Elasticsearch vous permet d’indexer des données rapidement et en toute flexibilité. Essayez-le gratuitement dans le cloud ou exécutez-le en local pour découvrir à quel point l’indexation peut être simple.
Dans cet article, nous montrons comment intégrer Apache Kafka avec Elasticsearch pour l'ingestion et l'indexation des données. Nous donnerons un aperçu de Kafka, de son concept de producteurs et de consommateurs, et nous créerons un index de logs où les messages seront reçus et indexés par Apache Kafka. Le projet est mis en œuvre en Python, et le code est disponible sur GitHub.
Produits requis
- Docker et Docker Compose : Assurez-vous que Docker et Docker Compose sont installés sur votre machine.
- Python 3.x : Pour exécuter les scripts du producteur et du consommateur.
Introduction à Apache Kafka
Apache Kafka est une plateforme de diffusion en continu distribuée qui permet une évolutivité et une disponibilité élevées, ainsi qu'une tolérance aux pannes. Dans Kafka, la gestion des données s'effectue par le biais des principaux composants :
- Courtier: responsable du stockage et de la distribution des messages entre les producteurs et les consommateurs.
- Zookeeper: gère et coordonne les courtiers Kafka, en contrôlant l'état de la grappe, les chefs de partition et les informations sur les consommateurs.
- Sujets: canaux où les données sont publiées et stockées pour être consommées.
- Consommateurs et producteurs: tandis que les producteurs envoient des données aux thèmes, les consommateurs récupèrent ces données.
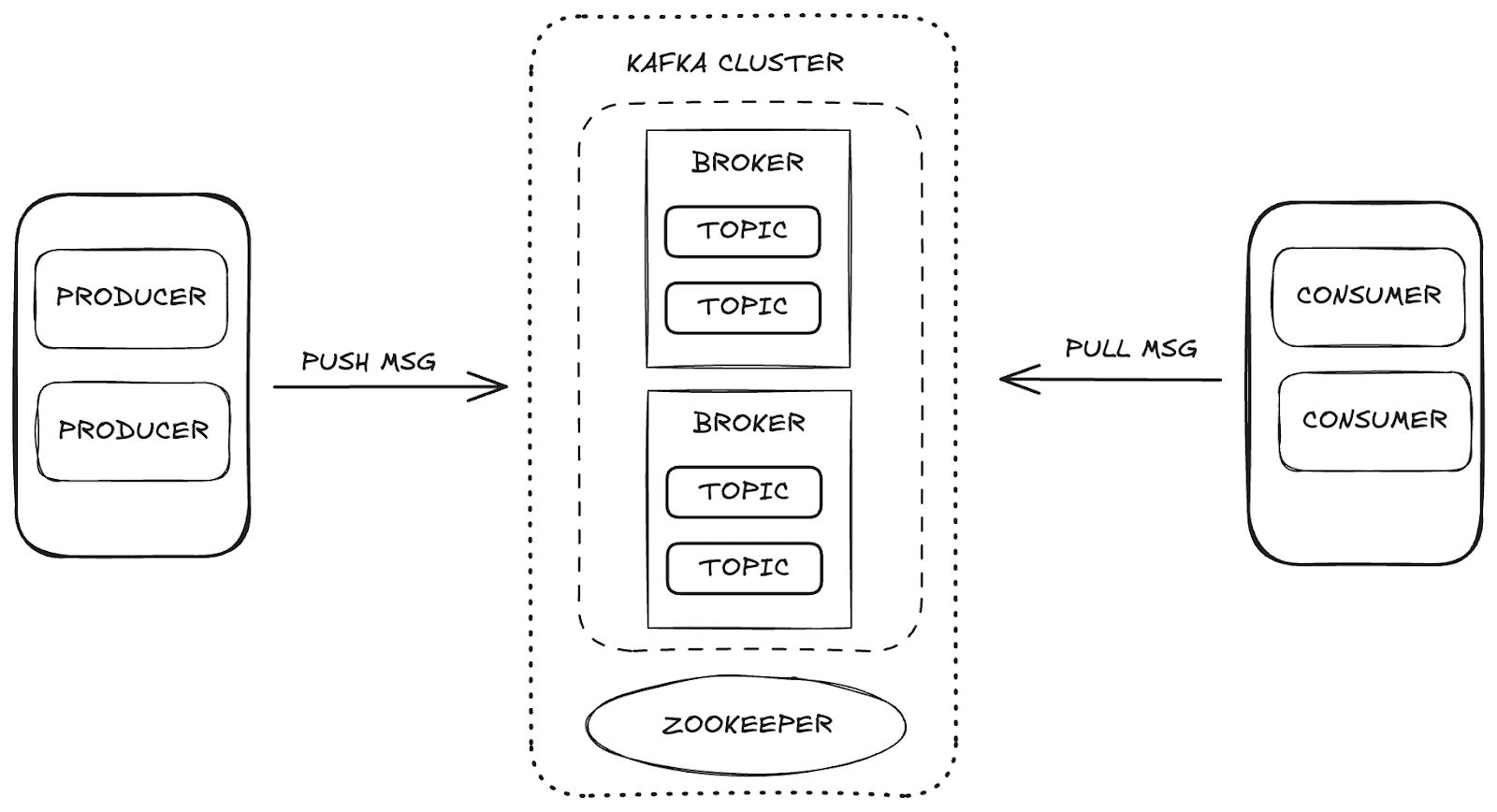
Ces composants fonctionnent ensemble pour former l'écosystème Kafka, qui fournit un cadre robuste pour la diffusion de données en continu.
Structure du projet
Pour comprendre le processus d'ingestion des données, nous l'avons divisé en plusieurs étapes :
- Provisionnement de l'infrastructure: mise en place de l'environnement Docker pour prendre en charge Kafka, Elasticsearch et Kibana.
- Création du producteur: mise en œuvre du producteur Kafka, qui envoie des données au sujet des journaux.
- Création du consommateur: développement du consommateur Kafka pour lire et indexer les messages dans Elasticsearch.
- Validation de l'ingestion: vérification et validation des données envoyées et consommées.
