Elastic 7.12 veröffentlicht: allgemeine Verfügbarkeit von Schema-on-Read, Technical Preview der Tier für „eingefrorene“ Daten und Unterstützung der automatischen Skalierung
Wir freuen uns, die allgemeine Verfügbarkeit von Elastic 7.12 bekanntgeben zu dürfen. Diese Version ergänzt unsere auf dem Elastic Stack basierenden Elastic Enterprise Search-, Observability- und Security-Lösungen – Elasticsearch und Kibana – um etliche neue Funktionen. Die neue Version gibt Kunden mit „Schema-on-Read“ die Wahl zwischen maximaler Flexibilität und Geschwindigkeit, macht mit der Tier für „eingefrorene“ Daten Objektspeicher voll durchsuchbar und ermöglicht automatisches Skalieren von Deployments auf Elastic Cloud.
Elastic Enterprise Search profitiert von einer Reihe von Architekturoptimierungen, die für geringere Deployment-Größen, schnelleres Indexieren und relevantere Ergebnisse sorgen. Neu in Elastic Observability sind Korrelationen, die dabei helfen, die wichtigsten Treiber für Probleme mit der Anwendungsleistung und Fehler zu identifizieren. Die analystengesteuerte Korrelation rationalisiert SecOps-Workflows in Elastic Security.
Elastic 7.12 ist ab sofort in der Elastic Cloud verfügbar, dem einzigen gehosteten Elasticsearch-Angebot, das alle Funktionen und Merkmale der neuen Version enthält. Wenn Sie Ihre Lösungen selbst verwalten möchten, können Sie auch den Elastic Stack und unsere Produkte für die Cloud-Orchestrierung (Elastic Cloud Enterprise und Elastic Cloud auf Kubernetes) herunterladen.
Im Folgenden finden Sie eine Übersicht über die Highlights der neuen Version. Eine vollständige Beschreibung der Features können Sie den verschiedenen Blogposts zu den einzelnen Lösungen und Produkten entnehmen.
Elastic Stack und Elastic Cloud
Schema-on-Read, ein Feature, mit dem Analysten zusätzliche Flexibilität bei der Erkundung von Daten erhalten, ist jetzt allgemein verfügbar.
Die Bekanntheit von Elasticsearch als rasend schnelle verteilte Suchmaschine und Analytics Engine basiert in Teilen auf der standardmäßigen Verwendung des Schema-on-Write-Ansatzes. Für diese organisierte Datenstruktur muss zwar vorab geplant und getestet werden, wie die Daten in Elasticsearch dargestellt werden, dieser Extraaufwand wird aber mit einer hohen Geschwindigkeit belohnt.
Was passiert, wenn neue Daten ingestiert werden müssen oder es gilt, einen neuen Anwendungsfall zu berücksichtigen, der kurze Durchsatzzeiten erfordert? Was wäre, wenn Sie mit „Schema-on-Read“ die Möglichkeit hätten, schon zum Zeitpunkt der Abfrage ad hoc ein Schema zu erstellen? Mit den in der neuen Version zum ersten Mal allgemein verfügbaren Laufzeitfeldern erhalten Sie die Flexibilität, nicht nur mit Schema-on-Write, sondern auch mit Schema-on-Read zu arbeiten. Auf diese Weise profitieren Sie von einer deutlich kürzeren Time-to-Value für Ihre Daten – mit dem Haken, dass dies auf Kosten der Suchgeschwindigkeit geht. Ab Version 7.12 sind Laufzeitfelder in Kibana Discover durchsuchbar, sodass Analysten mit Schema-on-Read strukturierte Daten in Elasticsearch flexibel erkunden können.
