O Elasticsearch permite que você indexe dados de maneira rápida e flexível. Experimente gratuitamente na nuvem ou execute-o localmente para ver como a indexação pode ser fácil.
O que é o Apache Airflow?
O Apache Airflow é uma plataforma projetada para criar, agendar e monitorar fluxos de trabalho. É utilizado para orquestrar processos ETL, pipelines de dados e outros fluxos de trabalho complexos, oferecendo flexibilidade e escalabilidade. Sua interface visual e recursos de monitoramento em tempo real tornam o gerenciamento de pipelines mais acessível e eficiente, permitindo acompanhar o progresso e os resultados de suas execuções. Abaixo estão seus quatro pilares principais:
- Dinâmico: Os pipelines são definidos em Python, permitindo a geração de fluxos de trabalho dinâmicos e flexíveis.
- Extensível: O Airflow pode ser integrado a uma variedade de ambientes, operadores personalizados podem ser criados e códigos específicos podem ser executados conforme necessário.
- Elegante: os pipelines são escritos de forma clara e explícita.
- Escalável: Sua arquitetura modular utiliza uma fila de mensagens para orquestrar um número arbitrário de trabalhadores.
Na prática, o Airflow pode ser usado em cenários como:
- Importação de dados: Orquestre a ingestão diária de dados em um banco de dados como o Elasticsearch.
- Monitoramento de logs: Gerencie a coleta e o processamento de arquivos de log, que são então analisados no Elasticsearch para identificar erros ou anomalias.
- Integração de múltiplas fontes de dados: Combine informações de diferentes sistemas (APIs, bancos de dados, arquivos) em uma única camada no Elasticsearch, simplificando a busca e a geração de relatórios.
Entendendo os DAGs (Grafos Acíclicos Direcionados) no fluxo de ar
No Airflow, os fluxos de trabalho são representados por DAGs (Grafos Acíclicos Direcionados). Um DAG (Grafo Acíclico Direcionado) é uma estrutura que define a sequência em que as tarefas serão executadas. As principais características dos DAGs são:
- Composição por tarefas independentes: Cada tarefa representa uma unidade de trabalho e foi concebida para ser executada de forma independente.
- Sequenciamento: A sequência em que as tarefas são executadas é definida explicitamente no DAG (grafo acíclico direcionado).
- Reutilização: os DAGs são projetados para serem executados repetidamente, facilitando a automação de processos.
Componentes do fluxo de ar
O ecossistema Airflow é composto por diversos componentes que trabalham em conjunto para orquestrar tarefas:
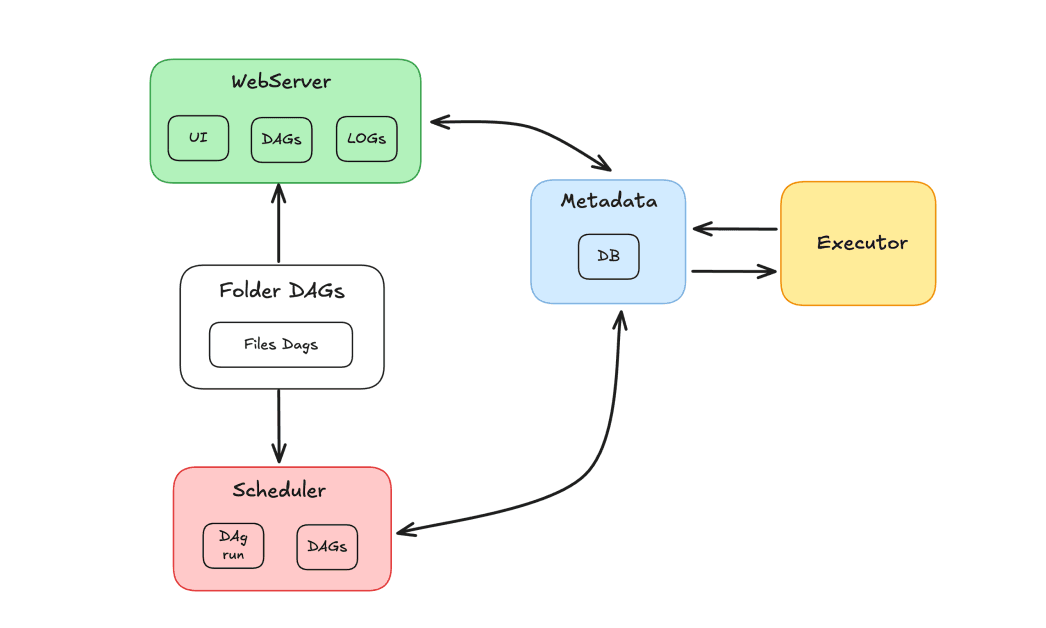
- Agendador: Responsável por agendar DAGs e enviar tarefas para execução pelos workers.
