L'une des principales difficultés rencontrées lors de l'utilisation de modèles d'apprentissage par classement est la création d'une liste de jugements de haute qualité pour entraîner le modèle. Traditionnellement, ce processus implique une évaluation manuelle de la pertinence des requêtes et des documents afin d'attribuer une note à chacun d'entre eux. Il s'agit d'un processus lent, peu évolutif et difficile à maintenir (imaginez que vous deviez mettre à jour à la main une liste comportant des centaines d'entrées).
Et si nous pouvions utiliser les interactions réelles des utilisateurs avec notre application de recherche pour créer ces données d'entraînement ? L'utilisation des données UBI nous permet justement de le faire. Créer un système automatique capable de capturer et d'utiliser nos recherches, nos clics et autres interactions pour générer une liste de jugement. Ce processus peut être mis à l'échelle et répété beaucoup plus facilement qu'une interaction manuelle et tendrait à donner de meilleurs résultats. Dans ce blog, nous allons explorer comment nous pouvons interroger les données UBI stockées dans Elasticsearch pour calculer des signaux significatifs afin de générer un ensemble de données d'entraînement pour un modèle LTR.
L'expérience complète est disponible ici.
Pourquoi les données UBI peuvent-elles être utiles pour entraîner votre modèle LTR ?
Les données UBI offrent plusieurs avantages par rapport à une annotation manuelle :
- Le volume : Étant donné que les données UBI proviennent d'interactions réelles, nous pouvons collecter beaucoup plus de données que nous ne pouvons en générer manuellement. Cela suppose que nous ayons suffisamment de trafic pour générer ces données, bien entendu.
- L'intention de l'utilisateur réel : Traditionnellement, une liste de jugement manuel provient d'une évaluation experte des données disponibles. D'autre part, les données UBI reflètent le comportement réel des utilisateurs. Cela signifie que nous pouvons générer de meilleures données de formation qui amélioreront la précision de notre système de recherche, car elles sont basées sur la façon dont les utilisateurs interagissent réellement avec votre contenu et y trouvent de la valeur, plutôt que sur des hypothèses théoriques sur ce qui devrait être pertinent.
- Mises à jour permanentes : Les listes de jugement doivent être actualisées au fil du temps. Si nous les créons à partir des données de l'UBI, nous pouvons disposer de données actualisées qui se traduisent par des listes de jugement mises à jour.
- Rentabilité : Sans les frais généraux liés à la création manuelle d'une liste de jugement, le processus peut être répété efficacement un nombre illimité de fois.
- Distribution naturelle des requêtes: Les données UBI représentent les requêtes réelles des utilisateurs, ce qui peut entraîner des changements plus profonds. Par exemple, nos utilisateurs utilisent-ils le langage naturel pour effectuer des recherches dans notre système ? Si c'est le cas, nous pourrions vouloir mettre en œuvre une recherche sémantique ou une approche de recherche hybride.
Elle s'accompagne toutefois de quelques mises en garde :
- Amplification des biais : Un contenu populaire est plus susceptible de recevoir des clics, simplement parce qu'il est plus exposé. Cela pourrait donc avoir pour effet d'amplifier les articles les plus populaires et d'étouffer les meilleures options.
- Couverture incomplète : Le nouveau contenu n'a pas d'interactions, il peut donc être difficile pour lui de figurer en bonne place dans les résultats. Les requêtes rares peuvent également ne pas comporter suffisamment de points de données pour créer des données de formation significatives.
- Variations saisonnières : Si vous vous attendez à ce que le comportement de l'utilisateur change radicalement au fil du temps, les données historiques risquent de ne pas vous donner beaucoup d'indications sur ce qui constitue un bon résultat.
- Ambiguïté de la tâche : Un clic ne garantit pas toujours que l'utilisateur a trouvé ce qu'il cherchait.
Calcul des notes
Grades pour la formation LTR
Pour former les modèles LTR, nous devons fournir une représentation numérique de la pertinence d'un document par rapport à une requête. Dans notre application, ce nombre est un score continu allant de 0,0 à 5,0+, les scores les plus élevés indiquant une plus grande pertinence.
