La recherche hybride est largement reconnue comme une approche de recherche puissante, combinant la précision et la vitesse de la recherche lexicale avec les capacités de langage naturel de la recherche sémantique. Cependant, son application pratique peut s'avérer délicate, nécessitant souvent une connaissance approfondie de votre index et la construction de requêtes verbeuses avec des configurations non triviales. Dans ce blog, nous allons voir comment le format de requête multi-champs pour les extracteurs linéaires et RRF rend la recherche hybride plus simple et plus accessible, en éliminant les maux de tête courants et en vous permettant de tirer parti de toute sa puissance avec plus de facilité. Nous verrons également comment le format d'interrogation à champs multiples vous permet d'effectuer des recherches hybrides sans aucune connaissance préalable de votre index.
Le problème de l'étendue des scores

Pour préparer le terrain, examinons l'une des principales raisons pour lesquelles la recherche hybride peut s'avérer difficile : la variation des fourchettes de scores. Notre vieil ami BM25 produit des scores non bornés. En d'autres termes, BM25 peut générer des scores allant de près de 0 à (théoriquement) l'infini. En revanche, les requêtes portant sur les champs dense_vector produiront des scores limités entre 0 et 1. Pour aggraver ce problème, semantic_text obscurcit le type de champ utilisé pour indexer les embeddings, de sorte qu'à moins d'avoir une connaissance détaillée de la configuration de votre index et de votre point de terminaison d'inférence, il peut être difficile de savoir quelle sera la plage de scores de votre requête. Cela pose un problème lorsqu'on essaie d'intercaler des résultats de recherche lexicaux et sémantiques, car les résultats lexicaux peuvent prendre le pas sur les résultats sémantiques, même si ces derniers sont plus pertinents. La solution généralement acceptée pour ce problème est de normaliser les scores avant d'entrelacer les résultats. Elasticsearch dispose de deux outils pour cela, les extracteurs linéaires et RRF.
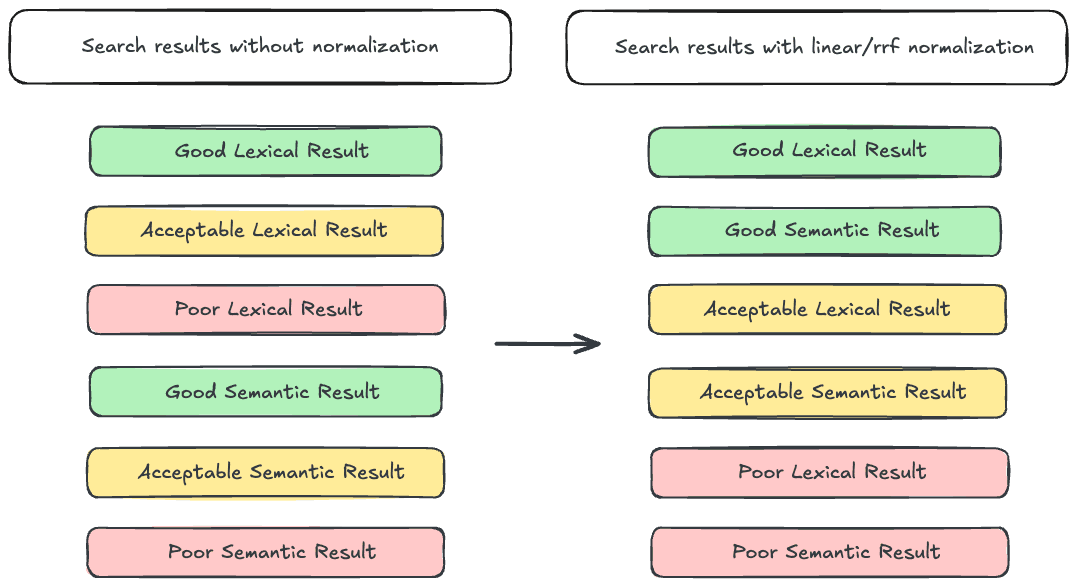
Le récupérateur RRF applique l'algorithme RRF, en utilisant le rang du document comme mesure de la pertinence et en écartant le score. Étant donné que le score n'est pas pris en compte, les écarts de score ne posent pas de problème.
L'extracteur linéaire utilise une combinaison linéaire pour déterminer le score final d'un document. Il s'agit de prendre le score de chaque composante de la requête pour le document, de le normaliser et de l'additionner pour obtenir le score total. Mathématiquement, l'opération peut être exprimée comme suit :
Où N est la fonction de normalisation et SX est le score de la requête X. La fonction de normalisation est essentielle ici, car elle transforme le score de chaque requête pour utiliser le même intervalle. Pour en savoir plus sur le retriever linéaire , cliquez ici.
La décomposition
Les utilisateurs peuvent mettre en œuvre une recherche hybride efficace à l'aide de ces outils, mais cela nécessite une certaine connaissance de votre index. Prenons un exemple avec l'extracteur linéaire, où nous allons interroger un index avec deux champs :
1. semantic_text_field est un champ semantic_text qui utilise E5, un modèle d'intégration de texte.
2. text_field est un champ standard text
1. Nous utilisons une requête match sur notre champ semantic_text, dont la prise en charge a été ajoutée dans Elasticsearch 8.18/9.0.
