Was gibts Neues in Elastic Observability 7.12? APM-Korrelationen und native OpenTelemetry-Unterstützung
Version 7.12 von Elastic Observability ist da! Die neue Version ermöglicht dank Korrelationen in Elastic APM eine schnellere Ursachenanalyse und bietet ARM-Unterstützung in Beats und Agent für die einfache Überwachung von Geräten mit geringem Energieverbrauch, native OpenTelemetry-Unterstützung – jetzt auch für Traces und Metriken – für das einfachere Ingestieren von Architekturen sowie automatisches Skalieren in Elastic Cloud und durchsuchbare Snapshots in der Tier für „eingefrorene“ Daten zur Reduzierung Ihrer TCO. Und es gibt noch viel mehr, auf das Sie sich in 7.12 freuen können.
Die neueste Version von Elastic Observability steht ab sofort auf dem offiziellen Elasticsearch Service auf Elastic Cloud zur Verfügung (kostenlose 14-tägige Probeversion ist verfügbar). Oder Sie installieren die neueste Version des Elastic Stack, um sie selbst zu verwalten und viele dieser Features in der kostenlosen und offenen Daten-Tier zu nutzen.
Genug der einleitenden Worte – lassen Sie uns mit der Vorstellung einiger der Highlights beginnen.
Automatisches Aufspüren der Hauptschuldigen für langsame Anwendungen und Fehler mit Korrelationen in APM
Elastic APM führt mit der Korrelationsfunktion eine neue Funktion ein, die Anwendungstransaktionen mit hohen Latenzen oder Fehlern analysiert und automatisch Faktoren wie Serviceversion, Infrastruktur-Metadaten und so weiter zutage fördert, bei denen ein enger Zusammenhang mit den unterdurchschnittlich performenden Transaktionen festzustellen ist. Das ermöglicht es Nutzern, sich im Rahmen von reaktiven Troubleshooting-Workflows schnell an die Ursache der schlechten Performance heranzutasten und so die mittlere Zeit bis zur Problemlösung zu verkürzen. Außerdem unterstützt die Funktion proaktive Workflows, indem sie Anwendungseigentümern dabei hilft, verbesserungswürdige Bereiche aufzuspüren und so kontinuierlich das Nutzungserlebnis zu verbessern.
