Comprendre le maillage de données dans le secteur public : piliers, architecture et exemples


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Pensez à toutes les données qui se cachent derrière des projets tels que le renseignement militaire, les dossiers de santé publique, les modèles d'urbanisme, etc. Les organismes gouvernementaux génèrent en permanence d'énormes quantités de données. La situation se complique encore davantage lorsque ces données sont réparties sur plusieurs plateformes cloud, des systèmes sur site ou des environnements spécialisés tels que des satellites ou des centres d'intervention d'urgence. Il est difficile de trouver les informations, et encore plus de les utiliser efficacement. De plus, lorsque différentes équipes travaillent avec de nombreuses applications et formats de données différents, un véritable manque d'interopérabilité apparaît.
Malgré tous leurs efforts pour mettre en place des organismes axés sur les données, 65 % des dirigeants du secteur public ont encore du mal à utiliser les données en continu, en temps réel et à grande échelle, selon une étude récente d'Elastic.
« Cela nous prend plus de temps pour accomplir nos tâches, ce qui n'est pas idéal puisque la majorité de notre travail s'effectue en situation d'urgence », a déclaré un dirigeant du secteur public à Elastic. « Nous devons être en mesure d'obtenir des informations le plus rapidement possible. »
La montagne de données ne cesse de croître, et leur accès est limité. Alors, comment les organismes du secteur public peuvent-ils surmonter la complexité de ces silos centralisés ? Le maillage de données offre une autre façon d'organiser les données qui pourrait être la solution.
Qu'est-ce qu'un maillage de données ?
Pour faire simple, un maillage de données permet de surmonter les silos. Les données collectées sur l'ensemble du réseau peuvent être récupérées et analysées à n'importe quel point de l'écosystème, à condition que l'utilisateur dispose des autorisations nécessaires. Il fournit une couche unifiée mais distribuée qui simplifie et standardise les opérations sur les données.

Les 4 piliers du maillage de données
Le maillage des données repose sur quatre principes clés :
Propriété du domaine : comment les agences et les départements gèrent leurs propres données
Données en tant que produit : les propriétaires de domaines s'assurent que leurs ensembles de données sont de haute qualité et facilement accessibles.
Plateformes en libre-service : permet aux équipes internes et externes de trouver et d'utiliser des données de haute qualité sans contraintes informatiques.
Gouvernance fédérée : garantit que tout fonctionne correctement et en toute sécurité sur tous les systèmes
Passons-les en revue un par un.
Propriété du domaine
Au lieu de compter sur une équipe informatique centrale pour gérer toutes les données, la propriété des données est répartie entre les organismes et les services gouvernementaux. En substance, vous constituez des équipes techniques qui reflètent la composition de l'organisme lui-même. Vous voulez que les personnes qui connaissent le mieux ces données en soient propriétaires. Cela peut s'appliquer à la santé publique, à la défense, à l'urbanisme et à bien d'autres domaines, pratiquement tous les cas d'utilisation du secteur public.
Par exemple, l'agence américaine Cybersecurity and Infrastructure Security Agency (CISA) utilise une approche de maillage des données pour obtenir une visibilité sur les données de sécurité provenant de centaines d'agences fédérales, tout en permettant à chaque agence de conserver le contrôle de ses données.
Cela nous amène au deuxième pilier (et sans doute le plus important), celui que les trois autres piliers sont censés soutenir :
Les données en tant que produit
Chaque ensemble de données est traité comme un produit avec une documentation claire et des normes de qualité. Le service qui détient les données doit s'assurer qu'elles sont facilement accessibles et organisées pour les autres services qui en ont besoin. En d'autres termes, ils sont responsables du partage de ces données et doivent garantir leur exploitabilité.
Du point de vue d'un gouvernement, il peut s'agir, par exemple, d'informations issues d'un recensement, de données relatives aux interventions d'urgence ou de rapports de renseignement. Tout dépend de la structure du projet ou de l'organisme gouvernemental. L'important est que ces données organisées soient prêtes à être utilisées lorsque d'autres équipes en auront besoin, sans qu'elles aient à passer du temps à les nettoyer ou à les vérifier.
Vous vous demandez peut-être s'il ne s'agit pas simplement d'une autre façon de cloisonner les données analytiques ? Comment les autres services peuvent-ils y accéder concrètement ? Cela nous amène à notre pilier suivant.
Plateformes en libre-service
On en demande beaucoup aux départements, et ils auront besoin de plateformes pratiques qui rendent leurs données accessibles aux autres. Des catalogues consultables pour faciliter la découverte des données, des outils de requête pour des analyses en temps réel et la possibilité pour les utilisateurs de nettoyer et d'intégrer eux-mêmes les données, ainsi que de partager des informations via des tableaux de bord et des API sont autant d'outils qui peuvent être utilisés.
