如今,在 Elastic,我们也像其他人一样,全力投入到聊天、代理和 RAG 中。在搜索部门,我们最近一直在开发代理生成器和工具注册表,目的都是为了简化在 Elasticsearch 中与数据 "聊天 "的过程。
请阅读 " 利用 Elasticsearch 构建人工智能代理工作流 "博客 ,了解更多有关这项工作的 "全貌",或阅读 " 你的第一个弹性代理" 博客 ,了解更多有关这项工作的实用入门知识 :从单个查询到人工智能驱动的聊天 》,了解更多实用入门知识。
不过,在本博客中,我们将放大一些,看看当您开始聊天时最先发生的事情之一,并向您介绍我们最近做出的一些改进。
这里发生了什么?

当您与 Elasticsearch 数据聊天时,我们默认的人工智能代理会执行此标准流程:
- 检查提示。
- 确定哪个索引可能包含该提示的答案。
- 根据提示为该索引生成查询。
- 使用该查询搜索该索引。
- 综合结果。
- 结果能否解决提示问题?如果是,请回答。如果不行,就重复,但要尝试不同的方法。
这看起来并不新奇--它只是检索增强一代(RAG)。正如您所期望的那样,回复的质量在很大程度上取决于初始搜索结果的相关性。因此,在我们努力提高响应质量的过程中,我们一直在密切关注在第 3 步中生成和在第 4 步中运行的查询。我们注意到一个有趣的模式。
通常情况下,当我们的首次响应 "糟糕 "时,并不是因为我们运行了一个糟糕的查询。这是因为我们选错了要查询的索引。第 3 步和第 4 步通常不是我们的问题,问题在于第 2 步。
我们在做什么?
我们最初的实施很简单。我们建立了一个工具(名为 index_explorer),它可以有效地进行_cat/indices ,列出我们可用的所有索引,然后要求 LLM 识别这些索引中哪个最符合用户的信息/问题/提示。您可以 在这里 看到 最初的实施方案 。
效果如何?我们不确定!我们有一些效果不佳的明显例子,但我们真正面临的第一个挑战是如何量化我们的现状。
确定基线
从数据开始
我们需要的是一个 "黄金数据集",用于衡量工具在用户提示和已有索引集的情况下选择正确索引的效率。而我们手头并没有这样的数据集,所以我们生成了一个。
致谢:我们知道,这不是 "最佳做法"。但有时,前进总比骑自行车好。进步,简单完美。
我们利用这一提示为多个不同领域生成了种子指数。然后,对于每个生成的域,我们使用 该提示又生成了几个索引(目的是用硬否定和难以分类的示例给 LLM 制造混乱)。接下来,我们手动编辑了每个生成的索引及其说明。最后,我们使用该提示生成了测试查询:

和测试用例,如
创建测试线束
从这里开始的过程非常简单。脚本工具可以
- 使用目标 Elasticsearch 集群建立一片净土。
- 创建目标数据集中定义的所有索引。
- 针对每个测试场景,执行 i
ndex_explorer工具(很方便,我们有一个执行工具 API)。 - 将结果索引与预期索引进行比较,并捕捉结果。
- 完成所有测试方案后,将结果制成表格。
调查说...
