Prise en main des visualisations Vega dans Kibana
La syntaxe déclarative Vega est un outil puissant pour visualiser vos données. Nouveauté dans Kibana 6.2 : vous pouvez désormais construire des visualisations riches Vega et Vega-Lite avec vos données Elasticsearch. Il est temps pour nous de découvrir le langage Vega au travers de quelques exemples simples.
Pour commencer, ouvrez l’éditeur Vega, un outil pratique pour tester le langage Vega "brut" (c’est-à-dire sans personnalisations Elasticsearch). Copiez le code ci-dessous. Le texte "Hello Vega!" s’affiche dans le panneau de droite.

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 100, "height": 30,
"background": "#eef2e8",
"padding": 5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value": "Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value": 15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
Le bloc de repères est une série de primitives de dessin, p. ex. texte, lignes et rectangles. Chaque repère dispose d’un grand nombre de paramètres indiqués dans l’ensemble d’encodage. Chaque paramètre est défini soit sur une constante (valeur), soit sur le résultat d’un calcul (signal) au stade de "mise à jour". Pour le repère de texte, nous définissons la chaîne de texte, nous veillons à ce que le texte soit correctement positionné par rapport aux coordonnées indiquées, dans le bon sens, et nous en définissons la couleur. Les coordonnées x et y sont calculées en fonction de la largeur et de la hauteur du graphe, en positionnant le texte au milieu. Il existe bien d’autres paramètres de repères de texte. Il y a également un graphe de démonstration interactif pour tester différentes valeurs de paramètres pour le repère de texte.
Expliquons quelques éléments : $schema correspond tout simplement à l’ID de la version du moteur Vega requise ; Background permet d’avoir un graphe qui n’est pas transparent ; width et height définissent la taille du quadrillage du dessin initial. La taille du graphe final peut changer dans certains cas, selon le contenu et les options d’autodimensionnement. Remarque : La valeur autosize par défaut dans Kibana est fit, et non pas pad. De ce fait, les éléments height et width sont facultatifs. Le paramètre padding permet d’ajouter de l’espace autour du graphe, en plus de définir la largeur et la hauteur.
Graphe axé sur les données
Prêt pour la prochaine étape ? Nous allons maintenant dessiner un graphe axé sur les données à l’aide du repère de rectangle. La section des données permet d’utiliser plusieurs sources de données, qu’elles soient codées en dur ou qu’elles se présentent sous forme d’URL. Dans Kibana, vous pouvez aussi utiliser des requêtes Elasticsearch directes. Notre table de données vals comprend quatre lignes et deux colonnes (category et count). La colonne category permet de positionner la barre sur l’axe x, tandis que la colonne count définit la hauteur de la barre. Remarque : La valeur 0 pour la coordonnée y se trouve tout en haut. Plus la barre descend, plus la valeur augmente.
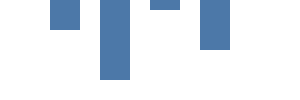
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 300, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 30},
{"category": 100, "count": 80},
{"category": 150, "count": 10},
{"category": 200, "count": 50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"field": "count"},
"y2": {"value": 0}
}
}
} ]
}
Le repère rect indique que la table vals est la source de données. Le repère est dessiné une fois par valeur de donnée source (connu aussi comme ligne de table ou datum). À la différence du graphe précédent, les paramètres x et y ne sont pas codés en dur : ils proviennent des champs du datum.
Montée en charge
La montée en charge est l’un des concepts les plus importants de Vega, mais aussi l’un des plus délicats. Dans les exemples précédents, les coordonnées des pixels à l’écran étaient codées en dur dans les données. Même si cela facilite les choses, il est rare que les données réelles arrivent sous cette forme. À la place, les données sources se présentent sous leurs propres unités (p. ex. nombre d’événements), et c’est au graphe d’effectuer la montée en charge des valeurs sources en pixels selon la taille de graphe souhaitée.