Pour illustrer le fonctionnement de ce système de classement, prenons l'exemple suivant, créé manuellement :
| Requête | Contenu du document | Grade | Explication |
|---|---|---|---|
| "meilleure recette de pizza" | "Recette de pâte à pizza italienne authentique avec photos étape par étape" | 4.0 | Très pertinent, exactement ce que l'utilisateur recherche |
| "meilleure recette de pizza" | "Histoire de la pizza en Italie" | 1.0 | Un peu dans le sujet, il s'agit de pizza mais ce n'est pas une recette. |
| "meilleure recette de pizza" | "Recette de pizza en 15 minutes pour les débutants" | 3.0 | C'est un bon résultat, mais il ne s'agit peut-être pas de la "meilleure" recette. |
| "meilleure recette de pizza" | "Guide d'entretien des voitures" | 0.0 | Pas du tout pertinent, sans aucun rapport avec la requête |
Comme nous pouvons le voir ici, la note est une représentation numérique de la pertinence d'un document par rapport à notre exemple de requête "meilleure recette de pizza". Grâce à ces scores, notre modèle LTR peut apprendre quels documents devraient être présentés plus haut dans les résultats.
La manière de calculer les notes est au cœur de notre ensemble de données de formation. Il existe plusieurs approches pour y parvenir, chacune ayant ses propres forces et faiblesses. Par exemple, nous pourrions attribuer un score binaire de 1 pour pertinent, 0 pour non pertinent, ou nous pourrions simplement compter le nombre de clics dans un document résultant pour chaque requête.
Dans cet article de blog, nous utiliserons une approche différente, en prenant en compte le comportement de l'utilisateur en tant qu'entrée et en calculant un nombre de notes en tant que sortie. Nous corrigerons également le biais qui pourrait résulter du fait que les résultats les plus élevés ont tendance à être davantage cliqués, quelle que soit la pertinence du document.
Calcul des notes - algorithme COEC
L'algorithme COEC(Clicks over Expected Clicks) est une méthodologie permettant de calculer les notes de jugement à partir des clics des utilisateurs.
Comme nous l'avons indiqué précédemment, les utilisateurs ont tendance à cliquer sur les résultats les mieux positionnés, même si le document n'est pas le plus pertinent par rapport à la requête ; c'est ce que l'on appelle le biais de position. L'idée centrale de l'utilisation de l'algorithme COEC est que tous les clics n'ont pas la même importance ; un clic sur un document en position 10 indique que ce document est beaucoup plus pertinent pour la requête qu'un clic sur un document en position 1. Pour citer le document de recherche sur l'algorithme COEC (lien ci-dessus) :
"Il est bien connu que le taux de clics (CTR) des résultats de recherche ou des publicités diminue de manière significative en fonction de la position des résultats."
Pour en savoir plus sur les préjugés de position , cliquez ici.
Pour résoudre ce problème avec l'algorithme COEC, nous suivons les étapes suivantes :
1. Établir des valeurs de référence pour les positions : Nous calculons le taux de clics (CTR) pour chaque position de recherche de 1 à 10. Cela signifie que nous déterminons le pourcentage d'utilisateurs qui cliquent généralement sur la position 1, la position 2, etc. Cette étape permet de prendre en compte les préférences naturelles des utilisateurs en matière de position.
Nous calculons le CTR en utilisant :
Où ?
p = Position. De 1 à 10
Cp = Nombre total de clics (sur n'importe quel document) à la position p sur l'ensemble des requêtes
Ip = Nombre total d'impressions : Nombre de fois qu'un document est apparu à la position p sur l'ensemble des requêtes.
Dans ce cas, nous nous attendons à ce que les positions les plus élevées donnent lieu à davantage de clics.
2. Calculer les clics attendus (EC):
Cette mesure détermine le nombre de clics qu'un document "aurait dû" recevoir sur la base des positions dans lesquelles il est apparu et du CTR pour ces positions. Nous calculons la CE à l'aide de :
Où ?
Qd = Toutes les requêtes dans lesquelles le document d est apparu
pos(d,q)= Position du document d dans les résultats de la requête q
3. Compter les clics réels : Nous comptons le nombre total de clics qu'un document a reçus pour toutes les requêtes où il est apparu, ci-après dénommé A(d).
4. Calculer le score COEC : Il s'agit du rapport entre les clics réels (A(d)) et les clics attendus (EC(d)) :
Cette métrique normalise le biais de position de la manière suivante :
- Un score de 1,0 signifie que le document s'est comporté exactement comme prévu compte tenu des positions dans lesquelles il est apparu.
- Un score supérieur à 1,0 signifie que le document a obtenu de meilleurs résultats que prévu en examinant ses positions. Ce document est donc plus pertinent pour la requête.
- Un score inférieur à 1,0 signifie que le document a obtenu de moins bons résultats que prévu, compte tenu de ses positions. Ce document est donc moins pertinent pour la requête.
Le résultat final est une note qui reflète ce que les utilisateurs recherchent, en tenant compte des attentes basées sur la position, extraites des interactions réelles avec notre système de recherche.
Mise en œuvre technique
Nous allons créer un script pour créer une liste de jugements afin d'entraîner un modèle LTR.