Lors de la construction de la requête, nous devons garder à l'esprit que semantic_text_field utilise un modèle d'intégration de texte, de sorte que toute requête sur ce site générera un score entre 0 et 1. Nous devons également savoir que text_field est un champ standard de text et que les requêtes sur ce champ génèreront donc un score non borné. Pour créer un ensemble de résultats pertinents, nous devons utiliser un extracteur qui normalisera les résultats des requêtes avant de les combiner. Dans cet exemple, nous utilisons l'extracteur linéaire avec la normalisation minmax, qui normalise le score de chaque requête à une valeur comprise entre 0 et 1.
La construction de la requête dans cet exemple est assez simple car seuls deux champs sont concernés. Toutefois, la situation peut se compliquer très rapidement à mesure que l'on ajoute d'autres champs, de types différents. Cela démontre que la rédaction d'une requête de recherche hybride efficace nécessite souvent une connaissance plus approfondie de l'index interrogé, afin que les scores des composantes de la requête soient correctement normalisés avant d'être combinés. Cela constitue un obstacle à l'adoption plus large de la recherche hybride.
Regroupement de requêtes
Étendons l'exemple : Et si nous voulions interroger un champ text et deux champs semantic_text? Nous pourrions construire une requête comme celle-ci :
Cela semble être une bonne chose à première vue, mais il y a un problème potentiel. Désormais, les matchs sur le terrain semantic_text représentent ⅔ du score total :
Ce n'est probablement pas ce que vous souhaitez, car cela crée un score déséquilibré. Les effets ne sont peut-être pas très visibles dans un exemple comme celui-ci, qui ne comporte que trois champs, mais ils deviennent problématiques lorsqu'un plus grand nombre de champs sont interrogés. Par exemple, la plupart des index contiennent beaucoup plus de champs lexicaux que de champs sémantiques (c.-à-d. dense_vector, sparse_vector, ou semantic_text). Que se passerait-il si nous interrogions un index comportant 9 champs lexicaux et 1 champ sémantique en utilisant le modèle ci-dessus ? Les correspondances lexicales représenteraient 90% du score, ce qui réduirait l'efficacité de la recherche sémantique.
Une solution courante consiste à regrouper les requêtes en catégories lexicales et sémantiques et à pondérer les deux de manière égale. Cela permet d'éviter que l'une ou l'autre catégorie ne domine le score total.
Mettons cela en pratique. À quoi ressemblerait cette approche de requêtes groupées pour cet exemple en utilisant l'outil de recherche linéaire ?
Wow, ça devient verbeux ! Vous avez peut-être même dû faire défiler l'écran de haut en bas plusieurs fois pour examiner l'ensemble de la requête ! Ici, nous utilisons deux niveaux de normalisation pour créer les groupes de requêtes. Mathématiquement, elle peut être exprimée comme suit :
Ce deuxième niveau de normalisation garantit que les requêtes portant sur les champs semantic_text et text sont pondérées de manière égale. Notez que nous omettons la normalisation de second niveau pour text_field dans cet exemple puisqu'il n'y a qu'un seul champ lexical, ce qui vous évite encore plus de verbosité.
Cette structure d'interrogation est déjà lourde, et nous n'interrogeons que trois champs. Il devient de plus en plus difficile à gérer, même pour les praticiens chevronnés de la recherche, au fur et à mesure que l'on interroge davantage de champs.
Le format d'interrogation à champs multiples

