Este é o primeiro artigo de uma série que aborda como usar o Elasticsearch com JavaScript. Nesta série, você aprenderá o básico de como usar o Elasticsearch em um ambiente JavaScript e revisará os recursos mais relevantes e as melhores práticas para criar um aplicativo de busca. Ao final, você saberá tudo o que precisa para executar o Elasticsearch usando JavaScript.
Nesta primeira parte, vamos analisar:
Você pode conferir o código-fonte com os exemplos aqui.
O que é o cliente Elasticsearch para Node.js?
O cliente Elasticsearch para Node.js é uma biblioteca JavaScript que converte as chamadas HTTP REST da API do Elasticsearch em código JavaScript. Isso facilita o manuseio e permite o uso de ferramentas auxiliares que simplificam tarefas como a indexação de documentos em lotes.
Ambiente
Frontend, backend ou serverless?
Para criar nosso aplicativo de busca usando o cliente JavaScript, precisamos de pelo menos dois componentes: um cluster Elasticsearch e um ambiente de execução JavaScript para executar o cliente.
O cliente JavaScript é compatível com todas as soluções Elasticsearch (Cloud, on-premise e Serverless), e não há grandes diferenças entre elas, já que o cliente lida com todas as variações internamente, então você não precisa se preocupar com qual usar.
O ambiente de execução JavaScript, no entanto, deve ser executado a partir do servidor e não diretamente do navegador.
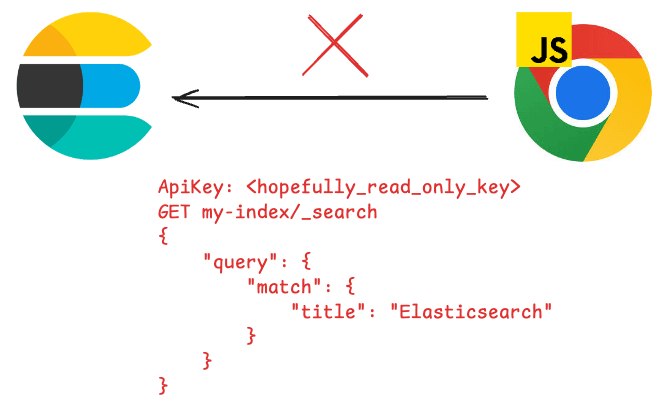
Isso ocorre porque, ao acessar o Elasticsearch pelo navegador, o usuário pode obter informações confidenciais, como a chave da API do cluster, o host ou a própria consulta. A Elasticsearch recomenda nunca expor o cluster diretamente à internet e usar uma camada intermediária que abstraia todas essas informações, de forma que o usuário possa ver apenas os parâmetros. Você pode ler mais sobre este tópico aqui.
Sugerimos usar um esquema como este:

