この記事では、データの取り込みとインデックス作成のために Apache Kafka と Elasticsearch を統合する方法を説明します。Kafka の概要、プロデューサーとコンシューマーの概念について説明し、Apache Kafka を介してメッセージを受信してインデックスを作成するログ インデックスを作成します。このプロジェクトは Python で実装されており、コードはGitHubで入手できます。
要件
- Docker と Docker Compose: マシンに Docker と Docker Compose がインストールされていることを確認します。
- Python 3.x: Producer スクリプトと Consumer スクリプトを実行します。
Apache Kafka の紹介
Apache Kafka は、高いスケーラビリティと可用性、およびフォールト トレランスを実現する分散ストリーミング プラットフォームです。Kafka では、データ管理は次の主要コンポーネントを通じて行われます。
- ブローカー: プロデューサーとコンシューマー間のメッセージの保存と配信を担当します。
- Zookeeper : Kafka ブローカーを管理および調整し、クラスターの状態、パーティション リーダー、およびコンシューマー情報を制御します。
- トピック: データが公開され、消費のために保存されるチャネル。
- コンシューマーとプロデューサー: プロデューサーはトピックにデータを送信し、コンシューマーはそのデータを取得します。
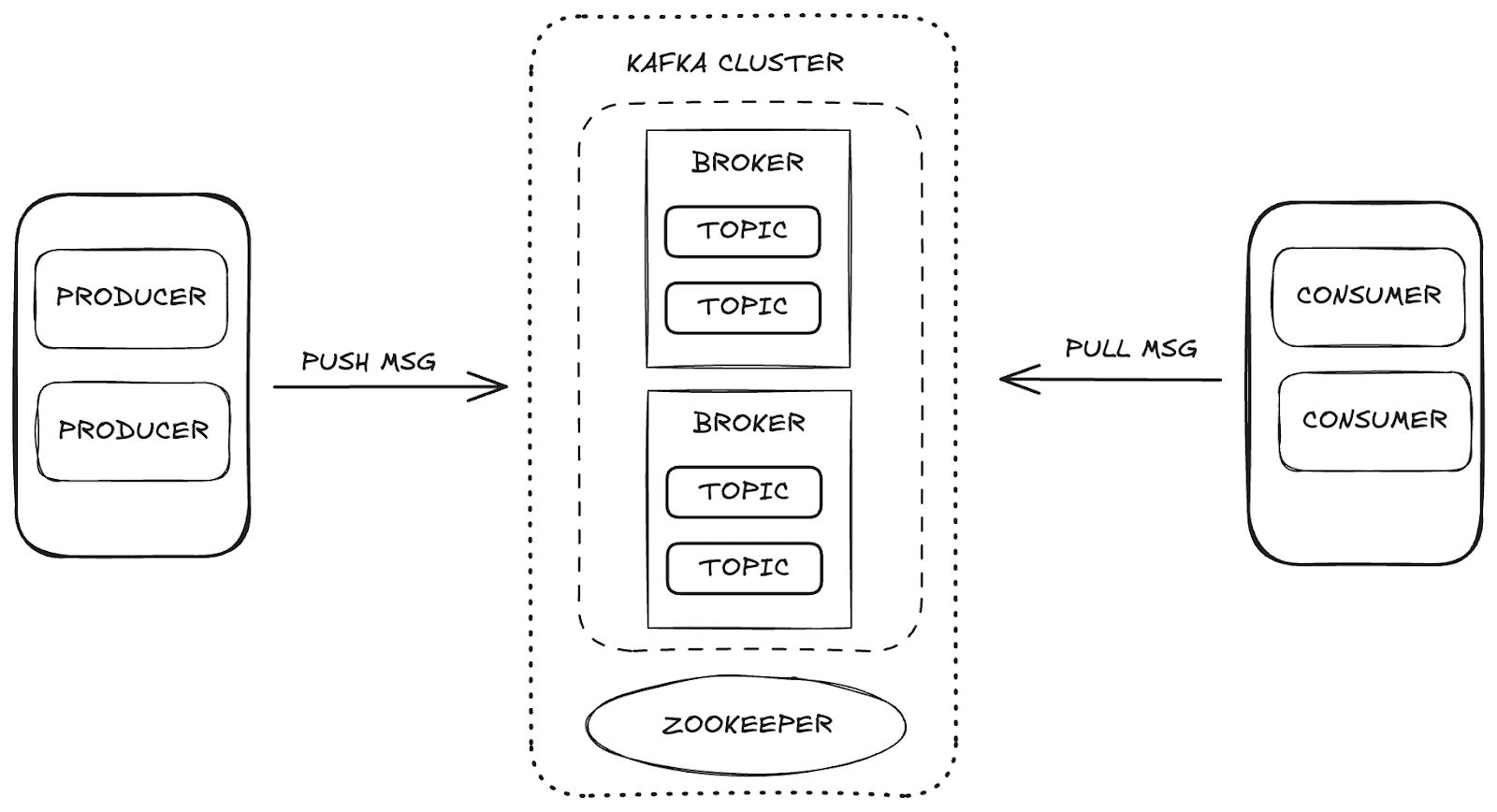
これらのコンポーネントは連携して Kafka エコシステムを形成し、データ ストリーミングのための堅牢なフレームワークを提供します。
プロジェクト構造
データ取り込みプロセスを理解するために、次の段階に分けました。
- インフラストラクチャのプロビジョニング: Kafka、Elasticsearch、Kibana をサポートするための Docker 環境をセットアップします。
- プロデューサーの作成: ログ トピックにデータを送信する Kafka プロデューサーを実装します。
- コンシューマーの作成: Elasticsearch でメッセージを読み取ってインデックスを作成する Kafka コンシューマーを開発します。
- 取り込み検証: 送信および消費されたデータを検証および検証します。
Docker Compose によるインフラストラクチャ構成
必要なサービスを構成および管理するために Docker Compose を利用しました。以下に、Apache Kafka、Elasticsearch、Kibana の統合に必要な各サービスを設定し、データ取り込みプロセスを確実に実行する Docker Compose コードを示します。
Elasticsearch Labs GitHubリポジトリから直接ファイルにアクセスできます。
Kafka Producerによるデータ送信
プロデューサーは、ログ トピックにメッセージを送信する責任を負います。メッセージをバッチで送信することで、ネットワークの使用効率が向上し、バッチの量と待ち時間をそれぞれ制御するbatch_sizeおよびlinger_ms設定による最適化が可能になります。構成acks='all'により、メッセージが永続的に保存されることが保証されます。これは重要なログ データにとって不可欠です。
プロデューサーを起動すると、次に示すように、メッセージがトピックにバッチで送信されます。
Kafka Consumerによるデータの消費とインデックス作成
コンシューマーは、ログ トピックからバッチを消費し、Elasticsearch にインデックスを付けることで、メッセージを効率的に処理するように設計されています。auto_offset_reset='latest'使用すると、コンシューマーが最新のメッセージの処理を開始し、古いメッセージを無視することが保証され、 max_poll_records=10バッチを 10 件のメッセージに制限します。fetch_max_wait_ms=2000の場合、コンシューマーはバッチを処理する前に十分なメッセージを蓄積するために最大 2 秒間待機します。
メイン ループでは、コンシューマーはログ メッセージを消費し、各バッチを処理して Elasticsearch にインデックス付けし、継続的なデータ取り込みを保証します。
Kibanaでデータを視覚化する
Kibana を使用すると、Kafka から取り込まれ Elasticsearch でインデックス化されたデータを探索および検証できます。Kibana のDev Toolsにアクセスすると、インデックス付けされたメッセージを表示し、データが期待どおりであることを確認できます。たとえば、Kafka プロデューサーが 10 件のメッセージを 5 つのバッチで送信した場合、インデックスには合計 50 件のレコードが表示されます。
データを検証するには、開発ツールセクションで次のクエリを使用できます。
対応:

さらに、Kibana は、分析をより直感的かつインタラクティブにするのに役立つ視覚化とダッシュボードを作成する機能を提供します。以下に、私たちが作成したダッシュボードと視覚化の例をいくつか示します。これらは、さまざまな形式でデータを示し、処理された情報に対する理解を深めます。

Kafka Connectによるデータ取り込み
Kafka Connect は、データベースやファイル システムなどのデータ ソースと宛先 (シンク) 間の統合を容易にするために設計されたサービスです。データの移動を自動的に処理する定義済みのコネクタを使用して動作します。私たちの場合、Elasticsearch はデータ シンクとして機能します。

Kafka Connect を使用すると、データ取り込みプロセスを簡素化できるため、Elasticsearch にデータ取り込みワークフローを手動で実装する必要がなくなります。適切なコネクタを使用すると、Kafka Connect では、追加のコーディングを必要とせず、最小限のセットアップで、Kafka トピックに送信されたデータを Elasticsearch で直接インデックス化できます。
Kafka Connect の操作
Kafka Connect を実装するには、Docker Compose セットアップにkafka-connect サービスを追加します。この構成の重要な部分は、データのインデックス作成を処理する Elasticsearch コネクタをインストールすることです。
サービスを設定し、Kafka Connect コンテナを作成した後、Elasticsearch コネクタの設定ファイルが必要になります。このファイルは次のような重要なパラメータを定義します。
connection.url: Elasticsearch の接続 URL。topics: コネクタが監視する Kafka トピック (この場合は「ログ」)。type.name: Elasticsearch のドキュメント タイプ (通常は _doc)。value.converter: Kafka メッセージを JSON 形式に変換します。value.converter.schemas.enable: スキーマを含めるかどうかを指定します。schema.ignoreおよびkey.ignore: インデックス作成中に Kafka スキーマとキーを無視する設定。
以下は、Kafka Connect で Elasticsearch コネクタを作成するためのcurlコマンドです。
この構成により、Kafka Connect は「logs」トピックに送信されたデータを自動的に取り込み、Elasticsearch でインデックス作成を開始します。このアプローチにより、追加のコーディングを必要とせずに完全に自動化されたデータの取り込みとインデックス作成が可能になり、統合プロセス全体が簡素化されます。
まとめ
Kafka と Elasticsearch を統合すると、リアルタイムのデータの取り込みと分析のための強力なパイプラインが作成されます。このガイドでは、Kibana でのシームレスな視覚化と分析を備えた堅牢なデータ取り込みアーキテクチャを構築するための基本的なアプローチを提供し、将来のより複雑な要件に適応できるようにします。
さらに、Kafka Connect を使用すると、Kafka と Elasticsearch の統合がさらに効率化され、データの処理やインデックス作成のための追加コードが不要になります。Kafka Connect を使用すると、最小限の構成で特定のトピックに送信されたデータを自動的に Elasticsearch にインデックス付けできます。
関連記事

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2025年9月22日
Elastic Open Web Crawler をコードとして
GitHub Actions を使用して Elastic Open Crawler の構成を管理する方法を学びます。これにより、リポジトリに変更をプッシュするたびに、その変更がクローラーのデプロイされたインスタンスに自動的に適用されます。

2025年8月6日
Elasticsearchインデックスのフィールドを表示する方法
_mapping および _search API、サブフィールド、合成 _source、およびランタイム フィールドを使用して Elasticsearch インデックスのフィールドを表示する方法を学習します。

