Simplifying data lifecycle management for data streams
Elasticsearch data streams can now be managed by a data stream property called lifecycle. Learn to set up and update a data stream lifecycle here.
Today, we’ll explore Elasticsearch’s new data management system for data streams: data stream lifecycle, available from version 8.14. With its straightforward and robust execution model, the data stream lifecycle lets you concentrate on the business-related aspects of your data's lifecycle, such as downsampling and retention. Behind the scenes, it automatically ensures that the Elasticsearch structures storing your data are efficiently managed.
This blog explains the evolution of data lifecycle management in Elasticsearch, how to configure a data stream lifecycle, update the configured lifecycle, and migrate from ILM to the data stream lifecycle.
Data lifecycle management evolution in Elasticsearch
Since the 6.x Elasticsearch series, Index Lifecycle Management (ILM) has empowered users to maintain healthy indices and save costs by automatically migrating data between tiers.
ILM takes care of indices based on their unique performance, resilience, and retention needs, whilst offering significant control over cost and defining an index's lifecycle in great detail.
ILM is a very general solution that caters to a broad range of use cases, from time series indices and data streams to indices that store text content. The lifecycle definitions will be very different for all these use cases, and it gets even more divergent when we factor each individual deployment’s available hardware and data tiering resources. For this reason, ILM allows fully customisable lifecycle definitions, at the cost of complexity (precise rollover definitions; when to force merge, shrink, and (partially) mount indices).
As we started working on our Serverless solution we got a chance to look at the lifecycle management through a new lens where our users could (and will) be shielded from Elasticsearch internal concepts like shards, allocations, or cluster topology. Even more, in Serverless we want to be able to change the internal Elasticsearch configuration as much as needed to maintain the best experience for our users.