Es könnte sich beispielsweise zeigen, dass eine bestimmte Dienstversion eng mit niedriger Performance korreliert oder dass ein bestimmter Kunde bei den fehlerbehafteten Transaktionen überrepräsentiert ist. Diese Erkenntnisse werden in der APM-UI herausgestellt und helfen Engineers, die nächsten Analyseschritte einzukreisen.
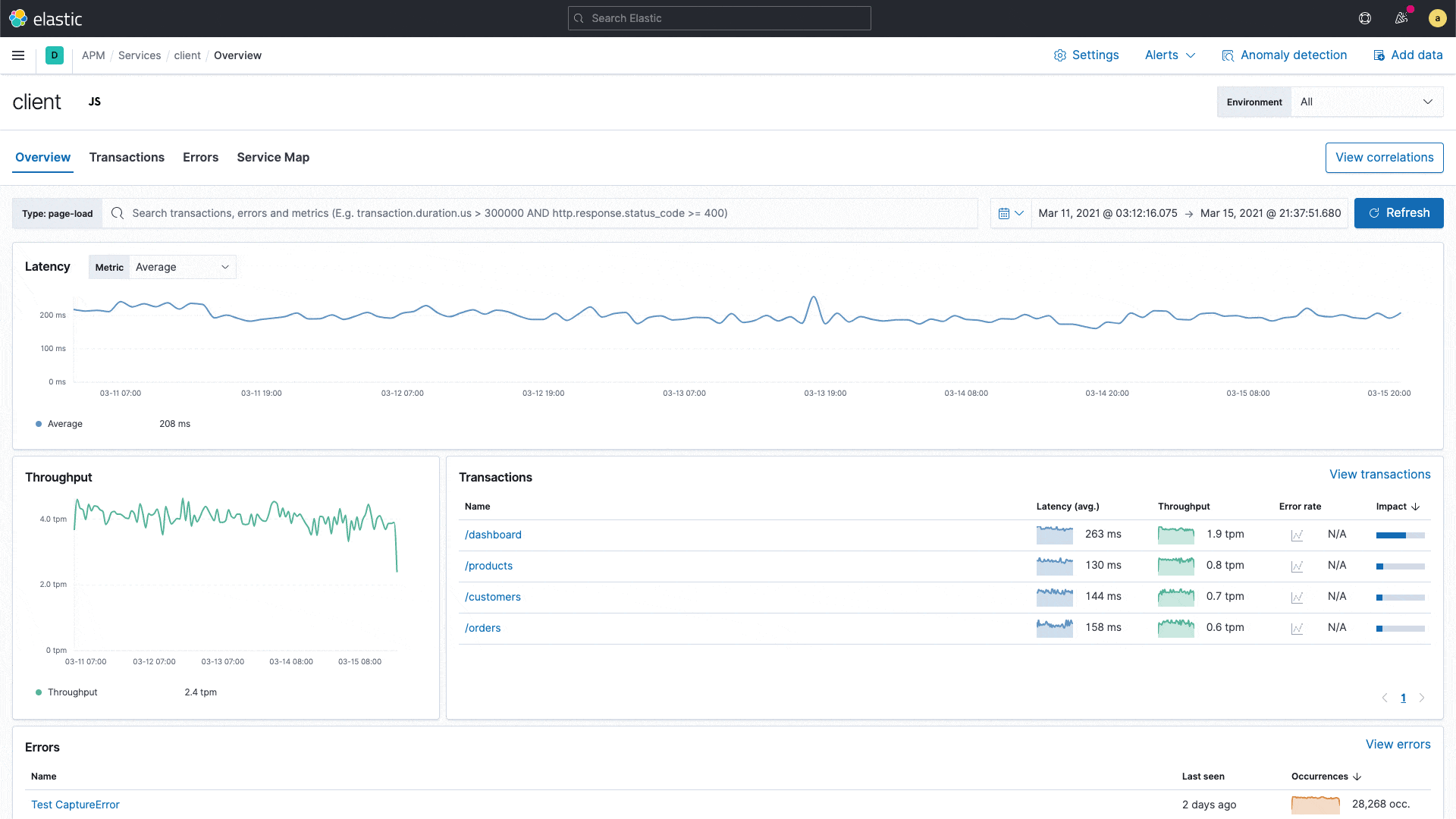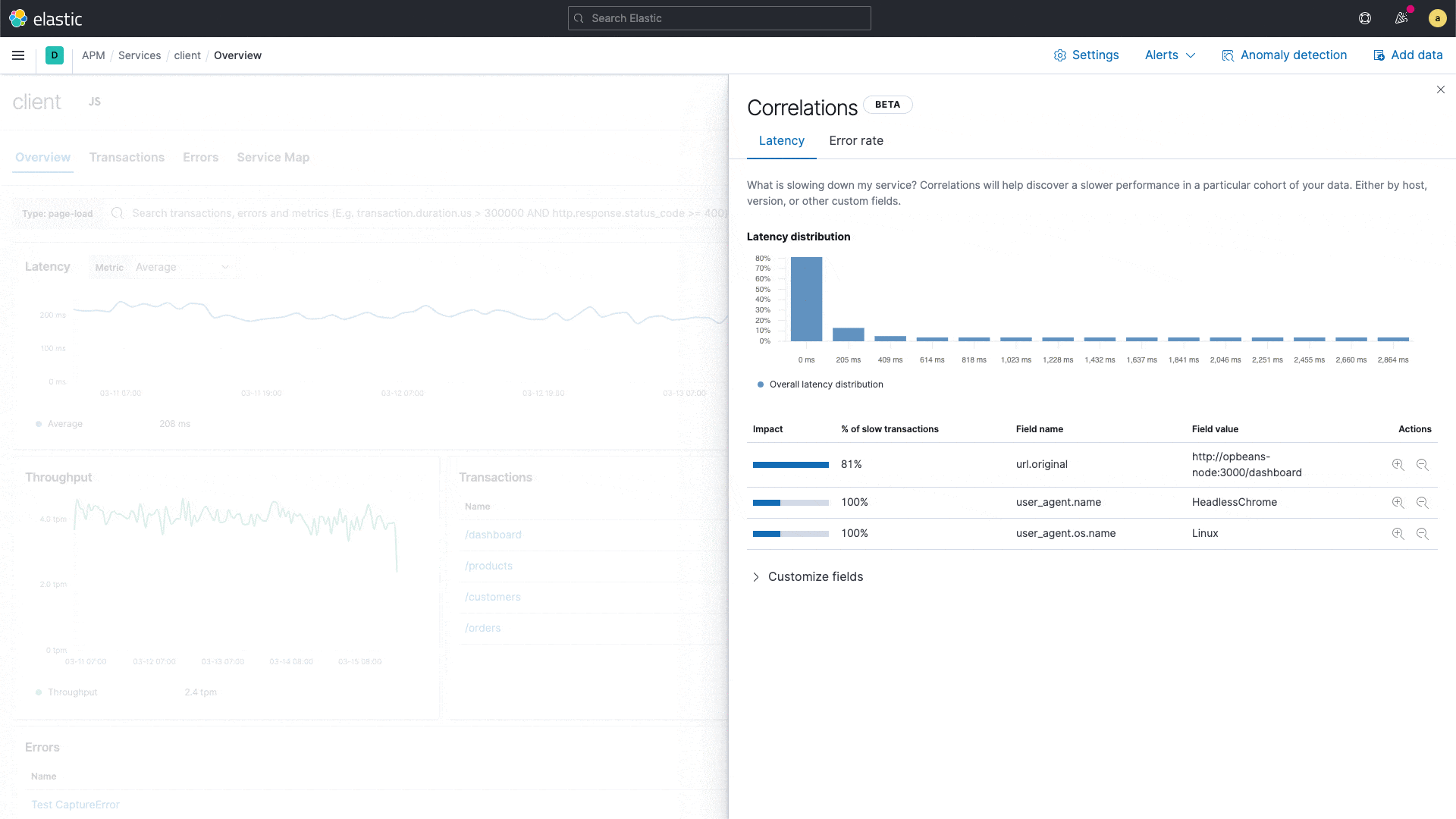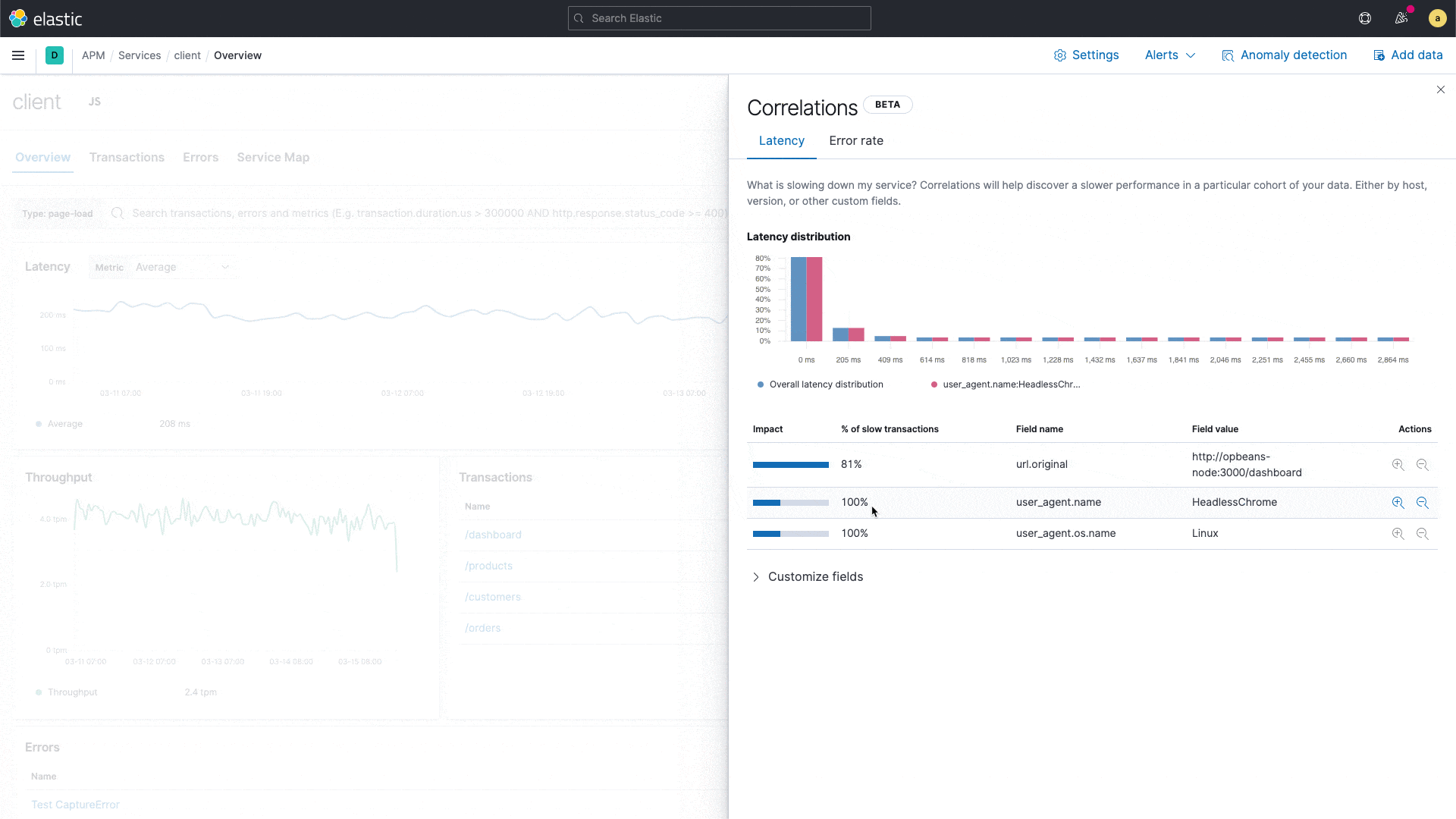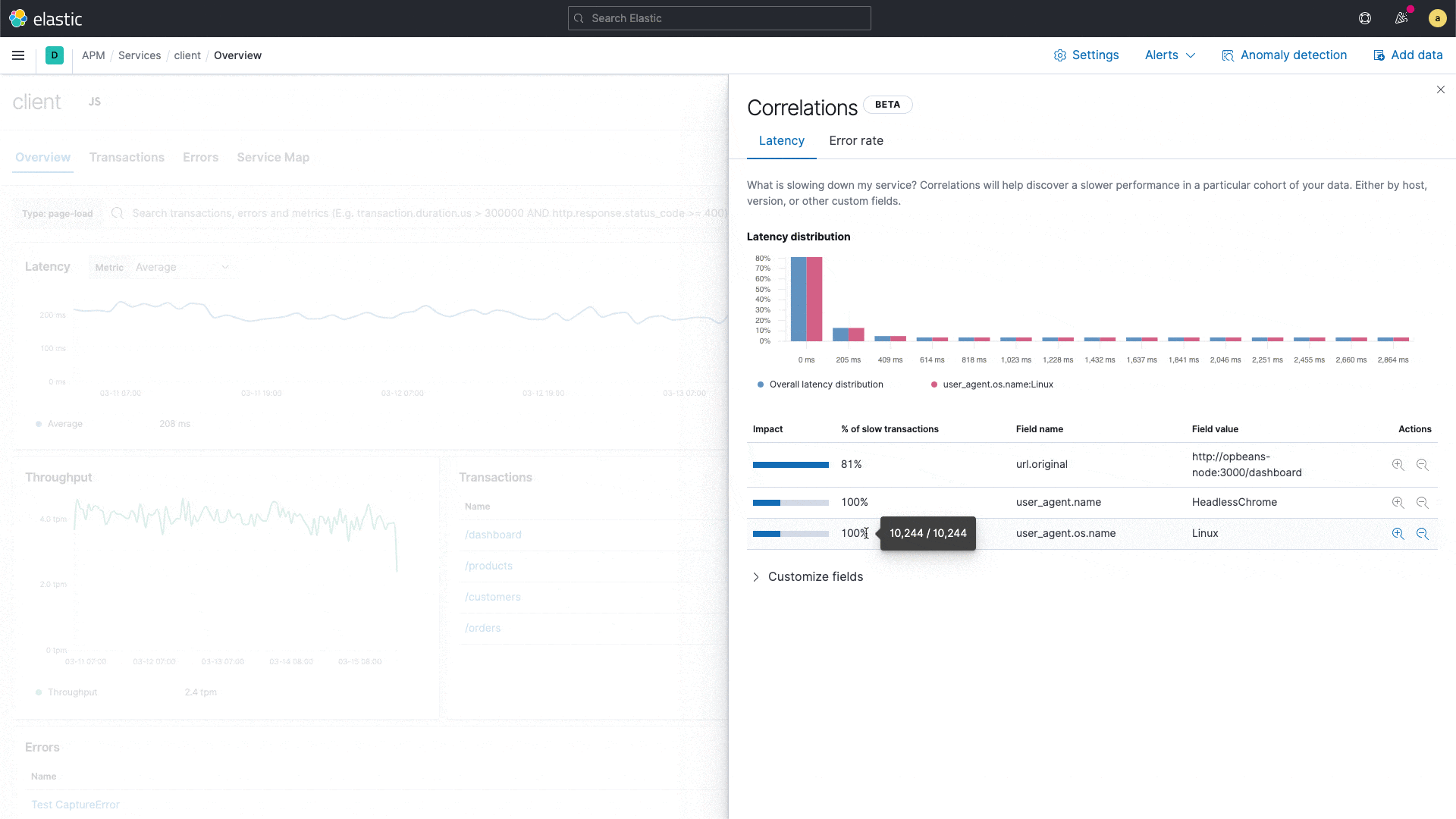
Die APM-Korrelationsfunktion, die auf der Aggregation wichtiger Begriffe in Elasticsearch aufbaut, vergleicht die Tags der Transaktionen, die hohe Latenzen und Fehler aufweisen, mit dem Transaktionssatz insgesamt und identifiziert automatisch diejenigen Tags und Metadaten, die in den suboptimalen Transaktionen ungewöhnlich