Software Asset Management avec Elasticsearch chez Red Mint Network
Lorsque votre entreprise a atteint une taille significative avec une infrastructure informatique comprenant un nombre considérable de postes de travail et de serveurs, il vous est parfois difficile de gérer vos actifs logiciels et d'avoir un aperçu exact de l'état de vos ressources. Lorsque l'heure de l'audit arrive (pour répondre à la demande de Microsoft, par exemple), cela peut être trop tard si vous ne disposez pas des analyses nécessaires pour restituer des données d'historique précises. Combien d'utilisateurs pour un logiciel spécifique ? Quelle est la durée d'utilisation par utilisateur ? Le nombre d'instances en cours d'utilisation est-il supérieur au nombre de licences achetées ? Quelqu'un utilise t-il des copies illégales des logiciels ? Ou, à l'inverse, avez-vous acheté plus de licences que ce dont vous avez réellement besoin ?
Le fait d'ignorer ces informations peut vous exposer à des frais supplémentaires en raison du paiement de licences inutiles, des ajustements de factures et des frais juridiques. Nous allons vous expliquer comment nous gérons les actifs logiciels de manière intelligente et pragmatique grâce à Elasticsearch et à la télémétrie SDN (Software Defined Networking).
Le réseau comme source de données
Fort heureusement, de nombreux programmes logiciels sont très loquaces. Ils contactent en permanence les serveurs de leurs fournisseurs pour différentes raisons, comme pour les demandes d'autorisation, la vérification des mises à jour, la télémétrie ou l'accès aux services de cloud. Cela génère du trafic sur le réseau, qui peut être disséqué par une VNF (fonction de réseau virtuel) au sein de l'infrastructure du fournisseur Internet, puis exploré dans Elasticsearch.
Lorsque l'on connait la source du paquet réseau (là où le logiciel est installé), sa destination et son horodatage, il est possible de savoir le moment auquel un logiciel est à jour, simplement en détectant des évènements significatifs sur la liaison réseau.
Par exemple, nous avons constaté que, lorsque Adobe® Photoshop® CC ou Adobe® Illustrator® CC fonctionnaient, ils ouvraient une session à cryptage TLS sous ans.oobesaas.adobe.com :
Ici, nous utilisons le champ anonymisé host_hmac pour identifier la source des données (c'est-à-dire un ordinateur, ou une tablette, etc.) et le SNI (Server Name Indication - Indication de nom de serveur) du certificat extrait de l'authentification TLS pour identifier la destination.
Kibana nous indique que cet échange est effectué toutes les 9 minutes :
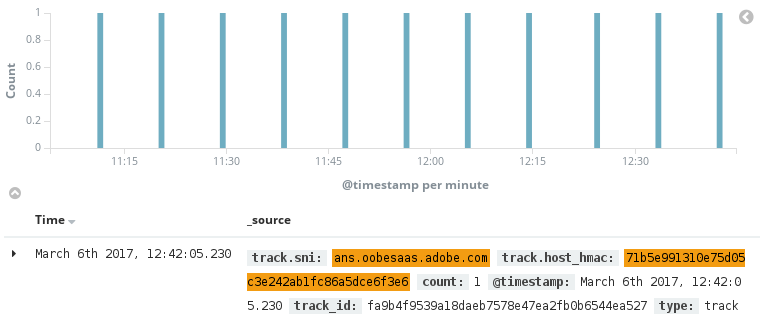
Ces informations sont suffisantes pour déterminer le nombre d'utilisateurs sur le réseau et la durée d'utilisation sur une période donnée !
Calcul du nombre d'utilisateurs
Dans cet exemple, nous souhaitons calculer le nombre d'utilisateurs pour chaque jour de la semaine passée. Tout d'abord, nous filtrons les données afin de sélectionner uniquement les objets qui correspondent au SNI associé et à la date demandée. Le sélecteur de date est utilisé pour définir une plage relative (entre maintenant-7j/j et maintenant/j). Ensuite, nous utilisons le cumul histogramme de dates pour collecter les données quotidiennes. Enfin, le nombre d'utilisateurs est calculé directement à l'aide du cumul cardinalité dans le champ host_hmac.
Demandons à Elasticsearch de rechercher le nombre d'utilisateurs d'Adobe pour chaque jour de la semaine passée :
<pre class="prettyprint"> { "size": 0, "timeout": "1s", "aggs": { "telemetry": { "filter": { "bool": { "must": [ { "range": { "@timestamp": {"gte": "now-7d/d", "lte": "now/d"} } } ], "should": [ {"match": {"track.sni": "ans.oobesaas.adobe.com"}} ], "minimum_should_match": 1 } }, "aggs": { "time_slot": { "date_histogram": { "field": "@timestamp", "interval": "day" }, "aggs": { "user_count": {"cardinality": {"field": "track.host_hmac"}} } } } } } } </pre>Calcul de la durée d'utilisation
Pour calculer la durée d'utilisation, une valeur « Time-To-Live » doit être définie. Si aucun signal n'est visible pendant cette période, le logiciel est considéré comme inutilisé. En cas de signal périodique, la valeur TTL doit être légèrement supérieure à la période de signal afin d'empêcher tout bug dû à la latence du réseau ou aux ralentissements de l'hôte. L'exemple ci-dessous utilise une valeur TTL de 10 minutes (supérieure à la valeur TTL de 9 minutes observée dans Adobe®).

