Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
What if you could turn your Elasticsearch data into creative output using an LLM—in just a few lines of code? With the new COMPLETION command in ES|QL, now you can.
Let’s build something fun to show it off: a Chuck Norris fact generator. We'll combine movie descriptions with a GPT model to generate facts so legendary even Rambo would be impressed.
What you'll need
- Access to an LLM (like OpenAI’s GPT-4o in our example below)
- A dataset of movie descriptions
You can download a sample dataset from Kaggle and upload it to your Elasticsearch cluster using the Data Visualizer in Kibana or the _bulk API.
Setting up the inference endpoint
Before you can run the COMPLETION command, you need to create an inference endpoint for the model you want to use via the _inference API.
Here’s how to set up GPT-4o with OpenAI:
Once this is in place, you can reference my-gpt-4o-endpoint directly in your query.
The query
Here’s the magic in action. This single ES|QL query handles the entire workflow: it finds a movie based on your input, constructs a prompt from its description, and then calls the LLM to generate a legendary Chuck Norris fact. Below is the full ES|QL query that powers our Chuck Norris fact generator. It takes in a movie query, retrieves the most relevant description, turns it into a prompt, and sends it off to the LLM—all in a single, piped query.
Here’s what comes back:
Yes, the model really said that. 💪🐐🚁
Dissecting the query
Let’s dissect the query and break down what’s happening, step by step.
Step 1: Retrieve relevant movie data
We begin by searching for the most relevant movie for the user query.
We use the MATCH function to search both the title and overview fields for the text provided by the query parameter, keeping only the first result, sorted by relevance using the metadata _score field:
This narrows down our dataset to the best match, giving us the movie's title and description, which will become the context for the LLM.
Step 2: Build the prompt from the context
Now we create the input prompt for the LLM by concatenating a static instruction provided as a query parameter, denoted by ?instruction, with the movie’s overview:
This creates a new prompt column combining the provided instruction with the overview field from the returned document, which for our request looks a bit like this:
You can easily swap in different instructions to change the tone or style of what the LLM generates by tweaking the instruction parameter. And because the prompt is just another ES|QL expression, you can compose it with any string-generating function—whether it’s simple concatenation, conditional logic, or even formatting based on your document content.
Step 3: Generate text using the LLM
Finally, we pass the prompt to the inference endpoint connected to our model using our new COMPLETION command, and select which fields to return:
The result? A Chuck Norris fact, rooted in your movie data without any extra tooling required.
This example also demonstrates the full power of ES|QL's piped structure. Each step flows naturally into the next, letting you express a full retrieval augmented generation (RAG) pipeline in a single, declarative query. It’s clean, composable, and stays entirely inside Elasticsearch.
What’s next?
While the COMPLETION command is still a tech preview, this new feature unlocks a whole new world of possibilities—from summarization and content generation to enrichment and storytelling. Try it yourself! Point it at your favorite movie, tweak the prompt, or go wild and generate haikus from SQL errors. The power is yours.
Let us know what you build! 💬
관련 콘텐츠

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.

2026년 7월 7일
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.
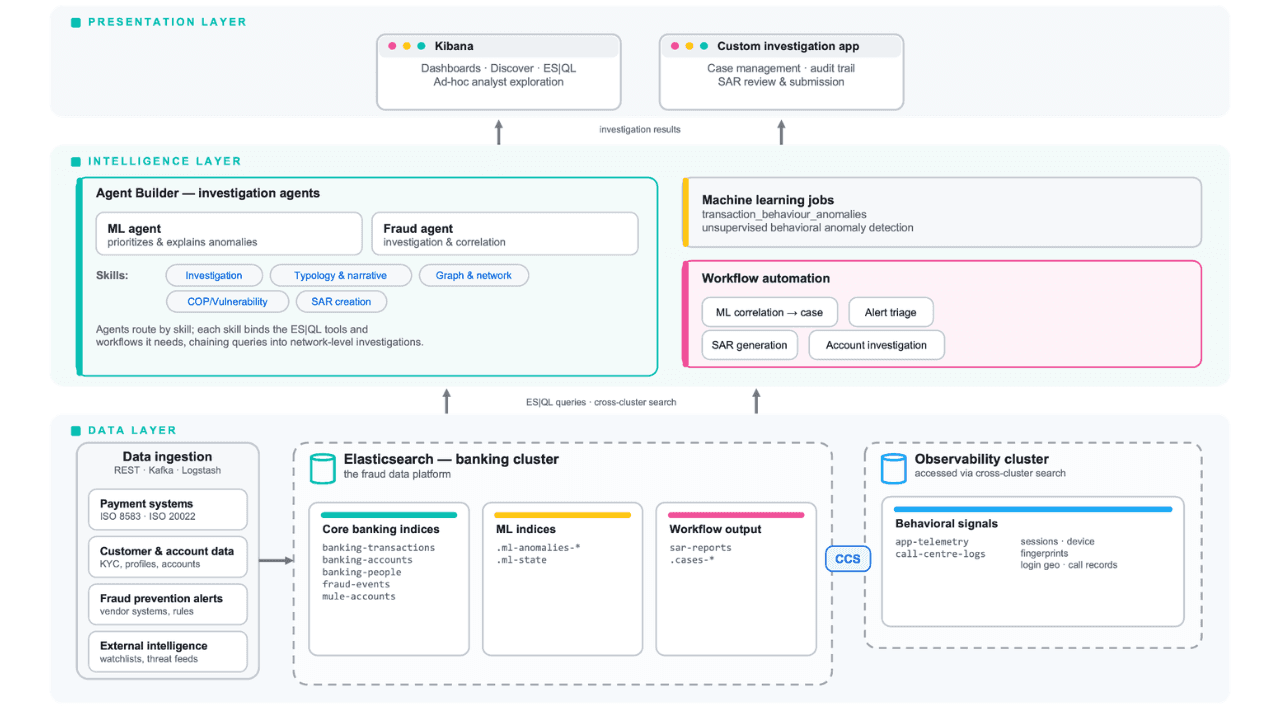
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

2026년 7월 1일
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

2026년 6월 30일
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.