Cet article de blog se penche sur les flux de travail agentiques RAG, en expliquant leurs principales caractéristiques et les modèles de conception courants. Il démontre en outre comment mettre en œuvre ces flux de travail au moyen d'un exemple pratique qui utilise Elasticsearch comme magasin de vecteurs et LangChain pour construire le cadre agentique RAG. Enfin, l'article aborde brièvement les meilleures pratiques et les défis associés à la conception et à la mise en œuvre de ces architectures. Vous pouvez suivre la création d'un simple pipeline RAG agentique avec ce carnet Jupyter.
Introduction au RAG agentique
La Génération Augmentée de Récupération(RAG) est devenue la pierre angulaire des applications basées sur le LLM, permettant aux modèles de fournir des réponses optimales en récupérant le contexte pertinent basé sur les requêtes de l'utilisateur. Les systèmes RAG améliorent la précision et le contexte des réponses LLM en s'appuyant sur des informations externes provenant d'API ou de magasins de données, au lieu d'être limités à des connaissances LLM préformées. D'autre part, les agents d'intelligence artificielle fonctionnent de manière autonome, prenant des décisions et des mesures pour atteindre les objectifs qui leur sont assignés.
Le RAG agentique est un cadre qui unifie les forces de la génération augmentée par la recherche et du raisonnement agentique. Il intègre le RAG dans le processus décisionnel de l'agent, ce qui permet au système de choisir dynamiquement les sources de données, d'affiner les requêtes pour une meilleure récupération du contexte, de générer des réponses plus précises et d'appliquer une boucle de rétroaction pour améliorer continuellement la qualité des résultats.
Principales caractéristiques du RAG agentic
Le cadre agentique des RAG constitue une avancée majeure par rapport aux systèmes traditionnels de RAG. Au lieu de suivre un processus de recherche fixe, il s'appuie sur des agents dynamiques capables de planifier, d'exécuter et d'optimiser les résultats en temps réel.
Examinons quelques-unes des principales caractéristiques qui distinguent les pipelines RAG agentiques :
- Prise de décision dynamique: Le RAG agentique utilise un mécanisme de raisonnement pour comprendre l'intention de l'utilisateur et acheminer chaque requête vers la source de données la plus pertinente, produisant ainsi des réponses précises et adaptées au contexte.
- Analyse complète des requêtes : Agentic RAG analyse en profondeur les requêtes des utilisateurs, y compris les sous-questions et leur intention générale. Il évalue la complexité des requêtes et sélectionne de manière dynamique les sources de données les plus pertinentes pour récupérer les informations, garantissant ainsi des réponses précises et complètes.
- Collaboration en plusieurs étapes: Ce cadre permet une collaboration en plusieurs étapes grâce à un réseau d'agents spécialisés. Chaque agent s'occupe d'une partie spécifique d'un objectif plus large, travaillant de manière séquentielle ou simultanée pour atteindre un résultat cohérent.
- Mécanismes d'auto-évaluation: Le pipeline RAG agentique utilise l'autoréflexion pour évaluer les documents récupérés et les réponses générées. Il peut vérifier si les informations extraites répondent entièrement à la requête, puis vérifier l'exactitude, l'exhaustivité et la cohérence factuelle des résultats.
- Intégration avec des outils externes: Ce flux de travail peut interagir avec des API externes, des bases de données et des sources d'information en temps réel, en incorporant des informations actualisées et en s'adaptant dynamiquement à l'évolution des données.
Modèles de flux de travail des RAG agentiques
Les modèles de flux de travail définissent la manière dont l'IA agentique structure, gère et orchestre les applications basées sur le LLM de manière fiable et efficace. Plusieurs cadres et plateformes, tels que LangChain, LangGraph, CrewAI et LlamaIndex, peuvent être utilisés pour mettre en œuvre ces flux de travail agentiques.