- Executor: Gerencia a execução de tarefas, delegando-as aos trabalhadores.
- Servidor Web: Fornece uma interface gráfica para interação com DAGs e tarefas.
- Pasta DAGs: Pasta onde armazenamos os DAGs escritos em Python.
- Metadados: Banco de dados que serve como repositório para a ferramenta, usado pelo agendador e pelo executor para armazenar o status da execução.
Apache Airflow e Elasticsearch
Iremos demonstrar o uso do Apache Airflow e do Elasticsearch para orquestrar tarefas e indexar resultados no Elasticsearch. O objetivo desta demonstração é criar um fluxo de tarefas para atualizar registros em um índice do Elasticsearch. Este índice contém um banco de dados de filmes, onde os usuários podem avaliar e atribuir notas. Imaginando um cenário com centenas de avaliações diárias, é necessário manter o registro de avaliações atualizado. Para isso, será desenvolvido um DAG (Grafo Acíclico Direcionado) que será executado diariamente, responsável por obter as novas classificações consolidadas e atualizar os registros no índice.
No fluxo DAG, teremos uma tarefa para obter as classificações, seguida de uma tarefa para validar os resultados. Caso os dados não existam, o DAG será direcionado para uma tarefa de falha. Caso contrário, os dados serão indexados no Elasticsearch. O objetivo é atualizar o campo de classificação de filmes em um índice, recuperando as classificações por meio de um método com o mecanismo responsável pelo cálculo das pontuações.
Utilizando Apache Airflow e Elasticsearch com Docker
Para criar um ambiente conteinerizado, usaremos o Apache Airflow com o Docker. Siga as instruções do guia "Executando o Airflow no Docker" para configurar o Airflow na prática.
Quanto ao Elasticsearch, usarei um cluster no Elastic Cloud, mas, se preferir, você também pode configurar o Elasticsearch com o Docker. Já foi criado um índice contendo um catálogo de filmes, com os dados dos filmes indexados. O campo de 'classificação' desses filmes será atualizado.
Criando o DAG
Após a instalação via Docker, será criada uma estrutura de pastas, incluindo a pasta dags, onde devemos colocar nossos arquivos DAG para que o Airflow os reconheça.
Antes disso, precisamos garantir que as dependências necessárias estejam instaladas. Aqui estão as dependências deste projeto:
Criaremos o arquivo update_ratings_movies.py e começaremos a codificar as tarefas.
Agora, vamos importar as bibliotecas necessárias:
Usaremos o ElasticsearchPythonHook, um componente que simplifica a integração entre o Airflow e um cluster Elasticsearch, abstraindo a conexão e o uso de APIs externas.
Em seguida, definimos o DAG, especificando seus principais argumentos:
dag_id: o nome do DAG.start_date: quando o DAG será iniciado.schedule: define a periodicidade (diária no nosso caso).doc_mdDocumentação que será importada e exibida na interface do Airflow.
Definindo as tarefas
Agora, vamos definir as tarefas do DAG. A primeira tarefa será responsável por obter os dados de classificação dos filmes. Usaremos o PythonOperator com o task_id definido como 'get_movie_ratings'. O parâmetro python_callable chamará a função responsável por obter as classificações.