L'entrée de ce script est constituée des données UBI indexées dans Elastic (requêtes et événements).
Le résultat est une liste de jugements dans un fichier CSV généré à partir de ces documents UBI en utilisant l'algorithme COEC. Cette liste de jugements peut être utilisée avec Eland pour extraire les caractéristiques pertinentes et former un modèle LTR.
Démarrage rapide
Pour générer une liste de jugement à partir de l'échantillon de données présenté dans ce blog, vous pouvez suivre les étapes suivantes :
1. Clonez le référentiel :
2. Installer les bibliothèques nécessaires
Pour ce script, nous avons besoin des bibliothèques suivantes :
- pandas: pour sauvegarder la liste des jugements
- elasticsearch: Pour obtenir les données UBI à partir de notre déploiement Elastic
Nous avons également besoin de Python 3.11
3. Mettez à jour les variables d'environnement pour votre déploiement Elastic dans un fichier .env
- ES_HOST
- API_KEY
Pour ajouter les variables d'environnement, utilisez :
4. Créez les index ubi_queries et ubi_events, et téléchargez les échantillons de données. Exécutez le fichier setup.py :
5. Exécutez le script Python :
Si vous suivez ces étapes, vous devriez voir apparaître un nouveau fichier appelé judgment_list.csv qui ressemble à ceci :
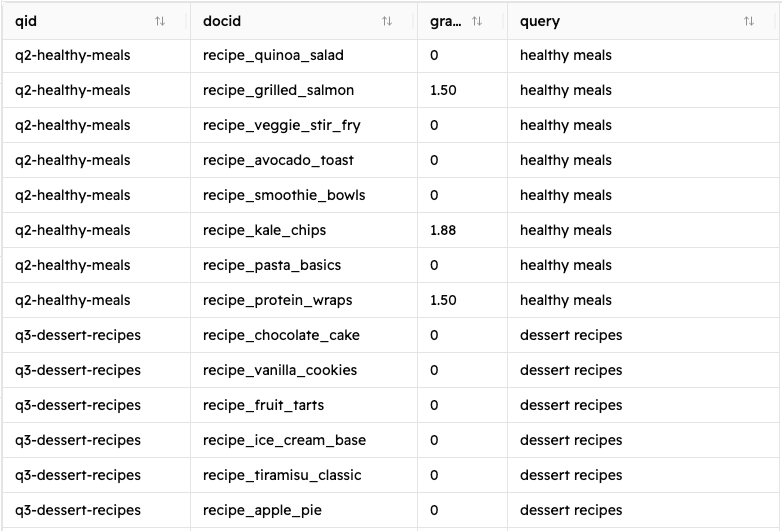
Ce script calcule les notes en appliquant l'algorithme COEC évoqué précédemment à l'aide de la fonction calculate_relevance_grade() présentée ci-dessous.
Architecture des données
Requêtes Ubi
Notre index des requêtes UBI contient des informations sur les requêtes exécutées dans notre système de recherche. Il s'agit d'un document type :
Ici, nous pouvons voir les données de l'utilisateur (client_id), les résultats de la requête (query_response_object_ids) et la requête elle-même (timestamp, user_query).
Événements de clics Ubi
Notre index ubi_events contient des données à chaque fois qu'un utilisateur a cliqué sur un document dans les résultats. Il s'agit d'un document type :
Script de génération de listes d'arrêts
Aperçu général du script
Ce script automatise la génération de la liste de jugement en utilisant les données UBI des requêtes et des événements de clics stockés dans Elasticsearch. Il exécute ces tâches :
- Récupère et traite les données UBI dans Elasticsearch.
- Corréler les événements UBI avec ses requêtes.
- Calcule le CTR pour chaque position.
- Calcule le nombre de clics attendus (EC) pour chaque document.
- Compte les clics réels pour chaque document.
- Calcule le score COEC pour chaque paire requête-document.
- Génère une liste de jugements et l'écrit dans un fichier CSV.
Passons en revue chaque fonction :
connect_to_elasticsearch()
Cette fonction renvoie un objet client Elasticsearch en utilisant l'hôte et la clé api.
fetch_ubi_data()
Cette fonction est la couche d'extraction des données ; elle se connecte à Elasticsearch pour récupérer les requêtes UBI à l'aide d'une requête match_all et filtre les événements UBI pour obtenir uniquement les événements "CLICK_THROUGH".
process_ubi_data()
Cette fonction gère la génération de la liste des jugements. Il commence à traiter les données UBI en associant les événements UBI et les requêtes. Il appelle ensuite la fonction calculate_relevance_grade() pour chaque paire document-requête afin d'obtenir les entrées de la liste de jugement. Enfin, il renvoie la liste résultante sous la forme d'un cadre de données pandas.
calculer_la_relevance_de_la_grade()
Il s'agit de la fonction qui met en œuvre l'algorithme COEC. Il calcule le CTR pour chaque position, puis compare les clics réels pour une paire document-requête, et enfin calcule le score COEC réel pour chacun d'entre eux.
generate_judgment_statistics()
Il génère des statistiques utiles à partir de la liste de jugement, telles que le nombre total de requêtes, le nombre total de documents uniques ou la distribution des notes. Il s'agit d'une information purement informative qui ne modifie pas la liste de jugement qui en résulte.
