Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
Building agent memory on Elasticsearch
Three indices, hybrid recall with a reranker, supersession, decay, and DLS. The architecture and the numbers behind a persistent memory layer for agents.
Sarah's smart bulbs are only showing white. Her smart-home assistant suggests resetting the hub. She did that in March, and again last week; neither reset fixed anything. The agent doesn't know that, and it doesn't know about the dog chewing through her sensor cables either. The history that mattered, what worked, what didn't, and who Sarah is ended with each session.
The standard workaround is to stuff prior context into the context window. That breaks down on cost, on latency, and on the well-documented "lost in the middle" effect, where models ignore facts placed far from the prompt's edges. A 1M-token context window is a scratchpad. It is not a memory system.
The context window is short-term memory: the active reasoning space for a single inference. What is missing is long-term memory: a persistent store that survives session end, scales to years of interaction, and lets you retrieve facts by content, by time, and by user.
This post is about the architecture of a real agent memory system, built on Elasticsearch and structured around three categories from cognitive science, one hybrid recall query with RRF and a cross-encoder reranker, supersession for contradictions, and per-user DLS isolation. On a QA-style eval over 168 questions, R@10 averages 0.89 with zero cross-tenant leaks.
The full implementation is on GitHub; this post is about why it is shaped the way it is.
What an agent memory store has to do
A user asks "what fix did we try last time?", a temporal query with an exact-match constraint. Or "Why are my smart bulbs only showing white?", which needs personal memory blended with a shared catalog. Memory itself doesn't behave uniformly: events the user lived, stable facts about them, and step-by-step playbooks all have different write rates and aging rules, so the store has to recognize the type and treat each accordingly. And in any multi-user deployment, each user's memory has to stay invisible to every other user. Fresh events accumulate fast enough that they have to be consolidated into the durable kinds, or the index turns into a haystack. When a user contradicts a recalled fact, the old version has to be superseded rather than deleted, so the audit trail stays. Older facts shouldn't outrank fresh ones, and facts the user touches often shouldn't sink. And the whole memory layer should be reachable by any MCP-speaking client, not tied to one agent runtime.
Splitting these across a vector store, a keyword engine, an audit layer, and a separate auth service means four things that can break and extra round-trips on every recall. The requirements describe a search engine, so this implementation uses one. The rest of this post walks through each.
Three types of agent memory: episodic, semantic, procedural
The first design decision is what categories of memory to store at all. Just saving everything builds a haystack with no signal. The cognitive-psychology split between episodic, semantic, and procedural memory, surfaced for LLM agents in the COALA framing, already has the right categories, and they map cleanly onto three Elasticsearch indices.
- Episodic memory. Time-stamped events: each user turn as it lands, before any extraction or interpretation. Most of it is short-lived: not always worth keeping. A few entries become evidence for durable facts later.
- Semantic memory. Distilled, stable assertions about the user. Sarah owns a Lumio Hub v2. Sarah is on iOS 17.4. Sarah's hub was reset in March. These survive across sessions and are what the agent grounds in.
- Procedural memory. Multi-step playbooks. How to troubleshoot Zigbee disconnects. Processes, not facts. Each carries
success_countandfailure_count, incremented by consolidation when the user confirms a fix worked or didn't. The counters are surfaced to the consolidation LLM as context when it considers whether to refine or replace a playbook.
Each category has a different lifecycle. Episodic is written constantly and decays. Semantic is curated, deduped, and superseded as the user changes. Procedural accumulates outcome feedback (success_count, failure_count) that feeds consolidation. One bucket cannot model that. Three indices, one per memory type, let each follow its own write rate, its own aging rules, and its own update rules without coupling them.
Alongside these three sits a fourth retrieval surface: world data already in Elasticsearch (catalog, knowledge base). It is not "memory" in the cognitive sense, but the agent reads it through the same hybrid-retrieval pipeline (covered in the next section), so it belongs in the same picture.