häufig vorkommen – also die Elemente, die bei den suboptimalen Transaktionen deutlich häufiger auftreten als im vollständigen Transaktionssatz. Der Standardschwellenwert für langsam ist das 75. Perzentil. Dieser Wert kann aber geändert werden. Tags, die beim Analysieren berücksichtigt werden, sind bei Back-end-Diensten benutzerdefinierte Labels, Infrastruktur und Dienstversion und bei Front-end-Diensten benutzerdefinierte Labels, Betriebssystem und Clienttyp.
Mehr dazu und zu anderen APM-Updates finden Sie in der Dokumentation.
Automatisches Skalieren in Elastic Cloud für die dynamische Anpassung an den aktuellen Bedarf
Viele Elastic-Kunden, z.B. Audi, nutzen zum Ausführen und Verwalten ihrer Elastic-Deployments Elastic Cloud, weil es durch Features wie 1-Klick-Upgrades, Deployment-Vorlagen und mehr die Abläufe deutlich vereinfacht. Wir freuen uns, die Einführung der Funktion für automatisches Skalieren („Autoscaling“) auf Elastic Cloud bekanntgeben zu können – so wird die Nutzung von Elastic Cloud für Unternehmen noch attraktiver. Das automatische Skalieren gehörte zu den meistgewünschten Features der Observability-Community, bietet sie doch die Möglichkeit, auf einfache Weise mit dynamischen Bedarfen Schritt zu halten, ohne dabei zu viel bezahlen zu müssen, um maximale Kapazität zu haben.

Das Skalieren von Clustern nach oben und unten war bei Elastic Cloud immer schon einfach: Es genügt, einen Schieberegler zu verschieben oder einen API-Aufruf zu starten. Mit automatischem Skalieren wird das nun noch einfacher. Sobald Sie „Autoscaling“ aktivieren (durch Klicken auf ein Kontrollkästchen in der Benutzeroberfläche oder durch einen API-/CLI-Aufruf), skaliert Elastic Cloud die Kapazität automatisch, um sich dynamisch dem aktuellen Bedarf auf dem Cluster anzupassen. Und um unliebsame Überraschungen zu vermeiden, können die Nutzer auch Obergrenzen festlegen.