In this new context, we looked at the existing ILM solution which offers the users the internal Elasticsearch concepts as building blocks and decided we need a new solution to manage the lifecycle of data.
We took the lessons learned from building and maintaining ILM at scale and created a simpler lifecycle management system for the future. This system is more specific and only applies to data streams. It's configured as a property directly on the data stream (similar to how an index setting belongs to an index), and we call it data stream lifecycle. It’s a built-in mechanism (continuing with the index settings analogy) that is always on and always reactive to the lifecycle needs of a data stream.
By scoping the applicability to only data streams (i.e. data with a timestamp that’s rarely updated in place) we were able to eschew customizations in favor of ease-of-use and automatic defaults. Data stream lifecycles will automatically execute the data structure maintenance operations like rollover and force merge, and allow you to only deal with the business-related lifecycle functionality you should care about, like downsampling and data retention.
A data stream lifecycle is not as feature-rich as ILM; most notably it doesn’t currently support data tiering, shrinking, or searchable snapshots. However, the use cases that do not need these particular features will be better served by data stream lifecycles.
Though data stream lifecycles were originally designed for the needs of the Serverless environment, they are also available in regular on-premise and ESS Elasticsearch deployments.
Configuring data stream lifecycle
Let’s create an Elasticsearch Serverless project and get started with creating a data stream managed by data stream lifecycle.
Once the project is created, go to Index Management and create an index template for the my-data-* index pattern and configure a retention of 30 days:
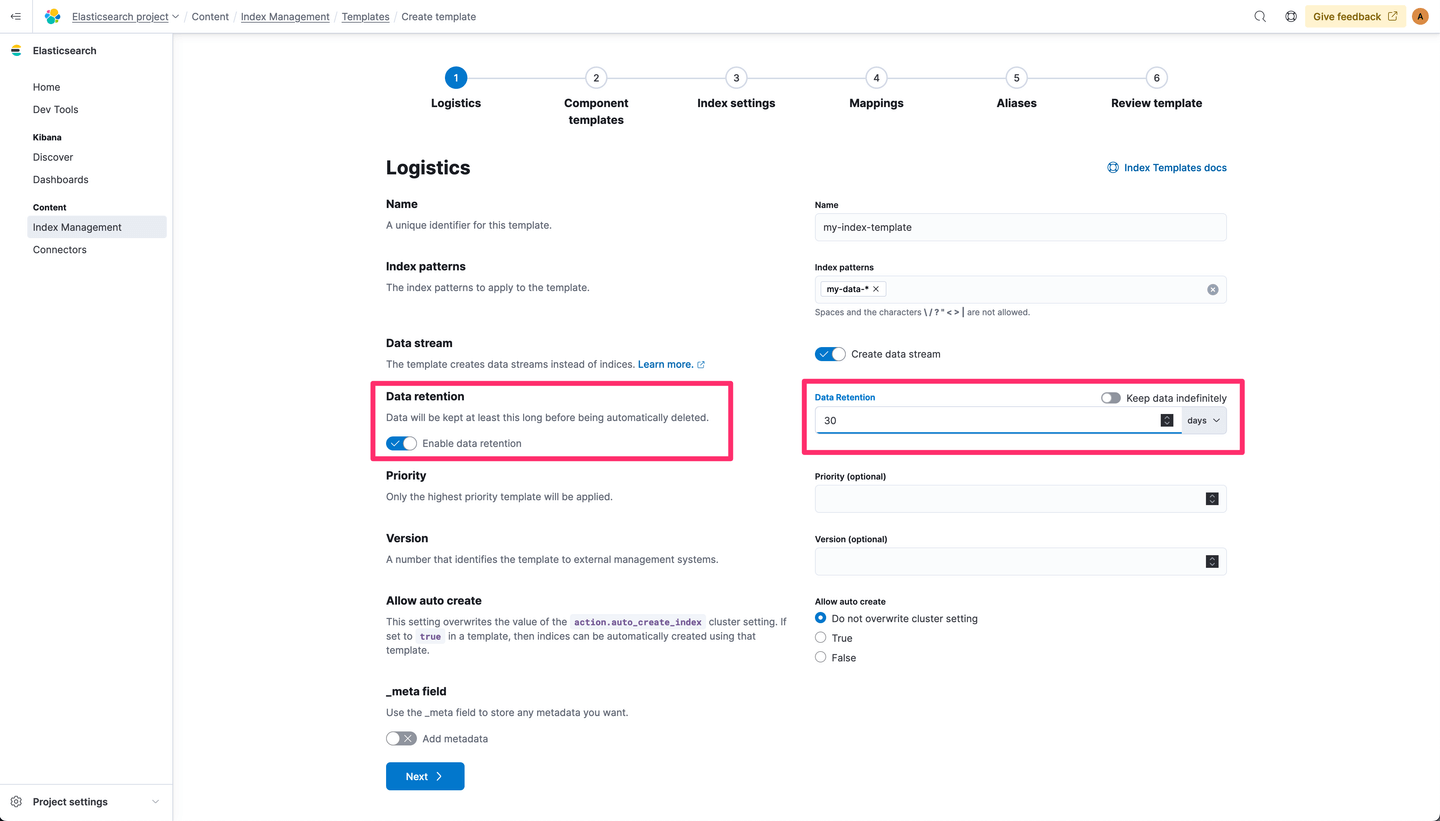
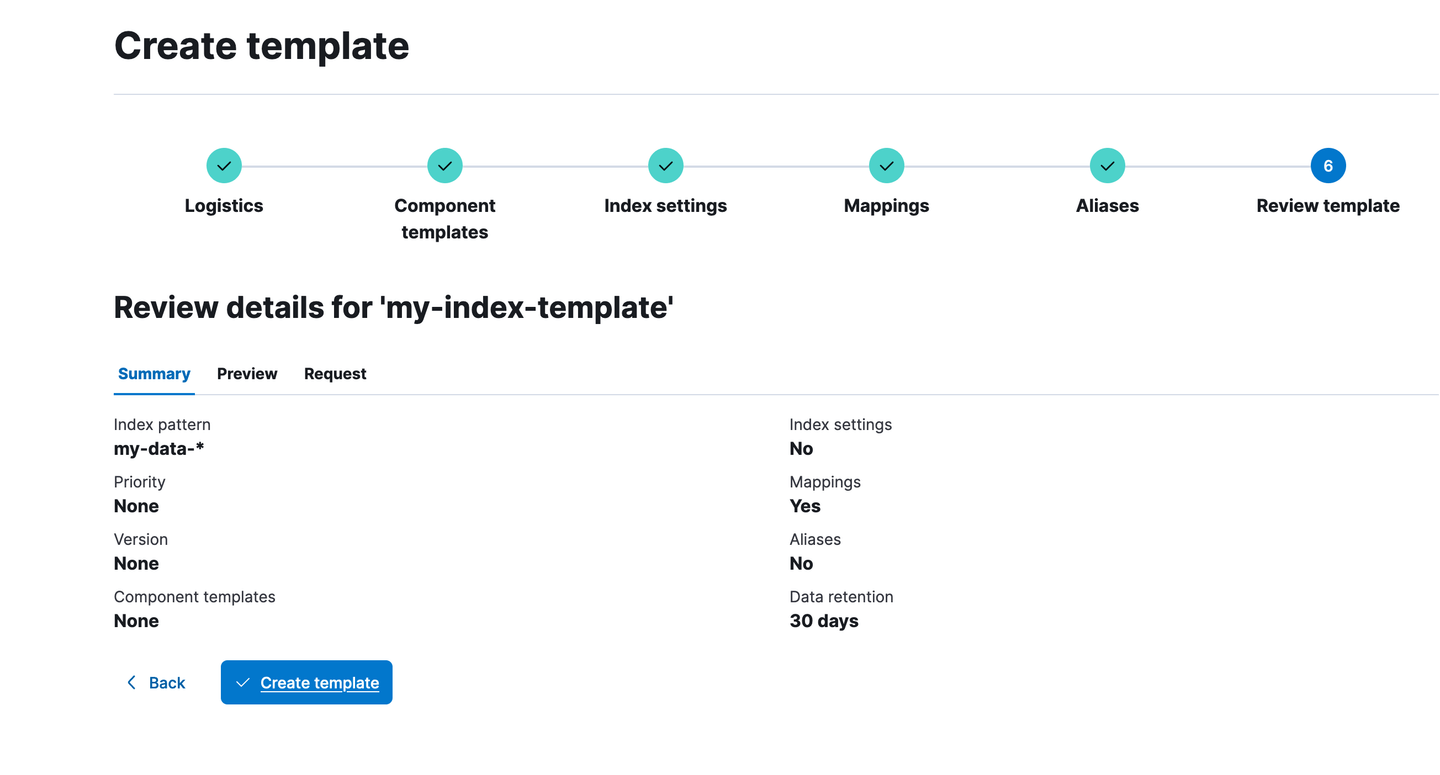
Let’s navigate through the steps and finalize this index template (I’ve configured one text field in the mapping section, but that’s optional):
