判断リストの作成は、検索結果の品質を最適化する上で重要なステップですが、複雑で困難な作業になる場合があります。判断リストは、対応する結果の関連性評価と組み合わせた検索クエリの厳選されたセットであり、テスト コレクションとも呼ばれます。このリストを使用して計算されたメトリックは、検索エンジンのパフォーマンスを測定するためのベンチマークとして機能します。判断リストの作成プロセスを効率化するために、 OpenSource ConnectionsチームはQuepid を開発しました。判断は明示的なものでも、ユーザーからの暗黙的なフィードバックに基づくものでも構いません。このブログでは、あらゆる判断リストの基礎となる明示的な判断を人間の評価者が効果的に行えるように、Quepid で共同作業環境を設定する方法について説明します。
Quepid は、検索品質評価プロセスにおいて検索チームをサポートします。
- クエリセットを構築する
- 判断リストを作成する
- 検索品質指標を計算する
- 計算された検索品質指標に基づいて、さまざまな検索アルゴリズム/ランカーを比較します
私たちのブログでは、映画レンタル店を運営しており、検索結果の品質を向上させることを目標としていると仮定しましょう。
要件
このブログでは、es-tmdb リポジトリのデータとマッピングを使用します。データはThe Movie Databaseから取得されています。手順に沿って、マッピングを使用して tmdb というインデックスを設定し、データにインデックスを付けます。ローカルインスタンスをセットアップするか、Elastic Cloud デプロイメントを使用するかは問題ではありません。どちらでも問題なく動作します。このブログでは、Elastic Cloud のデプロイメントを想定しています。データのインデックス作成方法については、es-tmdb リポジトリの README を参照してください。
検索するデータがあることを確認するには、 rockyのタイトル フィールドで単純な一致クエリを実行します。
8 件の結果が表示されます。
Quepidにログイン
Quepid は、ユーザーが検索結果の品質を測定し、オフライン実験を実行して品質を向上できるようにするツールです。
Quepid は 2 つの方法で使用できます: https://app.quepid.comで公開されている無料のホストバージョンを使用するか、または、アクセスできるマシンに Quepid をセットアップします。この投稿では、無料のホスト バージョンを使用していることを前提としています。ご使用の環境に Quepid インスタンスを設定する場合は、インストール ガイドに従ってください。
どちらの設定を選択する場合でも、まだアカウントをお持ちでない場合はアカウントを作成する必要があります。
Quepidケースの設定方法
Quepid は「ケース」を中心に構成されています。ケースには、関連性調整設定と検索エンジンへの接続を確立する方法とともにクエリが保存されます。
- 初めて使用する場合は、 「最初の関連性ケースを作成する」を選択します。
- 再度アクセスしたユーザーは、トップレベルのメニューから[関連性ケース]を選択し、 [+ ケースを作成] をクリックできます。