Dans cet exemple, c’est la montée en charge linéaire qui est utilisée. Il s’agit essentiellement d’une fonction mathématique servant à convertir une valeur du domaine des données sources (ici, les valeurs count de 1 000 à 8000, y compris count=0) selon la plage souhaitée (ici, la hauteur du graphe, de 0 à 99). La fonction de montée en charge yscale permet d’ajouter "scale": "yscale" aux paramètres y et y2 afin de convertir les valeurs count en coordonnées à l’écran (0 devient 99, et 8 000 - la plus grande valeur des données sources - devient 0). Remarque : Le paramètre de plage height est un cas spécial car il fait en sorte que la valeur 0 apparaisse en bas du graphe.
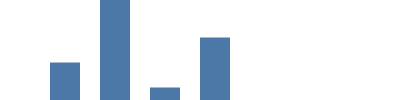
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 3000},
{"category": 100, "count": 8000},
{"category": 150, "count": 1000},
{"category": 200, "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Montée en charge de bande
Pour notre tutoriel, nous aurons besoin d’un autre type de montée en charge Vega 15+ : une montée en charge de bande. Ce type de montée en charge sert lorsque nous disposons d’un ensemble de valeurs (p. ex. des catégories) à représenter sous forme de bandes, occupant chacune la même largeur proportionnelle sur la largeur totale du graphe. Dans le cas présent, la montée en charge de bande attribue à chacune des quatre catégories uniques la même largeur proportionnelle (environ 400/4, moins 5 % de couche entre les barres et aux extrémités). {"scale": "xscale", "band": 1} obtient 100 % de la largeur des bandes pour le paramètre width du repère.
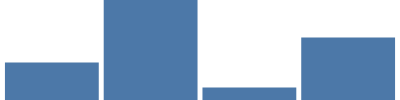
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges", "count": 3000},
{"category": "Pears", "count": 8000},
{"category": "Apples", "count": 1000},
{"category": "Peaches", "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Axes
Un graphe type ne serait pas complet sans balises d’axe. La définition des axes applique les mêmes montées en charge que celles indiquées précédemment. Pour les ajouter, rien de plus simple : il suffit de désigner la montée en charge par son nom et d’en préciser le côté de positionnement. Ajoutez le code suivant en tant qu’élément de niveau supérieur dans le dernier exemple de code.
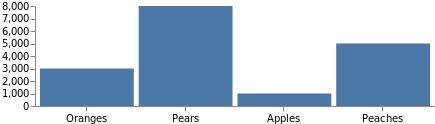
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
Remarque : La taille du graphique a automatiquement augmenté pour s’adapter à ces axes. Si vous souhaitez que le graphe conserve sa taille d’origine, ajoutez "autosize": "fit" dans la spécification.
Transformations des données et conditions
Pour pouvoir utiliser les données dans le dessin, il faut généralement les manipuler auparavant. Pour cela, Vega propose différentes transformations. Commençons par la transformation de formule la plus courante pour ajouter un champ de valeur count aléatoire à chaque datum source de façon dynamique. Dans ce graphe, nous allons également nous servir de la fonction de couleur de remplissage de la barre : les valeurs inférieures à 333 seront indiquées en rouge, celles comprises entre 333 et 666, en jaune, et celles supérieures à 666, en vert. Remarque : Il est possible d’utiliser une montée en charge à la place, en mappant le domaine des données sources à l’ensemble de couleurs ou à un spectre de couleurs.