Unsere Schema-on-Read-Implementierung ist ganz speziell. Bei den Elasticsearch-Laufzeitfeldern müssen Sie sich nicht zwischen der Geschwindigkeit und Skalierbarkeit von Schema-on-Write und der Flexibilität von Schema-on-Read entscheiden. Sie können einfach beides gleichzeitig verwenden – auf demselben Elastic Stack und mit denselben Daten. Erkunden Sie neue Daten und definieren Sie ad hoc neue Felder, während im Hintergrund weiterhin Ihre Suche auf Basis der Felder in den bereits bekannten Daten läuft. Sie können dabei jederzeit einfach und schnell zwischen den neu erstellten Feldern, die in Laufzeitfeldern definiert werden, und Schema-on-Write für eine höhere Suchgeschwindigkeit wechseln. Ganz gleich, für welchen Ansatz Sie sich entscheiden: Sie erhalten unvergleichliche Flexibilität mit der Geschwindigkeit und Skalierbarkeit, die Sie von Elasticsearch erwarten.
Dass dank der neuen Tier für „eingefrorene“ Daten („Technical Preview“) Objektspeicher wie S3 vollständig durchsucht werden können, eröffnet neue Wertschöpfungsoptionen – demnächst auch mit vereinfachtem Nutzungserlebnis in Elastic Cloud.
Mit der neuen Tier für „eingefrorene“ Daten („Technical Preview“) können Sie Rechenressourcen von Speicherressourcen trennen und Objektspeicher, wie Amazon S3, Google Cloud Storage und Microsoft Azure Storage, direkt durchsuchen. Dies ermöglicht ein Durchsuchen von Daten zu einem Bruchteil der bisherigen Kosten, Sie müssen im Gegenzug aber mit weniger für die Suche reservierten Ressourcen und damit mit einer geringeren Geschwindigkeit auskommen. Dadurch, dass nur diejenigen Daten aus dem Objektspeicher herangeholt und lokal zwischengespeichert werden, die für die Ausführung der Abfrage erforderlich sind, bietet die Tier für „eingefrorene“ Daten das beste Sucherlebnis und gleichzeitig die Flexibilität, unbegrenzt viele Daten zu speichern. Demnächst werden wir auch bessere Benutzeroberflächenfunktionen für das Konfigurieren der Tier für „eingefrorene“ Daten in Elastic Cloud anbieten können.
Durchsuchbare Snapshots stellen eine kostengünstige Möglichkeit dar, die Gesamtheit Ihrer Anwendungsinhalte und historischen Arbeitsplatzdatensätze durchsuchbar zu machen. So können mehr Analytics-Daten für Marketing-Analysen gespeichert oder auch versionierte Anwendungskataloge für neue Bereitstellungsstrategien getestet und veröffentlicht werden. Für Observability-Zwecke brauchen Sie nicht mehr zu entscheiden, welche Log-, Metrik- oder APM-Daten aus finanziellen Gründen gelöscht werden müssen. So können Sie ohne aufwendige Wiederherstellung der Daten aus dem Backup die Anwendungsperformance über viele Jahre hinweg zurückverfolgen Mit durchsuchbaren Snapshots können Sie Ihren Threat-Huntern und Security-Analysten einfachen Zugang zu großen Mengen von Security-Daten aus vielen Jahren verschaffen. Das ermöglicht die großangelegte Erfassung zusätzlicher sicherheitsrelevanter Daten, wie IDS-, NetFlow-, DNS-, PCAP- oder Endpoint-Daten, und deren Bereitstellung über einen längeren Zeitraum.
Mit der neuen Funktion zur Durchführung von Suchen im Hintergrund können Sie weiter Daten analysieren, während länger dauernde Suchen im Hintergrund weiterlaufen.
Zu den Kernversprechen der Elastic-Technologie gehört es, dass Sie selbst in riesigen Datenmengen die sprichwörtliche Nadel im Heuhaufen finden. Auch wenn die Ergebnisse in Daten aus einem „eingefrorenen“ Index stammen, der mehrere Cluster überspannt, hört der Elastic Stack nicht auf, Dokumente für Sie zu durchkämmen, bis es nichts mehr zu durchkämmen gibt. Das heißt aber nicht, dass Sie deshalb unterbrechen müssen, womit Sie sich gerade beschäftigen. Ab Version 7.12 können Sie festlegen, dass länger dauernde Suchen in Discover oder einem Kibana-Dashboard im Hintergrund ablaufen sollen, während Sie weiter Ihren Aufgaben nachgehen. Mit der neuen Funktion zur Suchsitzungsverwaltung können Sie jederzeit nachschauen, ob bereits Ergebnisse vorliegen – ob nach 5 Minuten, nach 5 Stunden oder auch nach 5 Tagen. Überlassen Sie dem Elastic Stack das Multitasking, damit Sie sich weiter auf Ihre Arbeit konzentrieren können.