Ils auront également besoin d'une gouvernance intégrée pour appliquer des contrôles d'accès, ce qui nous amène à notre dernier pilier.
Gouvernance computationnelle fédérée
Nous avons donc établi que chaque département contrôle ses propres données. Cependant, le maillage des données nécessite toujours des protocoles de gouvernance globaux pour assurer leur sécurité et prévenir les risques.
Ces contrôles de sécurité doivent être intégrés au système qui récupère les données, plutôt que d’être appliqués séparément par chaque service. Le système doit vérifier les autorisations des utilisateurs dans le cadre de la recherche et s'assurer que ceux-ci ne voient que les données auxquelles ils sont autorisés à accéder dès le début.
Dans le secteur public, cela peut aller des réglementations sur la confidentialité des données de santé aux informations classifiées dans les systèmes de défense.
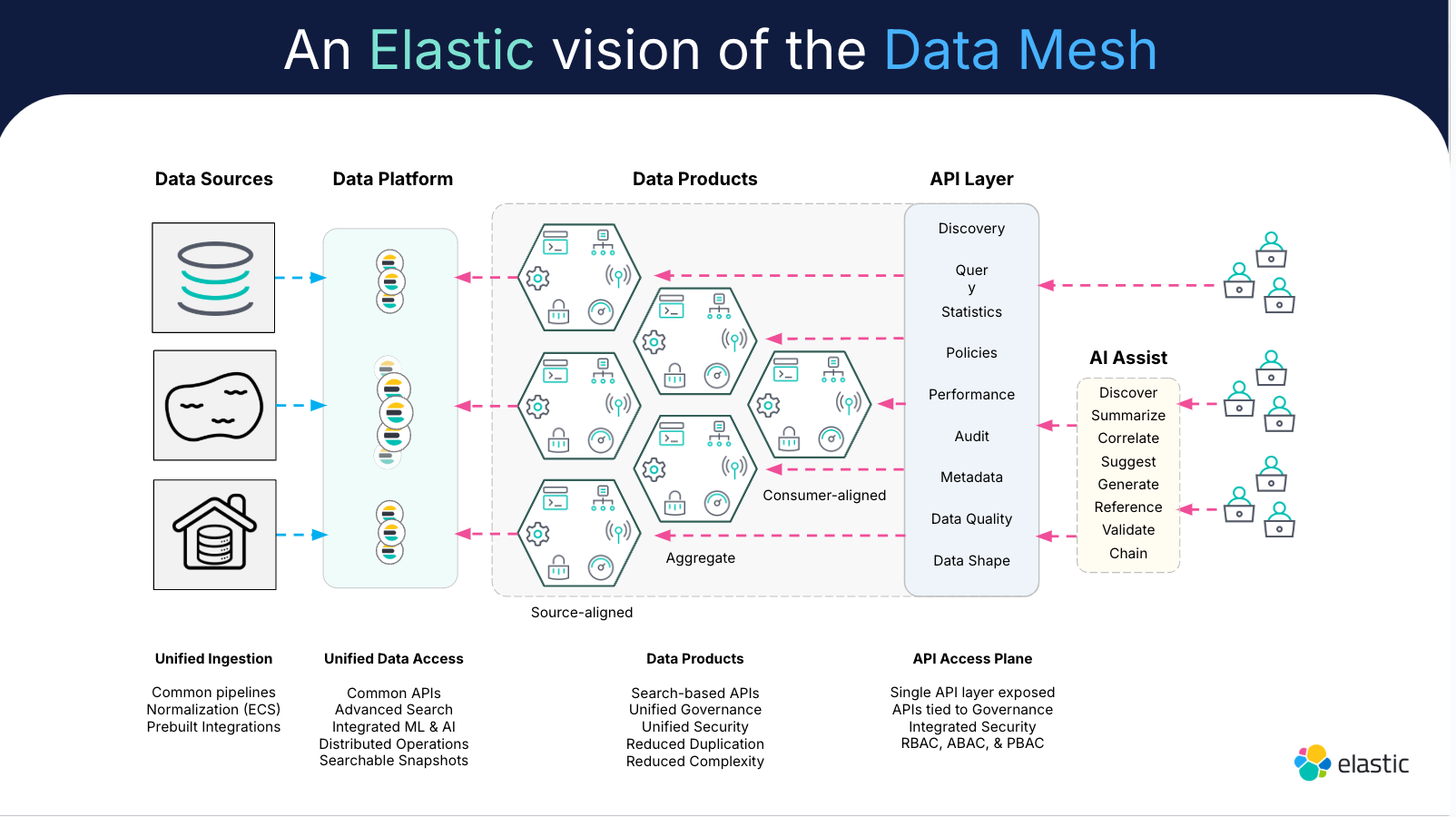
Architecture de maillage de données
Une architecture de maillage de données est un framework qui réunit les piliers du maillage de données au sein d'un processus de gestion des données distribuées.
