O Elasticsearch permite que você indexe dados de maneira rápida e flexível. Experimente gratuitamente na nuvem ou execute-o localmente para ver como a indexação pode ser fácil.
Neste artigo, mostramos como integrar o Apache Kafka com o Elasticsearch para ingestão e indexação de dados. Iremos apresentar uma visão geral do Kafka, seu conceito de produtores e consumidores, e criaremos um índice de logs onde as mensagens serão recebidas e indexadas através do Apache Kafka. O projeto foi implementado em Python e o código está disponível no GitHub.
Pré-requisitos
- Docker e Docker Compose: Certifique-se de ter o Docker e o Docker Compose instalados em sua máquina.
- Python 3.x: Para executar os scripts do produtor e do consumidor.
Introdução ao Apache Kafka
O Apache Kafka é uma plataforma de streaming distribuída que permite alta escalabilidade e disponibilidade, além de tolerância a falhas. No Kafka, o gerenciamento de dados ocorre por meio dos seguintes componentes principais:
- Intermediário (Broker): responsável por armazenar e distribuir mensagens entre produtores e consumidores.
- Zookeeper: gerencia e coordena os brokers do Kafka, controlando o estado do cluster, os líderes de partição e as informações do consumidor.
- Tópicos: canais onde os dados são publicados e armazenados para consumo.
- Consumidores e Produtores: enquanto os produtores enviam dados para os tópicos, os consumidores recuperam esses dados.
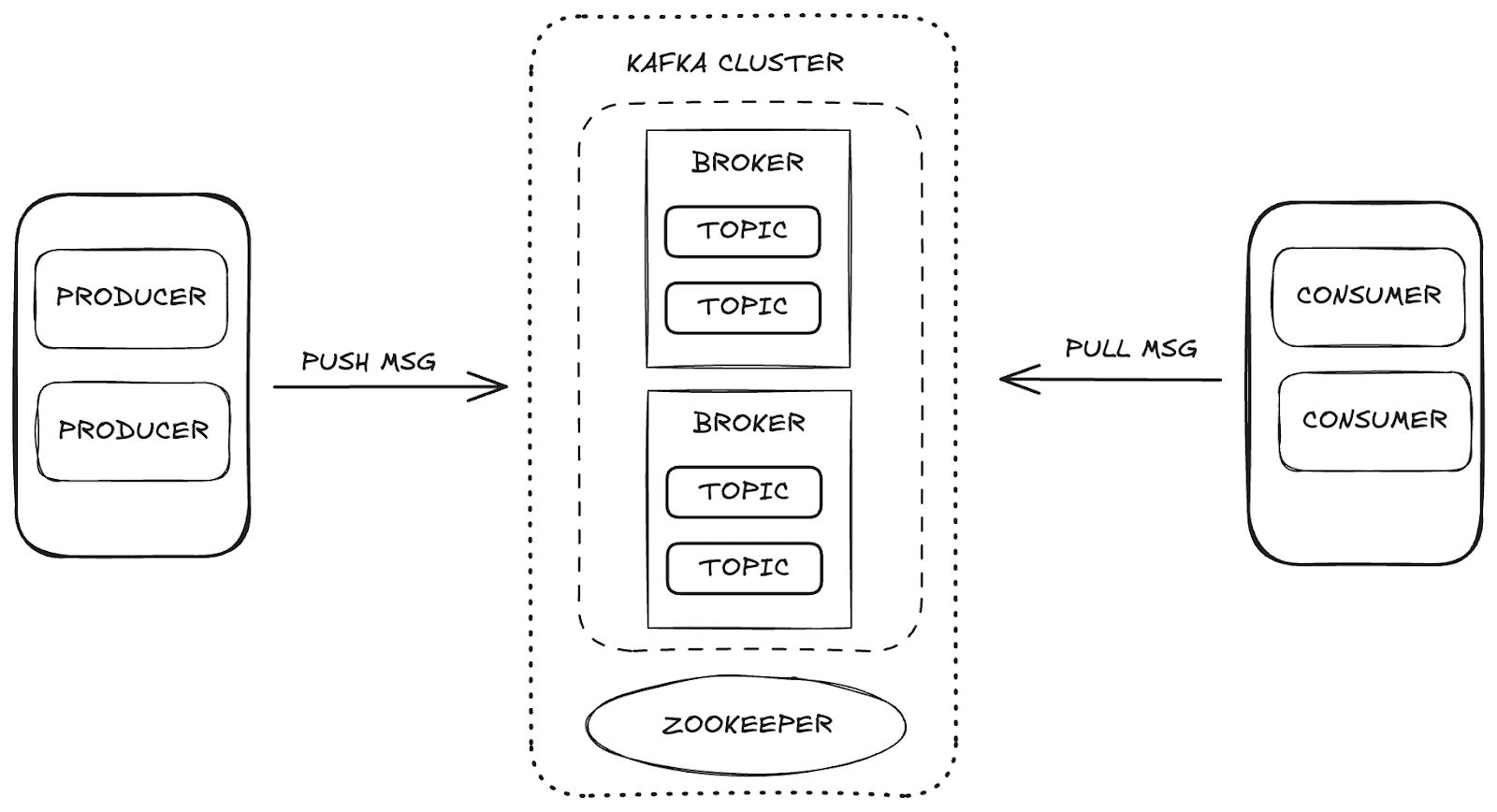
Esses componentes trabalham juntos para formar o ecossistema Kafka, fornecendo uma estrutura robusta para streaming de dados.
Estrutura do projeto
Para entender o processo de ingestão de dados, dividimos o processo em etapas:
- Provisionamento de infraestrutura: configuração do ambiente Docker para suportar Kafka, Elasticsearch e Kibana.
- Criação do produtor: implementação do produtor Kafka, que envia dados para o tópico de logs.
- Criação do consumidor: desenvolvimento do consumidor Kafka para ler e indexar mensagens no Elasticsearch.
- Validação de ingestão: verificação e validação dos dados enviados e consumidos.
