Elasticsearch : créer une application chatbot RAG
Aperçu
Introduction
Ce guide vous permettra de vous lancer dans la configuration et l’exécution d’une application RAG de chatbot. RAG est l'acronyme de Retrieval-Augmented Generation. Cette technique utilise une base de données sur mesure pour fonder les réponses des grands modèles linguistiques (LLM) d’IA générative (GenAI) et empêcher ainsi des problèmes comme les hallucinations des LLM. Ce processus explique comment paramétrer et utiliser l’application de chatbot RAG d’Elastic fournie à titre d’exemple, ce qui vous permettra de la découvrir en action.
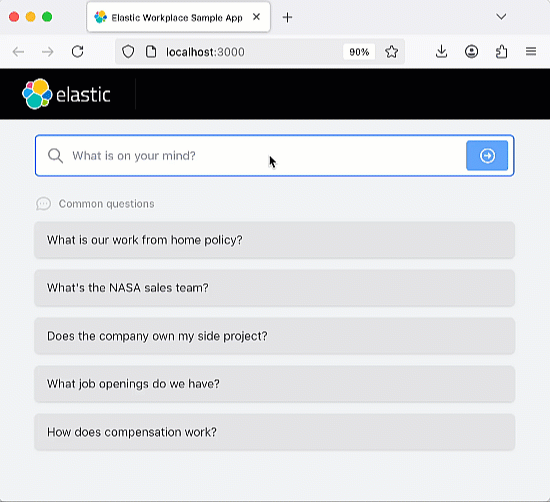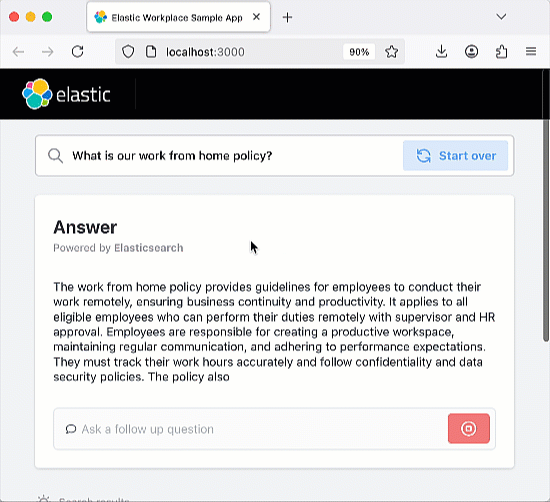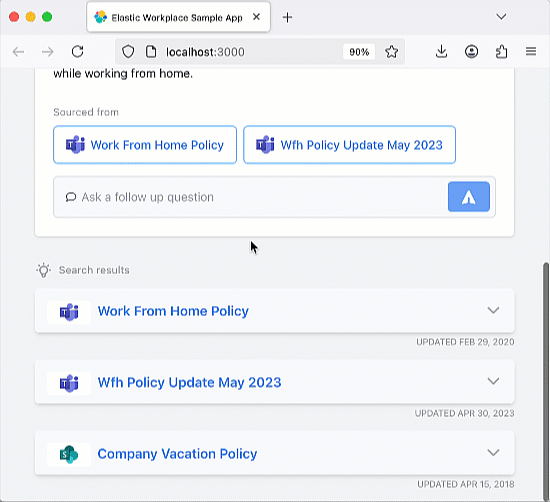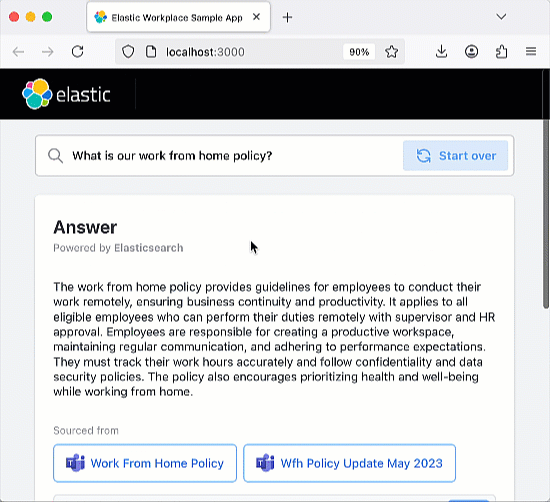
Cette application de chatbot RAG est open source et hébergée sur GitHub, ce qui vous permet de la cloner, de la forker et de créer votre propre version. L’application utilise Elastic Cloud pour héberger un index Elasticsearch qui sert de « source de vérité » pour l’augmentation de la récupération de l’application RAG. Cela assure que les réponses produites sont fondées sur les informations présentes dans les documents de l’index. Cette application de chatbot RAG est conçue pour fonctionner avec divers services de LLM répandus, comme OpenAI. L’architecture de l’application repose sur un back-end Python Flask et un front-end React. Référez-vous au tutoriel sur le chatbot d’Elasticsearch Labs pour prendre connaissance de l’ensemble des exigences de l’application.