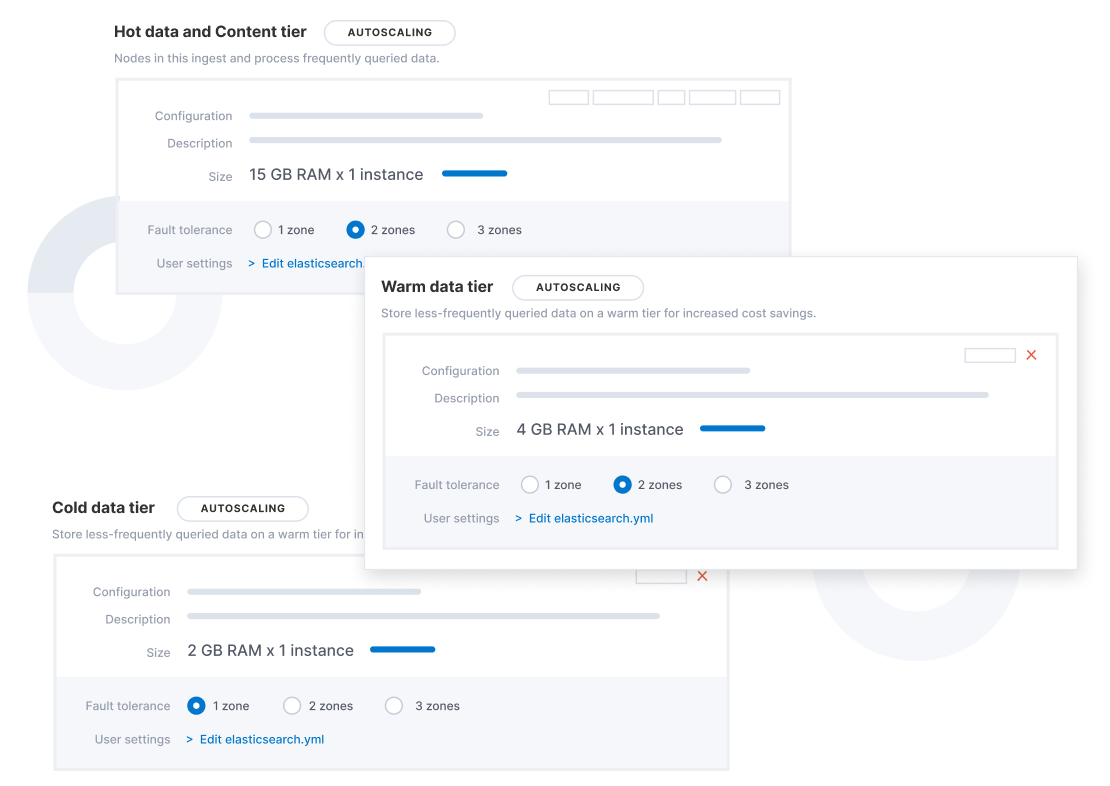
Sie können festlegen, dass Elastic Cloud automatisch die Speichernutzung und die ML-Funktion überwacht, Ressourcen anpasst und mittels automatischer Skalierung die Performance regelt, damit Sie sich auf Ihr Alltagsgeschäft konzentrieren können.
Für Elastic Cloud und Elastic Cloud Enterprise 2.9 steht jetzt die Funktion zur automatischen Skalierung („Autoscaling“) zur Verfügung. Sie überwacht sowohl die Speichernutzung für Ihre Elasticsearch-Datenknoten als auch die verfügbare Kapazität für Ihre Machine-Learning-Jobs und passt automatisch die Ressourcenkapazität an, um die Knotenperformance aufrechtzuerhalten.