Configuração de infraestrutura com Docker Compose
Utilizamos o Docker Compose para configurar e gerenciar os serviços necessários. A seguir, você encontrará o código Docker Compose que configura cada serviço necessário para a integração do Apache Kafka, Elasticsearch e Kibana, garantindo um processo de ingestão de dados.
Você pode acessar o arquivo diretamente do repositório GitHub do Elasticsearch Labs.
Envio de dados com o Kafka Producer
O produtor é responsável por enviar mensagens para o tópico de logs. Ao enviar mensagens em lotes, aumenta-se a eficiência do uso da rede, permitindo otimizações com as configurações batch_size e linger_ms , que controlam a quantidade e a latência dos lotes, respectivamente. A configuração acks='all' garante que as mensagens sejam armazenadas de forma durável, o que é essencial para dados de log importantes.
Ao iniciar o produtor, as mensagens são enviadas em lotes para o tópico, conforme mostrado abaixo:
Consumo e indexação de dados com o Kafka Consumer.
O consumidor foi projetado para processar mensagens de forma eficiente, consumindo lotes do tópico de logs e indexando-os no Elasticsearch. Com auto_offset_reset='latest', garante-se que o consumidor comece a processar as mensagens mais recentes, ignorando as mais antigas, e max_poll_records=10 limita o lote a 10 mensagens. Com fetch_max_wait_ms=2000, o consumidor espera até 2 segundos para acumular mensagens suficientes antes de processar o lote.
Em seu loop principal, o consumidor consome mensagens de log, processa e indexa cada lote no Elasticsearch, garantindo a ingestão contínua de dados.
Visualizando dados no Kibana
Com o Kibana, podemos explorar e validar os dados ingeridos do Kafka e indexados no Elasticsearch. Ao acessar as Ferramentas de Desenvolvimento no Kibana, você pode visualizar as mensagens indexadas e confirmar se os dados estão conforme o esperado. Por exemplo, se o nosso produtor Kafka enviar 5 lotes de 10 mensagens cada, devemos ver um total de 50 registros no índice.
Para verificar os dados, você pode usar a seguinte consulta na seção Ferramentas de Desenvolvimento :
Resposta.

