Apache Airflow とは何ですか?
Apache Airflow は、ワークフローを作成、スケジュール、監視するために設計されたプラットフォームです。ETL プロセス、データ パイプライン、その他の複雑なワークフローを調整するために使用され、柔軟性とスケーラビリティを提供します。視覚的なインターフェースとリアルタイムの監視機能により、パイプライン管理がよりアクセスしやすく効率的になり、実行の進行状況と結果を追跡できるようになります。その 4 つの主な柱は次のとおりです。
- 動的:パイプラインは Python で定義され、動的かつ柔軟なワークフロー生成が可能になります。
- 拡張可能: Airflow はさまざまな環境と統合でき、カスタム オペレーターを作成し、必要に応じて特定のコードを実行できます。
- エレガント:パイプラインは、明確かつ明示的に記述されます。
- スケーラブル:モジュール型アーキテクチャは、メッセージ キューを使用して任意の数のワーカーを調整します。
実際には、Airflow は次のようなシナリオで使用できます。
- データのインポート: Elasticsearch などのデータベースへの毎日のデータの取り込みを調整します。
- ログ監視:ログ ファイルの収集と処理を管理し、Elasticsearch で分析してエラーや異常を特定します。
- 複数のデータ ソースの統合:さまざまなシステム (API、データベース、ファイル) からの情報を Elasticsearch の 1 つのレイヤーに統合し、検索とレポートを簡素化します。
Airflow における DAG (有向非巡回グラフ) の理解
Airflow では、ワークフローは DAG (有向非巡回グラフ) によって表されます。DAG は、タスクが実行される順序を定義する構造です。DAG の主な特徴は次のとおりです。
- 独立したタスクによる構成:各タスクは作業単位を表し、独立して実行されるように設計されています。
- シーケンス:タスクが実行されるシーケンスは、DAG で明示的に定義されます。
- 再利用性: DAG は繰り返し実行されるように設計されており、プロセスの自動化を容易にします。
エアフローコンポーネント
Airflow エコシステムは、タスクを調整するために連携して動作する複数のコンポーネントで構成されています。
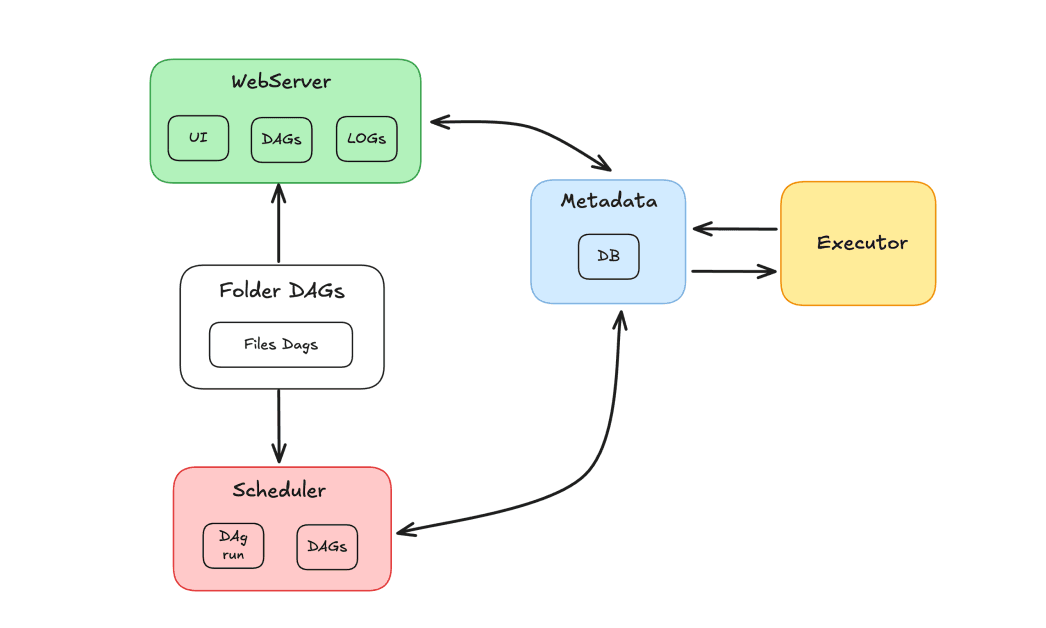
- スケジューラ: DAG のスケジュール設定と、ワーカーによる実行のためにタスクの送信を担当します。
- 実行者:タスクの実行を管理し、それをワーカーに委任します。
- Web サーバー: DAG およびタスクと対話するためのグラフィカル インターフェイスを提供します。
- Dags フォルダー: Python で記述された DAG を保存するフォルダー。
- メタデータ:ツールのリポジトリとして機能するデータベース。スケジューラとエグゼキュータによって実行ステータスを保存するために使用されます。
Apache Airflow と Elasticsearch
Apache Airflow と Elasticsearch を使用してタスクをオーケストレーションし、Elasticsearch で結果をインデックスする方法を紹介します。このデモの目的は、Elasticsearch インデックス内のレコードを更新するタスクのパイプラインを作成することです。このインデックスには映画のデータベースが含まれており、ユーザーは評価したり評価を割り当てたりすることができます。毎日何百もの評価があるシナリオを想像すると、評価記録を最新の状態に保つことが必要になります。これを実現するために、毎日実行され、新しい統合評価を取得してインデックス内のレコードを更新する役割を担う DAG が開発されます。