Die automatische Skalierung kann über die API, die Befehlszeile oder die Elastic Cloud-Konsole aktiviert werden. Wenn Ihre Elasticsearch-Datenknoten an ihre Kapazitätsgrenzen kommen, wird die Kapazität automatisch erweitert. Die Arbeitsspeicher- und CPU-Kapazität Ihres Machine-Learning-Knotens wächst oder schrumpft je nach den Ressourcenanforderungen Ihrer Machine-Learning-Jobs. Konfigurierbare Obergrenzen verhindern ein unkontrolliertes Anschwellen des Clusters.
Dank automatischer Skalierung können Sie mit den dynamischen Observability-Anforderungen Schritt halten. Dazu wird die Instrumentierung auf alle Anwendungen erweitert und optimiert, ohne dass Sie von vornherein für ein Zuviel an Kapazität zahlen müssen. Damit erfüllen wir einen langgehegten Wunsch vieler Mitglieder der Elastic Observability-Community. In Elastic Enterprise Search kann die automatische Skalierung genutzt werden, um bei der Gewinnung von Einblicken in die Suchplattform unnötige Ressourcenkosten zu sparen – wenn es die Größe der Log- und Analytics-Daten sowie der Inhalte erfordert, werden die Kapazitäten einfach entsprechend angepasst. In Elastic Security können Sie großangelegte Threat-Hunting-Aktionen starten und es dann der automatischen Skalierung überlassen, die Arbeitsspeicherressourcen für Ihre Machine-Learning-Knoten zu überwachen und aufzustocken, während sie anhand Ihrer Security-Ereignis-Informationen nach Anomalien suchen.
Durch die Unterstützung neuer Instanztypen in Elastic Cloud profitieren Sie von mehr Flexibilität und einem besseren Preis-Leistungs-Verhältnis.
In den Microsoft Azure-Regionen London und Tokio können Ls-Series-Instanzen genutzt werden. E/A-optimierte Ls-Series-Instanzen bieten einen hohen Durchsatz und eine geringe Latenz. Im Vergleich zu den bisherigen E‑Series-Instanzen lassen sich Kosteneinsparungen von mehr als 55 % erzielen. Für Ihre Deployments bedeutet dies eine bessere Performance und geringere Kosten.
In den AWS-Regionen Irland, Virginia, Ohio und Oregon können D3-Instanzen genutzt werden. D3-Instanzen bieten eine hohe Speicherkapazität für dichte Speicherlasten und liefern im Vergleich zu D2-Instanzen mehr Leistung bei geringeren Kosten. Da der Elastic Stack jetzt ARM unterstützt, arbeiten wir daran, in naher Zukunft auch ARM-basierte EC2-Instanzen unterstützen zu können. Diese Instanzen bieten deutliche Kosteneinsparungen und eignen sich perfekt für Deployments mit verteilten Datenspeichern.
Weitere Informationen zu diesen Funktionen und mehr finden Sie im Blogpost zu Kibana 7.12, im Blogpost zu Elasticsearch 7.12 und im Blogpost zu Elastic Cloud 7.12.
Elastic-Lösungen
Elastic Enterprise Search
Eine neue Datenarchitektur in Enterprise Search ermöglicht geringere Deployment-Größen, schnelleres Indexieren und relevantere Ergebnisse.
Elastic hat schon vor Jahren als einer der Ersten auf ein ressourcenbasiertes Preismodell für Suche-Anwendungsfälle umgestellt und damit eine vorhersehbare, transparente und faire Herangehensweise für die Bereitstellung von Suchfunktionen für Anforderungen aller Art eingeführt. Diese Prinzipien sind es auch, die das Enterprise Search-Team dazu bewegen, seine Forschungsaktivitäten und sein Fachwissen für die kontinuierliche Suche nach Wegen zur Optimierung der Ressourcennutzung, des Kapazitätsmanagements und der Relevanz einzusetzen und in komplexe Modellierungsentscheidungen zu investieren, damit Sie es nicht tun müssen. So kommen Sie in den Genuss eines vorjustierten und einsatzbereiten Bereitstellungserlebnisses.