Nous avons ajouté le format de requête multi-champs pour les extracteurs linéaires et RRF dans Elasticsearch 8.19, 9.1 et serverless pour simplifier tout cela. Vous pouvez maintenant effectuer la même requête que ci-dessus avec just :
Ce qui réduit la requête de 55 lignes à seulement 9 ! Elasticsearch utilise automatiquement les mappages d'index pour :
- Déterminer le type de chaque champ interrogé
- Regrouper chaque champ dans une catégorie lexicale ou sémantique
- Pondérer chaque catégorie de manière égale dans la note finale
Cela permet à n'importe qui d'exécuter une requête de recherche hybride efficace sans avoir besoin de connaître les détails de l'index ou les points de terminaison d'inférence utilisés.
Lorsque vous utilisez la méthode RRF, vous pouvez omettre le site normalizer, car le rang est utilisé comme indicateur de la pertinence :
Renforcement par champ
Lors de l'utilisation de l'extracteur linéaire, vous pouvez appliquer un boost par champ pour ajuster l'importance des correspondances dans certains champs. Par exemple, disons que vous interrogez quatre champs : deux champs semantic_text et deux champs text:
Par défaut, chaque champ est pondéré de manière égale dans son groupe (lexical ou sémantique). La répartition des points est la suivante :