不出所料,最初的成果平平。
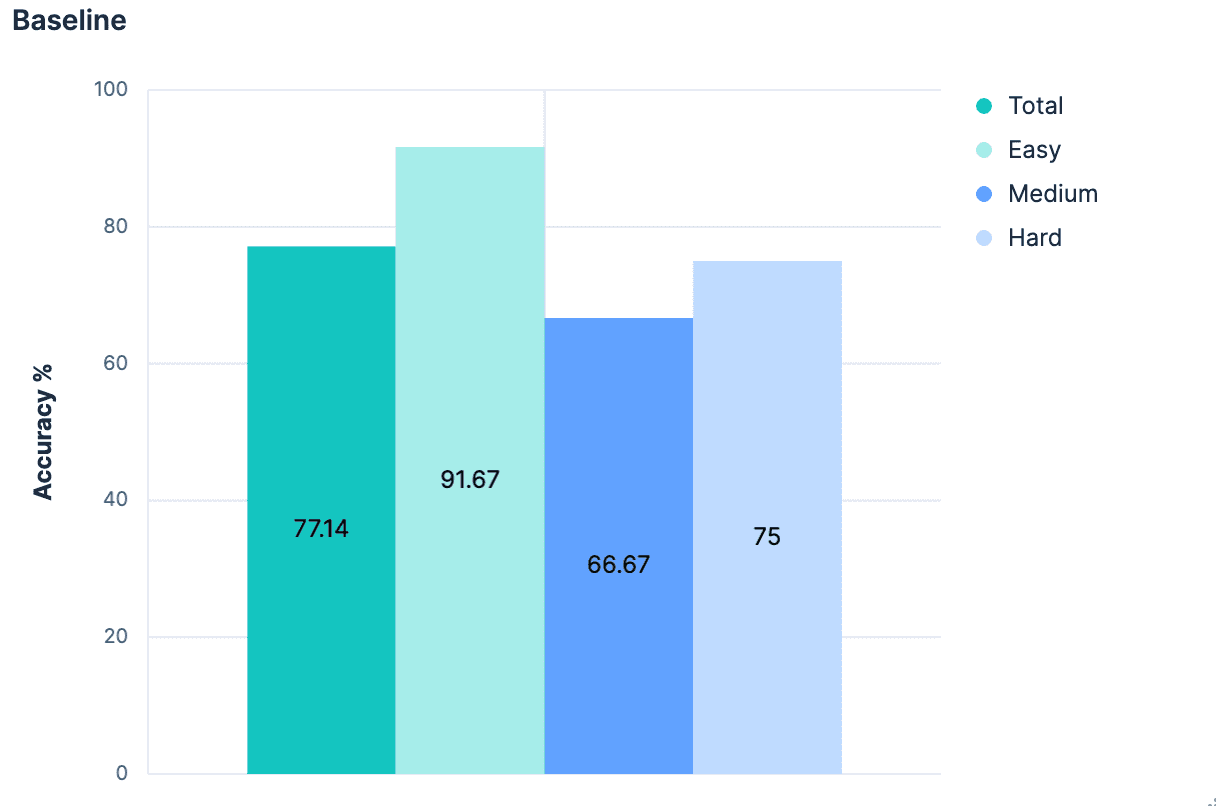
总体而言,77.14% 能准确识别正确的索引。这是在 "最好的情况 "下,即所有指数都有好的、语义上有意义的名称。使用过 `PUT test2/_doc/foo{...}` 的人都知道,索引的名称并不总是有意义的。
因此,我们有了一个基准线,而且它显示出很大的改进空间。现在是时候来点科学知识了!🧪
实验
假设 1:映射将有助于
这样做的目的是确定一个索引,其中包含与原始提示相关的数据。而索引中最能描述其所含数据的部分就是索引的映射。即使不抓取索引内容的任何样本,只要知道该索引有一个 double 类型的价格字段,就意味着该数据代表了要出售的东西。文本类型的作者字段意味着一些非结构化语言数据。两者合在一起可能意味着数据是书籍/故事/诗歌。通过了解索引的属性,我们可以获得很多语义线索。因此,我在本地分支中调整了 `.index_explorer工具,将索引的完整映射(连同索引名称)发送给 LLM,由 LLM 做出决定。
结果(来自 Kibana 日志):
该工具的最初作者已经预见到了这一点。虽然索引映射是一座信息金矿,但它也是一个相当冗长的 JSON 数据块。而在实际情况中,您需要比较众多指数(我们的评估数据集定义了 20 个指数),这些 JSON blob 会不断增加。因此,我们希望为 LLM 的决策提供更多的背景信息,而不仅仅是所有选项的索引名称,但又不至于提供每个选项的完整映射。
假设 2:"扁平化 "映射(字段列表)是一种折中方案
我们首先假设索引创建者会使用有语义的索引名称。如果我们将这一假设扩展到字段名呢?我们之前的实验之所以失败,是因为 JSON 映射包含了大量繁琐的元数据和模板。
例如,上面的代码块有 236 个字符,只定义了 Elasticsearch 映射中的一个字段。而字符串 "description_text "只有 16 个字符。字符数几乎增加了 15 倍,但在描述该字段对可用数据的含义方面却没有任何有意义的改进。如果我们要获取所有索引的映射,但在将其发送到 LLM 之前,将其 "扁平化 "为字段名列表,会怎么样?
我们试了一下。

这太棒了!全面改进。但我们能做得更好吗?