Résultats et impact
Si vous suivez les instructions de la section Démarrage rapide, vous devriez obtenir un fichier CSV contenant une liste de jugements de 320 entrées (vous pouvez voir un exemple de sortie dans le répertoire). Avec ces champs :
- qid : identifiant unique de la requête
- docid : identifiant unique du document résultant
- note : la note calculée pour la paire requête-document
- requête : La requête de l'utilisateur
Examinons les résultats de la requête "recettes italiennes" :
| qid | docid | grade | Requête |
|---|---|---|---|
| q1-italien-recettes | recette_pasta_basics | 0.0 | Recettes italiennes |
| q1-italien-recettes | recette_pizza_margherita | 3.333333 | Recettes italiennes |
| q1-italien-recettes | guide_recette_risotto_guide | 10.0 | Recettes italiennes |
| q1-italien-recettes | recette_french_croissant | 0.0 | Recettes italiennes |
| q1-italien-recettes | recette_paella_espagnole | 0.0 | Recettes italiennes |
| q1-italien-recettes | recette_greek_moussaka | 1.875 | Recettes italiennes |
Nous pouvons voir dans les résultats que pour la requête "recettes italiennes" :
- La recette de risotto est sans aucun doute le meilleur résultat pour la requête, recevant 10 fois plus de clics que prévu
- La pizza Margherita est également un excellent résultat.
- La mousaka grecque (surprenante) est également un bon résultat et se comporte mieux que ne le laisse supposer sa position dans les résultats. Cela signifie que quelques utilisateurs recherchant des recettes italiennes ont été intéressés par cette recette à la place. Ces utilisateurs sont peut-être intéressés par les plats méditerranéens en général. En fin de compte, cela nous indique qu'il pourrait s'agir d'un bon résultat à présenter dans le cadre des deux autres "meilleurs" matches dont nous avons parlé plus haut.
Conclusion
L'utilisation des données UBI nous permet d'automatiser l'apprentissage des modèles LTR, en créant des listes de jugement de haute qualité à partir de nos propres utilisateurs. En utilisant l'algorithme COEC pour générer les notes, nous tenons compte des biais inhérents tout en reflétant ce qu'un utilisateur considère comme un meilleur résultat. La méthode décrite ici peut être appliquée à des cas d'utilisation réels afin d'offrir une meilleure expérience de recherche qui évolue en fonction des tendances d'utilisation réelles.
Pour aller plus loin

4 novembre 2025
Recherche multimodale de sommets avec Elasticsearch et SigLIP-2
Apprenez à mettre en œuvre la recherche multimodale texte-image et image-image en utilisant les encastrements SigLIP-2 et la recherche vectorielle Elasticsearch kNN. Objectif du projet : trouver des photos du sommet du mont Ama Dablam prises lors d'un trekking dans l'Everest.

Recherche géospatiale Elasticsearch avec ES|QL
Recherche géospatiale dans le langage de requête Elasticsearch (ES|QL). Elasticsearch possède de puissantes fonctionnalités de recherche géospatiale, qui sont désormais intégrées à ES|QL pour une facilité d'utilisation et une familiarité avec l'OGC considérablement améliorées.

16 juillet 2024
Évaluation de la pertinence des recherches, partie 1 - Le benchmark BEIR
Apprenez à évaluer votre système de recherche dans le cadre d'une meilleure compréhension du benchmark BEIR, grâce à des conseils et des techniques pour améliorer vos processus d'évaluation des recherches.

19 décembre 2023
Plagiat par l'IA : Détection de plagiat avec Elasticsearch
Voici comment vérifier le plagiat de l'IA à l'aide d'Elasticsearch, en se concentrant sur les cas d'utilisation avec les modèles NLP et Vector Search.

3 octobre 2023
Recherche lexicale et sémantique avec Elasticsearch
Dans ce blog, nous allons explorer différentes approches de la recherche d'informations à l'aide d'Elasticsearch, en nous concentrant sur la recherche lexicale et sémantique.