L'implémentation d'une architecture de maillage de données réduit les obstacles dans le processus de collaboration. Grâce à son approche plus centrée sur l'utilisateur, elle change la donne pour les équipes qui travaillent avec des données spécifiques à un domaine pour l'entraînement de modèles et l'analytique.
Le maillage de données permet une gestion et une gouvernance des données plus efficaces à grande échelle, malgré la multiplicité des plateformes et des équipes d'implémentation. L'architecture de maillage de données crée plus d'autonomie et plus de démocratisation des données, si vous disposez d'une observabilité évolutive et en libre-service. L'observabilité permet aux équipes de gérer toutes ces données depuis une seule et même interface.
L'observabilité efficace des données est intégrée dans l'architecture d'un maillage de données. C'est ce qui permet aux équipes d'exploiter les informations dérivées de toutes les données qu'elles collectent. Voyez les choses de la manière suivante : l'observabilité des données consiste à contrôler l'intégrité des données, tandis que les architectures de maillage de données concernent leur gestion décentralisée. Et pour y parvenir, il faut être capable d'avoir une visibilité détaillée.
Maillage de données vs autres approches
Comment le maillage de données se distingue-t-il des autres formes d'architecture et de stockage analytiques ? Examinons deux autres concepts souvent comparés : la data fabric et les lacs de données.
Maillage de données vs data fabric
Le maillage de données et la data fabric sont des approches similaires dans le sens où elles sont toutes deux décentralisées et collectent des données sur des sites distants. Cependant, une data fabric prend des données collectées sur un site et les copie sur un autre. Ces données sont partagées sous forme d'enregistrements individuels et ne peuvent pas être corrélées avec d'autres enregistrements, à moins qu'elles ne soient exploitées par quelque chose qui leur donne un sens. Cette approche peut souvent conduire à des silos de données.
Une approche de maillage de données, en revanche, ne repose pas sur la copie des données mais les indexe localement lors de leur ingestion sur une plateforme distribuée où les utilisateurs peuvent rechercher des données localement et sur des sites distants. Dans ce modèle, les données sont unifiées au niveau de la plateforme de recherche. Les données sont indexées une fois et sont ensuite disponibles pour tout utilisateur autorisé ou cas d'utilisation via cette couche unifiée.
Maillage de données vs lac de données
Vous avez peut-être remarqué qu'il existe de nombreuses métaphores liées à l'eau dans le domaine des données : flux de données, pipelines de données, etc. Tout comme l'eau, les données peuvent être collectées, stockées, filtrées et distribuées, parfois de manière efficace, parfois de manière chaotique.
Tout comme un lac collecte l'eau provenant de multiples sources, un lac de données collecte les données et les conserve pour une utilisation future. En d'autres termes, il s'agit d'un environnement de stockage pour toute combinaison de données structurées, semi-structurées ou non structurées.
Les lacs de données peuvent parfois être utiles aux propriétaires de domaines de maillage de données lorsqu'ils traitent et organisent leurs produits de données. Ils peuvent utiliser un lac de données pour le stockage à long terme d'ensembles de données non structurées volumineux (par exemple, des images satellites ou des archives publiques) qui n'ont pas encore d'objectif spécifique. Mais si un lac de données devient désorganisé et difficile à exploiter, il se transforme en marécage de données, trouble, encombré et dont il est difficile d'extraire de la valeur.
Maillage de données et IA
Le maillage de données peut permettre de démocratiser l’IA et le Machine Learning pour les organismes du secteur public. Traditionnellement, les équipes de science des données fonctionnaient comme des hubs centralisés, extrayant des données de plusieurs sources pour développer des modèles de Machine Learning. Toutefois, comme nous l'avons vu précédemment, ce processus peut entraîner des tâches redondantes et des incohérences, ce qui entraîne des problèmes de reproductibilité des modèles.
En inversant ce modèle avec le maillage de données et en intégrant le développement de l’IA au sein des équipes de domaine, vous pouvez nettoyer et affiner les données à leur source et créer un produit de données basé sur l’IA que d’autres services peuvent utiliser.
Prenons l’exemple des interventions en cas de catastrophe nationale. Les modèles d’IA intégrés aux équipes d’intervention d’urgence analysent souvent des données telles que des images satellites en temps réel, des données de capteurs et même des rapports sur les réseaux sociaux pour identifier les zones les plus durement touchées. Grâce au maillage de données, différents organismes, allant des agences gouvernementales aux premiers intervenants, peuvent accéder immédiatement à ces informations sans attendre un traitement centralisé et améliorer ainsi leurs temps de réponse.
