Cet article est le premier d'une série qui traite de l'utilisation d'Elasticsearch avec JavaScript. Dans cette série, vous apprendrez les bases de l'utilisation d'Elasticsearch dans un environnement JavaScript et passerez en revue les fonctionnalités les plus pertinentes et les meilleures pratiques pour créer une application de recherche. À la fin, vous saurez tout ce dont vous avez besoin pour exécuter Elasticsearch à l'aide de JavaScript.
Dans cette première partie, nous passerons en revue
Vous pouvez consulter le code source avec les exemples ici.
Qu'est-ce que le client Elasticsearch Node.js ?
Le client Elasticsearch Node.js est une bibliothèque JavaScript qui transpose les appels HTTP REST de l'API Elasticsearch en JavaScript. Il est ainsi plus facile à manipuler et dispose d'assistants qui simplifient les tâches telles que l'indexation de documents par lots.
Environnement
Frontend, backend ou serverless ?
Pour créer notre application de recherche à l'aide du client JavaScript, nous avons besoin d'au moins deux composants : un cluster Elasticsearch et un moteur d'exécution JavaScript pour exécuter le client.
Le client JavaScript prend en charge toutes les solutions Elasticsearch (Cloud, on-prem et Serverless), et il n'y a pas de différences majeures entre elles puisque le client gère toutes les variations en interne, vous n'avez donc pas à vous soucier de savoir laquelle utiliser.
Le moteur d'exécution JavaScript doit toutefois être exécuté à partir du serveur et non directement à partir du navigateur.
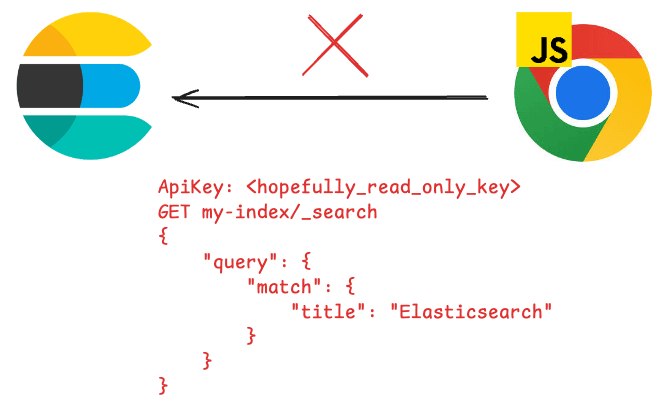
En effet, en appelant Elasticsearch depuis le navigateur, l'utilisateur peut obtenir des informations sensibles telles que la clé API du cluster, l'hôte ou la requête elle-même. Elasticsearch recommande de ne jamais exposer le cluster directement à l'internet et d'utiliser une couche intermédiaire qui abstrait toutes ces informations de sorte que l'utilisateur ne puisse voir que les paramètres. Pour en savoir plus sur ce sujet , cliquez ici.
Nous suggérons d'utiliser un schéma comme celui-ci :