We’ll now ingest some data that’ll target the my-data-stream namespace. I’ll use the Dev Tools section on the left hand side, but you can your preferred way of ingesting data:
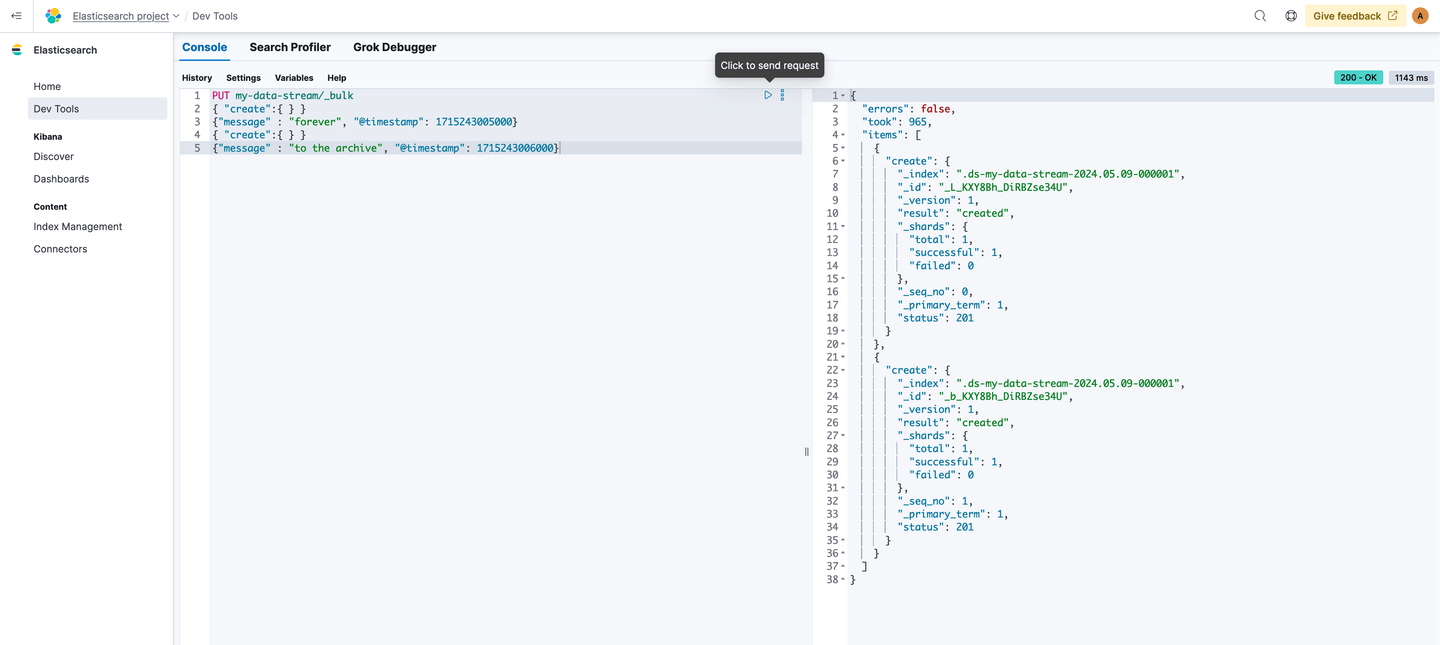
my-data-stream has now been created and it contains 2 documents. Let’s go to Index Management/Data Streams and check it out:
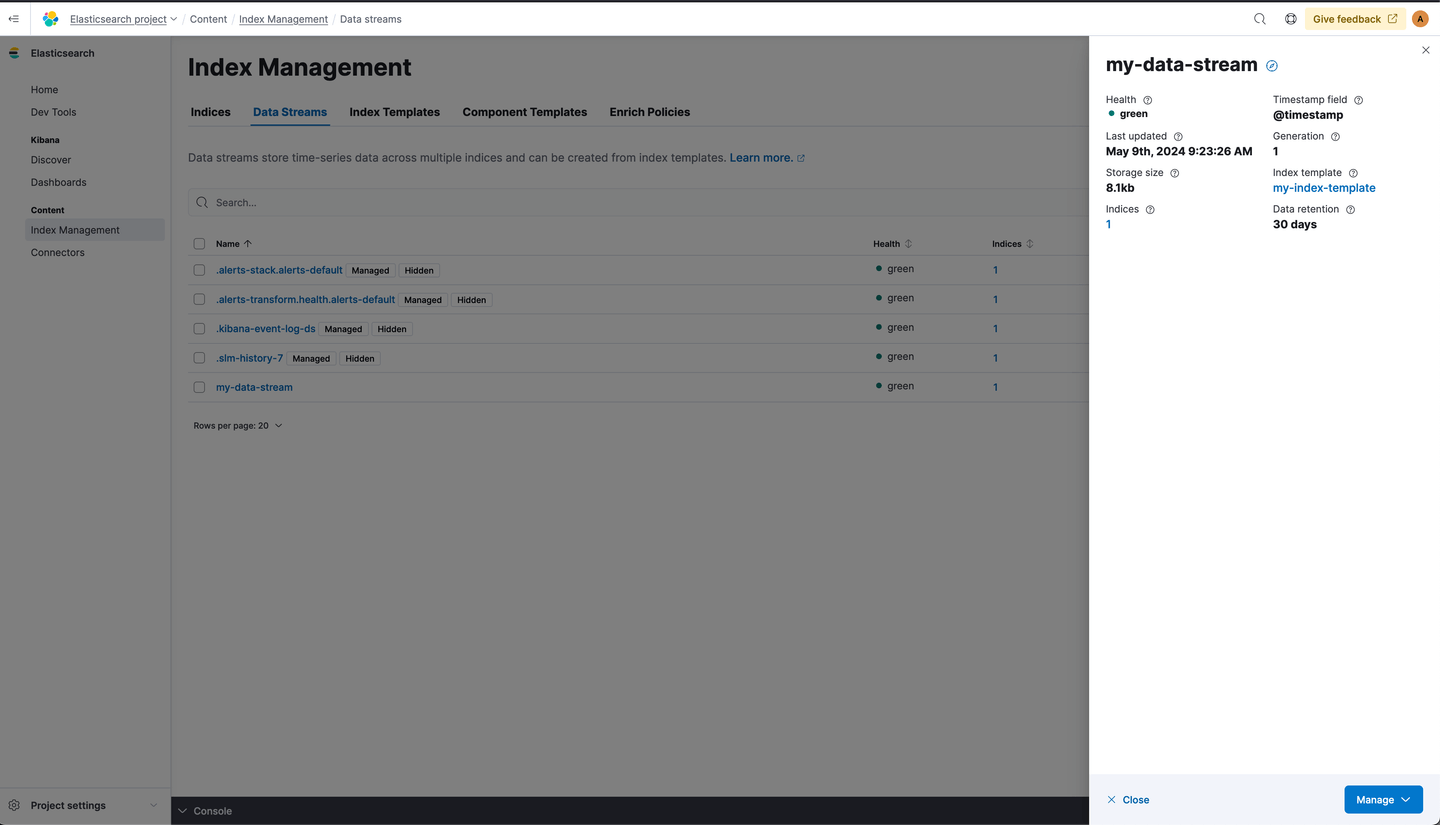
And that’s it! 🎉 Our data stream is managed by data steam lifecycle, and retention for the data is configured to 30 days. All new data streams that match the my-data-* pattern will be managed by data stream and receive a 30 days data retention.
Updating the configured lifecycle
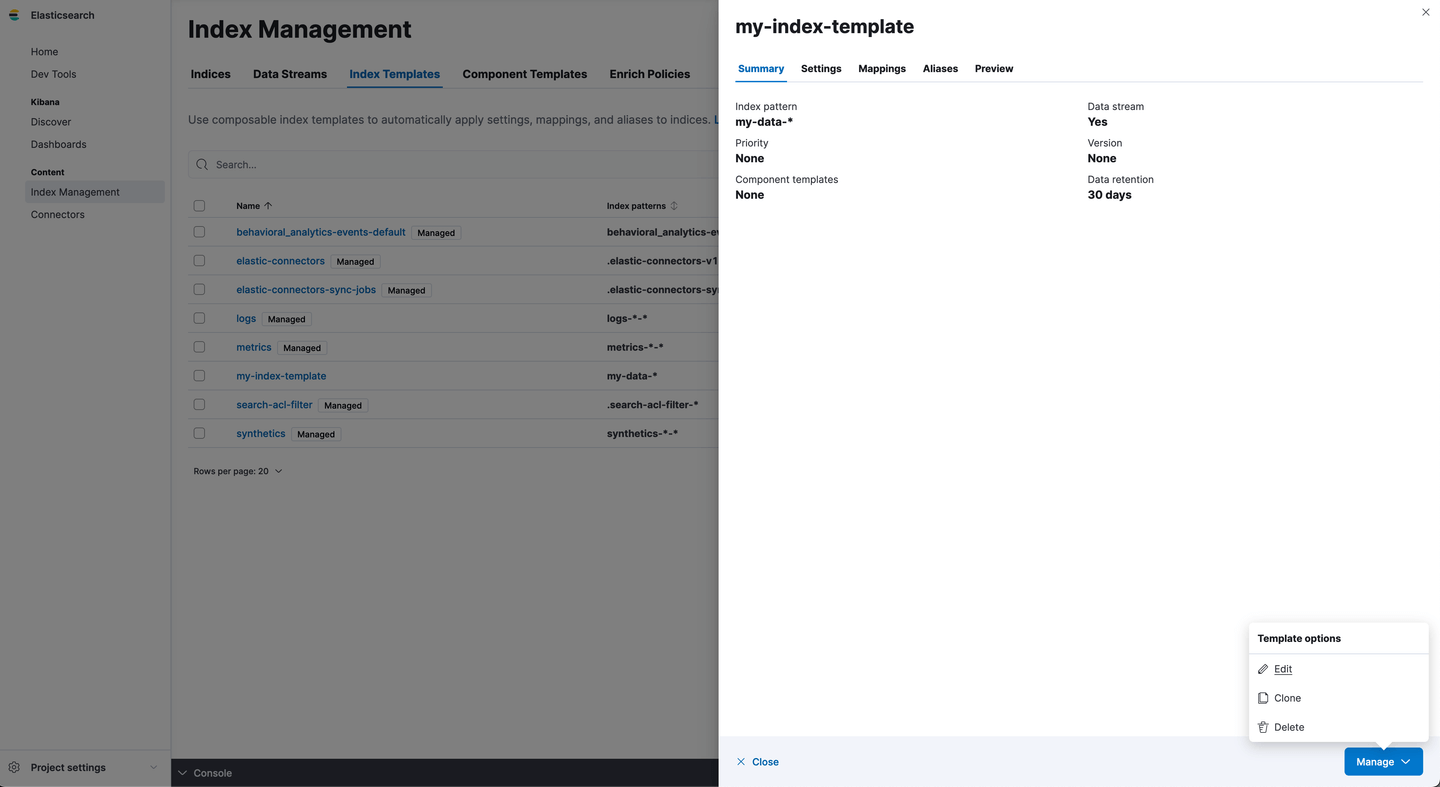
The data stream lifecycle property belongs to the data stream. So updating the lifecycle for existing data streams is something we configured by navigating to the data stream directly. Let’s go to Index Management/Data Streams and edit the retention for my-data-stream to 7 days:
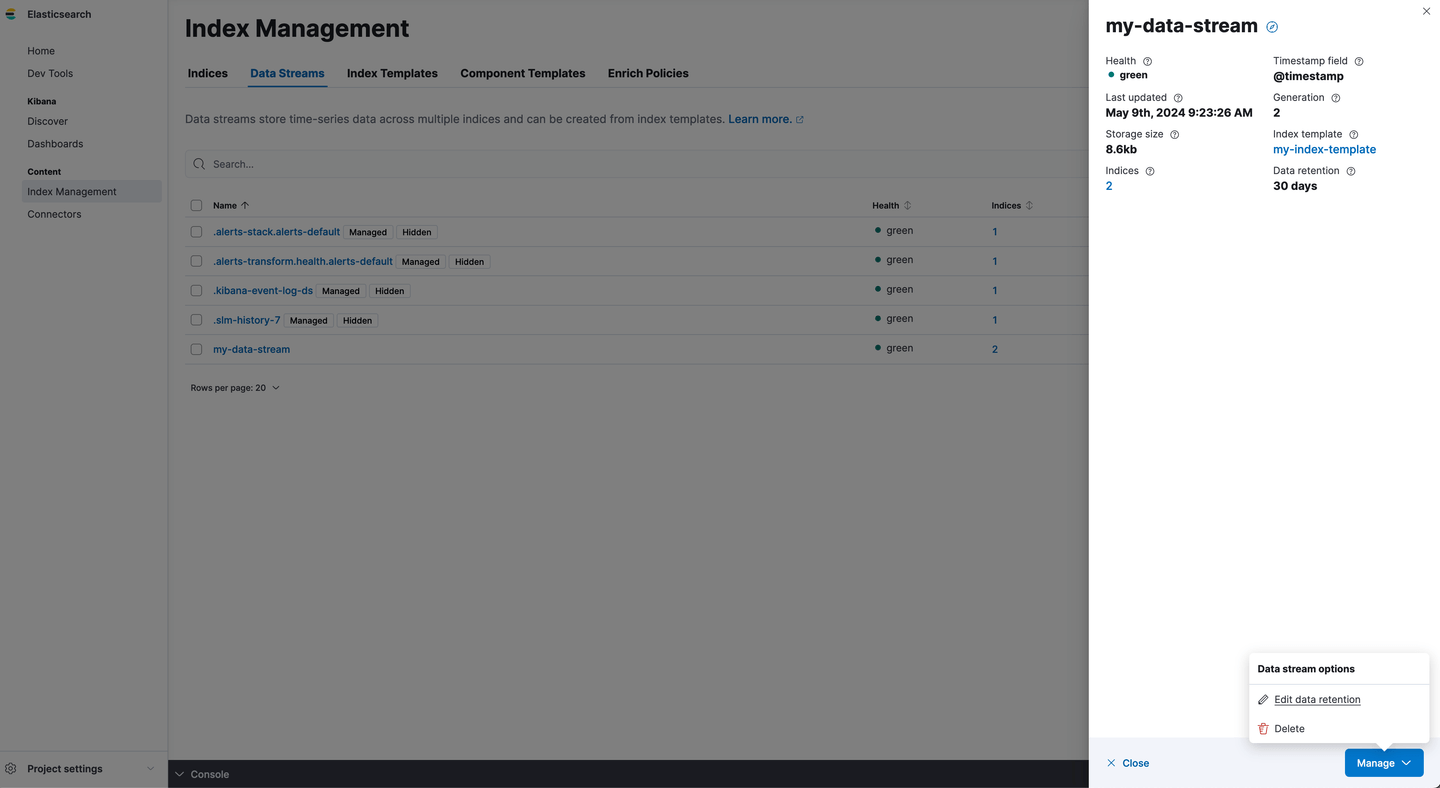
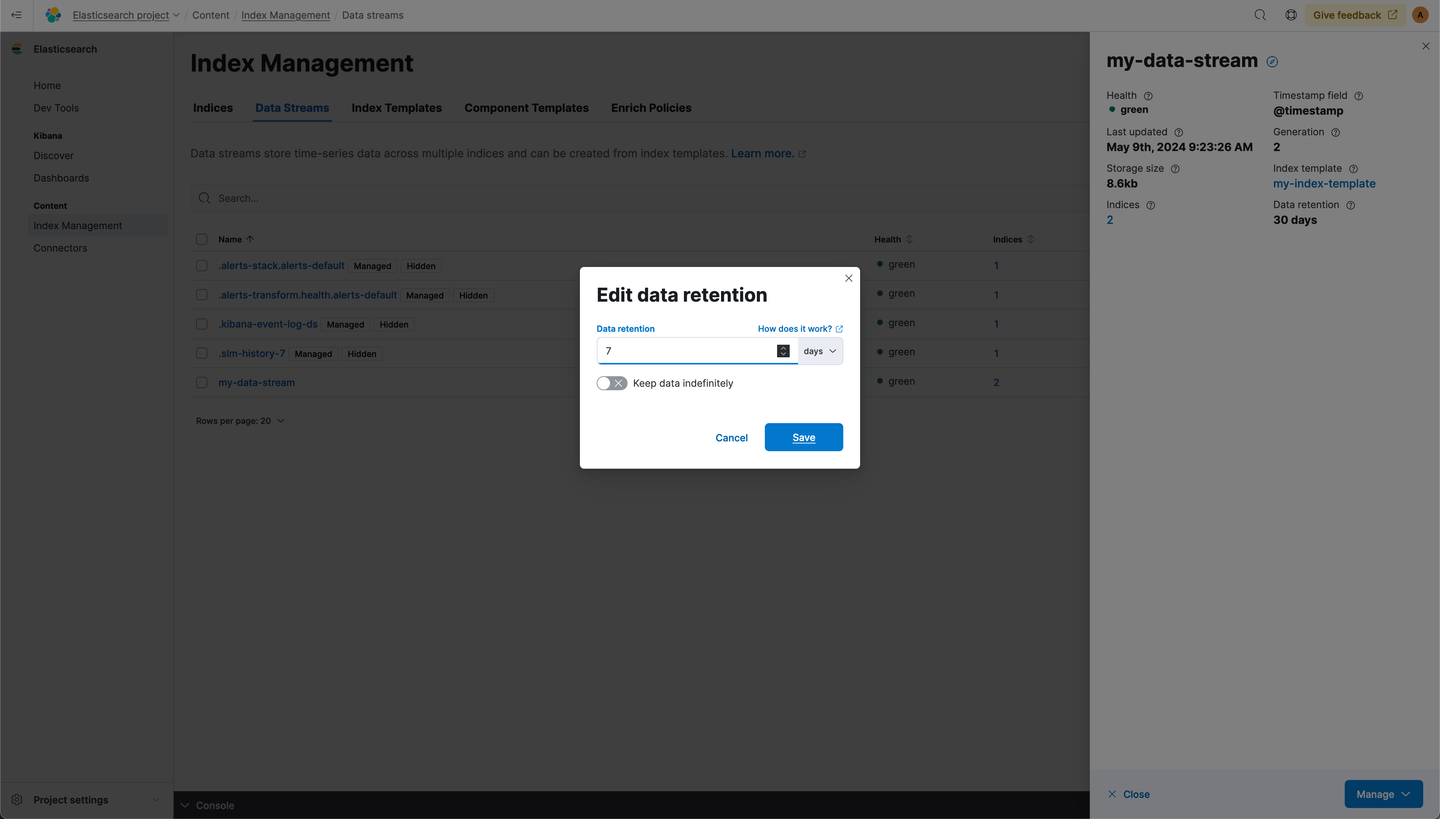