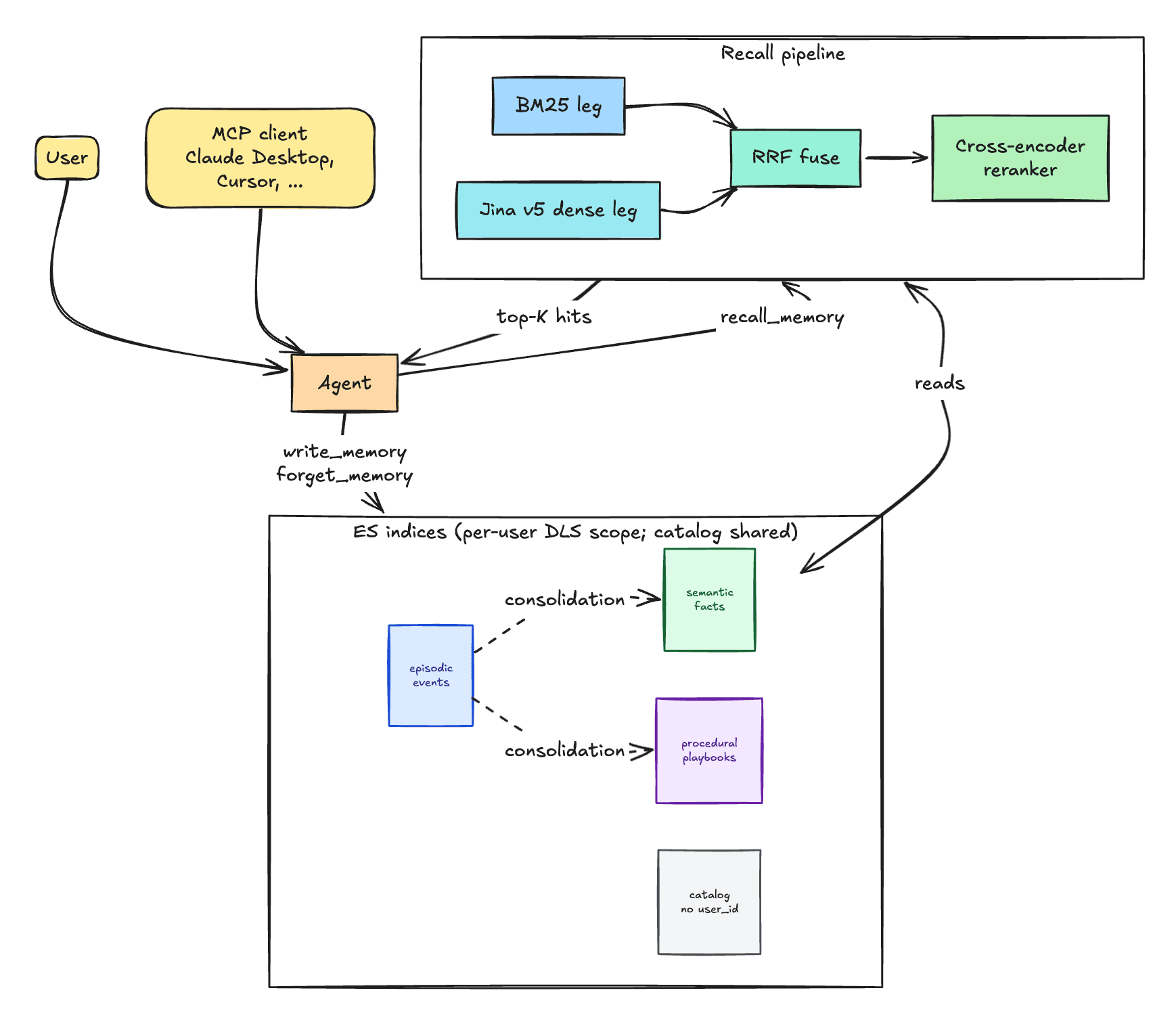
The recall pipeline: hybrid retrieval with RRF and a reranker
Memory is recalled with a two-stage hybrid search: RRF over BM25 + Jina v5 dense, then a cross-encoder reranker on the merged candidates. Each document is indexed two ways from one write: the raw text lands in the BM25 inverted index, and copy_to routes the same value into a semantic_text field that auto-generates Jina v5 vectors. Indexing the same content twice keeps the storage footprint flat: one source-of-truth write produces both retrieval legs (index mapping). Each leg solves a different problem. BM25 anchors literal-token matches that an agent paraphrase would dissolve: version numbers, error codes, proper nouns like "Lumio Hub v2." Dense vectors catch the semantic shape of a question whose answer uses different words. Either leg alone misses cases that the other handles, and RRF fuses their rankings without having to calibrate BM25 scores against cosine similarities.
Over-fetch. A reranker can only re-order what it sees, so the candidate pool needs to be wide. The hybrid retriever fetches 80 candidates per leg and RRF-fuses with rank_constant=30 (tighter than the ES default of 60, so top-ranked items dominate more). (_rrf_fetch)
Reranker. A Jina v2 cross-encoder scores the merged candidates against the user query. Where BM25 and the bi-encoder dense both score query and document independently, a cross-encoder scores them jointly, with full attention across the pair, which is a stronger relevance signal at higher per-pair cost. That's what motivates the two-stage pipeline: over-fetch cheaply with the hybrid retriever, then rerank a small candidate pool with the more expensive scorer (_rerank).
One subtlety, shown in the diagram above. The agent's tool kit includes recall_memory (defined in tools.py), which the model calls during a turn. A single call fans across all three memory indices and the catalog at once: the agent doesn't pick a memory type, because the retriever's ranking and per-index decay handle routing on its behalf. The second subtlety is paraphrasing. Agents almost always rewrite the user's message before reaching for that tool, which strips literal version numbers, error codes, and proper nouns from the query before BM25 ever sees them. So every turn opens with an automatic pre-recall on the verbatim user message, injected into the conversation as if the agent had made the call itself (agent.py).
Writing and consolidating agent memory.
Two operations move memory from "what just happened" into "what is durable about this user."