假设 3:映射 _meta 中的描述
如果仅仅是字段名而没有额外的上下文就能带来如此大的跳跃,那么增加大量的上下文可能会更好!每个索引都附加描述并不一定是常规做法,但可以在映射的 _meta 对象中添加任何类型的索引级元数据。我们回到生成的索引,为数据集中的每个索引添加说明。只要描述不是太长,就应该比完整映射使用更少的标记,并能更好地说明索引中包含了哪些数据。我们的实验验证了这一假设。
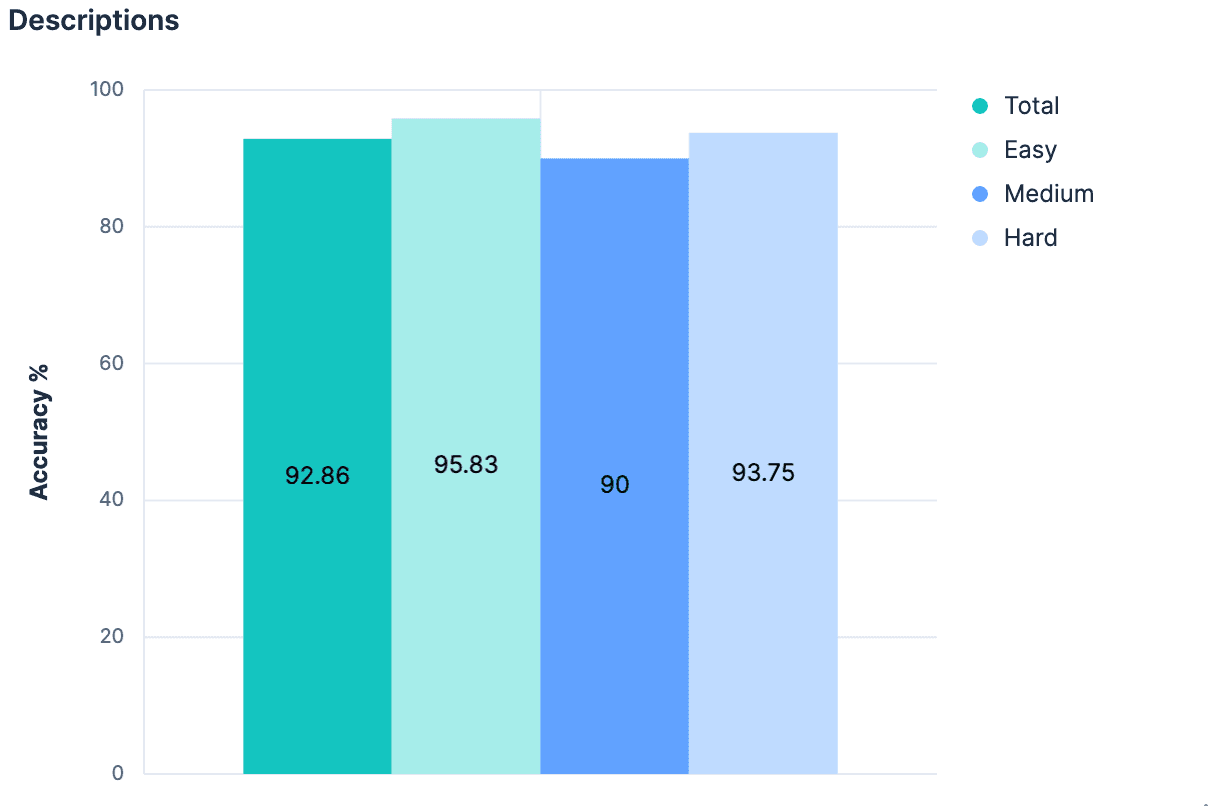
稍有改进,我们现在的>90% 准确度全面提高。
假设 4:总和大于部分
字段名增加了我们的成果。说明增加了我们的成果。因此,同时 使用描述和字段名称应该会得到更好的结果,对吗?