Nesse caso, o cliente envia apenas os termos de pesquisa e uma chave de autenticação para o seu servidor, enquanto o seu servidor mantém o controle total da consulta e da comunicação com o Elasticsearch.
Conectando o cliente
Comece criando uma chave de API seguindo estes passos.
Seguindo o exemplo anterior, criaremos um servidor Express simples e nos conectaremos a ele usando um cliente de um servidor Node.js.
Vamos inicializar o projeto com o NPM e instalar o cliente Elasticsearch e o Express. Esta última é uma biblioteca para iniciar servidores em Node.js. Usando o Express, podemos interagir com nosso backend via HTTP.
Vamos inicializar o projeto:
npm init -y
Instalar dependências:
npm install @elastic/elasticsearch express split2 dotenv
Deixe-me explicar melhor:
- @elastic/elasticsearch: É o cliente oficial do Node.js.
- Express: Isso nos permitirá criar um servidor Node.js leve para expor o Elasticsearch.
- split2: Divide linhas de texto em um fluxo. Útil para processar nossos arquivos ndjson linha por linha.
- dotenv: Permite gerenciar variáveis de ambiente usando um arquivo .env. arquivo
Crie um arquivo .env Abra o arquivo na raiz do projeto e adicione as seguintes linhas:
Dessa forma, podemos importar essas variáveis usando o pacote dotenv .
Crie um arquivo server.js :
Este código configura um servidor Express.js básico que escuta na porta 3000 e se conecta a um cluster Elasticsearch usando uma chave de API para autenticação. Inclui um endpoint /ping que, quando acessado por meio de uma solicitação GET, consulta o cluster Elasticsearch para obter informações básicas usando o método .info() do cliente Elasticsearch.
Se a consulta for bem-sucedida, ela retorna as informações do cluster em formato JSON; caso contrário, retorna uma mensagem de erro. O servidor também utiliza o middleware body-parser para lidar com os corpos das requisições JSON.
Execute o arquivo para iniciar o servidor:
node server.js
A resposta deve ser semelhante a esta:
E agora, vamos consultar o endpoint /ping para verificar o status do nosso cluster Elasticsearch.
Documentos de indexação
Uma vez conectados, podemos indexar documentos usando mapeamentos como semantic_text para pesquisa semântica e text para consultas de texto completo. Com esses dois tipos de campo, também podemos fazer buscas híbridas.
Criaremos um novo arquivo load.js para gerar os mapeamentos e carregar os documentos.
Cliente Elasticsearch
Primeiro precisamos instanciar e autenticar o cliente:
Mapeamentos semânticos
Criaremos um índice com dados sobre um hospital veterinário. Armazenaremos as informações do dono, do animal de estimação e os detalhes da visita.
Os dados nos quais desejamos realizar uma busca de texto completo, como nomes e descrições, serão armazenados como texto. Os dados das categorias, como a espécie ou raça do animal, serão armazenados como palavras-chave.
Além disso, copiaremos os valores de todos os campos para um campo semantic_text para podermos executar também uma pesquisa semântica nessas informações.
Auxiliar em massa
Outra vantagem do cliente é que podemos usar a função auxiliar de indexação em lotes. A função auxiliar de processamento em lote nos permite lidar facilmente com aspectos como concorrência, novas tentativas e o que fazer com cada documento que passa pela função, seja com sucesso ou com falha.
Uma característica interessante dessa ferramenta auxiliar é a possibilidade de trabalhar com fluxos de dados. Essa função permite enviar um arquivo linha por linha, em vez de armazenar o arquivo inteiro na memória e enviá-lo para o Elasticsearch de uma só vez.
Para enviar os dados para o Elasticsearch, crie um arquivo chamado data.ndjson na raiz do projeto e adicione as informações abaixo (alternativamente, você pode baixar o arquivo com o conjunto de dados aqui):
Usamos o split2 para transmitir as linhas do arquivo enquanto o auxiliar de processamento em lote as envia para o Elasticsearch.
O código acima lê um arquivo .ndjson. indexa cada objeto JSON em um índice Elasticsearch especificado usando o método helpers.bulk . Ele transmite o arquivo usando createReadStream e split2, configura metadados de indexação para cada documento e registra quaisquer documentos que não puderem ser processados. Após a conclusão, registra o número de itens indexados com sucesso.
Alternativamente à função indexData , você pode fazer o upload do arquivo diretamente pela interface do usuário usando o Kibana e usar a interface de upload de arquivos de dados.
Executamos o arquivo para enviar os documentos para o nosso cluster Elasticsearch.
node load.js
Buscando dados no Elasticsearch
Voltando ao nosso arquivo server.js , criaremos diferentes endpoints para realizar buscas lexicais, semânticas ou híbridas.
Em resumo, esses tipos de pesquisa não são mutuamente exclusivos, mas dependerão do tipo de pergunta que você precisa responder.