Write. Every user turn writes one episodic event (ID, exact message, timestamp and more) before the LLM responds. The ID is assigned by Elasticsearch on write, the DLS query on Sarah's API key keeps the doc scoped to her on every subsequent recall, and the timestamp is what the time-decay function (below) reads to rank the event against newer ones. Agent replies aren't stored. The conversation history already carries them into the next call, and their length drowns out the short, fact-rich things the user said. Hot-path writing is a deliberate choice. Two alternatives sound plausible at first. Letting the context window carry the new fact forward works for the rest of an open session, but the moment the session ends or crashes, in-context state vanishes; cross-session memory was the whole point.
Batching writes at session end preserves cross-session state, but it breaks two same-turn patterns this implementation depends on. A user mentioning a new device and asking for their device list inside one message needs the new fact to be visible to the recall that runs later in the same turn, because tool calls query the index, not the conversation history. And the supersession flow writes a corrected fact and recalls it against it inside one tool-call batch. Either pattern would silently misbehave under deferred writes. The cost we pay instead is one Elasticsearch write per user message, which is sub-100ms at the volumes a single conversation produces.
Which advice worked is captured separately, by success_count / failure_count on the procedural index, not by storing the response prose. Recent episodes containing user confirmation ("thanks, that worked") trigger success_count++; explicit rejection ("that didn't help") triggers failure_count++. The conversation itself is the feedback signal, with the consolidation LLM as the classifier. No thumbs-up widget is required. Disagreement also surfaces a refined_steps field for the LLM to write back into the playbook.
Consolidate. Episodic logs accumulate fast. Consolidation promotes them into semantic facts and procedural playbooks that survive after the conversation history is gone. This implementation runs it every turn, so you can watch the inspector update live; in production the right cadence is a background job: every 24 hours, or when a user's episodic index crosses N new events. Per-turn doubles LLM calls per message.
In one call (prompt), the consolidation LLM is handed recent episodes plus existing facts and playbooks, and asked for three things:
- New semantic facts, with
supporting_episode_idsfor provenance. - New procedural playbooks, when a multi-step resolution doesn't match any existing trigger.
- Procedural updates,
success_count++/failure_count++based on whether the user confirmed the fix, plus refined_steps when they disagreed.
The prompt requires supporting_episode_ids on every output, so a sparse turn returns an empty list and writes nothing.
Dedup uses the same hybrid retriever the agent uses for recall: for each candidate fact, a top-K hybrid search against the user's semantic index narrows the comparison set, and only those candidates go to the LLM for a meaning judgment. Two further guards bracket the output: candidates below a confidence floor are dropped, and an accepted fact whose top similarity hit clears ≥ 0.90 is treated as a duplicate. In this implementation, dedup is simpler: the most recent ~50 facts are passed to the consolidation LLM with a "do not duplicate" instruction, and the post-LLM confidence and similarity guards aren't wired yet. The hybrid-recall path and the bracketing guards are the production architecture; this snapshot relies on the LLM doing the comparison directly because the corpus is small enough that it fits.
success_count and failure_count close a feedback loop on playbooks: across enough conversations, the same field that records "this worked" becomes the signal for "show this one first next time." Today, the counts are written but not yet biased into retrieval ranking. On a handful of resolved tickets, the boost is statistical noise. Wired into production, once a deployment has the density to make the signal meaningful.
How agent memory handles contradictions and supersession
Memory that only ever adds, never removes, ends up wrong. A user says "I moved to Edinburgh"; the agent writes a new fact. Six months later, the old "lives in Bristol" fact is still in the index. Both surface on every recall, and the agent either picks the wrong one or hedges. Trust dies fast.