Configuration de l'infrastructure avec Docker Compose
Nous avons utilisé Docker Compose pour configurer et gérer les services nécessaires. Vous trouverez ci-dessous le code Docker Compose qui met en place chaque service nécessaire à l'intégration d'Apache Kafka, Elasticsearch et Kibana, en assurant un processus d'ingestion des données.
Vous pouvez accéder au fichier directement depuis le repo GitHub d'Elasticsearch Labs.
Envoi de données avec le producteur Kafka
Le producteur est responsable de l'envoi des messages au sujet des journaux. L'envoi de messages par lots augmente l'efficacité de l'utilisation du réseau et permet d'optimiser les paramètres batch_size et linger_ms, qui contrôlent respectivement la quantité et la latence des lots. La configuration acks='all' garantit que les messages sont stockés durablement, ce qui est essentiel pour les données d'enregistrement importantes.
Lors du démarrage du producteur, les messages sont envoyés par lots au sujet, comme indiqué ci-dessous :
Consommation et indexation des données avec le consommateur Kafka
Le consommateur est conçu pour traiter efficacement les messages, en consommant des lots à partir du sujet des journaux et en les indexant dans Elasticsearch. Avec auto_offset_reset='latest', il s'assure que le consommateur commence à traiter les messages les plus récents, en ignorant les plus anciens, et max_poll_records=10 limite le lot à 10 messages. Avec fetch_max_wait_ms=2000, le consommateur attend jusqu'à 2 secondes pour accumuler suffisamment de messages avant de traiter le lot.
Dans sa boucle principale, le consommateur consomme les messages du journal, traite et indexe chaque lot dans Elasticsearch, assurant ainsi une ingestion continue des données.
Visualisation des données dans Kibana
Avec Kibana, nous pouvons explorer et valider les données ingérées depuis Kafka et indexées dans Elasticsearch. En accédant à Dev Tools dans Kibana, vous pouvez visualiser les messages indexés et confirmer que les données sont conformes aux attentes. Par exemple, si notre producteur Kafka a envoyé 5 lots de 10 messages chacun, nous devrions voir un total de 50 enregistrements dans l'index.
Pour vérifier les données, vous pouvez utiliser la requête suivante dans la section Outils de développement :
Réponse :