DAG フローでは、評価を取得するタスクがあり、その後に結果を検証するタスクが続きます。データが存在しない場合は、DAG は失敗タスクに送られます。それ以外の場合、データは Elasticsearch でインデックス化されます。目標は、スコアを計算するメカニズムを備えたメソッドを通じて評価を取得し、インデックス内の映画の評価フィールドを更新することです。
Docker で Apache Airflow と Elasticsearch を使用する
コンテナ化された環境を作成するには、Docker と Apache Airflow を使用します。Airflow を実際的に設定するには、 「Docker で Airflow を実行する」ガイドの指示に従ってください。
Elasticsearch に関しては、Elastic Cloud 上のクラスターを使用しますが、必要に応じて Docker を使用して Elasticsearch を構成することもできます。映画カタログを含むインデックスがすでに作成されており、映画データがインデックス化されています。これらの映画の「評価」フィールドが更新されます。
DAGの作成
Docker 経由でインストールすると、dags フォルダーを含むフォルダー構造が作成されます。Airflow が認識できるように、ここに DAG ファイルを配置する必要があります。
その前に、必要な依存関係がインストールされていることを確認する必要があります。このプロジェクトの依存関係は次のとおりです。
ファイルupdate_ratings_movies.pyを作成し、タスクのコーディングを開始します。
次に、必要なライブラリをインポートします。
接続と外部 API の使用を抽象化することで、Airflow と Elasticsearch クラスター間の統合を簡素化するコンポーネントであるElasticsearchPythonHookを使用します。
次に、主な引数を指定して DAG を定義します。
dag_id: DAG の名前。start_date: DAG が開始される時刻。schedule: 周期性を定義します (この場合は毎日)。doc_md: Airflow インターフェースにインポートされ表示されるドキュメント。
タスクの定義
それでは、DAG のタスクを定義しましょう。最初のタスクは、映画の評価データを取得することです。task_idを'get_movie_ratings'に設定したPythonOperatorを使用します。python_callableパラメータは、評価を取得する関数を呼び出します。
次に、結果が有効かどうかを検証する必要があります。このため、 BranchPythonOperatorを使用した条件文を使用します。task_idは'validate_result'になり、 python_callableは検証関数を呼び出します。op_argsパラメータは、前のタスクの結果'get_movie_ratings'を検証関数に渡すために使用されます。
検証が成功した場合、 'get_movie_ratings'タスクからデータを取得して Elasticsearch にインデックス付けします。これを実現するには、 PythonOperatorを使用する新しいタスク'index_movie_ratings'を作成します。op_argsパラメータは、 'get_movie_ratings'タスクの結果をインデックス作成関数に渡します。
検証で失敗が示された場合、DAG は失敗通知タスクに進みます。この例では、単にメッセージを印刷しますが、実際のシナリオでは、障害について通知するアラートを設定できます。
最後に、タスクの依存関係を定義し、正しい順序で実行されるようにします。
次に、DAG の完全なコードを示します。
DAG実行の視覚化