We now see our data stream has a data retention of 7 days:
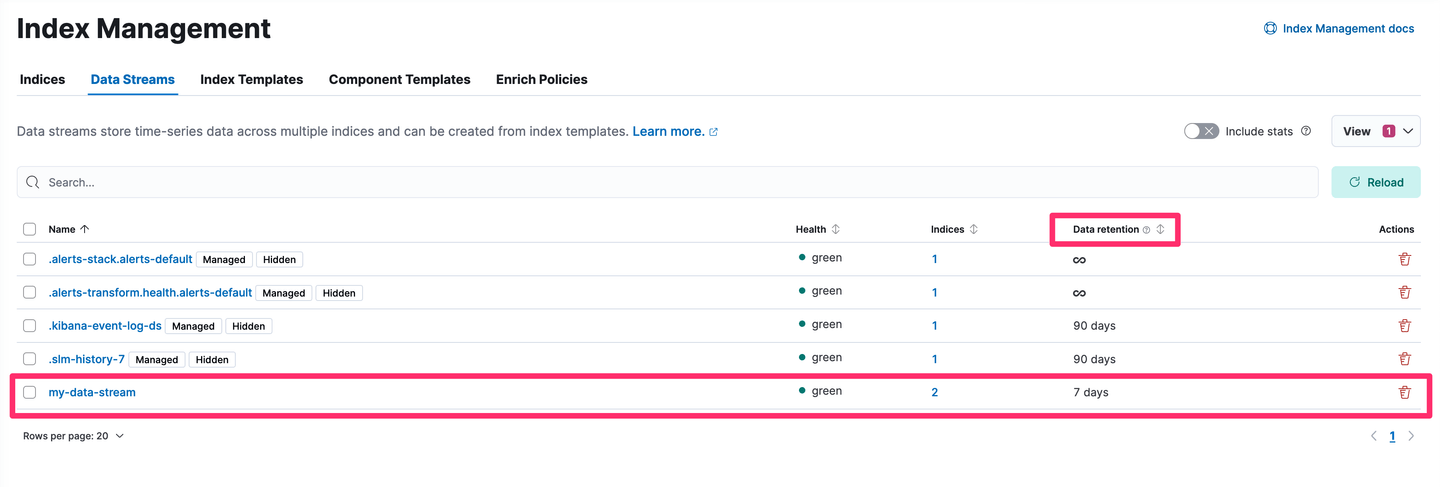
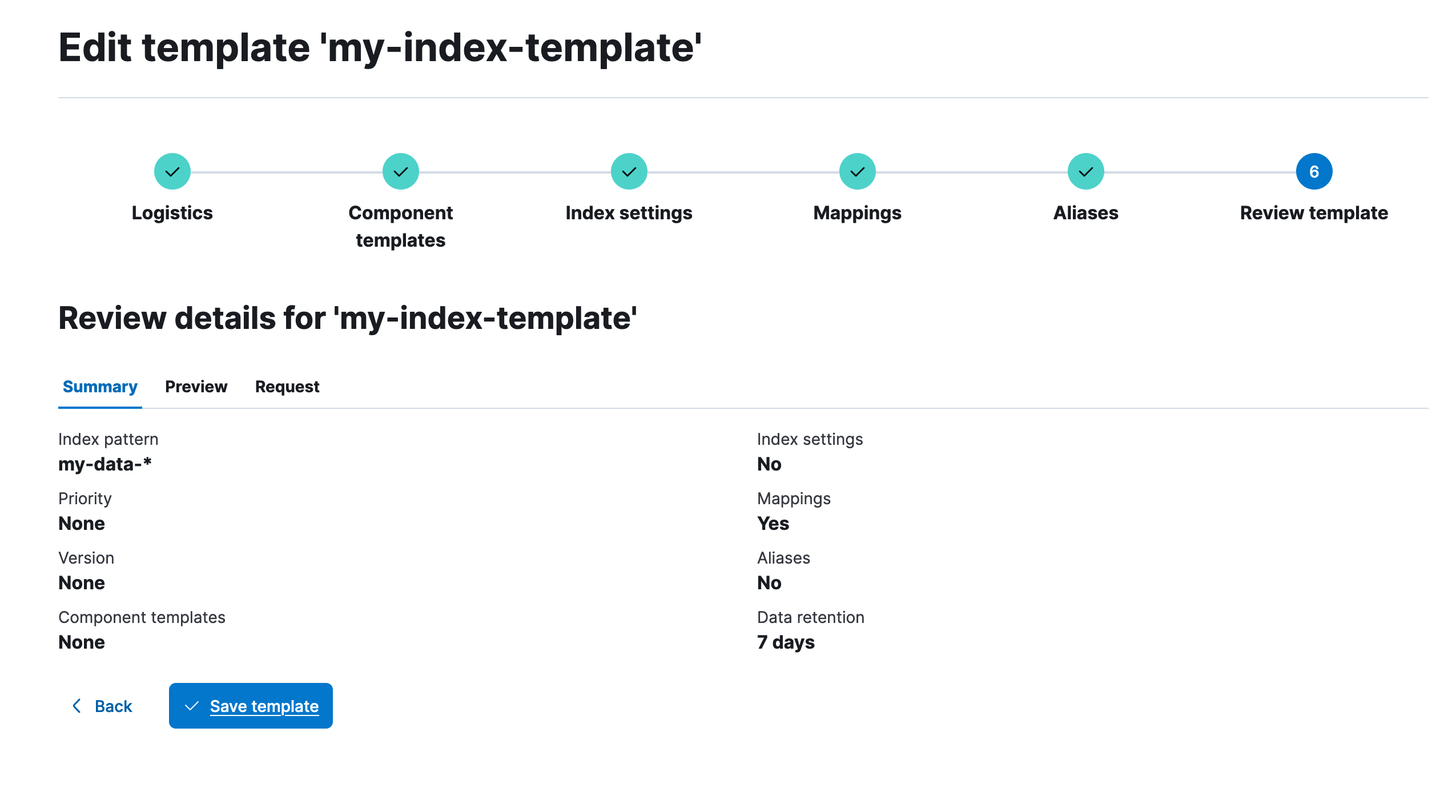
Now that the existing data stream in the system has the desired 7 days retention period configured, let’s also update the index template retention so that new data streams that get created also receive the 7 days retention period:
Implementation details
The master node periodically (every 5 minutes by default, according to the data_streams.lifecycle.poll_interval setting) iterates over the data streams in the system that are configured to be managed by the lifecycle. On every iteration, each backing index state in the system is evaluated and one operation is executed towards achieving the target state described by the configured lifecycle.
For each managed data stream we first attempt to rollover the data stream according to the cluster.lifecycle.default.rollover conditions. This is the only operation attempted for the write index of a data stream.
After rolling over, the former write index becomes eligible for merging. As we wanted the merging of the shards maintenance task to be something we execute automatically we implemented a lighter merging operation, an alternative to force merging to 1 segment, that only merges the long tail of small segments instead of the entire shard. The main benefit of this approach is that it can be applied automatically and early after rollover.
Once a backing index has been merged, on the next lifecycle execution run, the index will be downsampled.
After completing all the scheduled downsample rounds, each time the lifecycle runs, the backing index will be examined for eligibility for data retention. When the specified data retention period lapses (since rollover time), the backing index will be deleted.
Both downsampling and data retention are time based operations (e.g. data_retention: 7d) and are calculated since the index was rolled over. The time since an index has been rolled over is visible in the explain lifecycle API and we call it generation_time and represents the time since a backing index became a generational index (as opposed to being the write index of a data stream).
