Elasticsearch vous permet d’indexer des données rapidement et en toute flexibilité. Essayez-le gratuitement dans le cloud ou exécutez-le en local pour découvrir à quel point l’indexation peut être simple.
Qu'est-ce que le flux d'air Apache ?
Apache Airflow est une plateforme conçue pour créer, planifier et contrôler les flux de travail. Il est utilisé pour orchestrer les processus ETL, les pipelines de données et d'autres flux de travail complexes, en offrant flexibilité et évolutivité. Son interface visuelle et ses capacités de suivi en temps réel rendent la gestion des pipelines plus accessible et plus efficace, vous permettant de suivre la progression et les résultats de vos exécutions. Ses quatre principaux piliers sont décrits ci-dessous :
- Dynamique : Les pipelines sont définis en Python, ce qui permet de générer des flux de travail dynamiques et flexibles.
- Extensible : Airflow peut être intégré dans une variété d'environnements, des opérateurs personnalisés peuvent être créés et un code spécifique peut être exécuté selon les besoins.
- Élégant : Les pipelines sont rédigés de manière claire et explicite.
- Évolutif : Son architecture modulaire utilise une file d'attente de messages pour orchestrer un nombre arbitraire de travailleurs.
Dans la pratique, Airflow peut être utilisé dans des scénarios tels que
- Importation de données : Orchestrer l'ingestion quotidienne de données dans une base de données telle qu'Elasticsearch.
- Surveillance des journaux : Gérer la collecte et le traitement des fichiers journaux, qui sont ensuite analysés dans Elasticsearch pour identifier les erreurs ou les anomalies.
- Intégration de sources de données multiples : Combinez des informations provenant de différents systèmes (API, bases de données, fichiers) en une seule couche dans Elasticsearch, ce qui simplifie la recherche et la création de rapports.
Comprendre les DAG (Directed Acyclic Graphs) dans Airflow
Dans Airflow, les flux de travail sont représentés par des DAG (Directed Acyclic Graphs). Un DAG est une structure qui définit la séquence d'exécution des tâches. Les principales caractéristiques des DAG sont les suivantes
- Composition par tâches indépendantes : Chaque tâche représente une unité de travail et est conçue pour être exécutée de manière indépendante.
- Séquencement : L'ordre dans lequel les tâches sont exécutées est explicitement défini dans le DAG.
- Réutilisation : Les DAG sont conçus pour être exécutés de manière répétée, ce qui facilite l'automatisation des processus.
Composants du flux d'air
L'écosystème Airflow est composé de plusieurs éléments qui fonctionnent ensemble pour orchestrer les tâches :
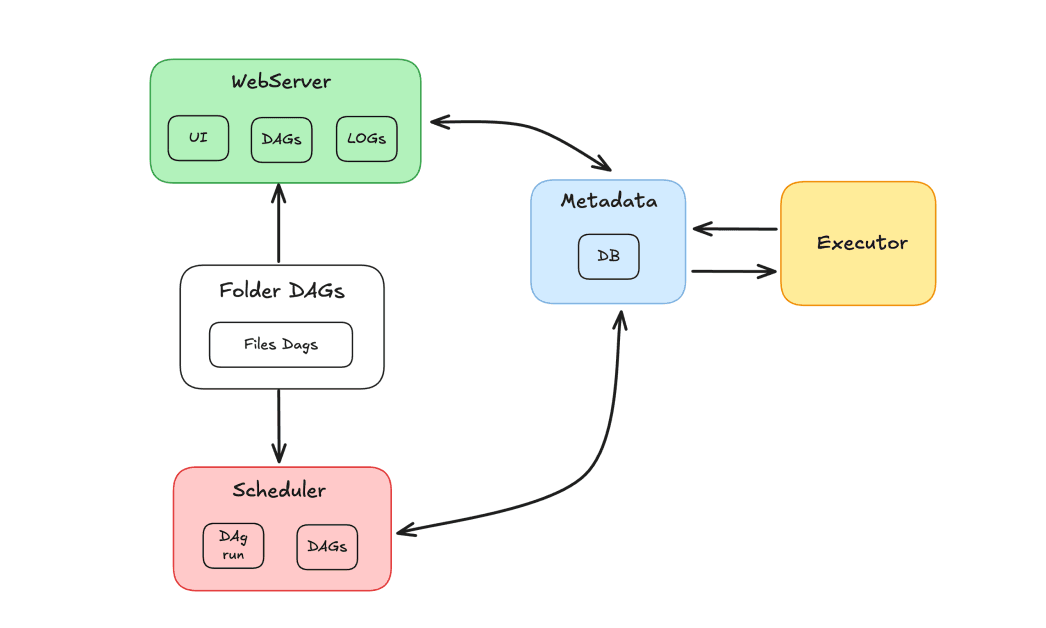
- Ordonnanceur : Responsable de la programmation des DAG et de l'envoi des tâches à exécuter par les travailleurs.