- Chaîne de récupération séquentielle: Les flux de travail séquentiels divisent les tâches complexes en étapes simples et ordonnées. Chaque étape améliore les données de l'étape suivante, ce qui permet d'obtenir de meilleurs résultats. Par exemple, lors de la création d'un profil de client, un agent peut extraire les détails de base d'un CRM, un autre récupère l'historique des achats dans une base de données de transactions, et un dernier agent combine ces informations pour générer un profil complet en vue de recommandations ou de rapports.
- Chaîne de recherche de routage: Dans ce modèle de flux de travail, un agent routeur analyse l'entrée et la dirige vers le processus ou la source de données la plus appropriée. Cette approche est particulièrement efficace lorsqu'il existe plusieurs sources de données distinctes se chevauchant très peu. Par exemple, dans un système de service à la clientèle, l'agent de routage classe les demandes entrantes, telles que les problèmes techniques, les remboursements ou les réclamations, et les achemine vers le service approprié pour un traitement efficace.
- Chaîne de recherche parallèle: Dans ce modèle de flux de travail, plusieurs sous-tâches indépendantes sont exécutées simultanément et leurs résultats sont ensuite agrégés pour générer une réponse finale. Cette approche permet de réduire considérablement le temps de traitement et d'accroître l'efficacité du flux de travail. Par exemple, dans un flux de travail parallèle de service à la clientèle, un agent récupère les demandes antérieures similaires et un autre consulte les articles pertinents de la base de connaissances. Un agrégateur combine ensuite ces résultats pour produire une résolution complète.
- Chaîne de travail de l'Orchestrator: Ce flux de travail présente des similitudes avec la parallélisation en raison de l'utilisation de sous-tâches indépendantes. Cependant, une distinction essentielle réside dans l'intégration d'un agent orchestrateur. Cet agent est chargé d'analyser les requêtes des utilisateurs, de les segmenter dynamiquement en sous-tâches au cours de l'exécution et d'identifier les processus ou outils appropriés nécessaires pour formuler une réponse précise.

Construire un pipeline RAG agentique à partir de zéro
Pour illustrer les principes du RAG agentique, concevons un flux de travail utilisant LangChain et Elasticsearch. Ce flux de travail adopte une architecture basée sur le routage, où plusieurs agents collaborent pour analyser les requêtes, récupérer les informations pertinentes, évaluer les résultats et générer des réponses cohérentes. Vous pouvez vous référer à ce carnet Jupyter pour suivre cet exemple.
Le flux de travail commence par l'agent routeur, qui analyse la requête de l'utilisateur pour sélectionner la méthode de recherche optimale, c'est-à-dire l'approche vectorstore, websearch ou composite. Le magasin vectoriel gère la recherche traditionnelle de documents basée sur le RAG, la recherche sur le web récupère les informations les plus récentes qui ne sont pas stockées dans le magasin vectoriel, et l'approche composite combine les deux lorsque des informations provenant de sources multiples sont nécessaires.
Si les documents sont jugés appropriés, l'agent de synthèse génère une réponse claire et adaptée au contexte. Toutefois, si les documents sont insuffisants ou non pertinents, l'agent de réécriture des requêtes reformule la requête pour améliorer la recherche. Cette requête révisée réinitialise alors le processus de routage, ce qui permet au système d'affiner sa recherche et d'améliorer le résultat final.