The fix is one rule in the system prompt (full prompt), no new tool. Instead of deleting, the agent supersedes:
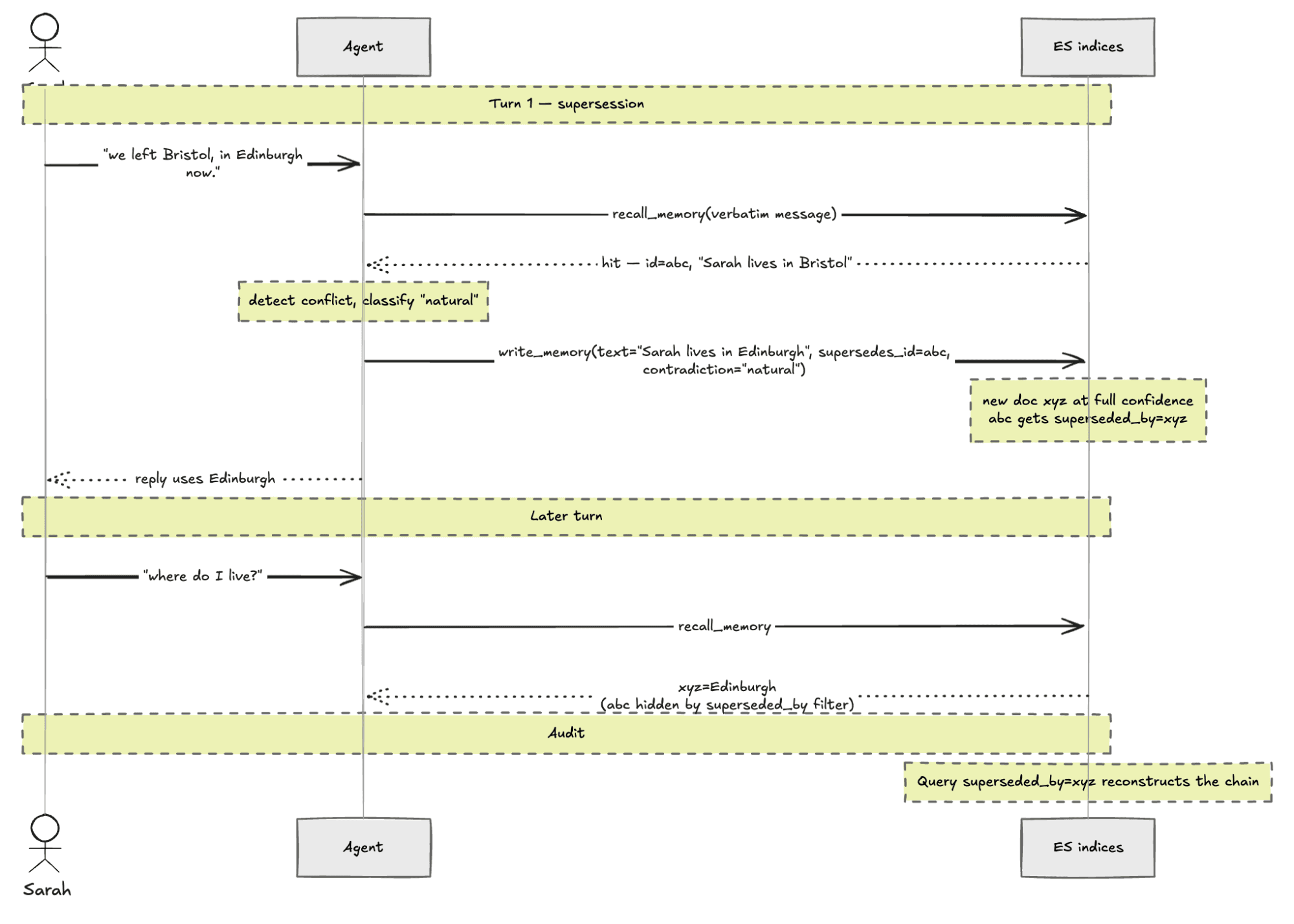
A worked example. Sarah's last visit recorded id=abc, "Sarah lives in Bristol" in the semantic index. Three months later, she opens a chat: "we left Bristol, in Edinburgh now."
1. Recall. The pre-recall on Sarah's message returns hits including {id: "abc", text: "Sarah lives in Bristol", memory_type: "semantic"}.
2. Detect. The agent sees the conflict between the recalled fact and the new message.
3. Classify. "We left Bristol, in Edinburgh now" is a natural update, not a denial. The agent picks contradiction="natural".
4. Write. The agent calls write_memory(text="Sarah lives in Edinburgh", supersedes_id="abc", contradiction="natural"). Two things happen in one shot:
- A new doc
id=xyzis written at full confidence (no penalty, because the contradiction was natural). - The old doc
abcis updated withsuperseded_by=xyz, superseded_at=<now>.
5. Recall hides the old. Every recall applies a filter must_not exists field=superseded_by. abc is hidden from the agent's view. xyz surfaces normally.
6. Audit kept. Doc abc stays in the index. A query for superseded_by=xyz reconstructs the chain.
Note: If Sarah later asks "where have I lived?", the agent calls recall_memory(query="places sarah has lived", include_superseded=True). The DLS-scoped recall surfaces both xyz (Edinburgh) and abc (Bristol). Hits with superseded_at set are archived state; the agent's reply distinguishes them: "You live in Edinburgh now; you previously lived in Bristol (until earlier this year).
Had Sarah instead said "I never lived in Bristol, that was my sister", step 3 would classify it as harsh. The same write happens, but the new fact's confidence is reduced by SUPERSEDE_CONFIDENCE_PENALTY. The system hedges slightly until the new state is reinforced by further conversation.
Edge cases follow the same shape: an already-superseded fact can be superseded again (abc → xyz → pqr); a low-stakes preference ("I prefer dark mode now") supersedes as contradiction="natural". forget_memory hard-deletes; use it only when the customer explicitly says "forget X." It is not a contradiction tool.
One subtlety. The recall might surface several facts contradicted by the same new statement. Sarah's location lives in "Sarah lives in a Victorian flat in Bristol" (semantic), in "Sarah has a flat in Bristol where her Hub v2 is" (semantic), and possibly in an episodic event from a previous chat. The agent must supersede all of them, not just the first one it sees. Scan recall for every fact the new statement makes false, and issue one write_memory(supersedes_id=…) call per old id. Facts that merely mention Bristol but remain true ("Victorian flats in Bristol have thick walls that attenuate Zigbee signal") stay unsuperseded. Sarah's move doesn't change Bristol's architecture.