ベースライン検索の測定と改善を開始するため、ケースに説明的な名前を付けます (例:「映画検索ベースライン」)。
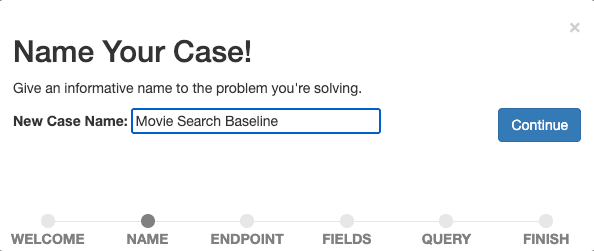
[続行]を選択して名前を確認します。
次に、Quepid から検索エンジンへの接続を確立します。Quepid は、Elasticsearch を含むさまざまな検索エンジンに接続できます。
構成は、Elasticsearch と Quepid の設定によって異なります。Quepid を Elastic Cloud デプロイメントに接続するには、Elastic Cloud デプロイメントに対して CORS を有効にして構成し、API キーを用意する必要があります。詳細な手順は、 Quepid ドキュメントの対応するハウツーに記載されています。
Elasticsearch エンドポイント情報 ( https://YOUR_ES_HOST:PORT/tmdb/_search ) と接続に必要な追加情報 (詳細設定オプションの Elastic Cloud デプロイメントの場合は API キー) を入力し、 pingをクリックして接続をテストし、 [続行] を選択して次のステップに進みます。

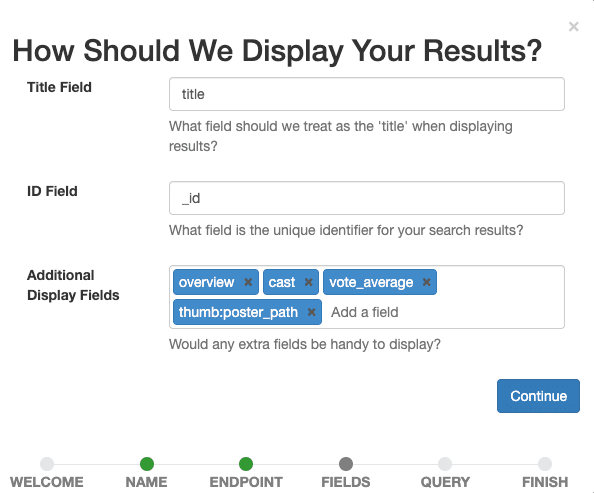
ここで、ケースに表示するフィールドを定義します。人間の評価者が後で特定のクエリに対するドキュメントの関連性を評価するのに役立つものをすべて選択します。
titleタイトル フィールドとして設定し、 _id ID フィールドのままにして、 overview, tagline, cast, vote_average, thumb:poster_path追加表示フィールドとして追加します。最後のエントリには、結果内の映画の小さなサムネイル画像が表示され、私たちと人間の評価者に視覚的にガイドします。
[続行]ボタンを選択して表示設定を確認します。
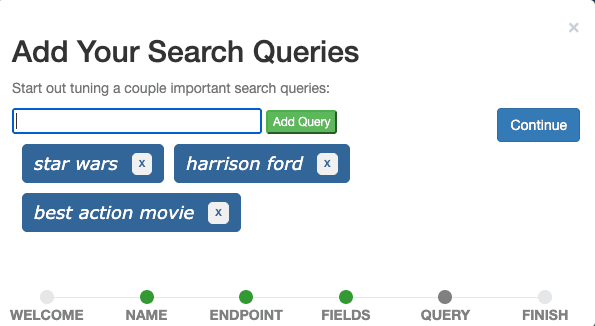
最後のステップは、ケースに検索クエリを追加することです。入力フィールドから「スターウォーズ」 、 「ハリソンフォード」 、 「ベストアクション映画」の3 つのクエリを 1 つずつ追加し、 「続行」をクリックします。
理想的には、ケースには実際のユーザークエリを表し、さまざまな種類のクエリを示すクエリが含まれます。現時点では、スターウォーズは映画のタイトルのすべてのクエリを表すクエリ、ハリソンフォードはキャストメンバーのすべてのクエリを表すクエリ、ベストアクション映画は特定のジャンルの映画を検索するすべてのクエリを表すクエリであると想像できます。これは通常、クエリ セットと呼ばれます。
実稼働シナリオでは、確率比例サイズサンプリングなどの統計手法を適用してイベント トラッキング データからクエリをサンプリングし、これらのサンプリングされたクエリを Quepid にインポートして、頻度に応じて先頭 (頻繁に発生するクエリ) と末尾 (発生頻度の低いクエリ) のクエリを含めます。つまり、まれなクエリを除外することなく、より頻度の高いクエリに偏向させるということです。
