确环境中的立足程度。能够在正确的时间检索和应用最相关信息的代理更有可能产生准确和可信的输出结果。
在本博客中,我们将使用Mastra构建一个知识代理,它能记住用户所说的话,并能在稍后调用相关信息,使用 Elasticsearch 作为记忆和检索后端。您可以轻松地将这一概念扩展到现实世界的使用案例中,例如,支持代理可以记住过去的对话和解决方案,使他们能够根据先前的上下文为特定用户定制响应或更快地提供解决方案。
在这里,您将看到如何一步一步地建造它。如果你迷失了方向,或者只是想运行一个已完成的示例,请点击此处查看软件仓库。
什么是 Mastra?
Mastra 是一个开源的 TypeScript 框架,用于构建具有可交换推理、内存和工具部分的人工智能代理。它的语义调用功能通过将信息作为嵌入信息存储在向量数据库中,使代理能够记住和检索过去的互动。这样,代理就能保留长期对话的上下文和连续性。Elasticsearch 支持高效的密集矢量搜索,是实现这一功能的绝佳矢量存储工具。当触发语义调用时,代理会将过去的相关信息拉入模型的上下文窗口,使模型能够将检索到的上下文作为其推理和响应的基础。
入门必备
- 节点 v18+
- Elasticsearch(8.15 或更新版本)
- Elasticsearch API 密钥
- OpenAI API 密钥
注意:您需要这个是因为演示使用了 OpenAI 提供商,但 Mastra 支持其他人工智能 SDK 和社区模型提供商,因此您可以根据自己的设置轻松更换。
构建 Mastra 项目
我们将使用 Mastra 内置的 CLI 为我们的项目提供脚手架。运行该命令:
您将收到一组提示,首先是
1.为项目命名。