Superseded docs accumulate but only surface in recall when the agent explicitly asks for them via include_superseded=True. In production, a periodic reindex moves them into a separate archive index that Elasticsearch's Index Lifecycle Management (ILM) ages through cold and frozen tiers (searchable snapshots). The audit chain stays queryable on cold storage; the active semantic index stays hot and small.
Ensuring same-turn write visibility in Elasticsearch agent memory
Elasticsearch's default async refresh interval creates a propagation gap when an agent writes and recalls memory within the same conversation turn. When the user says "I have a Lumio Range Extender I never set up. Now what's my complete device list?" in a single message, the agent writes the Range Extender fact and then immediately runs a recall, within the same turn, sometimes within the same iteration's tool-call batch. The default Elasticsearch refresh interval plus the semantic_text inference cost would risk a sub-second propagation gap where the just-written doc isn't yet visible to the recall.
The fix lives at the storage layer. Every write_memory the agent triggers passes refresh=True, forcing the shard to refresh (and the Jina v5 embedding from the inline inference processor to land) before the call returns. The next tool call sees the new doc. The Range Extender shows up in the final reply because the recall that ran right after the write saw it.
At higher write volume refresh=True becomes a throughput cost. Production deployments may want to shift to async indexing plus an agent-layer "just-written" register that holds writes in the LLM's context until the index catches up. Today the simpler choice earns its place.
Time decay and use-count scoring for agent memory retrieval
The retrieval setup so far gives every fact equal weight regardless of when it was created or last used. That's the wrong default. A fact recalled twice in the past week is almost certainly more relevant than an identical fact mentioned once two years ago.
We multiply every result's score by two multipliers: a primary recency signal and a secondary frequency refinement. The recency signal is time-decay: a gauss-shaped multiplier computed in Painless over each index's date field (details below). The frequency refinement is a use-count boost (1 + log10(1 + use_count) * weight), so a fact recalled ten times boosts about 1.2x and one recalled a hundred times about 1.4x.
The two answer different questions: time-decay, how recently a fact was touched; use-count, how often. They diverge when facts share a last_used_at timestamp: decay can't separate "recalled once" from "recalled forty times"; use-count can. Time-decay is load-bearing; use-count is the refinement that earns its place once recall volume per fact is high enough to carry a signal.
Date fields per memory type
Episodic and semantic decay use different date fields. Episodic uses timestamp (event time); semantic uses last_used_at (set at write, bumped on recall). ES's native gauss can't span them, because the function takes a single field name that must exist on every index in the search. So time decay lives in a Painless script that picks the right field per index and computes a gauss-shaped multiplier in place:
Procedural is exempt from time-decay deliberately. last_used_at is bumped on every recall, successful or not, so a pure decay multiplier would reward "recently tried" rather than "recently effective." The right pairing is a last_success_at field plus success_count / failure_count wired into ranking; until both are in place, recency alone is too coarse a signal for procedural retrieval.
The recall-time bump on semantic is the load-bearing part. It turns "old facts get less weight" into "facts the agent hasn't needed recently get less weight." Relevance decay, not truth decay. Truth decay is handled by supersession (above). A 5-year-old fact the agent recalls every week stays at the top because last_used_at is fresh.
This is the same cognitive-science thread the three-bucket split runs on. Retrieval practice (the act of recalling something) strengthens its accessibility, while disuse lets it fade. The recall-time bump on last_used_at is the engineering version of the same effect.
The retrieval-time multiplier
Both factors live in one function_score block that wraps each RRF leg:
In code, both functions live in a single Painless script that branches per index (same math, fewer function_score entries).
Two _index filters do double duty. They scope each function to the memory type it should affect: time decay applies to episodic and semantic, the use-count boost applies to semantic only. And they keep procedurals and catalog out: a function whose filter doesn't match returns the neutral 1.0, so cross-index queries that include those indices score correctly without parser issues. The full function is in operations.py.
