本文是系列文章的第一篇,介绍如何使用 JavaScript 使用 Elasticsearch。在本系列中,您将学习如何在 JavaScript 环境中使用 Elasticsearch 的基础知识,并回顾创建搜索应用程序的最相关功能和最佳实践。最后,您将了解使用 JavaScript 运行 Elasticsearch 所需的一切。
在第一部分中,我们将回顾
您可以 在这里查看示例的源代码 。
什么是 Elasticsearch Node.js 客户端?
Elasticsearch Node.js 客户端是一个 JavaScript 库,它将 Elasticsearch API 的 HTTP REST 调用放到了 JavaScript 中。这样就能更轻松地处理和使用帮助程序,简化批量编制文档索引等任务。
环境
前端、后端还是无服务器?
要使用 JavaScript 客户端创建搜索应用程序,我们至少需要两个组件:Elasticsearch 集群和运行客户端的 JavaScript 运行时。
JavaScript 客户端支持所有 Elasticsearch 解决方案(云、on-prem 和 Serverless),它们之间没有重大区别,因为客户端内部会处理所有变化,所以你不必担心使用哪一种。
不过,JavaScript 运行时必须从服务器运行,而不能直接从浏览器运行。
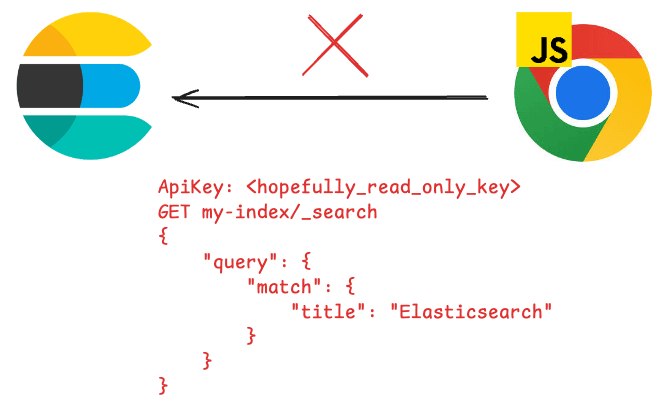
这是因为从浏览器调用 Elasticsearch 时,用户可能会获得敏感信息,如集群 API 密钥、主机或查询本身。Elasticsearch 建议永远不要将集群直接暴露在互联网上 ,而是使用一个中间层来抽象所有这些信息,这样用户只能看到参数。您可以在这里了解更多相关信息。
我们建议使用这样的模式:

在这种情况下,客户端只向服务器发送搜索条件和验证密钥,而服务器则完全控制查询和与 Elasticsearch 的通信。
连接客户端
首先,按照以下步骤创建一个 API 密钥。
按照前面的示例,我们将创建一个简单的 Express 服务器,并使用 Node.JS 服务器的客户端连接到该服务器。
我们将使用 NPM 初始化项目,并安装 Elasticsearch 客户端和Express。后者是一个在 Node.js 中调用服务器的库。使用 Express,我们可以通过 HTTP 与后端交互。
让我们初始化项目:
npm init -y
安装依赖项:
npm install @elastic/elasticsearch express split2 dotenv
让我来为你分析一下:
- @elastic/elasticsearch:它是 Node.js 的官方客户端
- 快递:它将使我们能够运行一个轻量级的 nodejs 服务器,以暴露 Elasticsearch
- split2: 将文本行分割成数据流。每次处理一行 ndjson 文件时非常有用
- dotenv:允许我们使用 .env 管理环境变量文件
创建 .env文件,并添加以下几行:
这样,我们就可以使用dotenv 软件包导入这些变量。
创建server.js 文件:
这段代码设置了一个基本的 Express.js 服务器,该服务器监听端口 3000,并使用 API 密钥进行身份验证,连接到 Elasticsearch 集群。它包括一个 /ping 端点,通过 GET 请求访问时,可使用 Elasticsearch 客户端的.info() 方法查询 Elasticsearch 集群的基本信息。
如果查询成功,会以 JSON 格式返回群集信息;否则会返回错误信息。服务器还使用 body-parser 中间件来处理 JSON 请求体。
运行文件,启动服务器:
node server.js
答案应该是这样的
现在,让我们查阅端点/ping ,检查 Elasticsearch 集群的状态。
编制文件索引
一旦连接起来,我们就可以使用语义_文本(用于语义搜索)和文本(用于全文查询)等映射对文档进行索引。有了这两种字段类型,我们还可以进行混合搜索。
我们将创建一个新的load.js 文件来生成映射并上传文件。
Elasticsearch 客户端
我们首先需要对客户端进行实例化和身份验证:
语义映射
我们将创建一个包含兽医院数据的索引。我们将保存主人、宠物和访问详情的信息。
我们要进行全文搜索的数据,如名称和描述,将以文本形式存储。类别中的数据,如动物的种类或品种,将以关键字的形式存储。
此外,我们还将把所有字段的值复制到一个 semantic_text 字段中,以便也能针对这些信息运行语义搜索。
批量助手
客户端的另一个优势是,我们可以使用批量助手来分批建立索引。通过批量辅助器,我们可以轻松处理并发、重试等问题,以及如何处理通过函数成功或失败的每个文档。
该助手的一个吸引人的特点是可以使用数据流。该功能允许您逐行发送文件,而不是将整个文件存储在内存中并一次性发送到 Elasticsearch。
要将数据上传到 Elasticsearch,请在项目根目录下创建名为 data.ndjson 的文件,并添加以下信息(也可以从此处下载包含数据集的文件):
我们使用 split2 对文件行进行流式处理,而批量助手则将它们发送到 Elasticsearch。
上面的代码读取 .ndjson文件,并使用helpers.bulk 方法将每个 JSON 对象批量索引到指定的 Elasticsearch 索引中。它使用createReadStream 和split2 对文件进行流式处理,为每个文件设置索引元数据,并记录处理失败的文件。完成后,它会记录成功索引的项目数。
除indexData 功能外,您还可以使用 Kibana 直接通过用户界面上传文件,并使用上传数据文件用户界面。
我们运行文件,将文件上传到 Elasticsearch 集群。
node load.js
在 Elasticsearch 中搜索数据
回到server.js 文件,我们将创建不同的端点来执行词法、语义或混合搜索。
简而言之,这些类型的搜索并不相互排斥,而是取决于您需要回答的问题类型。
| 查询类型 | 用例 | 问题示例 |
|---|---|---|
| 词法查询 | 问题中的单词或词根很可能出现在索引文件中。问题与文件之间的标记相似性。 | 我在找一件蓝色运动 T 恤。 |
| 语义查询 | 问题中的词语不可能出现在文件中。问题与文件之间的概念相似性。 | 我在寻找适合寒冷天气穿的衣服。 |
| 混合搜索 | 问题包含词汇和/或语义成分。问题与文档之间的标记和语义相似性。 | 我想为海滩婚礼找一件 S 码的礼服。 |
问题的词汇 部分很可能是标题和说明的一部分,或者是类别名称,而语义 部分则是与这些领域相关的概念。蓝色可能是一个类别名称或描述的一部分,海滩婚礼不太可能是,但可以与亚麻服装在语义上相关。
词法查询 (/search/lexic?q=<query_term>)
词法搜索也称全文搜索,是指基于标记的相似性进行搜索;也就是说,经过分析后,将返回包含搜索标记的文档。
您可以点击此处查看我们的词法搜索实践教程。
我们测试:修剪指甲
请回答:
语义查询 (/search/semantic?q=<query_term>)
语义搜索与词汇搜索不同,它通过矢量搜索找到与搜索词含义相似的结果。
您可以点击这里查看我们的语义搜索实践教程。
我们进行测试:谁做了修脚?
请回答:
混合查询 (/search/hybrid?q=<query_term>)
混合搜索允许我们将语义搜索和词法搜索结合起来,从而获得两全其美的效果:既能获得标记搜索的精确性,又能获得语义搜索的意义接近性。
我们以 "谁做了修脚或牙科治疗?"
响应:
结论
在本系列的第一部分中,我们介绍了如何按照客户端/服务器最佳实践设置环境并创建带有不同搜索端点的服务器,以查询 Elasticsearch 文档。查看我们系列的第二部分,您将了解生产最佳实践以及如何在无服务器环境中运行 Elasticsearch Node.js 客户端。
常见问题
什么是 Node.js 客户端?
Node.js 客户端是一个 JavaScript 库,用于将 Elasticsearch API 的 HTTP REST 调用封装成 JavaScript 接口。它还提供了一些辅助方法,可简化批量索引文档等任务。
为何应使用服务器端的 Node.js 环境,而不是在前端直接调用 Elasticsearch?
安全性是其主要优势。在后端环境(例如使用 Express 的 Node.js)中运行客户端,可避免集群 API 密钥、端点 URL 及内部查询逻辑等敏感信息暴露在浏览器端。
在 Node.js 中使用 Elasticsearch “Bulk Helper” 有哪些优势?
在 Node.js 中使用 Elasticsearch “Bulk Helper” 有哪些优势? 批量索引:它自动处理按组而非逐个对文档进行索引的复杂性。 流式支持:借助 split2 等工具,您可以对 .ndjson 等文件进行流式读取并按行处理。。这样一来,无需将整个数据集加载到服务器内存即可处理海量文件。
相关内容

2025年11月14日
如何在 Azure AKS 上自动部署 Elasticsearch
了解如何使用 AKS Automatic 和 ECK 在 Azure 上部署带有 Kibana 的 Elasticsearch,以实现部分托管的 Elasticsearch 设置配置。


介绍 Kibana 中的 Elasticsearch 查询规则用户界面
了解如何使用 Elasticsearch 查询规则用户界面,在 Kibana 中使用可定制的规则集从搜索查询中添加或排除文档,而不影响有机排名。

2025年10月3日
如何在 AWS Marketplace 上部署 Elasticsearch
通过这份分步指南,您将了解如何在 AWS Marketplace 上使用 Elastic Cloud Service 来设置和运行 Elasticsearch。