- Exécutant : Il gère l'exécution des tâches et les délègue aux travailleurs.
- Serveur Web : Fournit une interface graphique permettant d'interagir avec les DAG et les tâches.
- Dossier Dags : Dossier dans lequel nous stockons les DAGs écrits en Python.
- Métadonnées : Base de données qui sert de référentiel pour l'outil, utilisée par le planificateur et l'exécuteur pour stocker l'état d'exécution.
Apache Airflow et Elasticsearch
Nous démontrerons l'utilisation d'Apache Airflow et d'Elasticsearch pour orchestrer des tâches et indexer les résultats dans Elasticsearch. L'objectif de cette démonstration est de créer un pipeline de tâches pour mettre à jour les enregistrements dans un index Elasticsearch. Cet index contient une base de données de films, où les utilisateurs peuvent évaluer et attribuer des notes. Imaginons un scénario avec des centaines d'évaluations quotidiennes, il est nécessaire de maintenir l'enregistrement des évaluations à jour. Pour ce faire, un DAG sera développé et exécuté quotidiennement, chargé de récupérer les nouvelles notations consolidées et de mettre à jour les enregistrements dans l'index.
Dans le flux DAG, nous aurons une tâche pour récupérer les classements, suivie d'une tâche pour valider les résultats. Si les données n'existent pas, le DAG sera dirigé vers une tâche d'échec. Sinon, les données seront indexées dans Elasticsearch. L'objectif est de mettre à jour le champ de classement des films dans un index en récupérant les classements par le biais d'une méthode avec le mécanisme responsable du calcul des scores.
Utiliser Apache Airflow et Elasticsearch avec Docker
Pour créer un environnement conteneurisé, nous utiliserons Apache Airflow avec Docker. Suivez les instructions du guide "Running Airflow in Docker" pour configurer Airflow de manière pratique.
En ce qui concerne Elasticsearch, j'utiliserai un cluster sur Elastic Cloud, mais si vous préférez, vous pouvez également configurer Elasticsearch avec Docker. Un index a déjà été créé, contenant un catalogue de films, avec les données des films indexées. Le champ "rating" de ces films sera mis à jour.
Création du DAG
Après l'installation via Docker, une structure de dossiers sera créée, y compris le dossier dags, où nous devons placer nos fichiers DAG pour qu'Airflow les reconnaisse.
Avant cela, nous devons nous assurer que les dépendances nécessaires sont installées. Voici les dépendances pour ce projet :
Nous allons créer le fichier update_ratings_movies.py et commencer à coder les tâches.
Maintenant, importons les bibliothèques nécessaires :
Nous utiliserons ElasticsearchPythonHook, un composant qui simplifie l'intégration entre Airflow et un cluster Elasticsearch en abstrayant la connexion et l'utilisation d'API externes.
Nous définissons ensuite le DAG en précisant ses principaux arguments :
dag_idle nom du DAG.start_date: quand le DAG démarrera.schedule: définit la périodicité (quotidienne dans notre cas).doc_mdLa documentation : la documentation qui sera importée et affichée dans l'interface Airflow.
Définition des tâches
Définissons maintenant les tâches du DAG. La première tâche consistera à récupérer les données relatives à la classification des films. Nous utiliserons l'opérateur Python avec l'adresse task_id fixée à 'get_movie_ratings'. Le paramètre python_callable appellera la fonction responsable de la recherche des classements.