Two parameters control the gauss curve:
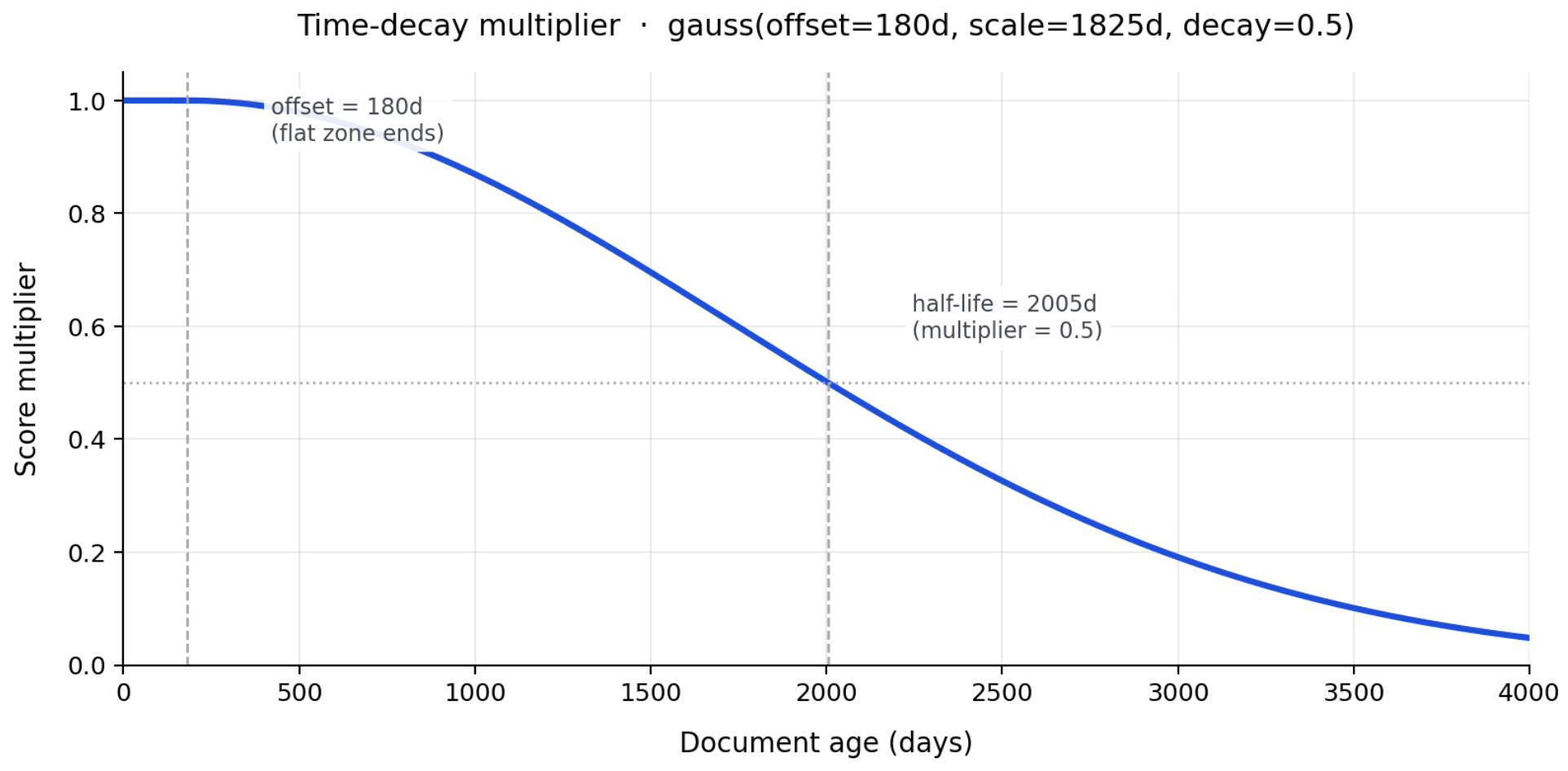
offset(180d): a flat zone. Docs younger than 180 days get multiplier 1.0 regardless of exact age. Without it, fresh facts compete with each other on sub-day timing noise.scale(1825d, ~5 years): the distance past the offset at which the multiplier hitsdecay = 0.5. Effectively a half-life from the end of the flat zone.
Decay is a deliberate trade-off. When every fact in the corpus is unique and stays correct over time, applying any decay costs some recall: old facts get penalised even when they're still right. Where decay earns its place is the realistic case: several competing facts about the same thing coexist, and you want the most recent or most-used one to rank highest. The default scale (1825d) is conservative for that reason. Tighten it for domains where facts go stale fast (customer support with rapid product churn). Loosen it for personal-assistant memory where facts stay relevant for years; both are one-line edits to constants.py.
Multi-tenant isolation with Elasticsearch DLS
Document-Level Security (DLS) moves the isolation rule into the cluster itself. Each user gets an API key whose role descriptor carries a DLS query that admits docs belonging to that user (and the shared catalog, which has no user_id field). An agent using that key can run any query it wants and will never see another user's documents. The cluster simply does not return them. That's the production isolation guarantee, enforced server-side on every query initiated with the key included
The retriever also carries a user_id filter in code as a paranoia pass against config drift: a new index template landing without DLS, a role descriptor edited and the clause silently dropped, an admin key reused by mistake. DLS is the architecture; this code-level pass costs essentially nothing at query time.
Integrating shared catalog data into agent memory retrieval
Memory lookup is one Elasticsearch query. The DLS query on Sarah's API key admits docs where user_id == "sarah". Catalog and other shared indices have no user_id field at all; they're meant to be visible to everyone. To include them, the DLS query widens from "must equal sarah" to "equals sarah OR has no user_id": a bool.should admitting user_id == "sarah" OR must_not exists: user_id. The retriever, RRF fusion, and decay function are unchanged: catalog and personal memory land in the same recall pass.
A bootstrap script mints the per-user DLS keys with the widened query baked in.