| Tipo de consulta | Caso de uso | Exemplo de pergunta |
|---|---|---|
| Consulta lexical | As palavras ou radicais presentes na pergunta provavelmente aparecerão nos documentos indexados. Similaridade entre tokens na pergunta e nos documentos. | Estou procurando uma camiseta esportiva azul. |
| Consulta semântica | É improvável que as palavras da pergunta apareçam nos documentos. Similaridade conceitual entre a pergunta e os documentos. | Estou procurando roupas para clima frio. |
| Busca híbrida | A questão contém componentes lexicais e/ou semânticos. Similaridade semântica e de tokens entre a pergunta e os documentos. | Estou procurando um vestido tamanho P para um casamento na praia. |
As partes lexicais da pergunta provavelmente fazem parte de títulos e descrições, ou nomes de categorias, enquanto as partes semânticas são conceitos relacionados a esses campos. "Azul" provavelmente será o nome de uma categoria ou parte de uma descrição, e "casamento na praia" provavelmente não será, mas pode estar semanticamente relacionado a roupas de linho.
Consulta lexical (/search/lexic?q=)<query_term>
A busca lexical, também chamada de busca de texto completo, significa pesquisar com base na similaridade de tokens; ou seja, após uma análise, os documentos que incluem os tokens da busca serão retornados.
Você pode conferir nosso tutorial prático de busca lexical aqui.
Testamos com: corte de unhas
Responder:
Consulta semântica<query_term> (/search/semantic?q=)
A busca semântica, diferentemente da busca lexical, encontra resultados que são semelhantes ao significado dos termos de busca por meio de busca vetorial.
Você pode conferir nosso tutorial prático de busca semântica aqui.
Fizemos o teste com a seguinte pergunta: Quem fez pedicure?
Responder:
Consulta híbrida (/search/hybrid?q=)<query_term>
A busca híbrida permite combinar a busca semântica e a busca lexical, obtendo assim o melhor dos dois mundos: a precisão da busca por token, juntamente com a proximidade de significado da busca semântica.
Fizemos o teste com a pergunta: “Quem fez pedicure ou tratamento dentário?”
Resposta.
Conclusão
Nesta primeira parte da nossa série, explicamos como configurar nosso ambiente e criar um servidor com diferentes endpoints de pesquisa para consultar os documentos do Elasticsearch, seguindo as melhores práticas de cliente/servidor. Confira a segunda parte da nossa série, na qual você aprenderá as melhores práticas de produção e como executar o cliente Elasticsearch Node.js em ambientes Serverless.
Perguntas frequentes
O que é o cliente Node.js?
O cliente Node.js é uma biblioteca JavaScript que coloca as chamadas HTTP REST da API Elasticsearch em JavaScript. Facilita ter ajudantes que simplificam tarefas como a indexação de documentos em lotes.
Por que usar um ambiente Node.js do lado do servidor em vez de chamar o Elasticsearch pelo frontend?
Segurança é a principal vantagem. Executar o cliente em um ambiente backend (como Node.js com Express) evita que informações sensíveis — como chaves da API do Cluster, URLs do host e lógica interna de consulta — sejam expostas ao navegador.
Quais são as vantagens de usar o "Bulk Helper" do Elasticsearch no Node.js?
As principais vantagens de usar o "Bulk Helper" do Elasticsearch no Node.js são: Indexação em lote: ela lida automaticamente com a complexidade de indexar documentos em grupos, em vez de um por um. Suporte a streams: usando ferramentas como split2, você pode transmitir arquivos (como .ndjson) linha por linha. Isso permite processar arquivos enormes sem carregar todo o conjunto de dados na memória do seu servidor.
Conteúdo relacionado

14 de novembro de 2025
Como implantar o Elasticsearch no Azure AKS automaticamente
Aprenda como implantar o Elasticsearch com o Kibana no Azure usando o AKS Automatic e o ECK para uma configuração parcialmente gerenciada do Elasticsearch.

11 de novembro de 2025
Configurando o particionamento recursivo para documentos estruturados no Elasticsearch
Aprenda como configurar o particionamento recursivo no Elasticsearch com tamanho de partição, grupos de separadores e listas de separadores personalizadas para indexação ideal de documentos estruturados.

7 de novembro de 2025
Apresentando a interface de usuário de regras de consulta do Elasticsearch no Kibana.
Aprenda a usar a interface de regras de consulta do Elasticsearch para adicionar ou excluir documentos de consultas de pesquisa usando conjuntos de regras personalizáveis no Kibana, sem afetar o ranking orgânico.

3 de outubro de 2025
Como implantar o Elasticsearch no AWS Marketplace
Aprenda como configurar e executar o Elasticsearch usando o Elastic Cloud Service no AWS Marketplace neste guia passo a passo.

14 de agosto de 2025
Fragmentos e réplicas do Elasticsearch: um guia prático
Domine os conceitos de shards e réplicas do Elasticsearch e aprenda como otimizá-los.