最後に、 「完了」を選択すると、定義された 3 つのクエリが表示されるケース インターフェイスに移動します。
クエリと情報ニーズ
判断リストという全体的な目標に到達するには、人間の評価者が特定のクエリに対する検索結果 (通常はドキュメント) を判断する必要があります。これはクエリ/ドキュメント ペアと呼ばれます。
場合によっては、クエリを見るとユーザーが何を望んでいたかが簡単にわかるようです。クエリharrison fordの目的は、俳優のハリソン・フォードが主演する映画を見つけることです。クエリactionについてはどうでしょうか?ユーザーの意図はアクション ジャンルに属する映画を見つけることだと言いたくなるでしょう。でもどれですか?最新のもの、最も人気のあるもの、ユーザーの評価による最高のものはありますか?あるいは、ユーザーは「アクション」と呼ばれるすべての映画を見つけたいのでしょうか?映画データベースには「アクション」というタイトルの映画が少なくとも 12 本 (!) あり、それらの名前は主にタイトルに含まれる感嘆符の数によって異なります。
意図が不明瞭なクエリの場合、2 人の評価者の間で解釈に違いが生じる可能性があります。情報ニーズの登場:情報ニーズとは、情報に対する意識的または無意識的な欲求のことです。情報ニーズを定義すると、人間の評価者がクエリに対して文書を判断するのに役立つため、判断リストを構築するプロセスで重要な役割を果たします。専門ユーザーまたは主題の専門家は、情報ニーズを指定するのに適しています。検索結果はユーザーのニーズを満たす必要があるため、ユーザーの視点から情報ニーズを定義することをお勧めします。
「映画検索ベースライン」のケースのクエリに必要な情報:
- スターウォーズ: ユーザーはスターウォーズシリーズの映画や番組を見つけたいと考えています。関連性がある可能性があるのは、スターウォーズに関するドキュメンタリーです。
- ハリソン・フォード: ユーザーは俳優ハリソン・フォードが主演する映画を見つけたいと考えています。関連性がある可能性があるのは、ハリソン・フォードがナレーターなどの別の役割を担っている映画です。
- 最高のアクション映画: ユーザーはアクション映画、できれば平均ユーザー投票数の多い映画を見つけたいと考えています。
Quepidで情報ニーズを定義する方法
Quepid で情報ニーズを定義するには、ケース インターフェースにアクセスします。
1. クエリ (たとえば、スターウォーズ) を開き、 [Toggle Notes] を選択します。
2. 最初のフィールドに情報ニーズを入力し、2 番目のフィールドに追加のメモを入力します。
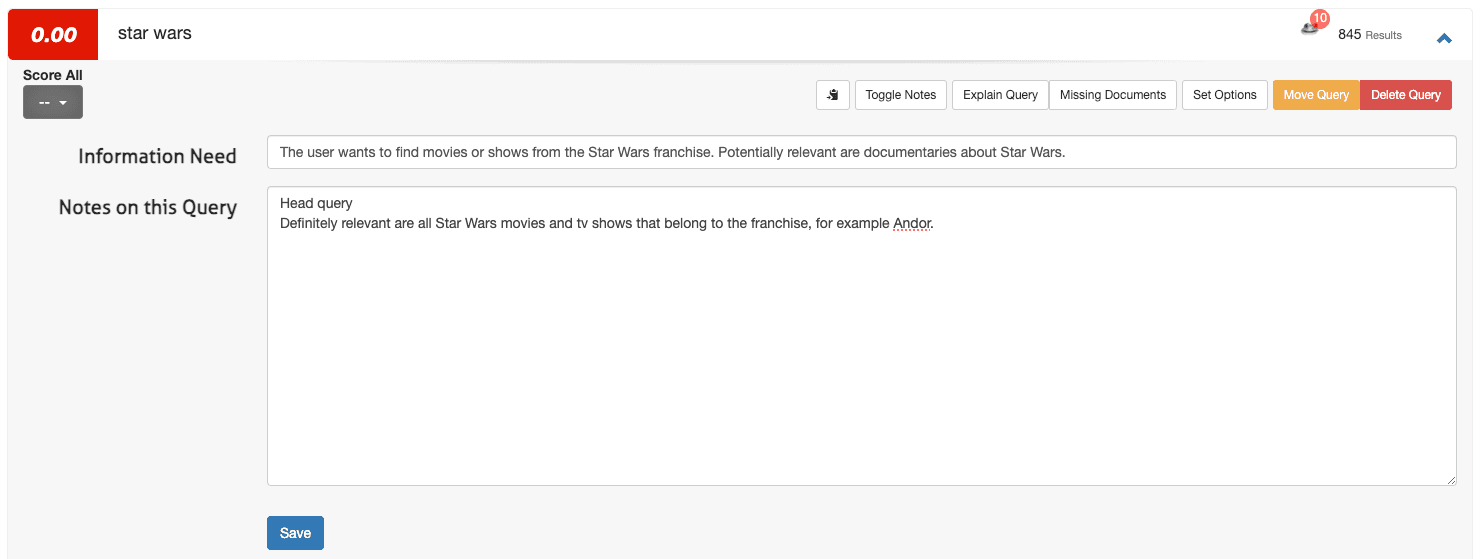
3. 「保存」をクリックします。
少数のクエリの場合、このプロセスは適切です。ただし、ケースを 3 クエリから 100 クエリに拡張する場合 (Quepid のケースでは、多くの場合、クエリは 50 ~ 100 クエリの範囲です)、Quepid の外部で (たとえば、スプレッドシートで) 情報ニーズを定義し、それを[インポート] からアップロードして[情報ニーズ] を選択する必要がある場合があります。
Quepidでチームを作成し、ケースを共有する