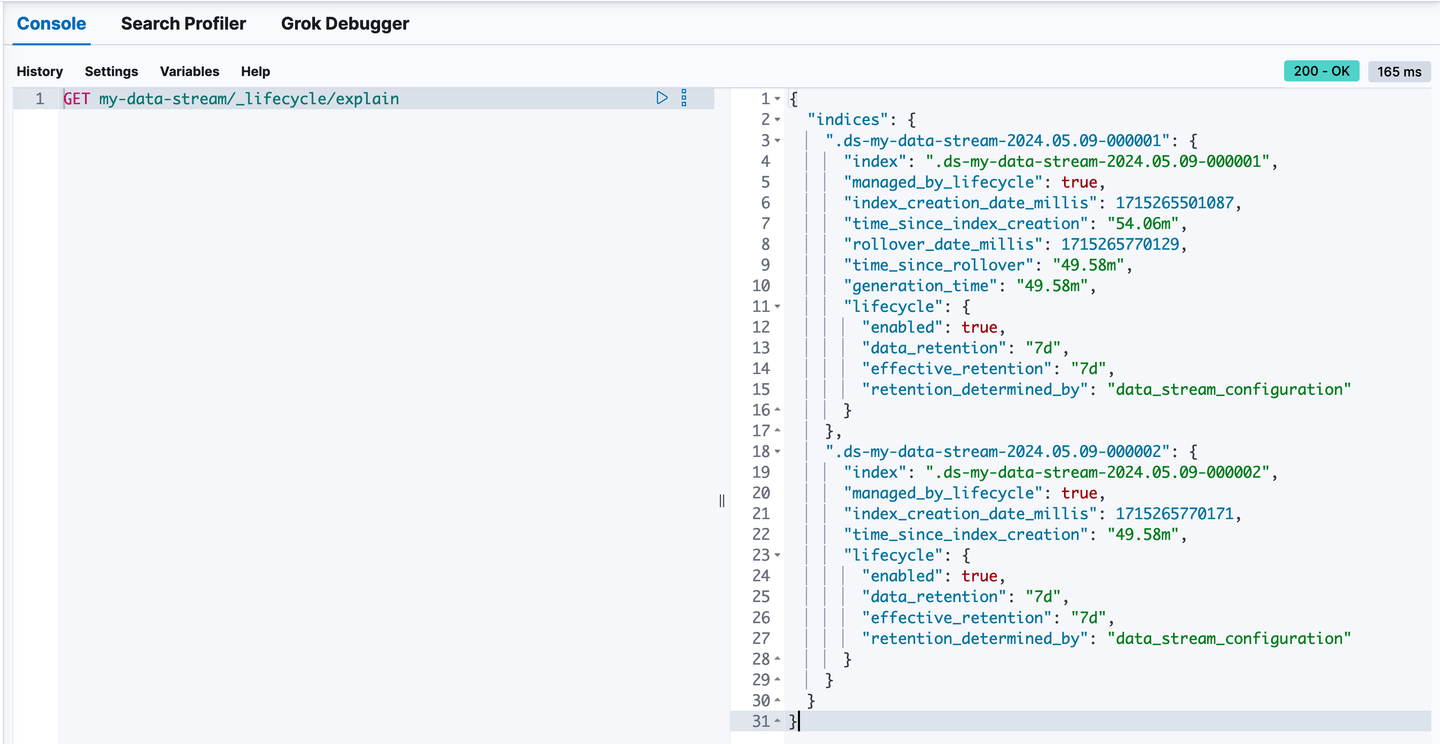
I’ve run the explain lifecycle API for my-data-stream (which has 2 backing indices as it was rolled over) to get some insights into
We can see the lifecycle definition for both indices includes the updated data retention of 7 days.
The older index, .ds-my-data-stream-2024.05.09-000001, is not the write index of the data stream anymore and we can see the explain API reports the generation_time as 49 minutes. Once the generation time reaches 7 days, the .ds-my-data-stream-2024.05.09-000001 backing index will be deleted to conform with the configured data retention.
Index .ds-my-data-stream-2024.05.09-000002 is the write index of the data stream and is waiting to be rolled over once it meets the rollover criteria.
The time_since_index_creation field is meant to help calculating when to rollover the data stream according to an automatic max_age criteria when the data stream is not receiving a lot of data anymore.
Migrating from ILM to data stream lifecycle
Facilitating a smooth transition to data stream lifecycle for testing, experimenting, and eventually production migration of data streams was always a goal for this feature. For this reason, we decided to allow ILM and data stream lifecycle to co-exist on a data stream in cloud environments and on premise deployments.
The ILM configuration continues to exist directly on the backing indices whilst the data stream lifecycle is configured on the data stream itself.
A backing index is managed by only one management system at a time. If both ILM and data stream lifecycle are applicable for a backing index, ILM takes precedence (by default, but the precedence can be changed to data stream lifecycle using the index.lifecycle.prefer_ilm index setting).
The migration path for a data stream will allow the existing ILM-managed backing indices to age out and eventually get deleted by ILM, whilst the new backing indices will start being managed by data stream lifecycle.
We’ve enhanced the GET _data_stream API to include rollover information for each backing index (a managed_by field with Index Lifecycle Management, Data stream lifecycle, or Unmanaged as possible values, and the value of the prefer_ilm setting) and at the data stream level a next_generation_managed_by field to indicate the system that’ll manage the next generation backing index.
To configure the future backing indices (created after data stream rollover) to be managed by data stream lifecycle two steps need to be executed:
Update the index template that’s backing the data stream to set prefer_ilm to
false(note thatprefer_ilmis an index setting so configuring it in the index template means it’ll only be configured on the new backing indices) and configure the desired data stream lifecycle (this will make sure the new data streams will start being managed by data stream lifecycle).Configure the data stream lifecycle for the existing data streams using the lifecycle API.
For a complete tutorial on migrating to data stream lifecycle check out our documentation.
Conclusion
We’ve built a lifecycle functionality for data streams that handles the underlying data structures maintenance automatically and lets you focus on the business lifecycle needs like downsampling and data retention.
Try out our new Serverless offering and learn more about the possibilities of data stream lifecycle.
Frequently Asked Questions
What is data stream lifecycle in Elasticearch?
Data stream lifecycle, available from version 8.14, is a management system for data streams that automatically handles the maintenance of underlying data structures.