En outre, Kibana permet de créer des visualisations et des tableaux de bord qui peuvent rendre l'analyse plus intuitive et interactive. Vous trouverez ci-dessous quelques exemples de tableaux de bord et de visualisations que nous avons créés, qui illustrent les données sous différents formats, améliorant ainsi notre compréhension des informations traitées.

Ingestion de données avec Kafka Connect
Kafka Connect est un service conçu pour faciliter l'intégration entre les sources de données et les destinations (puits), telles que les bases de données ou les systèmes de fichiers. Il fonctionne avec des connecteurs prédéfinis qui gèrent automatiquement les mouvements de données. Dans notre cas, Elasticsearch fait office de puits de données.

En utilisant Kafka Connect, nous pouvons simplifier le processus d'ingestion de données, en éliminant la nécessité d'implémenter manuellement le workflow d'ingestion de données dans Elasticsearch. Avec le connecteur approprié, Kafka Connect permet aux données envoyées à un sujet Kafka d'être directement indexées dans Elasticsearch avec une configuration minimale et sans codage supplémentaire.
Travailler avec Kafka Connect
Pour mettre en œuvre Kafka Connect, nous allons ajouter le service kafka-connect à notre installation Docker Compose. Un élément clé de cette configuration est l'installation du connecteur Elasticsearch, qui se chargera de l'indexation des données.
Après avoir configuré le service et créé le conteneur Kafka Connect, un fichier de configuration pour le connecteur Elasticsearch sera nécessaire. Ce fichier définit des paramètres essentiels tels que
connection.url: URL de connexion pour Elasticsearch.topics: Le sujet Kafka que le connecteur surveillera (dans ce cas, "logs").type.name: Type de document dans Elasticsearch (typiquement _doc).value.converter: Convertit les messages Kafka au format JSON.value.converter.schemas.enable: Spécifie si le schéma doit être inclus.schema.ignoreetkey.ignore: Paramètres permettant d'ignorer les schémas et les clés Kafka lors de l'indexation.
Voici la commande curl pour créer le connecteur Elasticsearch dans Kafka Connect :
Avec cette configuration, Kafka Connect commencera automatiquement à ingérer les données envoyées au sujet "logs" et à les indexer dans Elasticsearch. Cette approche permet d'automatiser entièrement l'ingestion et l'indexation des données sans nécessiter de codage supplémentaire, ce qui simplifie l'ensemble du processus d'intégration.
Conclusion
L'intégration de Kafka et d'Elasticsearch crée un pipeline puissant pour l'ingestion et l'analyse de données en temps réel. Ce guide fournit une approche fondamentale pour construire une architecture d'ingestion de données robuste, avec une visualisation et une analyse transparentes dans Kibana, prête à s'adapter à des exigences plus complexes à l'avenir.
En outre, l'utilisation de Kafka Connect rend l'intégration entre Kafka et Elasticsearch encore plus rationnelle, en éliminant le besoin de code supplémentaire pour traiter et indexer les données. Kafka Connect permet aux données envoyées à un sujet spécifique d'être automatiquement indexées dans Elasticsearch avec une configuration minimale.
Pour aller plus loin

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

22 septembre 2025
Elastic Open Web Crawler en tant que code
Apprenez à utiliser les actions GitHub pour gérer les configurations d'Elastic Open Crawler, de sorte que chaque fois que nous apportons des modifications au référentiel, celles-ci sont automatiquement appliquées à l'instance déployée du crawler.

6 août 2025
Comment afficher les champs d'un index Elasticsearch ?
Apprenez à afficher les champs d'un index Elasticsearch à l'aide des API _mapping et _search, des sous-champs, de la _source synthétique et des champs d'exécution.

24 juin 2025
Scripting Ruby dans Logstash
Découvrez le plugin Logstash Ruby filter pour une transformation avancée des données dans votre pipeline Logstash.

26 mai 2025
Affichage des champs dans un index Elasticsearch
Exploration des techniques d'affichage des champs dans un index Elasticsearch.