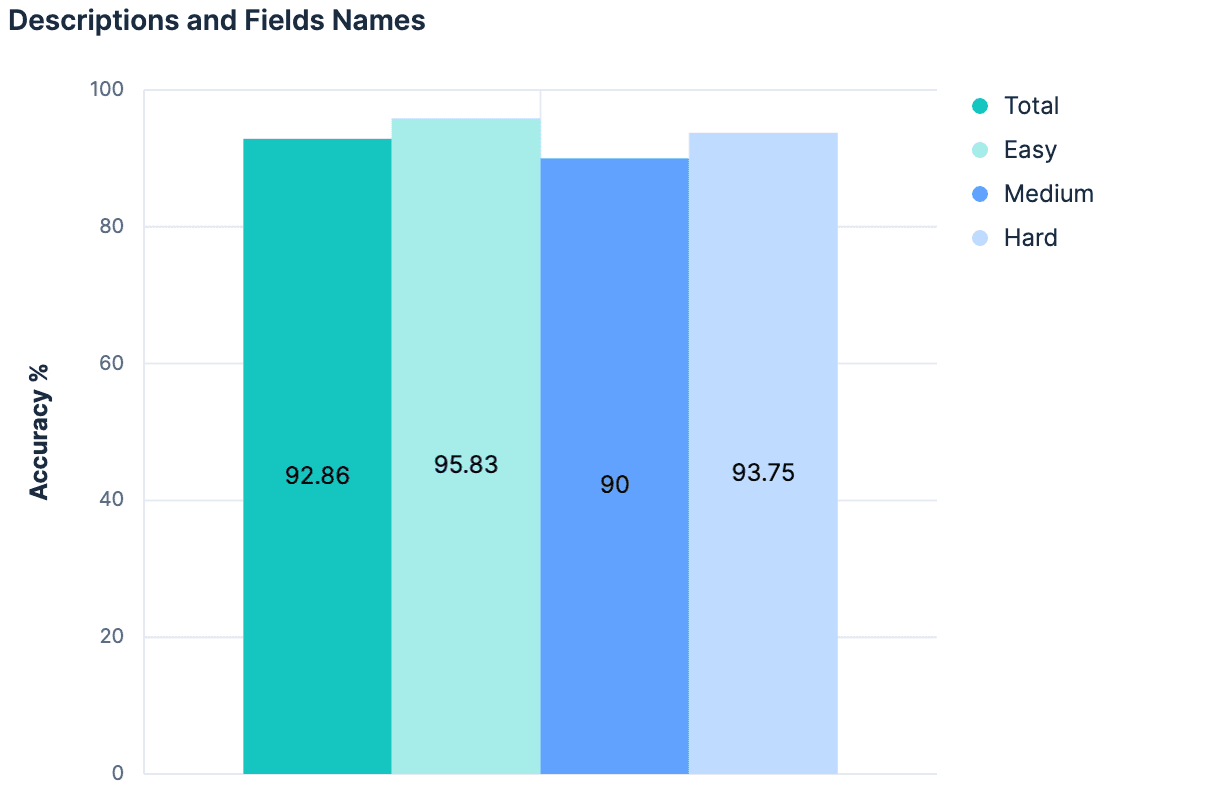
数据显示 "否"(与上次实验相比没有变化)。这里的主要理论是,由于描述是从索引字段/映射开始生成的,这两个上下文之间没有足够的不同信息,因此在将它们组合在一起时无助于添加任何 "新 "信息。此外,我们为 20 个测试指数发送的有效载荷越来越大。我们迄今为止所遵循的思路是无法扩展的。事实上,我们有充分的理由相信,在有成百上千个索引可供选择的 Elasticsearch 集群上,我们迄今为止进行的所有实验都不会奏效。任何随着索引总数的增加而线性增加发送到 LLM 的信息量的方法,可能都不是通用的策略。
我们真正需要的是一种方法,它能帮助我们从众多候选人中筛选出最相关的选项...
这就是一个搜索问题。
假设 5:通过语义搜索进行选择
如果一个索引的名称具有语义意义,那么它就可以存储为一个向量,并进行语义搜索。
如果索引的字段名具有语义意义,那么就可以将其存储为向量,并进行语义搜索。
如果一个索引有一个具有语义意义的描述,那么它也可以存储为一个向量,并进行语义搜索。
如今,Elasticsearch 索引并不能搜索到这些信息(也许我们应该这样做!),但要想解决这个问题却非常容易 。利用 Elastic 的连接器框架,我构建了一个连接器,可以为集群中的每个索引输出文档。输出文件将类似于
我将这些文件发送到一个新的索引,并在其中手动定义了映射:
这样就创建了一个单一的 semantic_content 字段,其他所有具有语义意义的字段都会被分块并编入索引。搜索该索引变得非常简单,只需.....:
修改后的index_explorer 工具现在速度更快,因为它不需要向 LLM 提出请求,而是可以为给定的查询请求单个嵌入,并执行高效的向量搜索操作。以最高点击率为选定索引,我们得到的结果是

