Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Elasticsearch has been used by developers to build search experiences for over a decade. At Microsoft Build this year, we announced the launch of Elasticsearch Relevance Engine — a set of tools to enable developers to build AI-powered search applications. With generative AI, large language models (LLMs), and vector search capabilities gaining mindshare, we are delighted to expand our range of tools and enable our customers in building the next generation of search apps.
One example of what a next-generation search experience might look like comes from Relativity — the eDiscovery and legal search technology company. At Build, we shared the stage with the Relativity team as they spoke about how they’re using Elasticsearch and Microsoft Azure. You can read about Relativity’s coverage of Build on their blog.
This blog explores how Relativity leverages Elasticsearch and Azure OpenAI to build futuristic search experiences. It also examines the key components of an AI-powered search experience and the important architectural considerations to keep in mind.
About Relativity
Relativity is the company behind RelativityOne, a leading cloud-based eDiscovery software solution. Relativity partners with Microsoft to innovate and deliver its solutions to hundreds of organizations, helping them manage, search, and act on large amounts of heterogeneous data. RelativityOne is respected in the industry for its global reach, and it is powered by Microsoft Azure infrastructure and a host of other Microsoft Azure services, such as Cognitive Services Translator.
The RelativityOne product is built with scale in mind. Typical use cases involve ingesting large amounts of data provided for legal eDiscovery. This data is presented to legal teams via a search interface. In order to enable high-quality legal investigations, it is critical for the search experience to return highly accurate and relevant results, every time. Elasticsearch fits these requirements and is a key underlying technology.
eDiscovery's future with generative AI

Brittany Roush, senior product manager at Relativity, says, “The biggest challenge Relativity customers are facing right now is data explosion from heterogeneous data sources. The challenge is really compounded by the differences in data generated from different modes of communication.” This explosion of data, sources, and complexity renders traditional keyword search approaches ineffective. With Elasticsearch Relevance Engine (ESRE), Relativity sees the potential of providing a search experience that goes beyond keyword search and basic conceptual search. ESRE provides an opportunity to natively tailor searches to case data. Relativity wants to augment the search experience with AI capabilities such as GPT-4, Signals, Classifications, and its in-house AI solutions.
In this talk at Microsoft Build, Roush shared that in Relativity’s future vision for search, there are a few key challenges. As data grows exponentially, and as investigators must search through documents, images, and video records, traditional keyword search approaches can reach their limits. Privacy and confidentiality are key factors in the legal discovery process. Additionally, the ability to search as if you’re having a natural conversation and leveraging LLMs are all important factors when the team imagines the future of search.
Elasticsearch for the future of AI search experiences
In making the vision for the future of eDiscover search real, Relativity relies on Elasticsearch for its proven track record at scale, the ability to manage structured and unstructured data sources, and its leadership in search and hybrid scoring. ESRE provides an opportunity to natively tailor searches to case data.
With Elasticsearch Relevance Engine, developers get a full vector database, the ability to manage multiple machine learning models or Elastic’s Learned Sparse Encoder that comes included with ESRE, and a plethora of data ingestion capabilities. Roush adds, “With ESRE and Azure OpenAI-powered search experiences, we aim to reduce what may take our customers months during an investigation to hours.”
Components of an AI-powered search experience