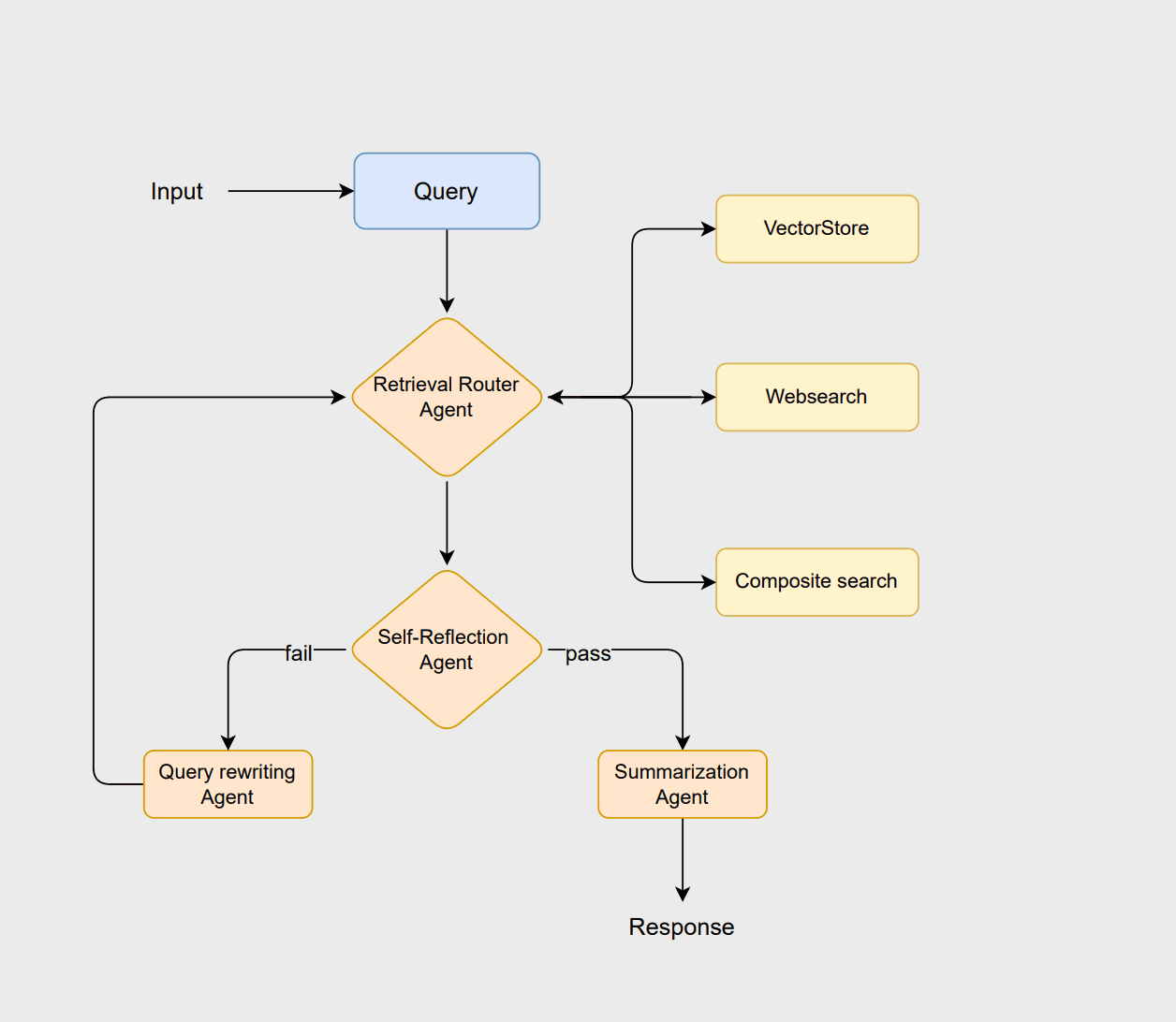
Produits requis
Ce flux de travail s'appuie sur les composants de base suivants pour exécuter l'exemple de manière efficace :
- Python 3.10
- Bloc-notes Jupyter
- Azure OpenAI
- Elasticsearch
- LangChain
Avant de poursuivre, vous serez invité à configurer l'ensemble des variables d'environnement requises pour cet exemple.
Sources de données
Ce processus est illustré à l'aide d'un sous-ensemble du jeu de données AG News. L'ensemble des données comprend des articles d'actualité dans diverses catégories, telles que International, Sports, Affaires et Science/Technologie.