共同判断により関連性評価の品質が向上します。チームを設定するには:
1. 最上位メニューの「Teams」に移動します。

2. [+ 新規追加]をクリックし、チーム名 (例:「検索関連性評価者」) を入力して、 [作成] をクリックします。
3. メールアドレスを入力し、 「ユーザーの追加」をクリックしてメンバーを追加します。
4. ケースインターフェースで、 「ケースの共有」を選択します。
5. 適切なチームを選択して確認します。
Quepidで判定ブックを作成する
Quepid のブックでは、複数の評価者がクエリ/ドキュメントのペアを体系的に評価できます。作成するには:
1. ケースインターフェースの「判決」に移動し、 「+ ブックを作成」をクリックします。
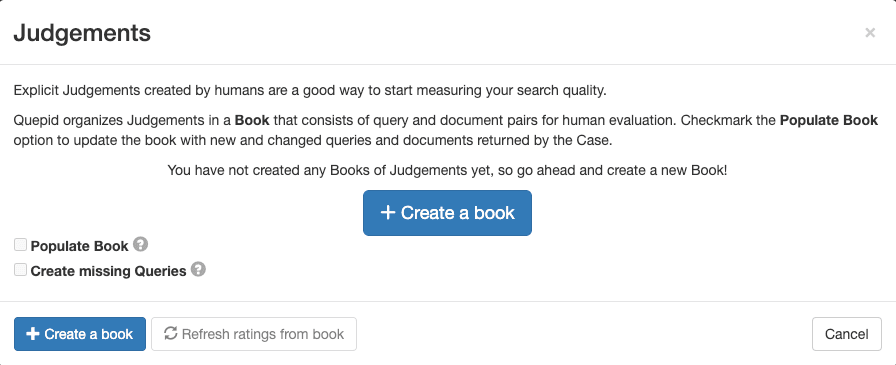
2. ブックにわかりやすい名前を付けてチームに割り当て、採点方法 (DCG@10 など) を選択し、選択戦略 (単一または複数の評価者) を設定します。ブックには次の設定を使用します。
- 名称:「映画検索0-3スケール」
- この本を共有するチーム: 作成したチームのボックスにチェックを入れます
- 得点者: DCG@10
3. 「ブックを作成」をクリックします。
名前は説明的で、検索対象(「映画」)に関する情報と、評価のスケール(「0~3」)が含まれています。選択したスコアラー DCG@10 によって、検索メトリックの計算方法が決まります。「DCG」は「Discounted Cumulative Gain」の略で、「@10」は指標を計算する際に考慮される上位からの結果の数です。
この場合、情報ゲインを測定し、それを位置の重み付けと組み合わせるメトリックを使用しています。他にもユースケースに適した検索メトリックが存在する可能性があり、適切なものを選択すること自体が課題となります。
クエリとドキュメントのペアをブックに入力する
関連性評価のためにクエリ/ドキュメントのペアを追加するには、次の手順に従います。
1.ケース インターフェースで、「判決」に移動します。

2. 作成したブックを選択します。
3. 「ブックに入力」をクリックし、「ブックのクエリ/ドキュメント ペアを更新」を選択して確認します。
このアクションにより、各クエリの上位の検索結果に基づいてペアが生成され、チームによる評価の準備が整います。
人間の評価チームに判断させる
これまでに完了した手順は、かなり技術的かつ管理的なものでした。必要な準備が完了したので、審査員チームに作業を任せることができます。本質的に、審査員の仕事は、与えられたクエリに対する特定の文書の関連性を評価することです。このプロセスの結果は、判断されたクエリ ドキュメント ペアのすべての関連性ラベルを含む判断リストです。次に、このプロセスとそのインターフェースについてさらに詳しく説明します。
人間評価インターフェースの概要

Quepidの人間評価インターフェースは、効率的な評価ができるように設計されています。
- クエリ:検索用語を表示します。
- 情報ニーズ:ユーザーの意図を示します。
- 採点ガイドライン:一貫した評価を行うための指示を提供します。