En d'autres termes, chaque champ représente 25% du score total.
Nous pouvons utiliser la syntaxe field^boost pour ajouter un boost par champ à n'importe quel champ. Appliquons un boost de 2 à semantic_text_field_1 et text_field_1:
La répartition des points est maintenant la suivante :
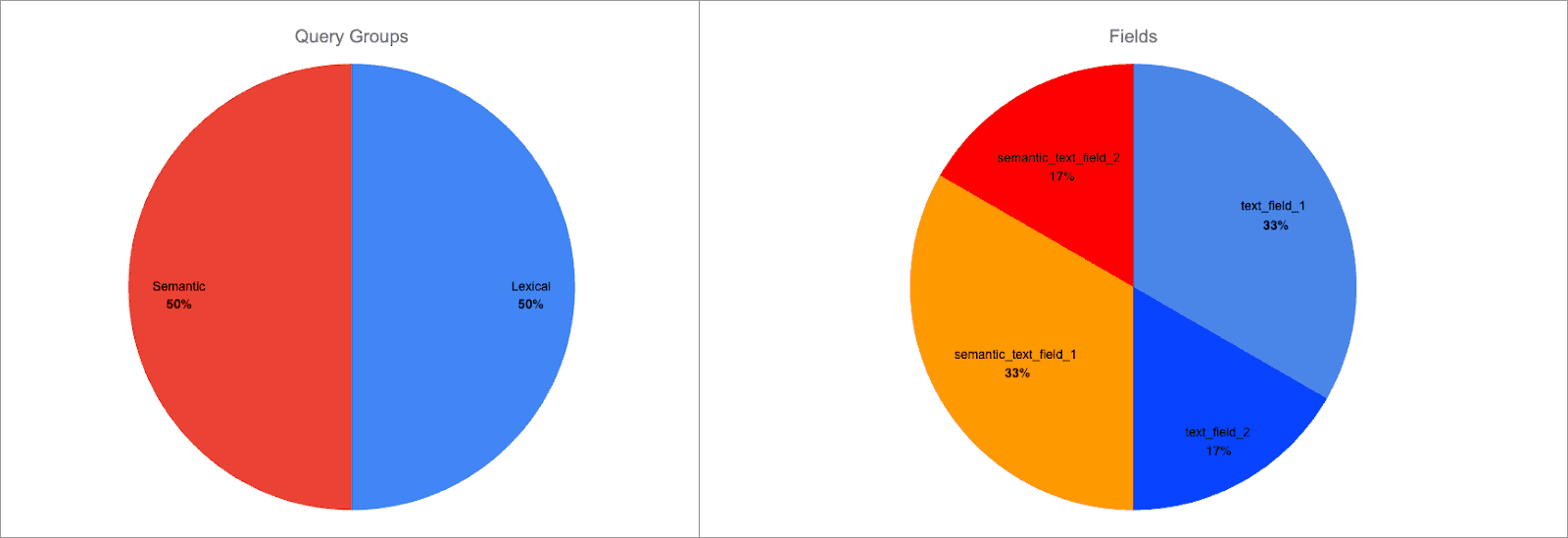
Chaque groupe de requêtes est toujours pondéré de manière égale, mais la pondération des champs à l'intérieur des groupes a changé :
semantic_text_field_1est 66% du score du groupe de requêtes sémantiques, 33% du score totaltext_field_1est 66% du score du groupe de requêtes lexicales, 33% du score total
| ℹ️ Notez que la fourchette de score total ne changera pas lorsqu'une majoration par champ est appliquée. Il s'agit d'un effet secondaire voulu de la normalisation des scores, qui garantit que les scores des requêtes lexicales et sémantiques restent directement comparables entre eux. |
|---|
| ℹ️ Le boosting par champ peut également être utilisé avec le récupérateur RRF dans Elasticsearch 9.2+. |
Résolution sur les caractères génériques
Vous pouvez utiliser le caractère générique * dans le paramètre fields pour faire correspondre plusieurs champs. Si l'on reprend l'exemple ci-dessus, cette requête est fonctionnellement équivalente à l'interrogation explicite des sitesemantic_text_field_1, semantic_text_field_2 et text_field_1:
Il est intéressant de noter que le modèle *_field_1 correspond à la fois à text_field_1 et à semantic_text_field_1. La requête sera exécutée comme si chacun des champs avait été explicitement interrogé. Le fait que le site semantic_text_field_1 corresponde aux deux modèles ne pose pas de problème ; tous les noms de champ correspondant sont dédupliqués avant l'exécution de la requête.
Vous pouvez utiliser les caractères génériques de différentes manières :
- Correspondance des préfixes (ex :
*_text_field) - Correspondance en ligne (ex :
semantic_*_field) - Correspondance des suffixes (ex :
semantic_text_field_*)
Vous pouvez également utiliser plusieurs caractères génériques pour appliquer une combinaison des éléments ci-dessus, par exemple *_text_field_*.
Champs de requête par défaut
Le format d'interrogation à champs multiples vous permet également d'interroger un index dont vous ignorez tout. Si vous omettez le paramètre fields, il interrogera tous les champs spécifiés par le paramètre d'indexation index.query.default_field:
Par défaut, index.query.default_field est défini comme *. Ce caractère générique permet de résoudre tous les types de champs de l'index qui prennent en charge les requêtes de termes, ce qui est le cas de la plupart d'entre eux. Les exceptions sont les suivantes :
dense_vectorchampsrank_vectorchamps- Champs de géométrie :
geo_point,shape
Cette fonctionnalité est particulièrement utile lorsque vous souhaitez effectuer une recherche hybride sur un index fourni par un tiers. Le format d'interrogation à champs multiples vous permet d'exécuter une requête appropriée de manière simple. Il suffit d'exclure le paramètre fields pour que tous les champs applicables soient interrogés.
Conclusion
Le problème de la plage de scores peut faire de la recherche hybride efficace un casse-tête à mettre en œuvre, en particulier lorsque l'on ne dispose que de peu d'informations sur l'index interrogé ou sur les points de terminaison d'inférence utilisés. Le format d'interrogation à champs multiples pour les extracteurs linéaires et RRF atténue cette difficulté en intégrant une approche de recherche hybride automatisée, basée sur le regroupement de requêtes, dans une API simple et facile d'accès. Des fonctionnalités supplémentaires, telles que le renforcement par champ, la résolution des caractères génériques et les champs de requête par défaut, permettent d'étendre les fonctionnalités à de nombreux cas d'utilisation.
Essayez le format d'interrogation à champs multiples dès aujourd'hui
Vous pouvez tester les extracteurs linéaires et RRF avec le format de requête multi-champs dans des projets Elasticsearch Serverless entièrement gérés avec un essai gratuit. Il est également disponible en version stack à partir de 8.19 & 9.1.
Démarrez en quelques minutes sur votre environnement local à l'aide d'une simple commande :
Pour aller plus loin

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.

26 février 2026
Résolution d’entités avec Elasticsearch et les LLM, partie 2 : mise en correspondance d’entités avec le jugement des LLM et la recherche sémantique
Utiliser la recherche sémantique et le jugement transparent des LLM pour la résolution d’entités dans Elasticsearch.

20 février 2026
Garantir une précision sémantique avec un score minimum
Améliorez la précision sémantique en utilisant des seuils de score minimum. Cet article présente des exemples concrets de recherche sémantique et hybride.

11 décembre 2025
Évaluer la pertinence des requêtes de recherche à l’aide de listes de jugement
Découvrez comment créer des listes de jugement pour évaluer objectivement la pertinence des requêtes de recherche et améliorer des indicateurs de performance comme le rappel, dans le cadre de tests de recherche scalable avec Elasticsearch.