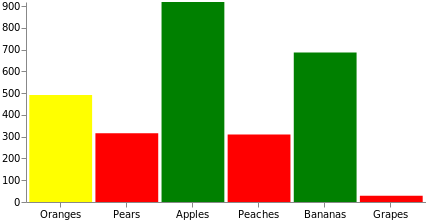
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges"},
{"category": "Pears"},
{"category": "Apples"},
{"category": "Peaches"},
{"category": "Bananas"},
{"category": "Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Données dynamiques avec Elasticsearch et Kibana
Maintenant que vous disposez des connaissances de base, passons aux choses sérieuses. Nous allons créer un graphe linéaire basé sur le temps en nous servant de données Elasticsearch générées de façon aléatoire. La procédure est similaire à celle que nous avons vue initialement lors de la création d’un graphe Vega dans Kibana. La seule différence, c’est que nous allons nous servir du langage Vega au lieu des paramètres par défaut Kibana de Vega-Lite (la version simplifiée de niveau supérieur de Vega).
Dans cet exemple, nous allons coder les données en dur avec values, au lieu d’émettre la requête réelle avec url. Ainsi, nous pourrons continuer nos essais dans l’éditeur Vega qui ne prend pas en charge les requêtes Elasticsearch Kibana. Le graphe deviendra totalement dynamique dans Kibana si vous remplacez values par la section url comme indiqué ci-dessous.
Notre requête recense le nombre de documents par intervalle de temps, en se servant de la plage de temps et des filtres de contexte sélectionnés par l’utilisateur du tableau de bord. Consultez comment interroger Elasticsearch à partir de Kibana pour en savoir plus.
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count": 0
}
}
},
"size": 0
}
Voici le résultat que nous obtenons lorsque nous l’exécutons (nous avons supprimé certains champs non pertinents dans un souci de concision) :
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528061400000, "doc_count": 1},
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528066800000, "doc_count": 17},
...
Comme vous pouvez le constater, les données réelles dont nous avons besoin se trouvent dans la série aggregations.time_buckets.buckets. Nous pouvons indiquer à Vega de se concentrer uniquement sur cette série en indiquant "format": {"property": "aggregations.time_buckets.buckets"} dans la définition des données.
Notre axe x n’est plus basé sur les catégories, mais sur le temps : le champ key est exprimé sous forme d’heure UNIX que Vega peut utiliser directement. Nous changeons donc le type xscale en temps, et nous ajustons tous les champs pour qu’ils utilisent key et doc_count. Nous devons également modifier le type de repère en line, et inclure uniquement les canaux de paramètres x et y. Voilà ! Vous avez désormais un graphe linéaire ! Si vous le souhaitez, vous pouvez personnaliser les balises de l’axe x avec les paramètresformat, labelAngle et tickCount.
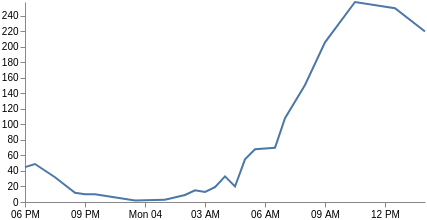
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528068600000, "doc_count": 32},
{"key": 1528072200000, "doc_count": 12},
{"key": 1528074000000, "doc_count": 10},
{"key": 1528075800000, "doc_count": 10},
{"key": 1528083000000, "doc_count": 2},
{"key": 1528088400000, "doc_count": 3},
{"key": 1528092000000, "doc_count": 9},
{"key": 1528093800000, "doc_count": 15},
{"key": 1528095600000, "doc_count": 13},
{"key": 1528097400000, "doc_count": 19},
{"key": 1528099200000, "doc_count": 33},
{"key": 1528101000000, "doc_count": 20},
{"key": 1528102800000, "doc_count": 55},
{"key": 1528104600000, "doc_count": 68},
{"key": 1528108200000, "doc_count": 70},
{"key": 1528110000000, "doc_count": 108},
{"key": 1528113600000, "doc_count": 151},
{"key": 1528117200000, "doc_count": 206},
{"key": 1528122600000, "doc_count": 258},
{"key": 1528129800000, "doc_count": 250},
{"key": 1528135200000, "doc_count": 220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
Gardez un œil sur notre blog pour lire d’autres articles sur Vega. Parmi les thèmes abordés prochainement : comment gérer les résultats Elasticsearch, notamment les agrégations et les données imbriquées.