Le module ElasticsearchStore est utilisé à partir de langchain_elasticsearch comme magasin de vecteurs. Pour la recherche, nous mettons en œuvre la stratégie SparseVectorStrategy, en utilisant ELSER, le modèle d'intégration propriétaire d'Elastic. Il est essentiel de confirmer que le modèle ELSER est correctement installé et déployé dans votre environnement Elasticsearch avant d'initier le magasin de vecteurs.
La fonctionnalité de recherche sur le web est mise en œuvre à l'aide de DuckDuckGoSearchRun des outils de la communauté LangChain, ce qui permet au système de récupérer efficacement des informations en direct sur le web. Vous pouvez également envisager d'utiliser d'autres API de recherche qui peuvent fournir des résultats plus pertinents. Cet outil a été choisi car il permet d'effectuer des recherches sans avoir besoin d'une clé API.
L'extracteur composite est conçu pour les requêtes qui nécessitent une combinaison de sources. Il est utilisé pour fournir une réponse complète et contextuelle précise en récupérant simultanément des données en temps réel sur le web et en consultant les informations historiques du magasin de vecteurs.
Mise en place des agents
Dans l'étape suivante, les agents LLM sont définis pour fournir des capacités de raisonnement et de prise de décision au sein de ce flux de travail. Les chaînes LLM que nous créerons sont les suivantes router_chain, grade_docs_chain, rewrite_query_chain, et summary_chain.
L'agent routeur utilise un assistant LLM pour déterminer la source de données la plus appropriée pour une requête donnée au moment de l'exécution. L'agent de classement évalue la pertinence des documents récupérés. Si les documents sont jugés pertinents, ils sont transmis à l'agent de synthèse pour générer un résumé. Dans le cas contraire, l'agent de réécriture reformule la requête et la renvoie au processus de routage pour une nouvelle tentative de recherche. Vous trouverez les instructions pour tous les agents dans la section chaînes LLM du carnet de notes.
Le site llm.with_structured_output contraint les résultats du modèle à suivre un schéma prédéfini par le BaseModel sous la classe RouteQuery, ce qui garantit la cohérence des résultats. La deuxième ligne compose un RunnableSequence en reliant router_prompt à router_structured, formant un pipeline dans lequel l'invite d'entrée est traitée par le modèle de langage pour produire des résultats structurés et conformes au schéma.
Définir les nœuds d'un graphique
Cette partie consiste à définir les états du graphe, qui représentent les données circulant entre les différents composants du système. Une spécification claire de ces états garantit que chaque nœud du flux de travail sait à quelles informations il peut accéder et les mettre à jour.
Une fois les états définis, l'étape suivante consiste à définir les nœuds du graphe. Les nœuds sont en quelque sorte les unités fonctionnelles du graphique qui effectuent des opérations spécifiques sur les données. Il y a 7 nœuds différents dans notre pipeline.
Le nœud query_rewriter a deux fonctions dans le flux de travail. Tout d'abord, il réécrit la requête de l'utilisateur à l'aide du site rewrite_query_chain pour améliorer la recherche lorsque les documents évalués par l'agent d'autoréflexion sont jugés insuffisants ou non pertinents. Deuxièmement, il sert de compteur pour savoir combien de fois la requête a été réécrite.
Chaque fois que le nœud est invoqué, il incrémente le site retry_count stocké dans l'état du flux de travail. Ce mécanisme empêche le flux de travail d'entrer dans une boucle infinie. Si le site retry_count dépasse un seuil prédéfini, le système peut passer à un état d'erreur, à une réponse par défaut ou à toute autre condition prédéfinie de votre choix.
Compilation du graphique
La dernière étape consiste à définir les arêtes du graphe et à ajouter toutes les conditions nécessaires avant de le compiler. Chaque graphe doit partir d'un nœud de départ désigné, qui sert de point d'entrée au flux de travail. Les arêtes du graphique représentent le flux de données entre les nœuds et peuvent être de deux types :
- Arêtes droites : Ils définissent un flux direct et inconditionnel d'un nœud à l'autre. Chaque fois que le premier nœud termine sa tâche, le flux de travail passe automatiquement au nœud suivant le long de la ligne droite.