2.我们可以保留默认值,也可以不填。

3.在本项目中,我们将使用 OpenAI 提供的模型。

4.选择 "暂时跳过 "选项,因为我们将把所有环境变量存储在一个".env "文件中,稍后再进行配置。

5.我们也可以跳过该选项。

跳过安装 Mastra 的 MCP 服务器
初始化完成后,我们就可以进入下一步。
安装依赖项
接下来,我们需要安装一些依赖项:
ai- 核心人工智能 SDK 软件包,提供用于在 JavaScript/TypeScript 中管理人工智能模型、提示和工作流程的工具。Mastra 是在 Vercel 的人工智能 SDK基础上构建的,因此我们需要依赖它来实现模型与代理的交互。@ai-sdk/openai- 将 AI SDK 连接到 OpenAI 模型(如 GPT-4、GPT-4o 等)的插件,可使用 OpenAI API 密钥进行 API 调用。@elastic/elasticsearch-Node.js 的官方 Elasticsearch 客户端、用于连接到弹性云或本地集群,以进行索引、搜索和矢量操作。dotenv- 从 .env 文件中加载环境变量文件到 process.env 文件中、允许您安全地注入 API 密钥和 Elasticsearch 端点等凭证。
配置环境变量
如果还没有.env 文件,请在项目根目录下创建该文件。或者,你也可以复制并重命名我在软件仓库中提供的.env 示例。在该文件中,我们可以添加以下变量:
基本设置到此结束。从这里,您就可以开始构建和协调代理。我们将更进一步,添加 Elasticsearch 作为存储和矢量搜索层。
添加 Elasticsearch 作为向量存储
新建一个名为stores 的文件夹,并在其中添加此文件。在 Mastra 和 Elastic 正式推出 Elasticsearch 向量存储集成之前,Abhi Aiyer(Mastra 首席技术官)分享了名为ElasticVector 的早期原型类。简单地说,它将 Mastra 的内存抽象与 Elasticsearch 的密集向量功能连接起来,因此开发人员可以将 Elasticsearch 作为其代理的向量数据库。
让我们深入了解整合的重要部分:
输入 Elasticsearch 客户端
本节定义了ElasticVector 类,并设置了 Elasticsearch 客户端连接,同时支持标准部署和无服务器部署。
ElasticVectorConfig extends ClientOptions:这将创建一个新的配置接口,继承所有 Elasticsearch 客户端选项(如node,auth,requestTimeout)并添加我们的自定义属性。这意味着用户可以通过任何有效的 Elasticsearch 配置和我们的无服务器特定选项。extends MastraVector:这样,ElasticVector就可以继承 Mastra 的基础MastraVector类,这是所有矢量存储集成都要遵守的通用接口。这可以确保从代理的角度来看,Elasticsearch 的行为与其他任何 Mastra 向量后端一样。private client: Client:这是一个私有属性,用于保存 Elasticsearch JavaScript 客户端的实例。这样,班级就可以直接与群集对话。isServerless和deploymentChecked:这些属性共同作用,以检测和缓存我们连接的是无服务器还是标准 Elasticsearch 部署。首次使用时会自动检测,也可以明确配置。constructor(config: ClientOptions):该构造函数接收一个配置对象(包含 Elasticsearch 凭据和可选的无服务器设置),并使用它在this.client = new Client(config)行中初始化客户端。super():它调用 Mastra 的基本构造函数,因此继承了日志记录、验证助手和其他内部钩子。
此时,Mastra 知道有一个名为 ElasticVector
检测部署类型
在创建索引之前,适配器会自动检测您使用的是标准 Elasticsearch 还是 Elasticsearch Serverless。这一点很重要,因为无服务器部署不允许手动配置分片。
发生了什么?
- 首先检查您是否在配置中明确设置了
isServerless(跳过自动检测)。 - 调用 Elasticsearch 的
info()API 获取群集信息 - 检查
build_flavor field(无服务器部署返回serverless) - 如果没有 "构建味道",则退回到检查标语阶段
- 缓存结果,避免重复调用应用程序接口
- 如果检测失败,则默认为标准部署
使用示例
在 Elasticsearch 中创建 "内存 "存储