这种方法具有可扩展性。这种方法效率很高。但这种方法比我们的基准线好不了多少。但这并不奇怪,因为这里的搜索方法太天真了。没有任何细微差别。不承认索引的名称和描述应比索引包含的任意字段名称更有分量。没有加权精确词性匹配而非同义匹配的功能。不过,要建立一个高度细致的查询,需要对手头的数据进行大量假设。到目前为止,我们已经对索引和字段名称的语义做了一些大的假设,但我们还需要更进一步,开始假设它们有多大的意义以及它们之间的关系。如果不这样做,我们可能无法可靠地将最佳匹配结果确定为我们的首要结果,但更有可能说最佳匹配结果就在前 N 个结果中的某个地方。我们需要的是一种能够在语义信息存在的语境中消费语义信息的东西,它可以与另一个可能以不同语义方式表示自己的实体进行比较,并在两者之间做出判断。比如法学硕士。
假设 6:候选集减少
还有很多实验我就不一一列举了,但关键的突破是放弃了纯粹从语义搜索中挑选最佳匹配项的愿望,转而利用语义搜索作为过滤器,从 LLM 的考虑范围中剔除不相关的索引。我们将线性检索、混合检索与 RRF 以及semantic_text 结合起来进行检索,将结果限制在匹配指数的前 5 位。
然后,对于每个匹配项,我们都将索引名称、描述和字段名称添加到 LLM 的信息中。结果非常好:
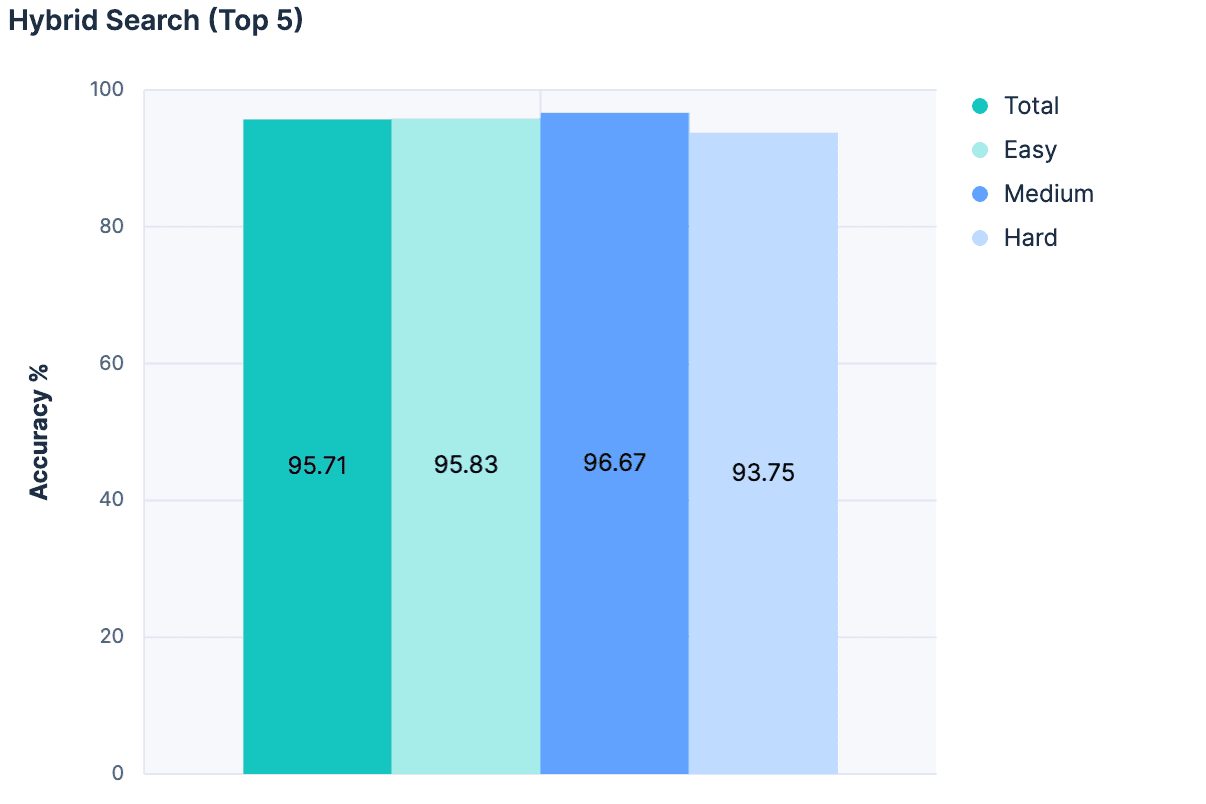
这是迄今为止精度最高的实验!由于这种方法不会使信息大小与索引总数成正比,因此这种方法的可扩展性要好得多。
成果
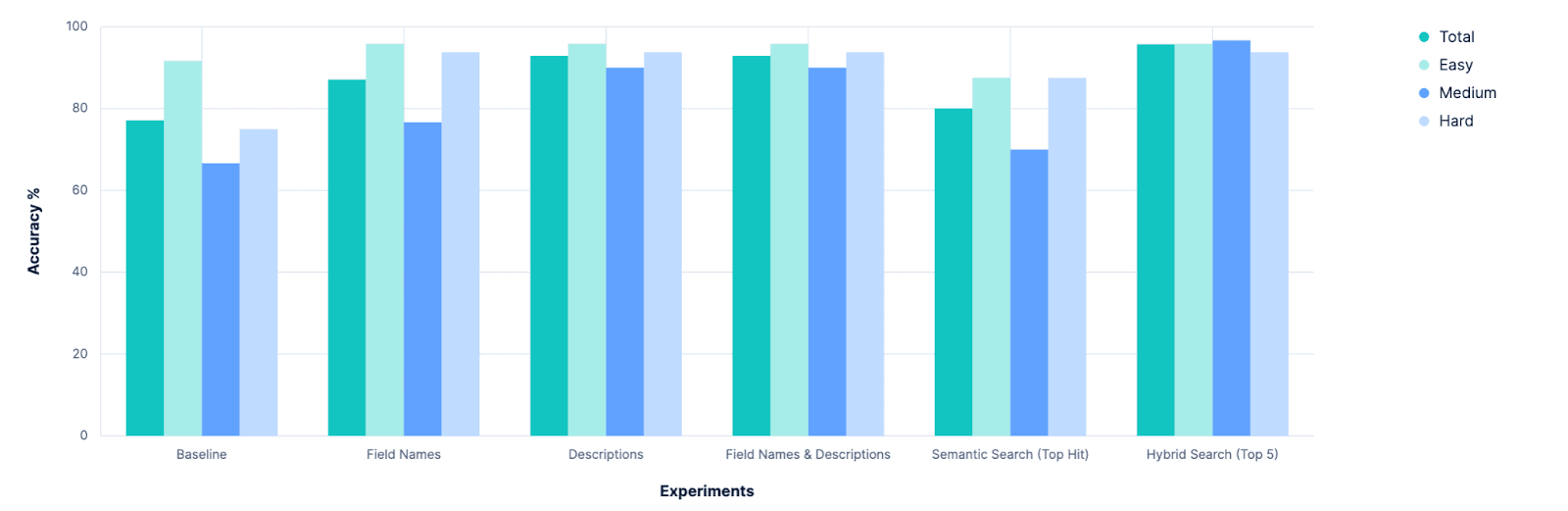