- ドキュメント メタデータ:ドキュメントに関する関連詳細を表示します。
- 評価ボタン:評価者は対応するキーボード ショートカットを使用して判断を割り当てることができます。
人間評価インターフェースを使用する
人間の評価者として、私は本の概要からインターフェースにアクセスします。
1. ケース インターフェイスに移動し、 [判決]をクリックします。
2. 「より多くの判断が必要です!」をクリックします。
システムはまだ評価されておらず、追加の判断が必要なクエリ/ドキュメントのペアを提示します。これは、ブックの選択戦略によって決まります。
- 単一の評価者: クエリ/ドキュメントのペアごとに 1 つの判断。
- 複数の評価者: クエリ/ドキュメントのペアごとに最大 3 つの判断。
クエリとドキュメントのペアを評価する
いくつかの例を見てみましょう。このガイドに従うと、さまざまな映画が表示される可能性が高くなります。ただし、評価の原則は変わりません。
最初の例は、映画「Heroes」でクエリ「harrison ford」を検索するものです。
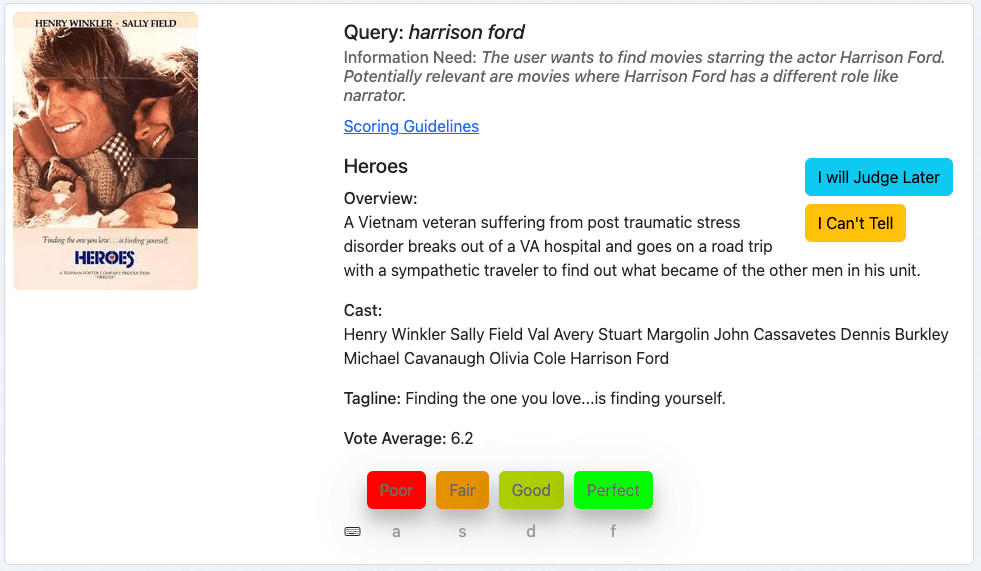
まずクエリを確認し、次に情報ニーズを確認し、最後に指定されたメタデータに基づいて映画を判断します。
この映画は、ハリドソン・フォードが出演しているため、私たちの検索に関連する結果です。私たちは主観的には最近の映画の方が関連性が高いと考えるかもしれませんが、これは私たちの情報ニーズには含まれません。したがって、この文書は当社の評価尺度で 3 に相当する「完璧」と評価されます。
次の例は、映画「フォードvsフェラーリ」のクエリ「harrison ford」です。

同じ慣例に従い、クエリ、情報ニーズ、そしてドキュメントのメタデータが情報ニーズにどの程度一致しているかを見て、このクエリ/ドキュメントを判断します。
これは悪い結果です。この結果は、おそらく、クエリ用語の 1 つである「ford」がタイトルに一致していることを示していると思われます。しかし、ハリソン・フォードはこの映画でも他の役でも何の役も演じていない。したがって、この文書は「悪い」と評価され、これは当社の評価尺度では 0 に相当します。
3番目の例は、クエリ「ベストアクション映画」に対する映画「アクションジャクソン」です。
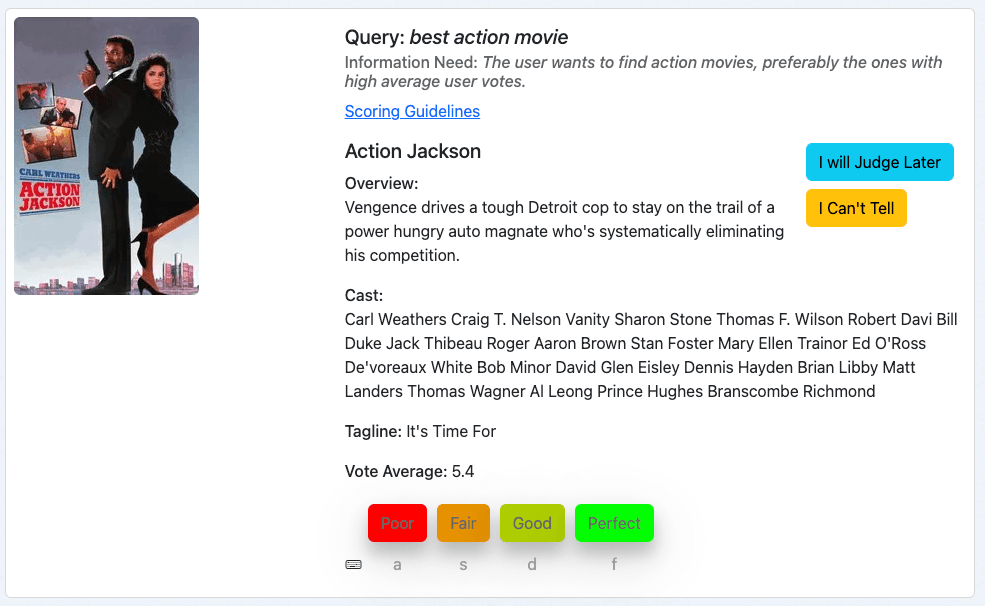
これはアクション映画のように見えるので、情報ニーズは少なくとも部分的に満たされています。しかし、投票平均は10点満点中5.4点です。そのため、この映画はおそらく私たちのコレクションの中で最高のアクション映画ではないでしょう。したがって、審査員である私としては、この文書を「普通」と評価します。これは、当社の評価尺度では 1 です。
これらの例は、特に Quepid を使用してクエリ/ドキュメントのペアを評価するプロセスを、高レベルと全般にわたって示しています。
人間評価者の最適な活用のヒント
示された例を見ると、明確な判断に至るのは簡単そうに思えるかもしれません。しかし、信頼できる人間による評価プログラムを構築するのは簡単なことではありません。これは、データの品質を簡単に損なう可能性のある課題に満ちたプロセスです。