Mit der Version 7.12 bietet Elastic Enterprise Search eine komplett überarbeitete Datenarchitektur, die sich durch eine größere Speichereffizienz, eine bessere Suchperformance und eine höhere Relevanz auszeichnet. Die neue Architektur optimiert das zugrundeliegende Indexmanagement mit dem Ziel, Datenduplikation zu vermeiden, und stellt eine neue Mapping-Konfiguration bereit, die für eine höhere Suchgenauigkeit sorgt, ohne dass dies zulasten der in modernen Suchfunktionen unabdingbaren Schreibfehlertoleranz führt. Kunden können eine bis zu 70 % höhere Speichereffizienz, eine um bis zu 40 % geringere Indexierungslatenz und signifikante Verbesserungen bei der Relevanz in App Search und Workplace Search erwarten.
Einen Überblick über alle neuen Funktionen in Elastic Enterprise Search erhalten Sie im Blogpost zu Elastic Enterprise Search 7.12.
Elastic Observability
Mit einer neuen Korrelationsfunktion in Elastic APM lassen sich Muster in langsamen Anwendungstransaktionen finden und die Ursachenanalyse beschleunigen.
Elastic APM führt eine neue Funktion ein, die Anwendungstransaktionen mit hohen Latenzen und Fehlern analysiert und automatisch Faktoren wie Serviceversion und Infrastruktur-Metadaten zutage fördert, bei denen eine enge Korrelation mit den unterdurchschnittlich performenden Transaktionen festzustellen ist. Das ermöglicht es Nutzern, sich im Rahmen von reaktiven Troubleshooting-Workflows schnell an die Ursache der schlechten Performance heranzutasten und so die mittlere Zeit bis zur Problemlösung zu verkürzen. Außerdem stärkt die Funktion den proaktiven Workflow, indem sie Anwendungseigentümern dabei hilft, verbesserungswürdige Bereiche aufzuspüren und kontinuierlich das Nutzungserlebnis zu verbessern.
So könnte die Korrelationsfunktion beispielsweise herausfinden, dass eine bestimmte Serviceversion eng mit einer langsamen Performance zusammenhängt oder dass ein bestimmter Kunde bei der Zahl der fehlerbehafteten Transaktionen überrepräsentiert ist. Diese Erkenntnisse lassen sich dann nutzen, um Probleme weiter einzugrenzen und so die Untersuchung voranbringen.
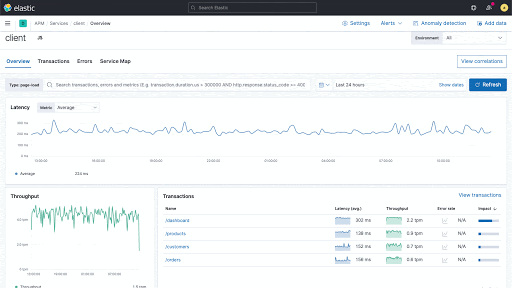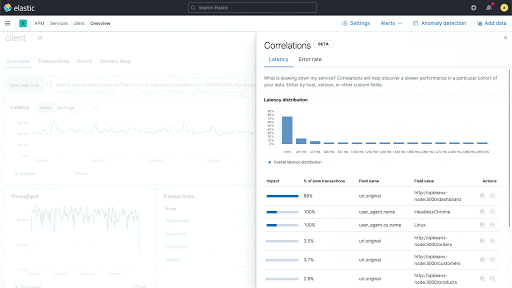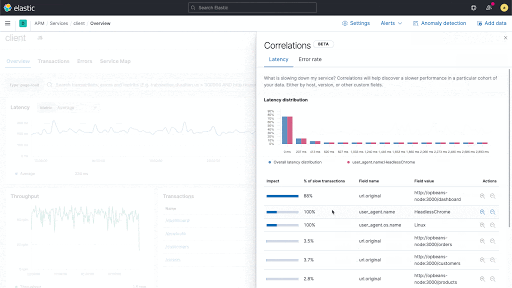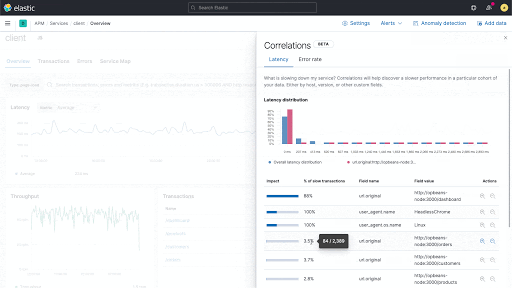
Neue Korrelationen in Elastic APM
Aufbauend auf der bestehenden Elastic-Aggregation für wichtige Begriffe („significant_terms“) vergleicht die neue Korrelationsfunktion („Correlation“) die Tags für Transaktionen mit hoher Latenz und Fehlern mit dem kompletten Transaktionssatz und identifiziert automatisch Metadaten, die in suboptimalen Transaktionen ungewöhnlich häufig auftreten.