下面的函数设置了一个 Elasticsearch 索引,用于存储嵌入式内容。它会检查索引是否已经存在。如果没有,它就会用下面的映射创建一个,其中包含一个dense_vector 字段,用于存储嵌入和自定义相似度度量。
有些事情需要注意:
dimension参数是每个嵌入向量的长度,这取决于你使用的嵌入模型。在我们的例子中,我们将使用 OpenAI 的text-embedding-3-small模型生成嵌入,该模型输出大小为1536的向量。我们将以此作为默认值。- 下面的映射中使用的
similarity变量是由辅助函数 const similarity = this.mapMetricToSimilarity(metric)定义的,该函数接收metric参数的值,并将其转换为与 Elasticsearch 兼容的关键字,用于所选的距离度量。- 例如Mastra 使用
cosine,euclidean, 和dotproduct等一般术语来表示向量相似性。如果我们直接将度量euclidean传递到 Elasticsearch 映射中,就会出现错误,因为 Elasticsearch 希望关键字l2_norm代表欧氏距离。
- 例如Mastra 使用
- 无服务器兼容性:代码会自动省略无服务器部署的分片和副本设置,因为 Elasticsearch Serverless 会自动管理这些设置。
互动后存储新的记忆或笔记
该函数接收每次交互后生成的新嵌入以及元数据,然后使用 Elastic 的bulk API 将其插入或更新到索引中。bulk API 将多个写入操作合并为一个请求;索引性能的提升确保了在代理内存不断增长的情况下,更新仍能保持高效。
查询相似向量以实现语义召回
该功能是语义召回功能的核心。代理使用向量搜索,在我们的索引中找到类似的存储嵌入。
引擎盖下
- 使用 Elasticsearch 中的
knnAPI 运行kNN(k-近邻)查询。 - 检索与输入查询向量最相似的 K 个向量。
- 可选择应用元数据过滤器来缩小搜索结果范围(例如,仅在特定类别或时间范围内进行搜索)
- 返回结构化结果,包括文档 ID、相似性得分和存储的元数据。
创建知识代理
现在,我们已经通过ElasticVector 集成看到了 Mastra 和 Elasticsearch 之间的连接,让我们来创建知识代理本身。
在agents 文件夹中,创建一个名为knowledge-agent.ts 的文件。我们可以从连接环境变量和初始化 Elasticsearch 客户端开始。
在这里,我们
- 使用
dotenv从.env文件中加载变量。 - 检查 Elasticsearch 凭据是否被正确注入,我们是否能成功建立与客户端的连接。
- 在
ElasticVector构造函数中输入 Elasticsearch 端点和 API 密钥,以创建我们之前定义的向量存储实例。 - 如果使用 Elasticsearch Serverless,可选择指定
isServerless: true。这样可以跳过自动检测步骤,缩短启动时间。如果省略,适配器将在首次使用时自动检测您的部署类型。
接下来,我们可以使用 Mastra 的Agent 类来定义代理。
我们可以定义的字段有
name和instructions:赋予其特性和主要功能。model:我们通过@ai-sdk/openai软件包使用 OpenAI 的gpt-4o。memory:vector:指向我们的 Elasticsearch 存储库,因此嵌入式会从那里存储和检索。embedder:使用哪种模型生成嵌入模型semanticRecall选项决定召回如何进行:topK:检索多少条语义相似的信息。messageRange:每场比赛应包括多少对话内容。scope:定义内存边界。
快好了我们只需将新创建的代理添加到 Mastra 配置中。在名为index.ts 的文件中,导入知识代理并将其插入agents 字段。
其他领域包括
storage:这是 Mastra 的内部数据存储,用于存储运行历史、可观察性指标、分数和缓存。有关 Mastra 存储的更多信息,请访问此处。logger:Mastra 使用Pino,这是一个轻量级结构化 JSON 日志记录器。它可捕捉代理启动和停止、工具调用和结果、错误以及 LLM 响应时间等事件。observability:控制人工智能跟踪和代理执行的可见性。它可以跟踪- 每个推理步骤的开始/结束。
- 使用了哪种模式或工具。
- 输入和输出。
- 分数和评估
使用 Mastra Studio 测试代理
祝贺你如果您已经到达这里,那么您就可以运行这个代理,测试它的语义回忆能力了。幸运的是,Mastra 提供了一个内置的聊天用户界面,这样我们就不必自己创建了。
要启动 Mastra 开发服务器,请打开终端并运行以下命令:
在初始捆绑和启动服务器后,它应该会为你提供一个 Playground 的地址。