- 人間の評価者は反復的な作業で疲れてしまうことがあります。
- 個人的な好みにより判断が歪む可能性があります。
- 分野の専門知識のレベルは裁判官によって異なります。
- 評価者は多くの場合、複数の責任を同時にこなします。
- ドキュメントの認識された関連性は、クエリに対する実際の関連性と一致しない場合があります。
これらの要因により、一貫性のない低品質の判断が生じる可能性があります。しかし、心配する必要はありません。これらの問題を最小限に抑え、より堅牢で信頼性の高い評価プロセスを構築するのに役立つ、実証済みのベスト プラクティスがあります。
- 一貫した評価:クエリ、情報ニーズ、ドキュメント メタデータを順番に確認します。
- ガイドラインを参照してください:一貫性を保つためにスコアリング ガイドラインを使用します。採点ガイドラインには、どのグレードをいつ適用するかの例など、審査プロセスを示すものが含まれます。最初の一連の判断の後に人間の評価者とチェックインすることは、困難なエッジケースや追加のサポートが必要な場所を知るための良い方法であることが証明されました。
- オプションを活用する:不明な場合は、「後で判断します」または「わかりません」を使用し、必要に応じて説明を加えます。
- 休憩を取る:定期的に休憩を取ると判断力を維持するのに役立ちます。Quepid は、人間の評価者が一連の判定を終えるたびに紙吹雪を飛ばして、定期的な休憩を促します。
これらの手順に従うことで、Quepid で判断リストを作成するための構造化された共同アプローチを確立し、検索関連性の最適化の取り組みの有効性を高めることができます。
今後の見通し
ここからどこへ行くのでしょうか?判断リストは、検索結果の品質を向上させるための基本的なステップの 1 つにすぎません。次の手順は次のとおりです。
指標を計算して実験を始める
判断リストが利用可能になると、その判断を活用して検索品質メトリックを計算するのは自然な流れになります。Quepid は、判断が可能な場合、現在のケースに対して構成されたメトリックを自動的に計算します。メトリックは「スコアラー」として実装されており、サポートされているメトリックにお気に入りのメトリックが含まれていない場合は、独自のメトリックを提供できます。
ケース インターフェイスに移動し、 [スコアラーの選択]に移動して、 DCG@10を選択し、 [スコアラーの選択]をクリックして確認します。Quepid はクエリごとに DCG@10 を計算し、全体的なクエリの平均も計算して、ケースの検索結果の品質を定量化します。
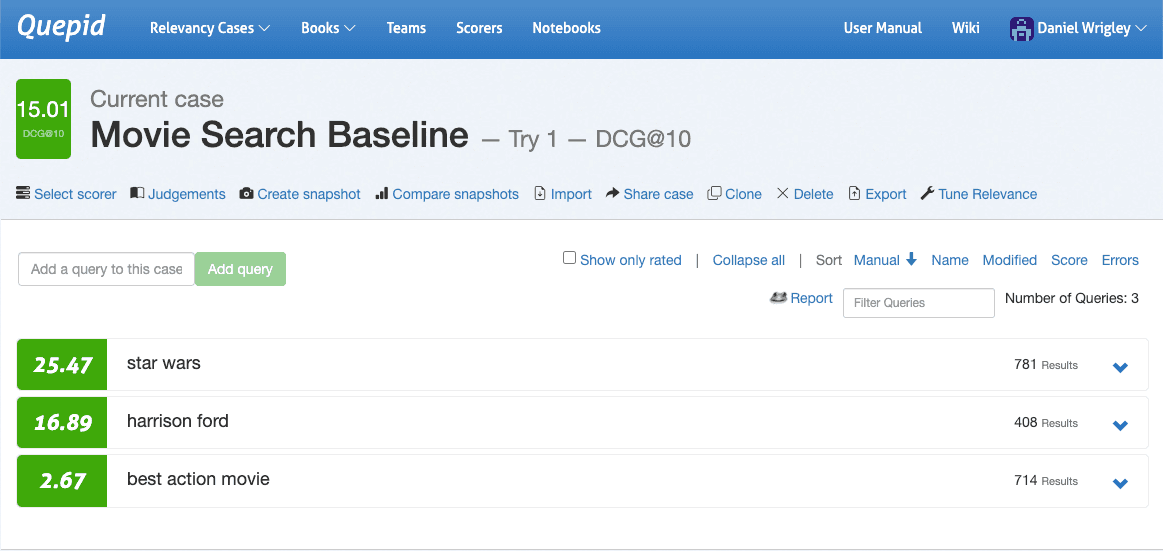
検索結果の品質が定量化されたので、最初の実験を実行できます。実験は仮説を立てることから始まります。評価を行った後のスクリーンショットの 3 つのクエリを見ると、検索品質メトリックの点から見ると 3 つのクエリのパフォーマンスが大きく異なることが明らかです。 「スターウォーズ」のパフォーマンスはかなり良好で、 「ハリソンフォード」も悪くありませんが、最も大きな可能性を秘めているのは「ベストアクション映画」です。
このクエリを拡張すると、その結果が表示され、細かい詳細まで掘り下げて、ドキュメントが一致した理由やスコアに影響を与えるものを調べることができます。

「クエリの説明」をクリックして「解析」タブに入ると、クエリがキャスト、概要、タイトルの3つのフィールドを検索するDisjunctionMaxxQueryであることがわかります。

通常、検索エンジニアとして私たちは、検索プラットフォームに関するドメイン固有の情報をある程度知っています。この場合、ジャンルフィールドがあることが分かります。これをクエリに追加して、検索品質が向上するかどうかを確認しましょう。
ケース インターフェースで[関連性の調整] を選択すると開く クエリ サンドボックス を使用します。検索するジャンルフィールドを追加して、これを探索してみましょう。
「検索を再実行」をクリックしてください。そして結果を確認します。彼らは変わったのでしょうか?残念ながらそうではありません。現在、探索できるオプションは多数あり、基本的には Elasticsearch が提供するすべてのクエリ オプションがあります。
- ジャンルフィールドのフィールドウェイトを増やすことができます。
- 投票平均によってドキュメントをブーストする関数を追加できます。
- ジャンルの一致が強い場合にのみ投票平均によってドキュメントをブーストする、より複雑なクエリを作成することもできます。
- …
これらすべてのオプションを Quepid で検討することの最大の利点は、改善しようとしている 1 つのクエリだけでなく、この場合のすべてのクエリへの影響を定量化できる点です。これにより、他のクエリの検索結果の品質を犠牲にして、パフォーマンスの低いクエリを改善することが防止されます。リスクなしで迅速かつ安価に反復して仮説の価値を検証できるため、オフライン実験はすべての検索チームの基本的な機能になります。
評価者間の信頼性を測定する
タスクの説明、情報のニーズ、そして Quepid が提供するような人間の評価者インターフェースがあっても、人間の評価者の間で意見の相違が生じる可能性があります。
意見の相違自体は悪いことではありません。むしろその逆です。意見の相違を測定することで、取り組むべき問題が明らかになることがあります。関連性は主観的である可能性があり、クエリはあいまいであり、データは不完全または不正確である可能性があります。Fleiss の Kappaは評価者間の一致を測る統計的尺度であり、Quepid には使用できるサンプルノートブックがあります。これを見つけるには、最上位のナビゲーションで[ノートブック] を選択し、 例の フォルダーにあるノートブック Fleiss Kappa.ipynb を選択します。

まとめ
Quepid は、最も複雑な検索関連性の課題にも対処できるようにし、進化し続けています。バージョン 8 では、Quepid は AI 生成の判断をサポートしており、これは判断生成プロセスを拡大したいチームにとって特に便利です。
Quepid ワークフローを使用すると、スケーラブルな判断リストを効率的に作成できるため、最終的にはユーザーのニーズを真に満たす検索結果が得られます。判断リストを確立すると、検索の関連性を測定し、改善を繰り返し、ユーザー エクスペリエンスを向上させるための強固な基盤が得られます。