- Arêtes conditionnelles : Elles permettent au flux de travail de se ramifier en fonction de l'état actuel ou des résultats du calcul d'un nœud. Le nœud suivant est sélectionné dynamiquement en fonction de conditions telles que les résultats de l'évaluation, les décisions de routage ou le nombre de tentatives.
Votre premier pipeline RAG agentique est donc prêt et peut être testé à l'aide de l'agent compilé.
Test du pipeline RAG agentique
Nous allons maintenant tester ce pipeline en utilisant trois types de requêtes distinctes, comme indiqué ci-dessous. Il convient de noter que les résultats peuvent varier et que les exemples présentés ci-dessous n'illustrent qu'un résultat potentiel.
Pour la première requête, le routeur sélectionne websearch comme source de données. La requête échoue à l'évaluation de l'autoréflexion et est ensuite redirigée vers l'étape de réécriture de la requête, comme le montre la sortie.
Ensuite, nous examinons un exemple où vectorstore est utilisé, avec la deuxième requête.
La requête finale est dirigée vers la recherche composite, qui utilise à la fois le magasin de vecteurs et la recherche sur le web.
Dans le flux de travail ci-dessus, le RAG agentique détermine intelligemment quelle source de données utiliser lors de la recherche d'informations pour une requête de l'utilisateur, améliorant ainsi la précision et la pertinence de la réponse. Vous pouvez créer des exemples supplémentaires pour tester l'agent et examiner les résultats pour voir s'ils produisent des résultats intéressants.
Meilleures pratiques pour l'élaboration de flux de travail agentiques de RAG
Maintenant que nous comprenons le fonctionnement du RAG agentique, examinons quelques bonnes pratiques pour la mise en place de ces flux de travail. Le respect de ces lignes directrices contribuera à maintenir l'efficacité du système et à en faciliter l'entretien.
- Préparez-vous à des solutions de repli: Planifiez à l'avance des stratégies de repli pour les scénarios dans lesquels une étape du flux de travail échoue. Il peut s'agir de renvoyer des réponses par défaut, de déclencher des états d'erreur ou d'utiliser d'autres outils. Cela permet au système de gérer les défaillances de manière gracieuse sans interrompre le flux de travail global.
- Mettre en œuvre une journalisation complète: Essayez de mettre en œuvre la journalisation à chaque étape du flux de travail, comme les tentatives, les résultats générés, les choix de routage et les réécritures de requêtes. Ces journaux permettent d'améliorer la transparence, de faciliter le débogage et d'affiner les messages-guides, le comportement de l'agent et les stratégies de recherche au fil du temps.
- Sélectionner le modèle de flux de travail approprié: Examinez votre cas d'utilisation et sélectionnez le modèle de flux de travail qui répond le mieux à vos besoins. Utilisez des flux séquentiels pour le raisonnement étape par étape, des flux parallèles pour les sources de données indépendantes et des modèles d'orchestrateur-worker pour les requêtes multi-outils ou complexes.
- Incorporer des stratégies d'évaluation: Intégrer des mécanismes d'évaluation à différents stades du processus. Il peut s'agir d'agents d'autoréflexion, de classement des documents extraits ou de contrôles de qualité automatisés. L'évaluation permet de vérifier que les documents récupérés sont pertinents, que les réponses sont exactes et que toutes les parties d'une requête complexe sont traitées.
Défis
Si les systèmes agentiques RAG offrent des avantages significatifs en termes d'adaptabilité, de précision et de raisonnement dynamique, ils s'accompagnent également de certains défis qui doivent être relevés lors de leur conception et de leur mise en œuvre. Voici quelques-uns des principaux défis à relever :
- Flux de travail complexes: Au fur et à mesure de l'ajout d'agents et de points de décision, le flux de travail global devient de plus en plus complexe. Cela peut augmenter les risques d'erreurs ou de défaillances au moment de l'exécution. Dans la mesure du possible, donnez la priorité à la rationalisation des flux de travail en éliminant les agents redondants et les points de décision inutiles.