第一个明确的结果是,我们的基线可以改进。现在回想起来,这一点似乎显而易见,但在实验开始之前,我们曾认真讨论过是否应该完全放弃index_explorer 工具,而依靠用户的明确配置来限制搜索空间。虽然这仍然是一个可行且有效的选择,但这项研究表明,在无法获得此类用户输入的情况下,实现索引选择自动化的道路大有可为。
下一个明确的结果是,一味地增加描述性文字的数量,其回报率会越来越低。在这项研究之前,我们一直在讨论是否应该投资扩展 Elasticsearch 存储字段级元数据的能力。如今,这些meta 值的上限是 50 个字符,而且有一种假设认为,我们需要增加这个值,以便能够从语义上理解我们的字段。但情况显然不是这样,法律硕士似乎只需填写字段名称就可以了。我们以后可能会进一步调查这个问题,但现在已经没有紧迫感了。
相反,这也清楚地证明了 "可搜索 "索引元数据的重要性。在这些实验中,我们破解了指数的索引。但是,我们可以研究将其直接构建到 Elasticsearch 中,构建应用程序接口来进行管理,或者至少围绕其建立一个惯例。我们将权衡各种选择并进行内部讨论,敬请期待。
最后,这项工作证实了我们花时间进行试验和做出数据驱动决策的价值。事实上,它帮助我们再次确认,我们的代理生成器产品需要一些强大的产品内评估功能。如果我们需要专门为一个选取指数的工具构建整个测试线束,那么我们的客户绝对需要在进行迭代调整时对其定制工具进行定性评估的方法。
我很期待看到我们的成果,希望你们也是!
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

2026年4月8日
如何使用 Mastra 和 Elasticsearch 构建代理式 AI 应用程序
通过一个实际示例,了解如何使用 Mastra 和 Elasticsearch 构建智能体 AI 应用。