Ausführliche Informationen zu allen neuen Features finden Sie im Blogpost zu Elastic Observability 7.12.
Elastic Security
Die analystengestützte Korrelation mithilfe von EQL beschleunigt Threat-Hunting- und Untersuchungsaktivitäten.
Die in Elastic Security 7.12 erstmalig verfügbare analystengesteuerte Korrelation („Analyst-driven Correlation“) ist ein hilfreiches Tool für Datenpraktiker, deren Aufgabe es ist, aus Daten Informationen und Erkenntnisse zu gewinnen. Sie ermöglicht es Analysten, Bedrohungen schneller zu erkennen und zu untersuchen, indem sie die Beziehungen zwischen Schlüsseldaten aufdeckt, statt die Analysten unter einer Flut von kontextlosen Datenpunkten zu begraben. So können sie bei ihren Hunting- und Untersuchungsaktivitäten gezielter vorgehen und profitieren dabei von zuverlässigeren Erkennungen auf der Basis der Ergebnisse der Analystenarbeit bei diesen Untersuchungen.
Bei der analystengesteuerten Korrelation kommt mit EQL (Event Query Language) die Technologie zum Einsatz, die auch hinter der Korrelation in der Elastic Security-Erkennungs-Engine steckt. Auf diese Weise können Datenpraktiker direkt das Potenzial der Korrelation nutzen. Das rationalisiert die SecOps-Workflows und hilft, Angriffsfortschritte aufzudecken und die sequenzbasierte Analyse über sämtliche Daten hinweg so einfach wie eine gewöhnliche Suche zu gestalten – alles von dem für das Threat-Hunting und die Untersuchung von Bedrohungen vorgesehenen Bereich in Elastic Security aus.
In der Vergangenheit wurden alle Versuche, das Threat-Hunting und die Untersuchung zu beschleunigen, durch lange Reaktionszeiten ausgebremst. Mit Elastic Security haben Datenpraktiker jetzt die Möglichkeit, Datenschätze mit der von Elasticsearch bekannten Geschwindigkeit zu heben. Und da es nun auch möglich ist, Korrelationen auf die verschiedensten Bestände historischer Daten anzuwenden, können Analysten innerhalb weniger Minuten Schlüsselerkenntnisse über Angriffe gewinnen, selbst wenn diese besonders geduldig und ausgefeilt sind. Security-Teams profitieren von mehreren Erkennungs- und Untersuchungsmethoden für eine breite Palette von Security-Anwendungsfällen. Die Kombination aus EQL-basierten Korrelationen und ML-basierten Erkennungsalgorithmen, Erkennungsregeln, die mit Indikatorabgleich funktionieren, und Drittanbieterkontext auf Cloud-Ebene schafft die Grundlagen für eine umfassendere Security-Strategie.