Apache Airflow インターフェースでは、DAG の実行を視覚化できます。「DAG」タブに移動して、作成した DAG を見つけるだけです。
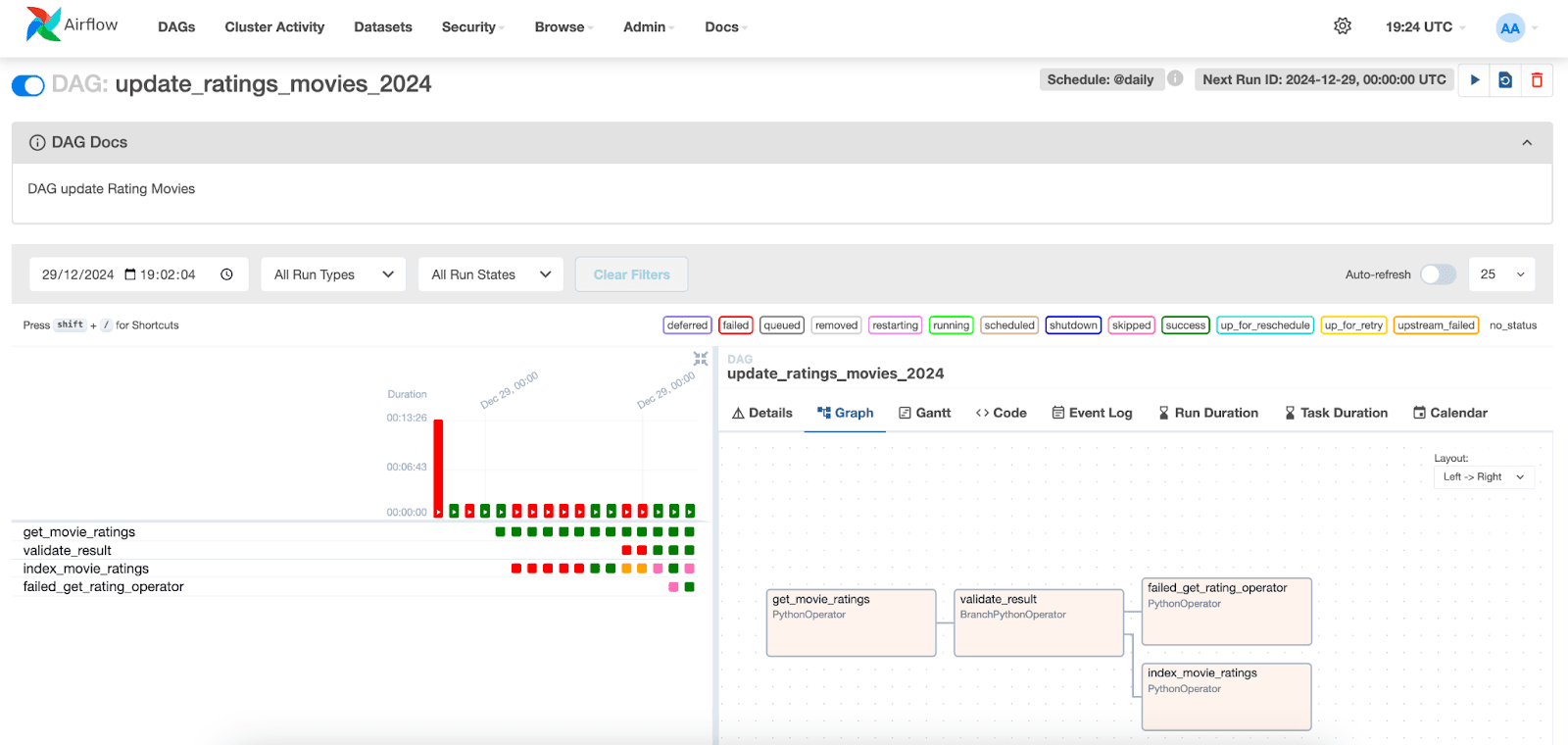
以下では、タスクの実行とそれぞれのステータスを視覚化できます。特定の日付の実行を選択すると、各タスクのログにアクセスできます。index_movie_ratingsタスクでは、インデックス内のインデックス作成結果が表示され、正常に完了したことがわかります。

他のタブでは、タスクと DAG に関する追加情報にアクセスでき、潜在的な問題の分析と解決に役立ちます。
まとめ
この記事では、Apache Airflow と Elasticsearch を統合してデータ取り込みソリューションを作成する方法を説明しました。DAG を構成し、映画データの取得、検証、インデックス作成を担当するタスクを定義する方法と、Airflow インターフェースでこれらのタスクの実行を監視および視覚化する方法を示しました。
このアプローチはさまざまな種類のデータやワークフローに簡単に適応できるため、Airflow はさまざまなシナリオでデータ パイプラインをオーケストレーションするための便利なツールになります。
参照資料
Apacheエアフロー
DockerでApache Airflowをインストールする
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
Elasticsearch Pythonフック
Python演算子
https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html
よくあるご質問
Apache Airflow とは何ですか?
Apache Airflow は、ワークフローを作成、スケジュール、監視するために設計されたプラットフォームです。
Apache Airflow は何に使用されますか?
Apache Airflow は、ETL プロセス、データ パイプライン、その他の複雑なワークフローを調整するために使用され、柔軟性とスケーラビリティを提供します。
Apache Airflow の主なコンポーネントは何ですか?
Airflow の主なコンポーネントは、スケジューラ、エグゼキュータ、Web サーバー、Dags フォルダ、メタデータです。
Apache Airflow を Elasticsearch と統合できますか?
はい、Apache Airflow は Elasticsearch と統合できます。たとえば、Apache Airflow を使用してタスクをオーケストレーションし、Elasticsearch で結果をインデックス化できます。
Apache Airflow における DAG とは何ですか?
Airflow では、ワークフローは DAG (有向非巡回グラフ) によって表されます。DAG は、タスクが実行される順序を定義する構造です。
関連記事

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2025年9月22日
Elastic Open Web Crawler をコードとして
GitHub Actions を使用して Elastic Open Crawler の構成を管理する方法を学びます。これにより、リポジトリに変更をプッシュするたびに、その変更がクローラーのデプロイされたインスタンスに自動的に適用されます。

2025年8月6日
Elasticsearchインデックスのフィールドを表示する方法
_mapping および _search API、サブフィールド、合成 _source、およびランタイム フィールドを使用して Elasticsearch インデックスのフィールドを表示する方法を学習します。