Cette application de chatbot RAG est idéale pour découvrir et tester les applications RAG, car elle peut être lancée sur votre machine locale. Vous pourrez ainsi observer directement comment les intégrations avec Elastic Cloud et les LLM s’articulent pour offrir une expérience de recherche basée sur la GenAI et adaptée à vos propres documents. Cette application est compatible avec une variété de LLM, notamment OpenAI, AWS Bedrock, Azure OpenAI, Google Vertex AI, Mistral AI et Cohere. Deux méthodes s’offrent à vous pour déployer l’exemple d’application de chatbot RAG sur votre machine locale : l’utilisation de Docker ou celle de Python.
Entrons dans le vif du sujet
Exécution de l’application de chatbot RAG
En fonction de votre approche de déploiement préférée, veuillez suivre les étapes indiquées soit dans la section « Exécuter l’application de chatbot avec Docker », soit dans la section « Exécuter l’application de chatbot avec Python » ci-dessous. Le recours à Docker simplifie la procédure, alors qu’opter pour Python permettra une compréhension plus détaillée de la manière de configurer et d’exécuter les composants back-end et front-end de l’application. Les deux méthodes d’exécution de l’application utilisent OpenAI comme LLM. Après avoir fait fonctionner l’application avec OpenAI, il suffit de quelques manipulations simples pour la configurer avec un autre LLM compatible.
Exécutez l'application de Chatbot avec Docker
Le processus d'exécution de l'application chatbot RAG avec Docker implique :
- Clonage du code de l’application
- Création d'un déploiement Elastic Cloud
- Création d'une clé d'API OpenAI
- Configuration des paramètres de l’application
Suivez cette visite guidée qui comprend toutes les étapes nécessaires pour atteindre l’objectif d’exécuter l’application sur votre ordinateur local :
Visite guidée : exécuter l’application de chatbot RAG avec OpenAI en utilisant Docker
Exécutez l'application chatbot avec Python
Le processus d'exécution de l'application chatbot RAG avec Python implique :
- Clonage du code de l’application
- Création d'un déploiement Elastic Cloud
- Création d'une clé d'API OpenAI
- Configuration des paramètres de l’application
Une fois l’application et ses dépendances configurées, le back-end Python de l’application sera démarré. Puis, l’interface utilisateur de l’application, développée en React, démarrera et sera accessible dans votre navigateur.