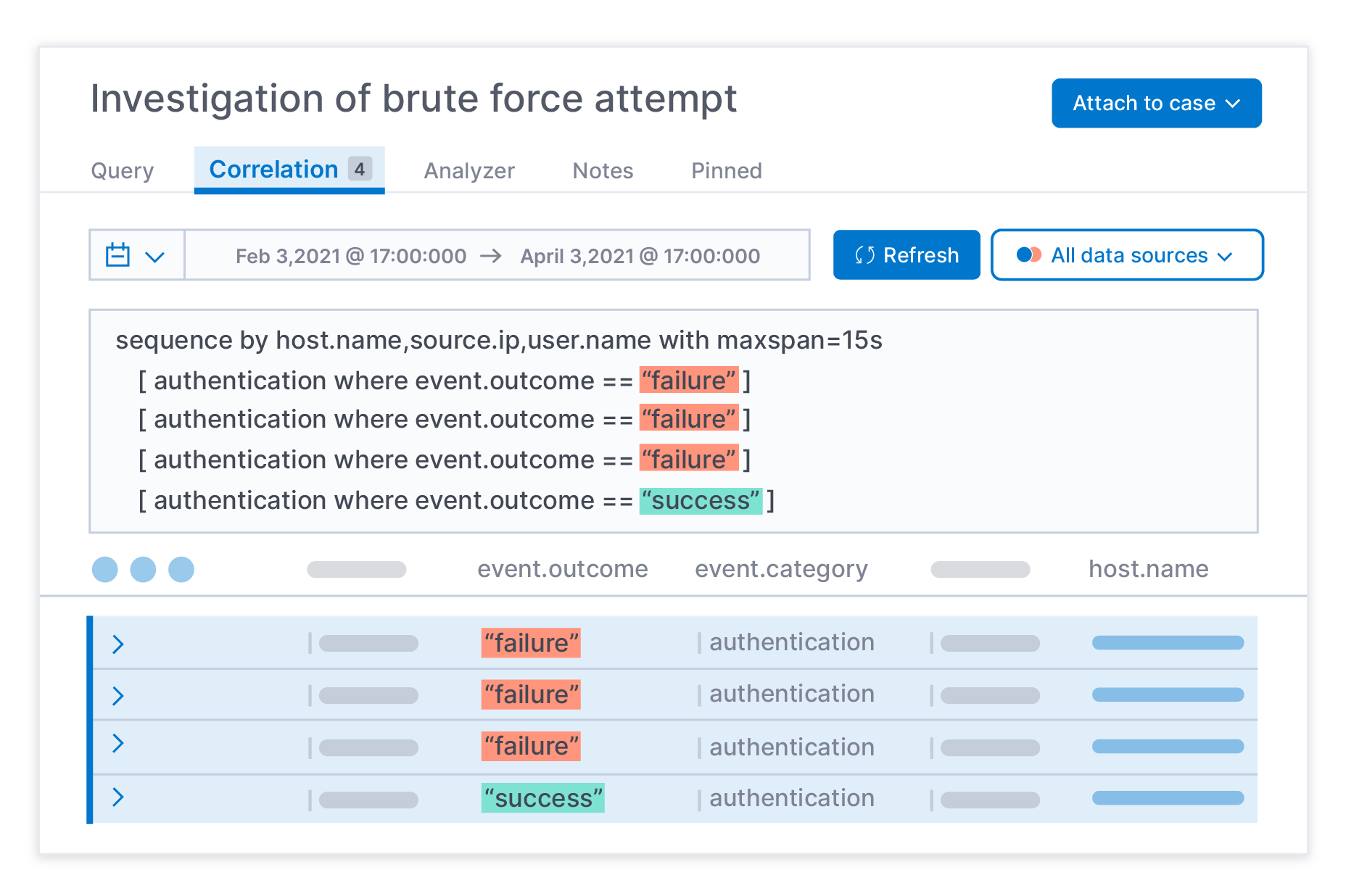
Analystengesteuerte Korrelationen in Elastic Security.
Elastic Agent bietet jetzt die Möglichkeit, Ransomware mit Verhaltensanalyse Einhalt zu gebieten.
Ransomware-Angriffe sind nach wie vor profitabel und die dafür verwendeten Verfahren entwickeln sich schnell weiter. Die gute Nachricht: Wie andere Malware-Arten auch, kann Ransomware an verschiedenen Punkten der Angriffskette gestoppt werden. Das Stichwort lautet dabei „Defense-in-depth“, also in der Tiefe gestaffelte Verteidigung.
Elastic Security 7.12 bietet eine neue Ebene der Ransomware-Vorbeugung: Verhaltensanalyse mit dem Elastic Agent als Ergänzung zum signaturlosen Malware-Schutz, der in Version 7.9 eingeführt wurde. Der verhaltensorientierte Schutz vor Ransomware in Elastic Agent erkennt und stoppt Ransomware-Angriffe auf Windows-Systeme, indem er Daten aus Low-Level-Systemprozessen analysiert. Er ist bei einer ganzen Reihe von verbreiteten Ransomware-Familien effektiv, einschließlich derer, die auf den Master Boot Record des Systems abzielen.