Em seguida, precisamos validar se os resultados são válidos. Para isso, usaremos uma condicional com um BranchPythonOperator. O task_id será 'validate_result' e o python_callable chamará a função de validação. O parâmetro op_args será usado para passar o resultado da tarefa anterior, 'get_movie_ratings', para a função de validação.
Se a validação for bem-sucedida, pegaremos os dados da tarefa 'get_movie_ratings' e os indexaremos no Elasticsearch. Para alcançar isso, criaremos uma nova tarefa, 'index_movie_ratings', que usará o PythonOperator. O parâmetro op_args passará os resultados da tarefa 'get_movie_ratings' para a função de indexação.
Se a validação indicar uma falha, o DAG prosseguirá para uma tarefa de notificação de falha. Neste exemplo, simplesmente imprimimos uma mensagem, mas em um cenário real, poderíamos configurar alertas para notificar sobre as falhas.
Por fim, definimos as dependências das tarefas, garantindo que elas sejam executadas na ordem correta:
Segue agora o código completo do nosso DAG:
Visualizando a execução do DAG
Na interface do Apache Airflow, podemos visualizar a execução dos DAGs (grafos acíclicos direcionados). Basta acessar a aba "DAGs" e localizar o DAG que você criou.
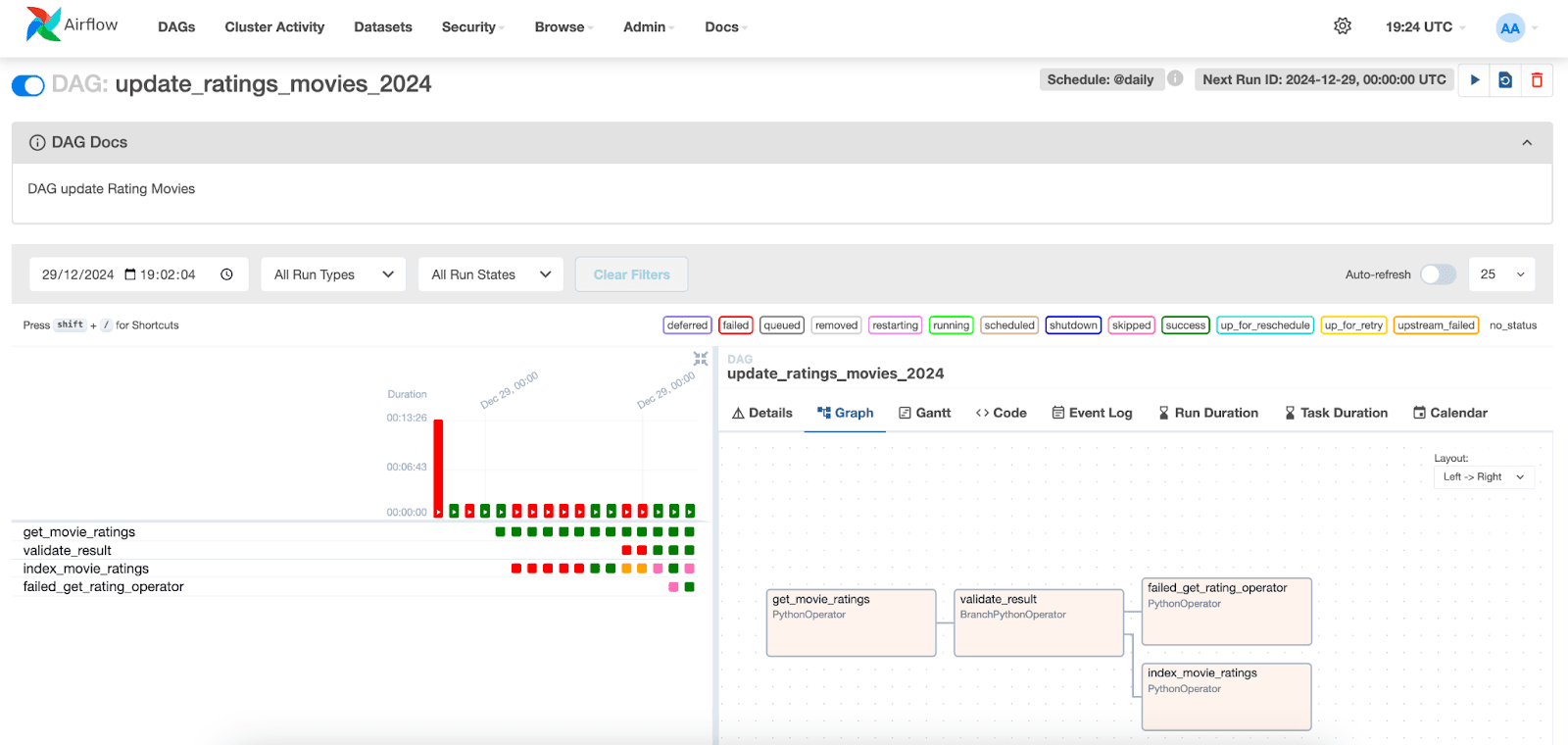
Abaixo, podemos visualizar a execução das tarefas e seus respectivos status. Ao selecionar uma execução para uma data específica, podemos acessar os registros de cada tarefa. Observe que na tarefa index_movie_ratings , podemos ver os resultados da indexação no índice e que ela foi concluída com sucesso.