Natural language processing (NLP) NLP offers the ability to interact with a search interface using human language, or spoken intent. The search engine must identify intent and match it to data records. An example is matching “side hustle” to mean a secondary work occupation.
Vector database This is a database that stores data as numerical representations, or vectors embeddings, across a vector space that may span several dimensions. Each dimension may be a mathematical representation of features or attributes used to describe search documents.
Vector search A vector space is a mathematical representation of search documents as numbers. Traditional search relies on placement of keywords, frequency, and lexical similarity. A vector search engine uses numerical distances between vectors to represent similarity.
Model flexibility and LLM integration In this fast-evolving space, support for public and proprietary machine learning models and the ability to switch models enables customers to keep up with innovation.
Architectural considerations for an AI-powered search experience
In order to build a search experience that understands natural language search prompts, stores underlying data as vectors, and leverages a large language model to present context-relevant responses, an approach such as the one below may be used:
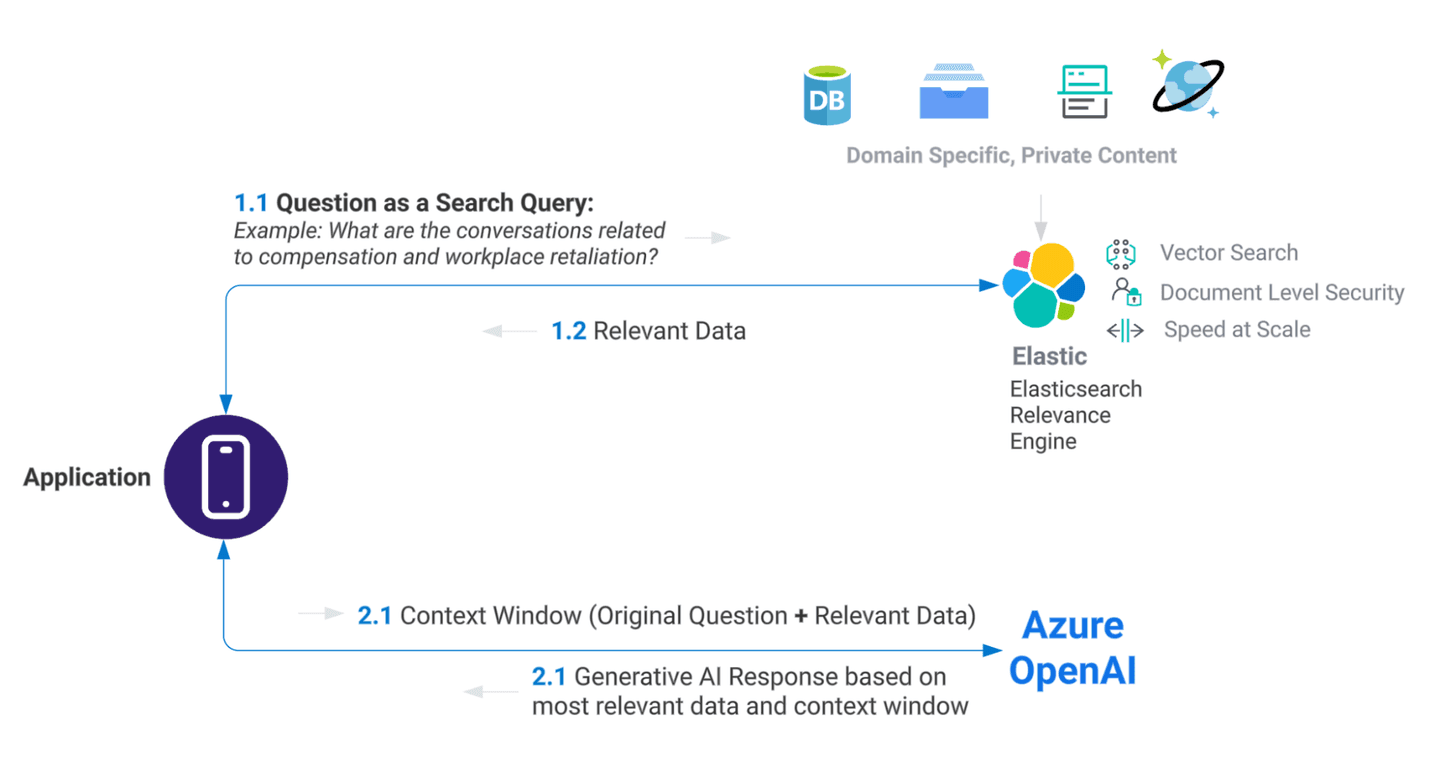
In order to achieve goals, for example building next-generation eDiscovery search leveraging LLM like OpenAI, users should consider the following factors:
Cost
LLMs can require large-scale resources and are trained on public data sets. Elasticsearch helps customers bring their private data and integrate with LLMs by passing a context window to keep the costs in check.
Scale and flexibility
Elasticsearch is a proven data store and vector database at petabyte scale. AI search experiences are powered by the data. The ability to ingest from a variety of private data sources is table stakes for the platform powering the solution. Elasticsearch as a datastore has been optimized over the years to host numerous data types, including the ability to store vectors. We cover Elastic’s ingestion capabilities in this recent webinar.
Most AI-powered search experiences will benefit from having the flexibility of retrieval: keyword search, vector search, and the ability to deliver hybrid ranking. Elastic 8.8 introduced Elastic Learned Sparse Encoder in technical preview. This is a semantic search model trained and optimized by Elastic for superior relevance out of the box. Our model provides superior performance for vector and hybrid search approaches, and some of the work is documented in this blog. Elastic also supports a wide variety of third-party NLP transformer models to enable you to add NLP models that you may have trained for your use cases.
Privacy and security
Elasticsearch can help users limit access to domain-specific data by sharing only relevant context with LLM services. Combine this with Microsoft’s enterprise focus on data, privacy, and security of the Azure OpenAPI service, and users like Relativity can roll out search experiences leveraging generative AI built on proprietary data.
For the private data hosted in Elasticsearch, applying Role Based Access Control will help protect sensitive data by configuring roles and corresponding access levels. Elasticsearch offers security options such as Document Level and Field Level security, which can restrict access based on domain-specific data sensitivity requirements.
Elasticsearch Service is built with a security-first mindset and is independently audited and certified to meet industry compliance standards such as PCI DSS, SOC2, and HIPAA to name a few.
Industry-specific considerations: Compliance, air-gapped, private clouds
Elastic can go where our users are, whether that is on public cloud, private cloud, on-prem, and in air-gapped environments. For a privacy-first LLM experience, users can deploy proprietary transformer models to air-gapped environments.
What will you build with Elastic and generative AI?
We’re excited about the experiences that customers such as Relativity are building. The past few years in search have been very exciting, but with the rapid adoption of generative AI capabilities, we can’t wait to see what developers create with Elastic’s tools. If you’d like to try some of the capabilities that were mentioned here, we recommend these resources:
- Demo video: State of the Art Data Retrieval with Machine Learning & Elasticsearch
- Blog: How to deploy NLP: Text Embeddings and Vector Search
- Announcing Elasticsearch Relevance Engine: AI search tools for developers Sign up for an Elastic Cloud trial and get started today!
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Frequently Asked Questions
What are the key components of an AI-powered search experience?
The building blocks of an AI-powered search experience are: natural language processing (NLP), vector database, vector search, and model flexibility with large language models integration.
Which considerations should you keep in mind when building an AI-search experience?
Users should consider the following factors when building an AI-search experience: cost, scale & flexibility, privacy and security. Also, keep in mind your industry-specific considerations (compliance, air-gapped, private clouds).
Related Content

March 13, 2026
Entity resolution with Elasticsearch, part 4: The ultimate challenge
Solving and evaluating entity resolution challenges in a highly diverse “ultimate challenge” dataset designed to prevent shortcuts.

March 4, 2026
Entity resolution with Elasticsearch, part 3: Optimizing LLM integration with function calling
Learn how function calling enhances LLM integration, enabling a reliable and cost-efficient entity resolution pipeline in Elasticsearch.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.
February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.