Além disso, o Kibana oferece a capacidade de criar visualizações e painéis que podem ajudar a tornar a análise mais intuitiva e interativa. Abaixo, você pode ver alguns exemplos dos painéis e visualizações que criamos, os quais ilustram os dados em vários formatos, aprimorando nossa compreensão das informações processadas.

Ingestão de dados com Kafka Connect
O Kafka Connect é um serviço projetado para facilitar a integração entre fontes de dados e destinos (sinks), como bancos de dados ou sistemas de arquivos. Ele opera com conectores predefinidos que gerenciam a movimentação de dados automaticamente. Em nosso caso, o Elasticsearch funciona como o coletor de dados.

Ao usar o Kafka Connect, podemos simplificar o processo de ingestão de dados, eliminando a necessidade de implementar manualmente o fluxo de trabalho de ingestão de dados no Elasticsearch. Com o conector apropriado, o Kafka Connect permite que os dados enviados para um tópico do Kafka sejam indexados diretamente no Elasticsearch com configuração mínima e sem necessidade de codificação adicional.
Trabalhando com o Kafka Connect
Para implementar o Kafka Connect, adicionaremos o serviço kafka-connect à nossa configuração do Docker Compose. Uma parte fundamental dessa configuração é a instalação do conector Elasticsearch, que ficará responsável pela indexação dos dados.
Após configurar o serviço e criar o contêiner do Kafka Connect, será necessário um arquivo de configuração para o conector do Elasticsearch. Este arquivo define parâmetros essenciais, tais como:
connection.urlURL de conexão para o Elasticsearch.topicsO tópico do Kafka que o conector irá monitorar (neste caso, "logs").type.nameTipo de documento no Elasticsearch (normalmente _doc).value.converterConverte mensagens do Kafka para o formato JSON.value.converter.schemas.enableEspecifica se o esquema deve ser incluído.schema.ignoreekey.ignore: Configurações para ignorar esquemas e chaves do Kafka durante a indexação.
Abaixo está o comando curl para criar o conector Elasticsearch no Kafka Connect:
Com essa configuração, o Kafka Connect começará automaticamente a ingerir os dados enviados para o tópico "logs" e a indexá-los no Elasticsearch. Essa abordagem permite a ingestão e indexação de dados totalmente automatizadas, sem a necessidade de codificação adicional, simplificando assim todo o processo de integração.
Conclusão
A integração do Kafka e do Elasticsearch cria um poderoso pipeline para ingestão e análise de dados em tempo real. Este guia fornece uma abordagem fundamental para a construção de uma arquitetura robusta de ingestão de dados, com visualização e análise integradas no Kibana, pronta para se adaptar a requisitos mais complexos no futuro.
Além disso, o uso do Kafka Connect torna a integração entre o Kafka e o Elasticsearch ainda mais simplificada, eliminando a necessidade de código adicional para processar e indexar dados. O Kafka Connect permite que os dados enviados para um tópico específico sejam indexados automaticamente no Elasticsearch com configuração mínima.
Conteúdo relacionado

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

22 de setembro de 2025
Elastic Open Web Crawler como código
Aprenda a usar o GitHub Actions para gerenciar as configurações do Elastic Open Crawler, de forma que, sempre que enviarmos alterações para o repositório, elas sejam aplicadas automaticamente à instância implantada do crawler.

6 de agosto de 2025
Como exibir os campos de um índice do Elasticsearch
Aprenda como exibir os campos de um índice do Elasticsearch usando as APIs _mapping e _search, subcampos, _source sintético e campos de tempo de execução.

24 de junho de 2025
Scripting em Ruby no Logstash
Saiba mais sobre o plugin de filtro Ruby para Logstash, que permite a transformação avançada de dados em seu pipeline Logstash.

26 de maio de 2025
Exibindo campos em um índice do Elasticsearch
Explorando técnicas para exibir campos em um índice do Elasticsearch.