Suivez cette visite guidée qui comprend toutes les étapes nécessaires pour atteindre l’objectif d’exécuter l’application sur votre ordinateur local :
Visite guidée : exécuter l'application chatbot RAG avec OpenAI en Python
Fonctionnement d'Elasticsearch
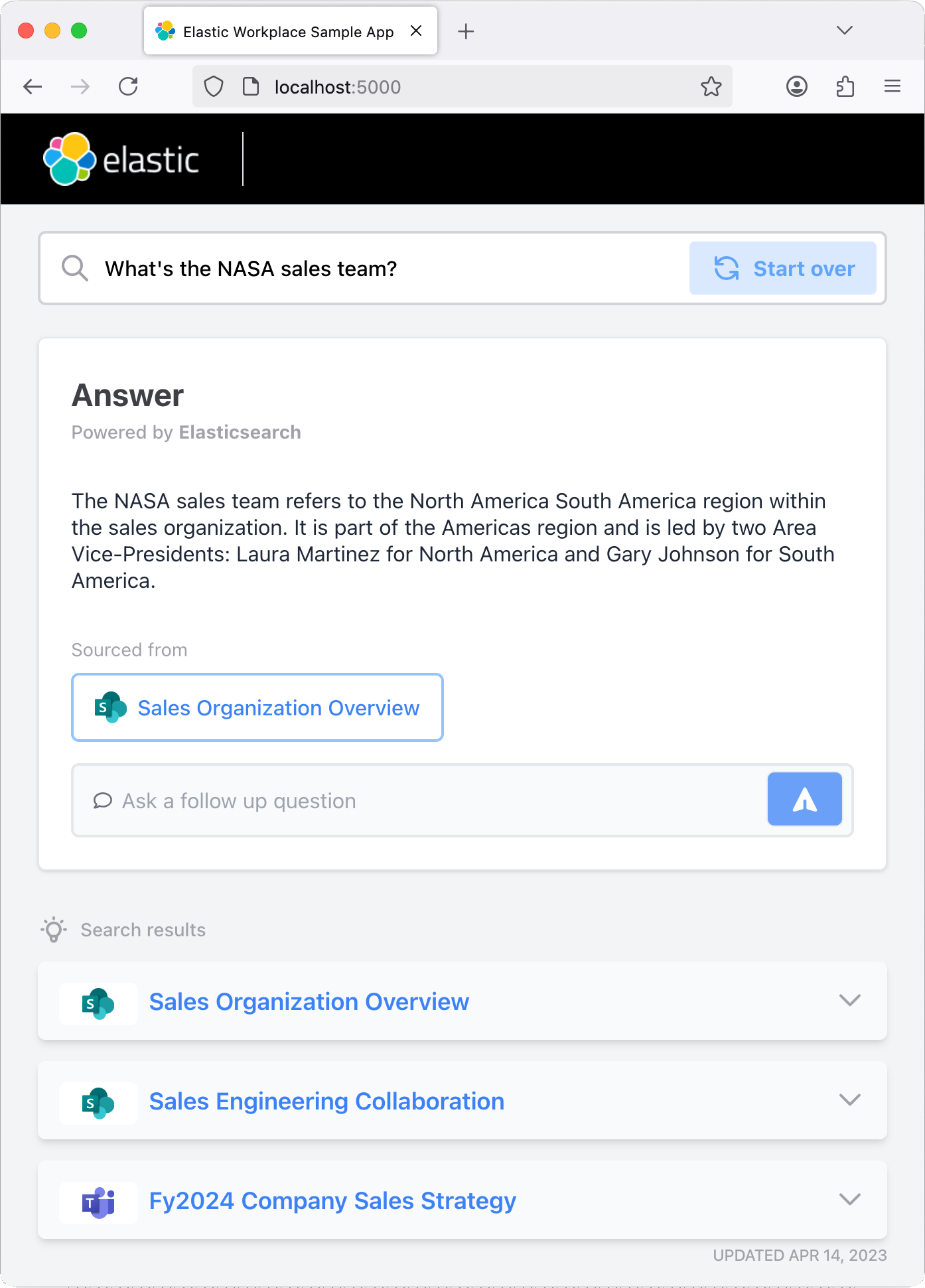
Jouer avec l'application en cours d'exécution
Une fois l’application lancée, n’hésitez pas à poser une question ou à utiliser l’une des questions prédéfinies. L’application intègre un index Elastic qui enregistre l’historique de vos échanges. N’hésitez pas à poser des questions complémentaires pour tester la « mémoire » du chatbot.
Étapes suivantes
Merci d’avoir pris le temps de vous familiariser avec la procédure de lancement de l’application de chatbot RAG d’Elastic fournie à titre d’exemple. Lorsque vous commencerez avec Elastic, vous comprendrez certains éléments opérationnels, de sécurité et de données que vous devrez gérer en tant qu'utilisateur lors du déploiement dans votre environnement.
Prêt à vous lancer ? Bénéficiez d’un essai gratuit de 14 jours sur Elastic Cloud.