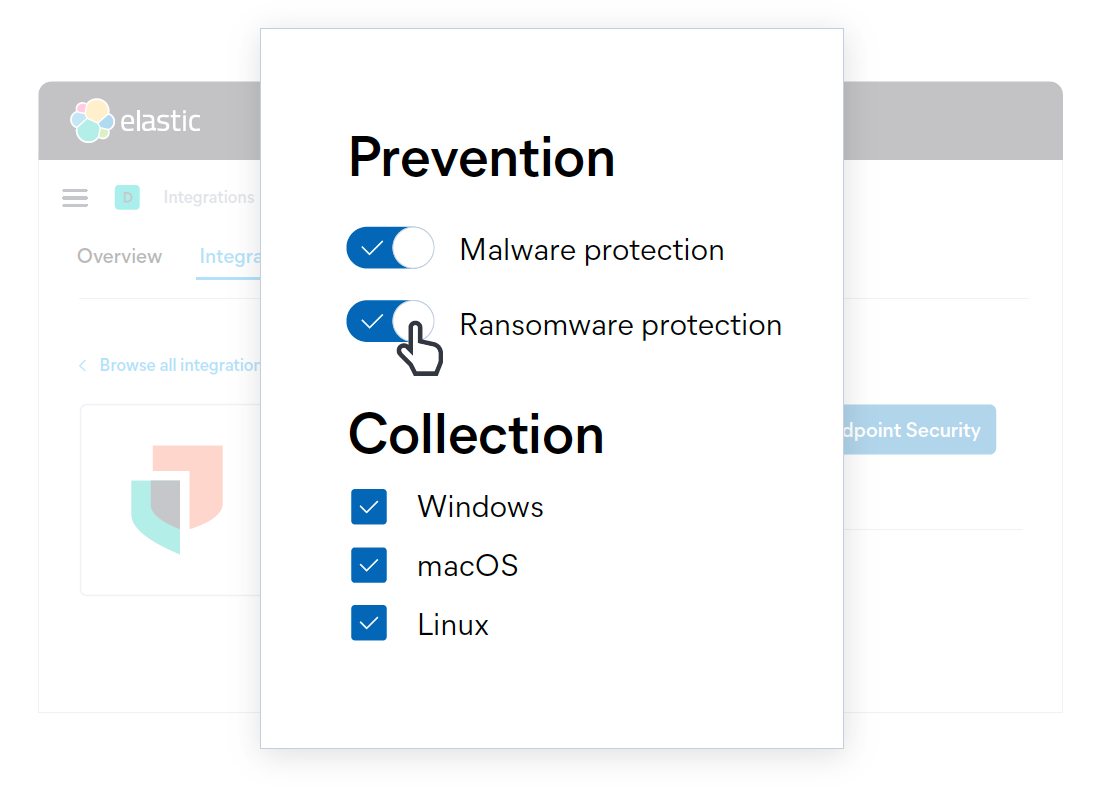
Erweiterter Ransomware-Schutz in Elastic Agent.
Weitere Details finden Sie im Blogpost zu Elastic Security 7.12.
Wie immer gibt es noch viel mehr zu berichten –
viel, viel mehr! Nähere Informationen zu allen Neuerungen in Version 7.12 finden Sie in den Blogposts zu den einzelnen Lösungen und Produkten:
Elastic Stack
Elasticsearch 7.12 veröffentlicht
Elastic Cloud
Neuigkeiten in Elastic Cloud für 7.12
Elastic-Lösungen
Elastic Enterprise Search 7.12 veröffentlicht
Elastic Observability 7.12 veröffentlicht
Elastic Security 7.12 veröffentlicht
Probieren Sie Elastic Cloud kostenlos aus.
Die Entscheidung über die Veröffentlichung der in diesem Dokument beschriebenen Leistungsmerkmale und Funktionen oder deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Leistungsmerkmale oder Funktionen nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.