Dans ce cas, le client n'envoie que les termes de recherche et une clé d'authentification pour votre serveur, tandis que votre serveur contrôle totalement la requête et la communication avec Elasticsearch.
Connexion du client
Commencez par créer une clé API en suivant ces étapes.
En suivant l'exemple précédent, nous allons créer un simple serveur Express, et nous y connecter en utilisant un client depuis un serveur Node.JS.
Nous allons initialiser le projet avec NPM et installer le client Elasticsearch et Express. Cette dernière est une bibliothèque qui permet d'activer des serveurs dans Node.js. En utilisant Express, nous pouvons interagir avec notre backend via HTTP.
Initialisons le projet :
npm init -y
Installer les dépendances :
npm install @elastic/elasticsearch express split2 dotenv
Laissez-moi vous expliquer :
- @elastic/elasticsearch: C'est le client officiel Node.js
- express: Il nous permettra de faire tourner un serveur nodejs léger pour exposer Elasticsearch.
- split2: divise les lignes de texte en un flux. Utile pour traiter nos fichiers ndjson une ligne à la fois
- dotenv: Permet de gérer les variables d'environnement à l'aide d'un fichier .env fichier
Créer un fichier .env à la racine du projet et ajoutez les lignes suivantes :
Ainsi, nous pouvons importer ces variables à l'aide du paquetage dotenv.
Créer un fichier server.js:
Ce code met en place un serveur Express.js de base qui écoute sur le port 3000 et se connecte à un cluster Elasticsearch en utilisant une clé API pour l'authentification. Il comprend un point d'extrémité /ping qui, lorsqu'on y accède par une requête GET, interroge le cluster Elasticsearch pour obtenir des informations de base à l'aide de la méthode .info() du client Elasticsearch.
Si la requête aboutit, elle renvoie les informations sur le cluster au format JSON ; dans le cas contraire, elle renvoie un message d'erreur. Le serveur utilise également un intergiciel d'analyseur de corps pour traiter les corps de requête JSON.
Exécutez le fichier pour lancer le serveur :
node server.js
La réponse devrait ressembler à ceci :
Et maintenant, consultons le point de terminaison /ping pour vérifier l'état de notre cluster Elasticsearch.
Indexation des documents
Une fois connectés, nous pouvons indexer les documents à l'aide de mappings tels que semantic_text pour la recherche sémantique et text pour les requêtes en texte intégral. Avec ces deux types de champs, nous pouvons également effectuer une recherche hybride.
Nous allons créer un nouveau fichier load.js pour générer les correspondances et télécharger les documents.
Client Elasticsearch
Nous devons d'abord instancier et authentifier le client :
Correspondances sémantiques
Nous allons créer un index contenant des données sur un hôpital vétérinaire. Nous stockons les informations concernant le propriétaire, l'animal et les détails de la visite.
Les données sur lesquelles nous voulons effectuer une recherche en texte intégral, telles que les noms et les descriptions, seront stockées sous forme de texte. Les données des catégories, telles que l'espèce ou la race de l'animal, seront stockées sous forme de mots-clés.
En outre, nous copierons les valeurs de tous les champs dans un champ semantic_text afin de pouvoir effectuer une recherche sémantique sur ces informations également.
Aide en vrac
Un autre avantage du client est qu'il est possible d'utiliser l'assistant de masse pour indexer par lots. L'assistant de masse nous permet de gérer facilement des choses comme la concurrence, les tentatives, et ce qu'il faut faire avec chaque document qui passe par la fonction et qui réussit ou échoue.
L'une des caractéristiques intéressantes de cette aide est qu'elle permet de travailler avec des flux. Cette fonction vous permet d'envoyer un fichier ligne par ligne au lieu de stocker le fichier complet dans la mémoire et de l'envoyer à Elasticsearch en une seule fois.
Pour télécharger les données vers Elasticsearch, créez un fichier appelé data.ndjson à la racine du projet et ajoutez les informations ci-dessous (vous pouvez également télécharger le fichier avec le jeu de données à partir d'ici) :
Nous utilisons split2 pour streamer les lignes de fichiers pendant que l'assistant bulk les envoie à Elasticsearch.
Le code ci-dessus lit un fichier .ndjson ligne par ligne et indexe en bloc chaque objet JSON dans un index Elasticsearch spécifié à l'aide de la méthode helpers.bulk. Il diffuse le fichier en utilisant createReadStream et split2, met en place des métadonnées d'indexation pour chaque document et enregistre tous les documents qui ne sont pas traités. Une fois l'opération terminée, il enregistre le nombre d'éléments indexés avec succès.
En lieu et place de la fonction indexData, vous pouvez télécharger le fichier directement via l'interface utilisateur à l'aide de Kibana et utiliser l'interface utilisateur de téléchargement des fichiers de données.
Nous exécutons le fichier pour télécharger les documents vers notre cluster Elasticsearch.
node load.js
Recherche de données dans Elasticsearch
En revenant à notre fichier server.js, nous allons créer différents points de terminaison pour effectuer une recherche lexicale, sémantique ou hybride.
En résumé, ces types de recherche ne s'excluent pas mutuellement, mais dépendent du type de question à laquelle vous devez répondre.
| Type de requête | Cas d'utilisation | Exemple de question |
|---|---|---|
| Requête lexicale | Les mots ou racines de mots de la question sont susceptibles d'apparaître dans les documents de l'index. Similitude des jetons entre la question et les documents. | Je cherche un t-shirt de sport bleu. |
| Requête sémantique | Les mots de la question ne sont pas susceptibles de figurer dans les documents. Similitude conceptuelle entre la question et les documents. | Je cherche des vêtements pour le froid. |
| Recherche hybride | La question contient des éléments lexicaux et/ou sémantiques. Similitude toxique et sémantique entre les questions et les documents. | Je cherche une robe taille S pour un mariage sur la plage. |
Les parties lexicales de la question sont susceptibles de faire partie de titres et de descriptions, ou de noms de catégories, tandis que les parties sémantiques sont des concepts liés à ces domaines. Le bleu sera probablement un nom de catégorie ou une partie de la description, et le mariage à la plage ne le sera probablement pas, mais il peut être sémantiquement lié aux vêtements en lin.
Requête lexicale (/search/lexic?q=<query_term>)
La recherche lexicale, également appelée recherche en texte intégral, consiste à effectuer une recherche basée sur la similarité des mots-clés, c'est-à-dire qu'après une analyse, les documents qui contiennent les mots-clés de la recherche seront renvoyés.
Vous pouvez consulter notre tutoriel pratique sur la recherche lexicale ici.
Nous testons avec : coupe-ongles
Réponse :
Requête sémantique (/search/semantic?q=<query_term>)
La recherche sémantique, contrairement à la recherche lexicale, permet de trouver des résultats similaires à la signification des termes de recherche par le biais d'une recherche vectorielle.
Vous pouvez consulter notre tutoriel pratique sur la recherche sémantique ici.
Nous testons avec : Qui s'est fait faire une pédicure ?
Réponse :
Requête hybride (/search/hybrid?q=<query_term>)
La recherche hybride nous permet de combiner la recherche sémantique et la recherche lexicale, et d'obtenir ainsi le meilleur des deux mondes : vous bénéficiez de la précision de la recherche par jeton, ainsi que de la proximité de sens de la recherche sémantique.
Nous testons avec "Qui a reçu une pédicure ou un traitement dentaire ?"
Réponse :
Conclusion
Dans cette première partie de notre série, nous avons expliqué comment configurer notre environnement et créer un serveur avec différents points de terminaison de recherche pour interroger les documents Elasticsearch en suivant les meilleures pratiques client/serveur. Consultez la deuxième partie de notre série, dans laquelle vous découvrirez les meilleures pratiques de production et comment exécuter le client Elasticsearch Node.js dans des environnements sans serveur.
Questions fréquentes
Qu’est-ce que le client Node.js ?
Le client Node.js est une bibliothèque JavaScript qui transpose les appels HTTP REST de l'API Elasticsearch en JavaScript. Des outils d’aide simplifient les tâches complexes, à l’image de l’indexation groupée de documents.
Pourquoi utiliser un environnement Node.js côté serveur au lieu d’appeler Elasticsearch depuis le frontend ?
Security est le principal avantage. L’exécution du client dans un environnement back-end (comme Node.js avec Express) empêche les informations sensibles, telles que les clés API de cluster, les URL d’hébergement et la logique de requête interne, d’être exposées au navigateur.
Quels sont les avantages d'utiliser Elasticsearch Bulk Helper dans Node.js ?
Les principaux avantages de l'utilisation d’Elasticsearch Bulk Helper dans Node.js sont les suivants : Indexation par lots : il gère automatiquement la complexité de ’'indexation des documents par groupes plutôt qu’un par un. Support du stream : avec des outils comme split2, vous pouvez diffuser des fichiers (comme .ndjson) ligne par ligne. Cela vous permet de traiter des fichiers volumineux sans charger l’ensemble de données dans la mémoire de votre serveur.
Pour aller plus loin