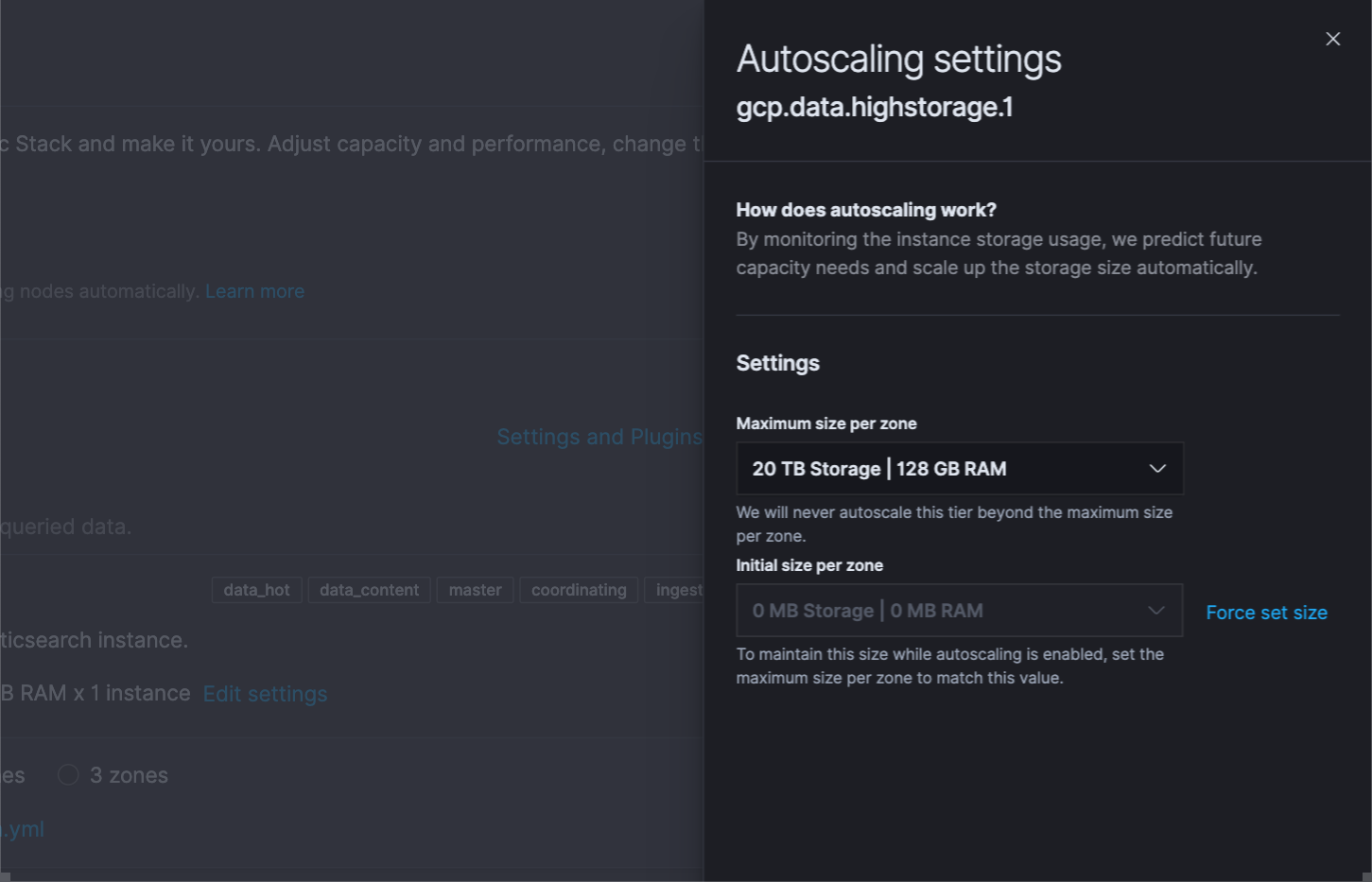
Das automatische Skalieren ist derzeit für Datenspeicherungs- und Machine-Learning-Knoten verfügbar, es ist aber geplant, die Funktion zukünftig auf weitere Knotentypen zu erweitern.
Mehr zu diesen Updates finden Sie in unserem Blogpost zu den Neuerungen in Elastic 7.12.