- Évolutivité: Il peut être difficile de faire évoluer les systèmes RAG agentiques pour traiter de grands ensembles de données et des volumes d'interrogation élevés. Incorporer des stratégies efficaces d'indexation, de mise en cache et de traitement distribué pour maintenir les performances à l'échelle.
- Orchestration et surcharge de calcul: L'exécution de flux de travail avec plusieurs agents nécessite une orchestration avancée. Cela implique une programmation minutieuse, la gestion des dépendances et la coordination des agents afin d'éviter les goulets d'étranglement et les conflits, autant d'éléments qui ajoutent à la complexité globale du système.
- Complexité de l'évaluation: L'évaluation de ces flux de travail présente des défis inhérents, car chaque étape nécessite une stratégie d'évaluation distincte. Par exemple, l'étape RAG doit être évaluée en fonction de la pertinence et de l'exhaustivité des documents récupérés, tandis que les résumés générés doivent être vérifiés en termes de qualité et d'exactitude. De même, l'efficacité de la reformulation de la requête nécessite une logique d'évaluation distincte pour déterminer si la requête réécrite améliore les résultats de la recherche.
Conclusion
Dans cet article de blog, nous avons présenté le concept de RAG agentique et souligné comment il améliore le cadre traditionnel de RAG en incorporant des capacités autonomes de l'IA agentique. Nous avons exploré les caractéristiques principales du RAG agentique et les avons démontrées à l'aide d'un exemple pratique, en construisant un assistant de nouvelles utilisant Elasticsearch comme magasin de vecteurs et LangChain pour créer le cadre agentique.
En outre, nous avons discuté des meilleures pratiques et des principaux défis à prendre en compte lors de la conception et de la mise en œuvre d'un pipeline RAG agentique. Ces idées sont destinées à guider les développeurs dans la création de systèmes agentiques robustes, évolutifs et efficaces qui combinent de manière effective la recherche, le raisonnement et la prise de décision.
Prochaines étapes
Le flux de travail que nous avons mis en place est simple et laisse une large place aux améliorations et à l'expérimentation. Nous pouvons l'améliorer en expérimentant divers modèles d'intégration et en affinant les stratégies de recherche. En outre, l'intégration d'un agent de reclassement pour hiérarchiser les documents récupérés pourrait être bénéfique. Un autre domaine d'exploration concerne le développement de stratégies d'évaluation pour les cadres agentiques, en particulier l'identification d'approches communes et réutilisables applicables à différents types de cadres. Enfin, l'expérimentation de ces cadres sur des ensembles de données plus vastes et plus complexes.
En attendant, si vous avez des expériences similaires à partager, nous serions ravis de les connaître ! N'hésitez pas à nous faire part de vos commentaires ou à vous connecter avec nous via notre canal Slack communautaire ou nos forums de discussion.
Ressources
Pour aller plus loin

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

23 mars 2026
Utilisation de l'API d'inférence Elasticsearch avec les modèles Hugging Face
Découvrez comment connecter Elasticsearch aux modèles Hugging Face à l'aide de points de terminaison d'inférence, et comment créer un système de recommandation de blogs multilingue avec recherche sémantique et complétion de chat.

27 mars 2026
Création d'un serveur Elasticsearch MCP avec TypeScript
Apprenez à créer un serveur MCP Elasticsearch avec TypeScript et Claude Desktop.
17 mars 2026
L'extension Gemini CLI pour Elasticsearch avec des outils et des fonctionnalités
Présentation de l’extension Elastic pour le CLI Gemini de Google, afin de rechercher, récupérer et analyser les données Elasticsearch dans les workflows des développeurs et des agents.