14 novembre 2025
Comment déployer Elasticsearch sur Azure AKS Automatic
Découvrez comment déployer Elasticsearch avec Kibana sur Azure en utilisant AKS Automatic et ECK pour une configuration Elasticsearch partiellement gérée.

11 novembre 2025
Configurer le découpage récursif pour les documents structurés dans Elasticsearch
Apprenez à configurer le découpage récursif dans Elasticsearch avec la taille des morceaux, les groupes de séparateurs et les listes de séparateurs personnalisées pour une indexation optimale des documents structurés.

7 novembre 2025
Présentation de l'interface utilisateur des règles de requête Elasticsearch dans Kibana
Découvrez comment utiliser l'interface utilisateur Elasticsearch Query Rules pour ajouter ou exclure des documents des requêtes de recherche à l'aide d'ensembles de règles personnalisables dans Kibana, sans affecter le classement organique.

3 octobre 2025
Comment déployer Elasticsearch sur AWS Marketplace
Découvrez comment configurer et exécuter Elasticsearch à l'aide d'Elastic Cloud Service sur AWS Marketplace grâce à ce guide étape par étape.

14 août 2025
Shards et répliques Elasticsearch : Un guide pratique
Maîtriser les concepts de shards et de réplicas Elasticsearch et apprendre à les optimiser.