Le maillage de données améliore également la gouvernance de l’IA car il l’intègre dès le départ, en normalisant des tâches telles que la validation de modèle, la détection des biais, l’explicabilité et le suivi de la dérive du modèle.
Comment mettre en œuvre le maillage de données pour le secteur public
Chaque organisation du secteur public a des besoins spécifiques en matière de données. C'est pourquoi les silos de données uniformisés peuvent ralentir et entraver le travail des utilisateurs internes et externes. Deux dirigeants du secteur public sur trois se disent insatisfaits des informations dont ils disposent.
Le maillage de données peut être personnalisé en fonction des besoins propres à chaque organisme du secteur public, qu'il s'agisse de la défense, de la sécurité nationale ou des administrations fédérales, régionales ou locales.
Pour se lancer avec le maillage de données, les organismes publics devront suivre quelques étapes :
Attribuer la responsabilité des données à des services spécifiques.
Traiter les ensembles de données comme des actifs bien documentés et accessibles, conçus pour un usage interne et externe, et s'assurer qu'ils sont conformes aux exigences réglementaires.
Mettre en œuvre des outils qui permettent aux organismes, aux analystes et aux décideurs politiques d'accéder facilement aux données et de les analyser sans dépendre d'équipes informatiques centralisées.
Appliquer une gouvernance à l'échelle des administrations, en gardant à l'esprit des frameworks tels que FedRAMP, CMMC et Zero Trust.
Enfin, encourager le partage des données entre les différentes organisations afin de prendre de meilleures décisions et d'améliorer les services publics tout en maintenant les contrôles de sécurité.
Applications gouvernementales et de défense
Le maillage de données convient naturellement aux secteurs du gouvernement et de la défense, où de vastes ensembles de données distribuées doivent être accessibles et analysés en toute sécurité et en temps réel.
Dans le secteur de la défense, il permet d'accélérer la collecte de renseignements et la gestion des actifs afin de faciliter l'exploitation des données les plus récentes par les opérateurs sur le terrain. Dans le secteur de la santé publique, il peut aider à intégrer rapidement les données épidémiologiques provenant des hôpitaux ou des laboratoires de recherche afin de faire face aux épidémies. Les services des transports peuvent analyser les données relatives à la circulation et à la météo dans les villes. Les services de l'éducation peuvent consulter les résultats des enfants aux examens au cours des dix dernières années et les croiser avec d'autres données, telles que le temps consacré à l'apprentissage à distance par rapport à l'apprentissage en présentiel.
Prenons cet exemple de la marine américaine : sa modernisation numérique repose sur sa capacité à « transférer en toute sécurité n'importe quelle information, de n'importe où vers n'importe où ailleurs » afin d'asseoir sa supériorité en matière d'informations. Mais le stockage centralisé traditionnel des données est trop risqué, en particulier dans les environnements isolés et DDIL (Denied, Degraded, Intermittent, Limited). Voici un scénario dans lequel un maillage de données mondial peut être utile, en permettant aux données de rester à leur source tout en restant consultables et accessibles dans le vaste environnement opérationnel de la marine. Cette approche décentralisée garantit la résilience des opérations même en cas de panne d'un serveur ou d'un datacenter, et offre une vue unifiée des données critiques sans avoir à les déplacer ou à les dupliquer.
Maillage de données en action avec Elastic
En tant que Search IA Company, la plateforme d'analyse de données d'Elastic sert de puissant maillage global de données, offrant le Machine Learning, le traitement du langage naturel, la recherche sémantique, l'alerte et la visualisation dans un système unifié. En d'autres termes, Elastic remplit une fonction unificatrice en donnant aux agences une visibilité totale sur leurs données ainsi que la possibilité de les ingérer, de les organiser, d'y accéder et de les analyser.
Trois fonctionnalités clés distinguent Elastic :
La recherche inter-clusters (CCS), qui vous permet d'exécuter une seule requête sur un ou plusieurs clusters distants.
Les instantanés interrogeables, qui vous permettent d'accéder à des données historiques peu utilisées et de les interroger de manière rentable
Le contrôle d'accès basé sur les rôles, qui assure une sécurité intégrée
L'approche du maillage de données d'Elastic peut également servir de base aux frameworks de sécurité modernes tels que le Zero Trust et ouvre de nouvelles possibilités pour les opérations basées sur les données.
Découvrez comment Elastic aide les équipes gouvernementales, de santé et d'éducation à maximiser la valeur des données avec rapidité, évolutivité et pertinence.
Découvrez d'autres ressources sur le maillage des données dans le secteur public
- Utiliser Elastic comme maillage de données mondial : unifier l'accès aux données grâce à la sécurité, à la gouvernance et aux politiques
- Accélérer les missions de défense grâce à un maillage de données mondial
- La CISA accélère la mise en œuvre du Zero Trust avec Elastic en tant que couche de données unifiée
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'IA générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer