はじめに
この記事では、GPT-OSSと Elastic Agent Builder を使用して HR 向けの AI エージェントを構築する方法を説明します。エージェントは、OpenAI、Anthropic、その他の外部サービスにデータを送信せずに質問に答えることができます。
LM Studio を使用して GPT-OSS をローカルで提供し、Elastic Agent Builder に接続します。
この記事を読み終える頃には、情報とモデルを完全に制御しながら、従業員データに関する自然言語の質問に答えることができるカスタム AI エージェントが完成しているはずです。
要件
この記事には以下が必要です:
- Elastic Cloudホスト 9.2、サーバーレスまたはローカル展開
- 32GB RAM搭載マシンを推奨(GPT-OSS 20Bの場合は最低16GB)
- LM Studioがインストール済み
- Dockerデスクトップがインストール済み
GPT-OSS を使用する理由は何ですか?
ローカル LLM を使用すると、独自のインフラストラクチャに LLM を展開し、独自のニーズに合わせて微調整することができます。モデルと共有するデータの制御を維持しながら、これらすべてを実行できます。もちろん、外部プロバイダーにライセンス料を支払う必要はありません。
OpenAI は、オープン モデル エコシステムへの取り組みの一環として、2025 年 8 月 5 日にGPT-OSS をリリースしました。
20B パラメータ モデルは以下を提供します。
- ツール使用能力
- 効率的な推論
- OpenAI SDK対応
- エージェントワークフローと互換性あり
ベンチマーク比較:

ベンチマークソース。
ソリューションアーキテクチャ
アーキテクチャは完全にローカル マシン上で実行されます。Elastic (Docker で実行) は LM Studio を介してローカル LLM と直接通信し、Elastic Agent Builder はこの接続を使用して従業員データを照会できるカスタム AI エージェントを作成します。
詳細については、 こちらのドキュメントを参照してください。

HR向けAIエージェントの構築:手順
実装は 5 つのステップに分けられます。
- ローカルモデルでLMスタジオを構成する
- DockerでローカルElasticをデプロイする
- ElasticでOpenAIコネクタを作成する
- 従業員データをElasticsearchにアップロードする
- AIエージェントを構築してテストする
ステップ1:LM StudioをGPT-OSS 20Bで構成する
LM Studio は、大規模な言語モデルをコンピュータ上でローカルに実行できるユーザーフレンドリーなアプリケーションです。OpenAI 互換の API サーバーを提供するため、複雑なセットアップ プロセスなしで Elastic などのツールと簡単に統合できます。詳細については、 LM Studio ドキュメントを参照してください。
まず、公式サイトからLM Studioをダウンロードしてインストールします。インストールしたら、アプリケーションを開きます。
LM Studio インターフェースの場合:
- 検索タブに移動して「GPT-OSS」を検索します。
- OpenAIから
openai/gpt-oss-20bを選択してください - ダウンロードをクリック
このモデルのサイズは約12.10 GBになります。インターネット接続によっては、ダウンロードに数分かかる場合があります。

モデルをダウンロードしたら:
- ローカルサーバータブに移動します
- openai/gpt-oss-20bを選択します
- デフォルトのポート1234を使用する
- 右側のパネルで、 「ロード」に移動し、コンテキストの長さを40K以上に設定します。

5. サーバーの開始をクリック
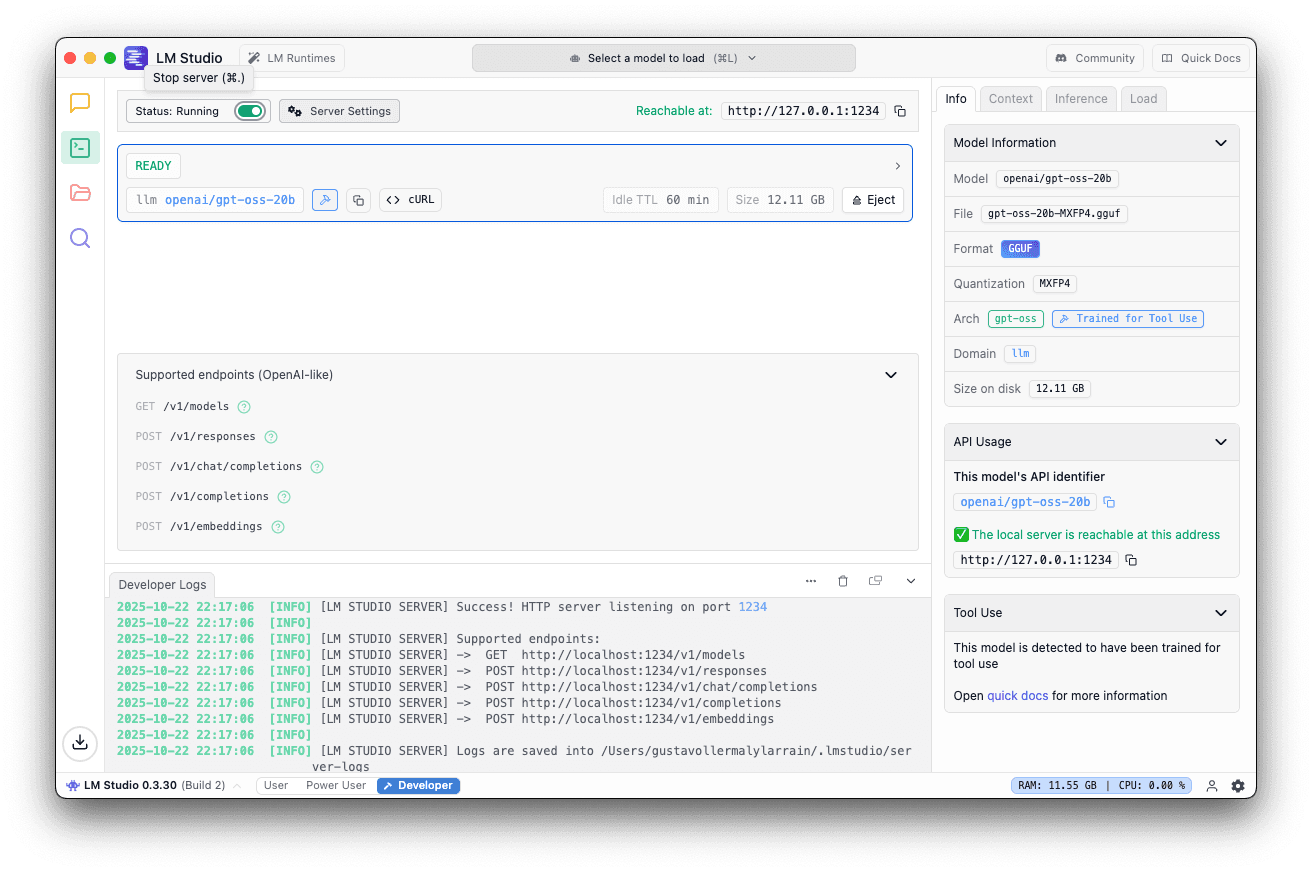
サーバーが実行中の場合はこれが表示されます。
ステップ2: DockerでローカルElasticをデプロイする
ここで、Docker を使用して Elasticsearch と Kibana をローカルにセットアップします。Elastic は、セットアッププロセス全体を処理する便利なスクリプトを提供します。詳細については、公式ドキュメントを参照してください。
start-local スクリプトを実行する
ターミナルで次のコマンドを実行します。
このスクリプトは次のことを行います。
- ElasticsearchとKibanaをダウンロードして設定する
- Docker Composeを使用して両方のサービスを開始します
- 30日間のプラチナトライアルライセンスを自動的に有効化
期待される出力
次のメッセージが表示されるまで待ち、表示されるパスワードと API キーを保存します。これらは Kibana にアクセスするために必要になります。
Kibanaにアクセスする
ブラウザを開いて次の場所に移動します:
ターミナル出力で取得した資格情報を使用してログインします。
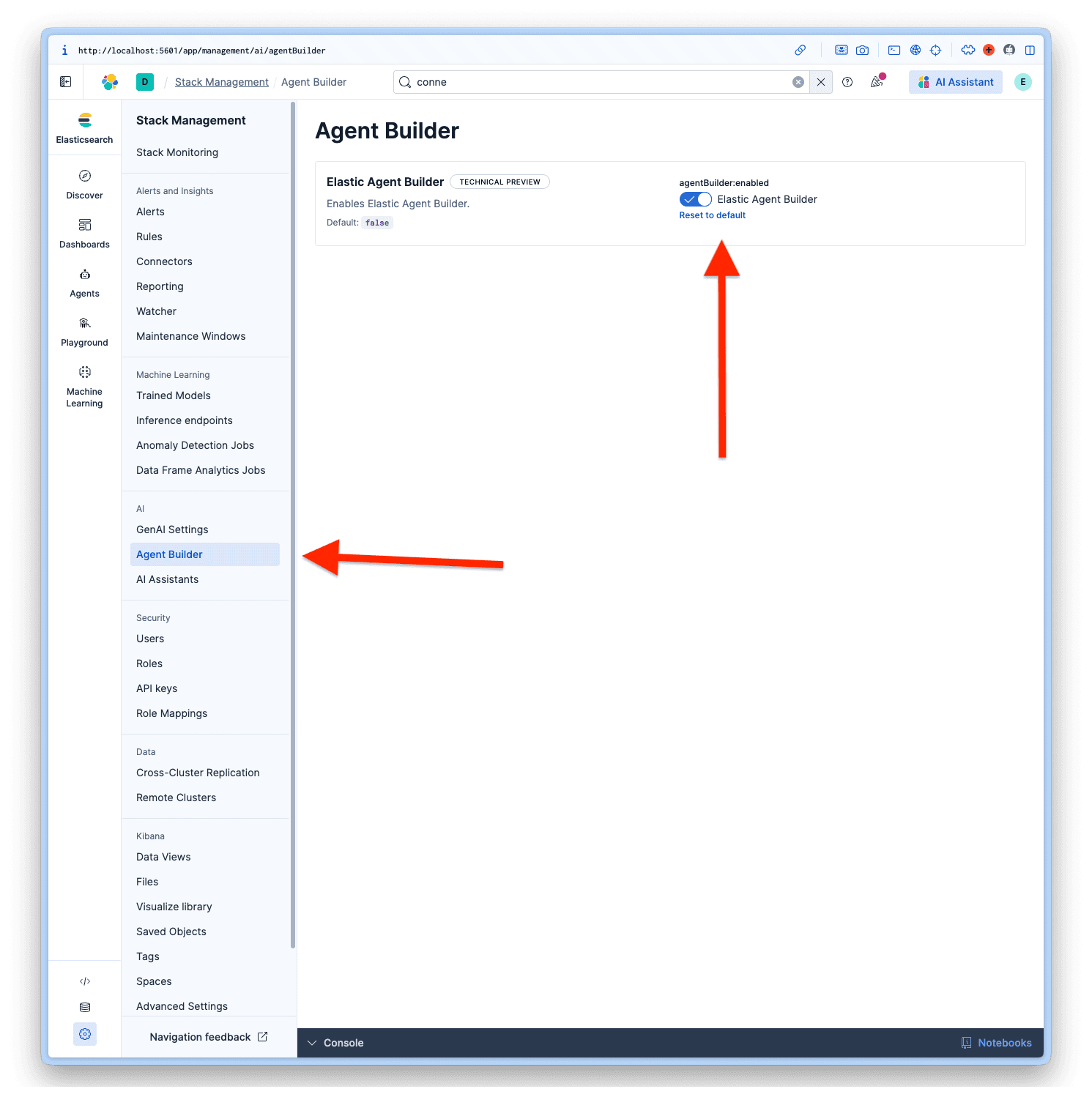
エージェントビルダーを有効にする
Kibana にログインしたら、 [Management] > [AI] > [Agent Builder]に移動して、Agent Builder をアクティブ化します。
ステップ3: ElasticでOpenAIコネクタを作成する
ここで、ローカル LLM を使用するように Elastic を構成します。
アクセスコネクタ
- キバナで
- プロジェクト設定>管理に移動します
- アラートとインサイトの下で、コネクタを選択します。
- コネクタの作成をクリック
コネクタを構成する
コネクタのリストからOpenAI を選択します。LM Studio は OpenAI SDK を使用しているため、互換性があります。

次の値をフィールドに入力します。
- コネクタ名: LM Studio - GPT-OSS 20B
- OpenAIプロバイダーを選択:その他 (OpenAI互換サービス)
- URL:
http://host.docker.internal:1234/v1/chat/completions - デフォルトモデル: openai/gpt-oss-20b
- API キー: testkey-123 (LM Studio Server では認証が不要なので、任意のテキストを使用できます。)

設定を完了するには、 「保存してテスト」をクリックします。
重要: 「ネイティブ関数の呼び出しを有効にする」をオンにします。これは、Agent Builder が正しく動作するために必要です。これを有効にしないと、 No tool calls found in the responseエラーが発生します。
接続をテストする
Elastic は自動的に接続をテストするはずです。すべてが正しく構成されている場合、次のような成功メッセージが表示されます。

対応:
ステップ4: 従業員データをElasticsearchにアップロードする
ここで、 HR 従業員データセットをアップロードして、エージェントが機密データをどのように処理するかを説明します。私はこの構造を持つ架空のデータセットを生成しました。
データセットの構造
マッピングを使用してインデックスを作成する
まず、適切なマッピングを使用してインデックスを作成します。一部のキー フィールドにsemantic_textフィールドを使用していることに注意してください。これにより、インデックスのセマンティック検索機能が有効になります。
Bulk APIを使用したインデックス
データセットをコピーして Kibana の開発ツールに貼り付け、実行します。
データを検証する
クエリを実行して確認します。
ステップ5: AIエージェントを構築してテストする
すべての設定が完了したら、Elastic Agent Builder を使用してカスタム AI エージェントを構築します。詳細については、 Elastic のドキュメントを参照してください。
コネクタを追加する
新しいエージェントを作成する前に、デフォルトのコネクタはElastic Managed LLMであるため、 LM Studio - GPT-OSS 20Bというカスタム コネクタを使用するようにエージェント ビルダーを設定する必要があります。そのためには、 「プロジェクト設定」 > 「管理」 > 「GenAI 設定」に移動し、作成した設定を選択して「保存」をクリックします。

アクセスエージェントビルダー
- エージェントへ
- 「新しいエージェントを作成」をクリックします

エージェントを構成する
新しいエージェントを作成するには、エージェント ID 、表示名、および表示手順が必須フィールドです。
ただし、システム プロンプトに似ていますが、カスタム エージェント用の、エージェントの動作やツールとの対話方法をガイドするカスタム インストラクションなど、さらに多くのカスタマイズ オプションがあります。ラベルは、エージェント、アバターの色、アバター シンボルを整理するのに役立ちます。
データセットに基づいてエージェント用に選択したものは次のとおりです。
エージェントID: hr_assistant
カスタム指示:
ラベル: Human Resourcesおよび GPT-OSS
表示名: HR Analytics Assistant
表示の説明:

すべてのデータが入力されたら、新しいエージェントの「保存」をクリックします。
エージェントをテストする
従業員データについて自然言語で質問できるようになり、GPT-OSS 20B が意図を理解して適切な応答を生成します。
プロンプト:
答え:

エージェントのプロセスは次のとおりです。
1. GPT-OSSコネクタを使用して質問を理解する
2. 適切なElasticsearchクエリを生成する(組み込みツールまたはカスタムES|QLを使用)
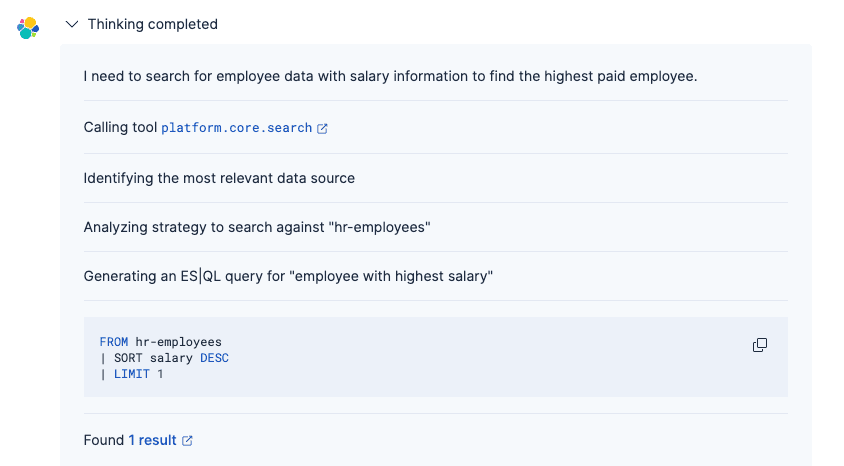
3. 一致する従業員レコードを取得する
4. 適切なフォーマットで自然言語で結果を提示する
従来の語彙検索とは異なり、GPT-OSS を搭載したエージェントは意図とコンテキストを理解するため、正確なフィールド名やクエリ構文を知らなくても情報を簡単に見つけることができます。エージェントの思考プロセスの詳細については、こちらの記事を参照してください。
まとめ
この記事では、Elastic の Agent Builder を使用してカスタム AI エージェントを構築し、ローカルで実行されている OpenAI GPT-OSS モデルに接続しました。このアーキテクチャでは、Elastic と LLM の両方をローカルマシンにデプロイすることで、外部サービスに情報を送信することなく、データに対する完全な制御を維持しながら生成 AI 機能を活用できます。
実験としてはGPT-OSS 20Bを使用しましたが、Elastic Agent Builderの公式推奨モデルはこちらを参考にしています。より高度な推論機能が必要な場合は、複雑なシナリオでより優れたパフォーマンスを発揮する120B パラメータ バリアントもありますが、ローカルで実行するにはより高性能なマシンが必要です。詳細については、 OpenAI の公式ドキュメントを参照してください。
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。