Ensuite, nous devons vérifier si les résultats sont valables. Pour cela, nous utiliserons une conditionnelle avec un BranchPythonOperator. L'adresse task_id sera 'validate_result', et l'adresse python_callable appellera la fonction de validation. Le paramètre op_args sera utilisé pour transmettre le résultat de la tâche précédente, 'get_movie_ratings', à la fonction de validation.
Si la validation est réussie, nous prendrons les données de la tâche 'get_movie_ratings' et les indexerons dans Elasticsearch. Pour ce faire, nous allons créer une nouvelle tâche, 'index_movie_ratings', qui utilisera l'opérateur Python. Le paramètre op_args transmet les résultats de la tâche 'get_movie_ratings' à la fonction d'indexation.
Si la validation indique un échec, le DAG passe à une tâche de notification d'échec. Dans cet exemple, nous nous contentons d'imprimer un message, mais dans un scénario réel, nous pourrions configurer des alertes pour signaler les défaillances.
Enfin, nous définissons les dépendances des tâches, en veillant à ce qu'elles s'exécutent dans le bon ordre :
Voici maintenant le code complet de notre DAG :
Visualisation de l'exécution du DAG
Dans l'interface Apache Airflow, nous pouvons visualiser l'exécution des DAGs. Il suffit d'aller sur l'onglet "DAGs" et de localiser le DAG que vous avez créé.
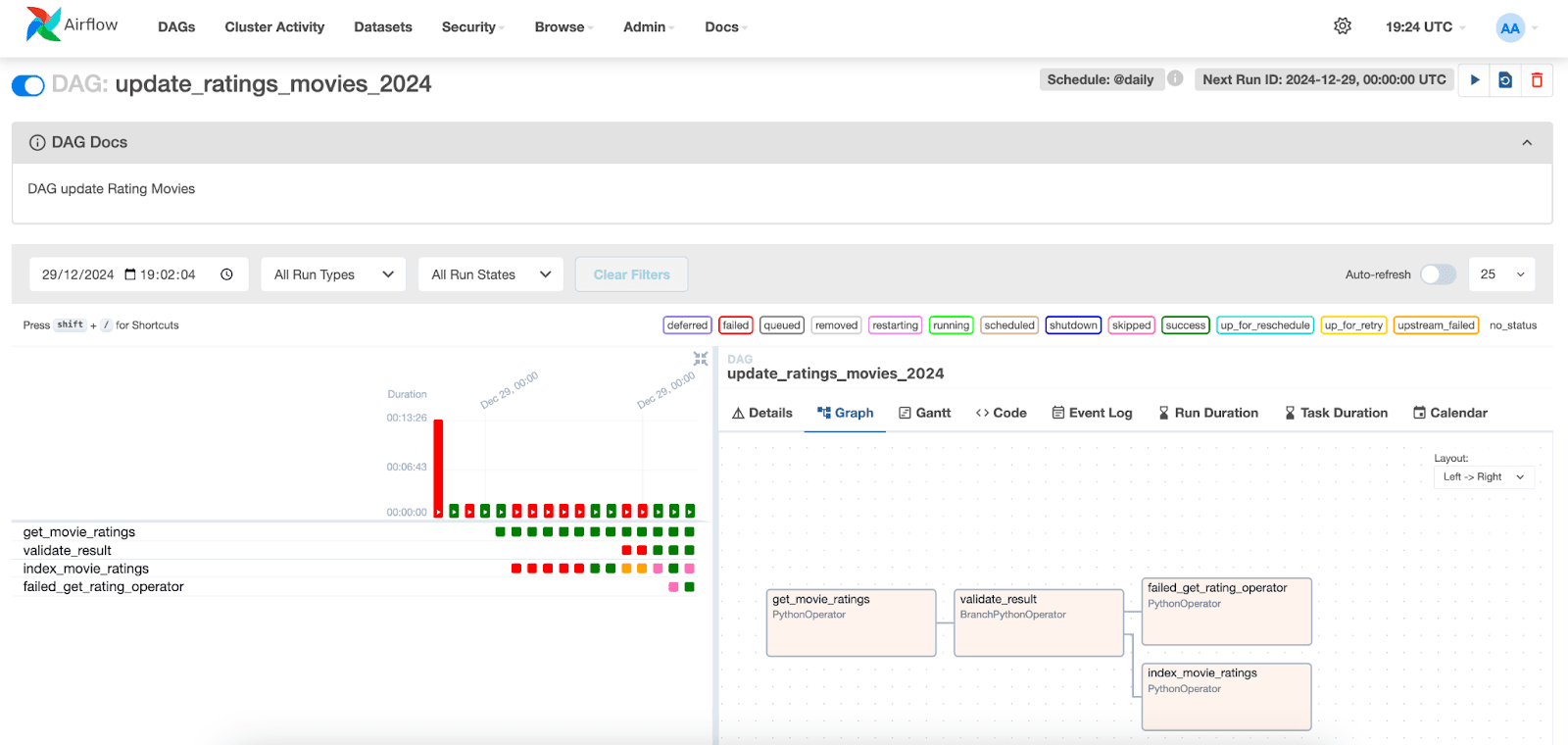
Ci-dessous, nous pouvons visualiser les exécutions des tâches et leurs statuts respectifs. En sélectionnant une exécution pour une date spécifique, nous pouvons accéder aux journaux de chaque tâche. Notez que dans la tâche index_movie_ratings, nous pouvons voir les résultats de l'indexation dans l'index, et qu'elle s'est déroulée avec succès.

Dans les autres onglets, il est possible d'accéder à des informations supplémentaires sur les tâches et le GDA, ce qui facilite l'analyse et la résolution des problèmes potentiels.
Conclusion
Dans cet article, nous avons montré comment intégrer Apache Airflow à Elasticsearch pour créer une solution d'ingestion de données. Nous avons montré comment configurer le DAG, définir les tâches responsables de la récupération, de la validation et de l'indexation des données des films, ainsi que contrôler et visualiser l'exécution de ces tâches dans l'interface Airflow.