先に進む際には、関連性の調整は継続的なプロセスであることを忘れないでください。判断リストを使用すると進捗状況を体系的に評価できますが、実験、メトリック分析、反復的な改善と組み合わせると最も強力になります。
参考資料
- Quepid ドキュメント:
- Quepid Githubリポジトリ
- 電子商取引の検索を改善するブログシリーズ「Pete」
- 関連性Slack :#quepidチャンネルに参加する
Open Source Connections と提携して 検索機能と AI 機能を変革し、チームが継続的に進化できるようにします。当社の実績は世界中に広がっており、クライアントは一貫して検索品質、チーム能力、ビジネス パフォーマンスの劇的な改善を達成しています。詳細については、今すぐお問い合わせください。
よくあるご質問
Quepidとは?
Quepidは、ユーザーが検索結果の品質を測定し、オフライン実験を実行して改善できるようにするツールです。
Quepidではどのような種類の検索結果品質の実験を作成できますか?
Quepidでは、検索の関連性を向上させるため、クエリセットの構築、判定リストの作成、検索品質メトリクスの計算、計算された検索品質メトリクスに基づく異なる検索アルゴリズム/ランカーの比較などの多くの実験を実行できます。
QuepidとElasticsearchの使用方法
Query Sandboxを使用すると、迅速かつ安価に繰り返し処理できます。フィールドの重みを追加したり、スコアを上げたり、クエリロジックを変更したりして、それがElasticsearchのデータの検索品質指標(nDCGやDCG @10 など)にどのように影響するかをすぐに確認できます。
関連記事

最小スコアで意味的精度を確保
最小スコアしきい値を採用することで意味的精度を向上させます。この記事にはセマンティック検索とハイブリッド検索の具体的な例が含まれています。

2025年12月11日
判断リストによる検索クエリの関連性の評価
Elasticsearchで検索クエリの関連性を客観的に評価し、リコールなどのパフォーマンス指標を改善するための判断リストの構築方法を探ります。スケーラブルな検索のテストの拡張性についても学びます。

面倒な手間を省いたハイブリッド検索:リトリーバーによるハイブリッド検索の簡素化
線形および RRF リトリーバーのマルチフィールド クエリ形式を使用して Elasticsearch でのハイブリッド検索を簡素化する方法と、Elasticsearch インデックスに関する事前の知識なしでクエリを作成する方法について説明します。

コンテキストのためのYou Know - パート1:ハイブリッド検索とコンテキストエンジニアリングの進化
ハイブリッド検索とコンテキスト エンジニアリングが語彙の基礎からどのように進化し、次世代のエージェント AI ワークフローを可能にしたかを探ります。

ハイブリッド検索の再考: Elasticsearch の線形リトリーバーの導入!
線形リトリーバーが加重スコアと MinMax 正規化を活用してハイブリッド検索を強化し、より正確で一貫性のあるランキングを実現する方法を確認し、その使用方法を学びます。