Überwachen ARM-basierter Infrastrukturen mit ARM-Unterstützung in Beats und Agent
ARM-Architekturen sind aufgrund ihrer Energieeffizienz und Portabilität seit Langem die dominierende Kraft im Markt der Mobil- und IoT-Geräte. In den letzten Jahren hat ARM auch im serverseitigen Cloud-Computing immer mehr Boden gutgemacht. AWS hat mehrere ARM-basierte EC2-Instanzen eingeführt und es sieht so aus, als wären auch Microsoft und Google Cloud auf dem Sprung, diesem Trend zu folgen.
Getreu unserer Philosophie „dort zu sein, wo unsere Nutzer sind“, freuen wir uns, die Einführung der Unterstützung für ARM-basierte Architekturen im gesamten Elastic Stack, also auch in Beats und dem Elastic Agent, bekanntgeben zu können. Kunden, auf deren Servern oder Geräten ARM läuft, können jetzt für das Endpoint-Monitoring mit Beats oder dem Elastic Agent Daten zum Zustand und zur Performance erfassen. Viele Nutzer stehen noch ganz am Anfang des ARM-basierten Computings und arbeiten in hybriden Umgebungen. Diese Nutzer können jetzt ihre ARM-Infrastruktur zusammen mit der übrigen Infrastruktur in einem zusammengeführten Stack überwachen.
Und noch ein Hinweis speziell für die IoT-Community, die den Elastic Stack als flexible und skalierbare Plattform für das Edge-Monitoring schätzt: Diese Nutzer können jetzt Beats und Agent an der Peripherie ausführen, was ihre Ingestieren-Architekturen noch weiter vereinfacht.
Native OpenTelemetry-Unterstützung
OpenTelemetry entwickelt sich zur standardisierten Schicht für die Erfassung von Observability-Daten und soll Unternehmen dazu befähigen, ihre Anwendungen offen und anbieterneutral zu instrumentieren. Wir freuen uns daher, die Einführung der nativen Unterstützung für OpenTelemetry in Elastic Observability bekanntgeben zu können. So können Unternehmen Daten, die von OpenTelemetry-Agents erfasst wurden, direkt an ihre Elastic-Deployments senden. Dadurch verringert sich nicht nur der Aufwand, den Nutzer betreiben müssen, um OpenTelemetry an ihre vorhandene Elastic-Architektur anzupassen, sondern vereinfacht auch die Architektur.
Wir sind stolz darauf, dass wir damit bei der Unterstützung für OpenTelemetry einen Schritt vorangekommen sind. Im Juli 2020 hatten wir mit dem OpenTelemetry-Collector-Exporter für Elastic eine Übersetzungsschicht zwischen OpenTelemetry-Agents und Elastic APM veröffentlicht. Mit der Ergänzung der nativen Unterstützung (in 7.12. als experimentelles Feature ausgewiesen) entfällt die Notwendigkeit, diese zusätzliche Komponente zu installieren und zu verwalten, und Nutzer können nun direkt Daten aus ihren OpenTelemetry-Agents an den Elastic APM-Server senden.
Die native OpenTelemetry-Unterstützung ist derzeit für Elastic Observability in selbst verwalteten Standalone-Deployments verfügbar, wird aber bald auch auf Elastic Cloud und ECE verfügbar sein.
Und das ist noch nicht alles!
Die Tier für „eingefrorene“ Daten (jetzt als „Technical Preview“ verfügbar) ermöglicht es Nutzern, auch Daten direkt zu durchsuchen, die auf preisgünstigen Objektspeichern wie Amazon S3, Google Cloud Storage und Microsoft Azure Storage gespeichert sind. Das bedeutet für Sie: Sie können Logdaten von vor vielen Jahren durchsuchen, ohne sie aus einem Archiv rehydrieren zu müssen!
Und um das Nutzungserlebnis beim Durchführen solcher länger dauernden Aufgaben in Kibana zu verbessern, bieten wir die Möglichkeit, die Suche im Hintergrund zu speichern. Sie können also jetzt solche Abfragen an den Hintergrund senden und Kibana für andere Analysen und Erkundungen nutzen, während die Suche läuft.
Mehr zu diesen Möglichkeiten und anderen Highlights des Elastic Stack finden Sie im Blogpost zur Ankündigung von Elastic 7.12.
Die Entscheidung über die Veröffentlichung der in diesem Dokument beschriebenen Leistungsmerkmale und Funktionen oder deren Zeitpunkt liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Leistungsmerkmale oder Funktionen nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.