Cette approche peut être facilement adaptée à différents types de données et de flux de travail, ce qui fait d'Airflow un outil utile pour orchestrer les pipelines de données dans divers scénarios.
Références
Apache AirFlow
Installer Apache Airflow avec Docker
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
Elasticsearch Python Hook
Opérateur Python
https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html
Questions fréquentes
Qu'est-ce que le flux d'air Apache ?
Apache Airflow est une plateforme conçue pour créer, planifier et contrôler les flux de travail.
À quoi sert Apache Airflow ?
Apache Airflow est utilisé pour orchestrer des processus ETL, des pipelines de données et d'autres flux de travail complexes, offrant flexibilité et évolutivité.
Quels sont les principaux composants d'Apache Airflow ?
Les principaux composants d'Airflow sont les suivants : Scheduler, Executor, Web Server, Dags Folder et Metadata.
Apache Airflow peut-il être intégré à Elasticsearch ?
Oui, Apache Airflow peut être intégré à Elasticsearch, par exemple vous pouvez utiliser Apache Airflow pour orchestrer des tâches et indexer les résultats dans Elasticsearch.
Qu'est-ce qu'un DAG dans Apache Airflow ?
Dans Airflow, les flux de travail sont représentés par des DAG (Directed Acyclic Graphs). Un DAG est une structure qui définit la séquence d'exécution des tâches.
Pour aller plus loin

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

22 septembre 2025
Elastic Open Web Crawler en tant que code
Apprenez à utiliser les actions GitHub pour gérer les configurations d'Elastic Open Crawler, de sorte que chaque fois que nous apportons des modifications au référentiel, celles-ci sont automatiquement appliquées à l'instance déployée du crawler.

6 août 2025
Comment afficher les champs d'un index Elasticsearch ?
Apprenez à afficher les champs d'un index Elasticsearch à l'aide des API _mapping et _search, des sous-champs, de la _source synthétique et des champs d'exécution.

24 juin 2025
Scripting Ruby dans Logstash
Découvrez le plugin Logstash Ruby filter pour une transformation avancée des données dans votre pipeline Logstash.

26 mai 2025
Affichage des champs dans un index Elasticsearch
Exploration des techniques d'affichage des champs dans un index Elasticsearch.