将此地址粘贴到浏览器中,您将看到 Mastra Studio。
选择knowledgeAgent ,然后开始聊天。
为了快速测试一切接线是否正确,请给它提供一些信息,如 "团队宣布 10 月份的销售业绩增长了 12% ,主要是由企业续订驱动的。下一步是扩大对中端市场客户的拓展"。下一步,开始新的聊天,并提问:"我们说过下一步需要关注哪个客户群?知识代理应该能够回忆起您在第一次聊天中提供给它的信息。您应该会看到类似的回复:

看到这样的响应,意味着代理成功地将我们之前的信息以嵌入的形式存储在 Elasticsearch 中,并在稍后使用向量搜索进行检索。
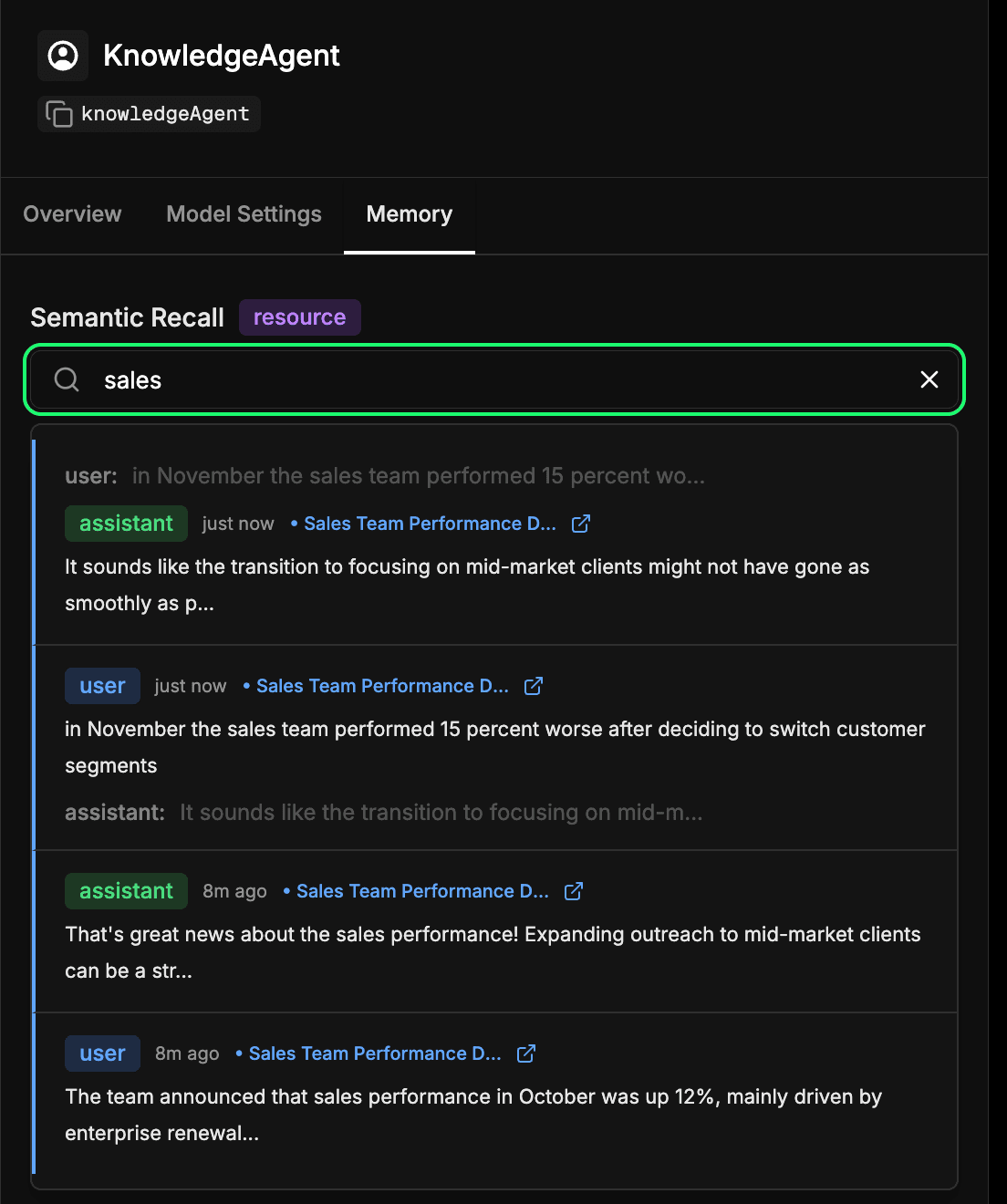
检查代理的长期记忆存储
在 Mastra Studio 的代理配置中,前往memory 选项卡。这可以让您了解您的代理随着时间的推移学到了什么。嵌入并存储在 Elasticsearch 中的每一条消息、响应和交互都会成为长期记忆的一部分。您可以对过去的交互进行语义搜索,以快速找到代理之前了解到的信息或上下文。这与代理在语义回想时使用的机制基本相同,但在这里你可以直接检查它。在下面的示例中,我们搜索 "销售 "一词,并返回所有包含销售内容的互动。
结论
通过连接 Mastra 和 Elasticsearch,我们可以为代理提供内存,这是上下文工程的关键层。有了语义记忆功能,代理可以随着时间的推移建立上下文,将他们的反应建立在所学知识的基础上。这意味着更准确、更可靠、更自然的互动。
早期的整合只是一个起点。同样的模式可以让支持代理记住过去的票单,让内部机器人检索相关文档,或者让人工智能助理在对话中回忆起客户的详细信息。我们还在努力实现与 Mastra 的正式集成,以便在不久的将来使这种搭配更加完美。
我们很期待看到您的下一个作品。试试吧,探索Mastra及其内存功能,并随时与社区分享您的发现。
相关内容

2026年5月11日
为 Elasticsearch 注入活力:添加对原生 Prometheus API 的支持
通过原生 PromQL、发现及元数据终端,从兼容 Prometheus 的客户端直接查询 Elasticsearch。使用 Prometheus Remote Write 将数据发送到 Elasticsearch。

2026年4月20日
为 Elastic Cloud Serverless 和 Elasticsearch 引入统一的 API 密钥。
了解 Elastic 如何通过全局分布式 IAM 架构,在 Serverless 中统一控制平面与数据平面的身份验证。使用同一 API 密钥访问 Cloud 和 Elasticsearch API。

2026年4月8日
如何使用 Mastra 和 Elasticsearch 构建代理式 AI 应用程序
通过一个实际示例,了解如何使用 Mastra 和 Elasticsearch 构建智能体 AI 应用。
2026年4月3日
使用 Elastic 工作流监测 Kibana 仪表板的浏览情况
了解如何使用 Elastic 工作流每 30 分钟收集一次 Kibana 仪表板视图指标,并将其索引到 Elasticsearch 中,以便您可以基于自己的数据构建自定义分析和可视化。