Nas outras abas, é possível acessar informações adicionais sobre as tarefas e o DAG, auxiliando na análise e resolução de possíveis problemas.
Conclusão
Neste artigo, demonstramos como integrar o Apache Airflow com o Elasticsearch para criar uma solução de ingestão de dados. Mostramos como configurar o DAG, definir as tarefas responsáveis por recuperar, validar e indexar dados de filmes, bem como monitorar e visualizar a execução dessas tarefas na interface do Airflow.
Essa abordagem pode ser facilmente adaptada a diferentes tipos de dados e fluxos de trabalho, tornando o Airflow uma ferramenta útil para orquestrar pipelines de dados em diversos cenários.
Referências
Apache AirFlow
Instale o Apache Airflow com o Docker.
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
Gancho Python do Elasticsearch
Operador Python
https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html
Perguntas frequentes
O que é o Apache Airflow?
O Apache Airflow é uma plataforma projetada para criar, agendar e monitorar fluxos de trabalho.
Para que serve o Apache Airflow?
O Apache Airflow é usado para orquestrar processos ETL, pipelines de dados e outros fluxos de trabalho complexos, oferecendo flexibilidade e escalabilidade.
Quais são os principais componentes do Apache Airflow?
Os principais componentes do Airflow são: Scheduler (Agendador), Executor (Executor), Web Server (Servidor Web), DAGs Folder (Pasta de DAGs) e Metadata (Metadados).
É possível integrar o Apache Airflow com o Elasticsearch?
Sim, o Apache Airflow pode ser integrado ao Elasticsearch. Por exemplo, você pode usar o Apache Airflow para orquestrar tarefas e indexar resultados no Elasticsearch.
O que é um DAG no Apache Airflow?
No Airflow, os fluxos de trabalho são representados por DAGs (Grafos Acíclicos Direcionados). Um DAG (Grafo Acíclico Direcionado) é uma estrutura que define a sequência em que as tarefas serão executadas.
Conteúdo relacionado

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

22 de setembro de 2025
Elastic Open Web Crawler como código
Aprenda a usar o GitHub Actions para gerenciar as configurações do Elastic Open Crawler, de forma que, sempre que enviarmos alterações para o repositório, elas sejam aplicadas automaticamente à instância implantada do crawler.

6 de agosto de 2025
Como exibir os campos de um índice do Elasticsearch
Aprenda como exibir os campos de um índice do Elasticsearch usando as APIs _mapping e _search, subcampos, _source sintético e campos de tempo de execução.

24 de junho de 2025
Scripting em Ruby no Logstash
Saiba mais sobre o plugin de filtro Ruby para Logstash, que permite a transformação avançada de dados em seu pipeline Logstash.

26 de maio de 2025
Exibindo campos em um índice do Elasticsearch
Explorando técnicas para exibir campos em um índice do Elasticsearch.