Utilisons le cumul métrique à script pour calculer la durée d'utilisation par utilisateur et obtenir la valeur moyenne.
Ce type de cumul permet de mettre en place un modèle Map/Reduce avec une combinaison de quatre scripts rédigés en langage Painless.
init
Initialisation d'une hashmap vide pour cumuler les résultats hôte par hôte.
<pre class="prettyprint"> params._agg = [:]; </pre>map
Collecte des horodatages de chaque occurrence de signal.
<pre class="prettyprint"> def host = doc['track.host_hmac'].value; def ts = doc['@timestamp'].value; /* Gather signal timestamps for each host */ params._agg.putIfAbsent(host, []); params._agg[host].add(ts); </pre>combine
Tri des résultats de chaque instance.
<pre class="prettyprint"> for (ts_list in params._agg.values()) { ts_list.sort(Long::compare); } return params._agg; </pre>reduce
- Fusion des résultats
- Calcul de la durée d'utilisation par utilisateur
- Calcul et obtention de la valeur moyenne
A ce jour, le cumul « métrique à script » reste expérimental. Le transfert de son résultat vers un autre cumul ne semble pas être pris en charge pour l'instant. C'est la raison pour laquelle le calcul de la moyenne est effectué par le script Painless, et non avec le cumul Avg Bucket.
Visualisation des données
Il est possible de combiner ces deux cumuls en une seule requête :
<pre class="prettyprint"> { "aggs" : { "time_slot": { "date_histogram": { "field": "@timestamp", "interval": "day" }, "aggs": { "user_count": { "cardinality": { "field": "track.host_hmac" } }, "time_used": { "scripted_metric": { "init_script": "...", "map_script": "...", "combine_script": "...", "reduce_script": "..." } } } } } </pre>Le résultat est facile à analyser : pour chaque jour de la période demandée, nous obtenons le nombre d'utilisateurs et la durée d'utilisation moyenne.
<pre class="prettyprint"> "buckets": [ { "key_as_string": "2017-03-11T00:00:00.000Z", "key": 1489190400000, "doc_count": 4352, "user_count": { "value": 128 }, "time_used": { "value": 20340 } }, { "key_as_string": "2017-03-12T00:00:00.000Z", "key": 1489276800000, "doc_count": 4860, "user_count": { "value": 180 }, "time_used": { "value": 16080 } }, ... ] </pre>Le résultat de cette requête est suffisant pour afficher les deux valeurs sur le même diagramme en barres/en segments créé avec Chart.js.
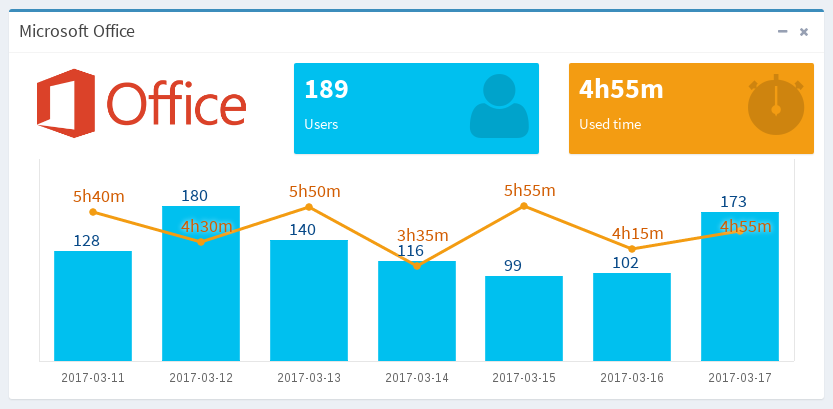
L'exploration des sources de données réseau peut constituer un puissant moyen d'analyse pour le service Informatique lorsqu'elle est associée à Elastic Stack. La révolution qui s'opère et qui consiste à utiliser de plus en plus la télémétrie SDN et les fonctions de réseau virtuel permet de proposer de nouveaux services de données aux clients, en considérant les données comme un service. Extraire le signal du bruit, lui donner un sens à l'aide Elasticsearch, et présenter les données comme une ressource de valeur : voilà ce que nous faisons, en espérant que vous aurez apprécié cet article. Vianney Bajart @ Red Mint Network.
Adobe Photoshop CC et Adobe Illustrator CC sont des marques déposées ou des appellations commerciales de Adobe Systems Incorporated aux États-Unis et/ou dans les autres pays.