A lookup for "smart bulb showing only white" now returns both Sarah's stored constraint and the catalog entry on bulb compatibility, ranked together.
User memory and catalog can land in the same recall on the same topic and contradict each other. The retriever applies a small source prior (CATALOG_SOURCE_PRIOR, 0.85) inside the same script that handles time decay (one more _index branch, no new mechanism), so user memory wins on near-ties. It's a soft tilt, not a routing rule: when the catalog has a clearly stronger relevance match (product specs, technical lookups), the reranker still picks it. The hard cases ("always trust catalog for spec lookups" or the inverse for personal preferences) sit in the agent's system prompt, not the retriever.
Connect any agent via MCP
The memory layer is most useful when it isn't tied to one agent. The Model Context Protocol gives that for free. The endpoint is /api/atlas/mcp/{user_id}, so any MCP-speaking client (Claude Desktop, Cursor, your own agent) can plug in by pasting the JSON snippet at mcp.py into its config.
For Claude Desktop, the config lives in ~/Library/Application Support/Claude/claude_desktop_config.json (macOS) or %APPDATA%\Claude\claude_desktop_config.json (Windows). For Cursor, paste it under Settings → MCP. Restart the client and the three Atlas tools (recall_memory, write_memory, and forget_memory) appear in the tool drawer, calling the same Elasticsearch indices the FastAPI app uses. Same memory layer, any agent, no rewrite. The three tool contracts are defined in tools.py.
Measuring agent-memory recall quality
A note on "recall": elsewhere in this post, it means memory recall (the agent retrieving a stored fact). Here, it's the unrelated information-retrieval metric Recall@K: whether the right doc appears in the top-K results.
Memory architectures are hard to verify. The eval here is QA-style passage retrieval, the standard RAG benchmark. For each sampled doc, an LLM writes two questions a user might plausibly ask whose answer is that doc. For example, "my baby's sleep is fragile, anything I should remember when setting up automations?" points to Sarah's nursery quiet-hours fact. The retriever then has to surface the source doc in the top-k.
Generic memory-specific benchmarks like LoCoMo exist and would make the numbers comparable cross-system. The corpus-specific QA pattern was chosen for two reasons. First, it tests the actual deployed corpus per persona, so the recall numbers reflect what real conversations would see. Second, it isolates the retrieval slice (does the source doc surface in top-K?) that the hybrid + decay + reranker pipeline is iterating on; LoCoMo's dialogue-coherence metric measures something further downstream. A follow-up post will run the full LoCoMo benchmark and disentangle retrieval performance from LLM-choice and prompt-engineering confounds.
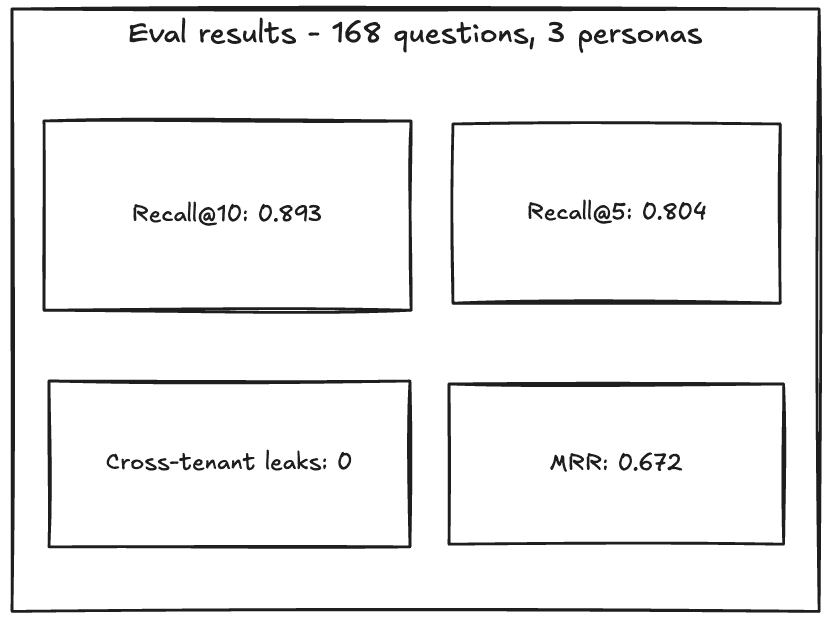
The leaks number is the ship gate for any multi-tenant memory system; the rest is the quality story. The eval is gated in CI (eval_recall.py) at R@10 ≥ 0.85, R@5 ≥ 0.75, leaks = 0. The numbers are approximate because the reranker has serving-side variance: across four back-to-back runs, R@10 landed at 0.85, 0.88, 0.89, 0.893.
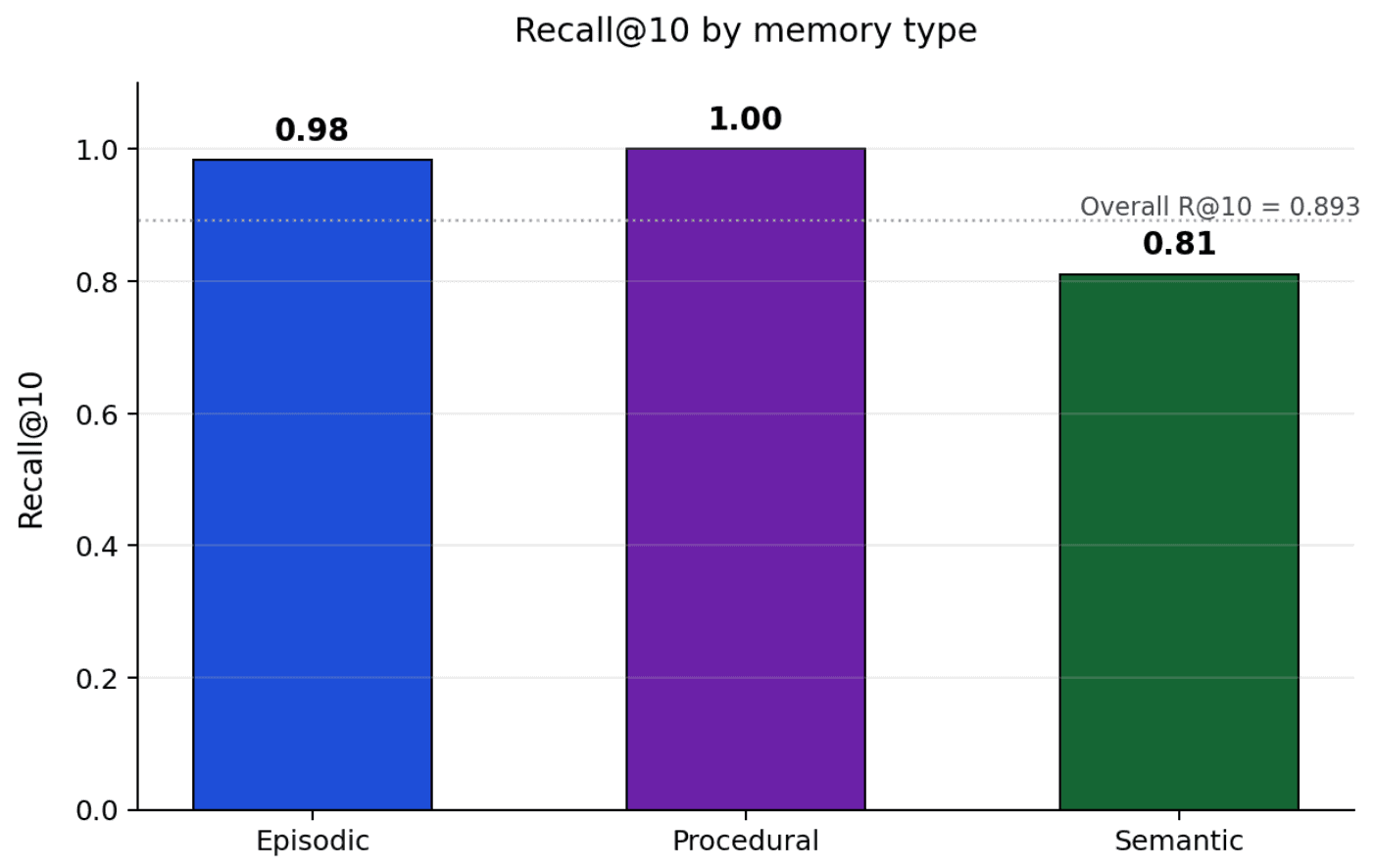
Semantic facts are the harder case (R@10 ≈ 0.81); episodic averages 0.98 and procedural hits 1.0. The reason is sibling collisions: a question about Sarah's hub disconnects has several plausibly-correct facts in the corpus, and the retriever sometimes picks the wrong one. Worth noting: a sibling collision typically doesn't degrade the agent's reply (it still gets a related, true fact), so R@10 reads as conservative for semantic specifically
Agent memory architecture: key decisions
Agent memory is a handful of problems, each with one move:
- Memory isn't one thing. Three indices, one per lifecycle: episodic (what happened), semantic (what's true), procedural (what works).
- The LLM paraphrases away keyword precision. Every turn opens with a recall on the verbatim message; retrieval is hybrid, then reranked.
- Append-only memory rots. Consolidation promotes episodes into durable facts; supersession retires the ones a user contradicts.
- Old facts shouldn't rank like fresh ones. Scores decay over time, and a recall lifts a fact back up.
- Tenants must never see each other. Isolation lives in the cluster via DLS, not in a filter you can forget.
None of it is a separate system: catalog, isolation, and decay all compose into one Elasticsearch query.
Get that right, and the assistant that kept telling Sarah to reset her hub finally remembers: she tried that in March, the dog chews the sensor cables, and home is Edinburgh now.
相关内容
2026年7月20日
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

2026年7月16日
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

2026年7月13日
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

2026年7月21日
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

2026年7月10日
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.