Este es el primer artículo de un serial que explica cómo usar Elasticsearch con JavaScript. En este serial, aprenderás lo básico sobre cómo usar Elasticsearch en un entorno JavaScript y revisarás las características y mejores prácticas más relevantes para crear una aplicación de búsqueda. Al final, sabrás todo lo necesario para ejecutar Elasticsearch usando JavaScript.
En esta primera parte, repasaremos:
Puedes consultar el código fuente con los ejemplos aquí.
¿Qué es el cliente de Node.js Elasticsearch?
El cliente Elasticsearch Node.js es una biblioteca de JavaScript que introduce las llamadas HTTP REST de la API Elasticsearch a JavaScript. Esto facilita la gestión y cuenta con ayudas que simplifican tareas como indexar documentos en lotes.
Medio ambiente
¿Frontend, backend o serverless?
Para crear nuestra aplicación de búsqueda usando el cliente JavaScript, necesitamos al menos dos componentes: un clúster Elasticsearch y un entorno de ejecución en JavaScript para ejecutar el cliente.
El cliente JavaScript soporta todas las soluciones Elasticsearch (Cloud, local y Serverless), y no hay diferencias importantes entre ellas ya que el cliente gestiona todas las variaciones internamente, así que no tienes que preocuparte por cuál usar.
Sin embargo, el tiempo de ejecución de JavaScript debe ejecutar desde el servidor y no directamente desde el navegador.
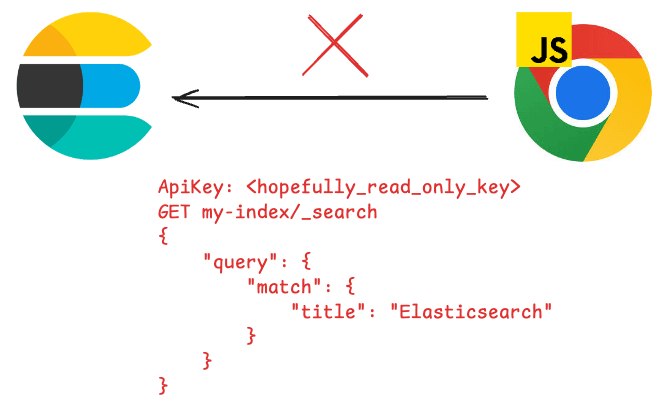
Esto se debe a que, al llamar a Elasticsearch desde el navegador, el usuario puede obtener información sensible como la clave de la API del clúster, el host o la propia consulta. Elasticsearch recomienda no exponer nunca el clúster directamente a Internet y usar una capa intermedia que abstraiga toda esta información para que el usuario solo pueda ver los parámetros. Puedes leer más sobre este tema aquí.
Sugerimos usar un esquema como este:

En este caso, el cliente solo envía los términos de búsqueda y una clave de autenticación para tu servidor mientras este tiene el control total de la consulta y la comunicación con Elasticsearch.
Conexión del cliente
Empieza creando una clave API siguiendo estos pasos.
Siguiendo el ejemplo anterior, crearemos un servidor Express sencillo y nos conectaremos a él usando un cliente de un servidor Node.JS.
Inicializaremos el proyecto con NPM e instalaremos el cliente Elasticsearch y Express. Esta última es una biblioteca para abrir servidores en Node.js. Usando Express, podemos interactuar con nuestro backend vía HTTP.
Inicialemos el proyecto:
npm init -y
Dependencias de instalación:
npm install @elastic/elasticsearch express split2 dotenv
Déjame explicártelo:
- @elastic/elasticsearch: Es el cliente oficial de Node.js
- express: Nos permitirá montar un servidor nodejs ligero para exponer Elasticsearch
- split2: Divide líneas de texto en un flujo. Útil para procesar nuestros archivos de ndjson línea a línea
- dotenv: Permítenos gestionar variables de entorno usando un .env archivo
Crea un .env archiva en la raíz del proyecto y agrega las siguientes líneas:
De esta manera, podemos importar esas variables usando el paquete dotenv .
Crea un archivo server.js :
Este código configura un servidor de Express.js básico que escucha en el puerto 3000 y se conecta a un clúster Elasticsearch usando una clave API para autenticación. Incluye un punto final /ping que, al acceder mediante una solicitud GET, consulta al clúster de Elasticsearch información básica empleando el método .info() del cliente Elasticsearch.
Si la consulta tiene éxito, devuelve la información del clúster en formato JSON; de lo contrario, devuelve un mensaje de error. El servidor también emplea middleware de parser corporal para gestionar los cuerpos de las solicitudes JSON.
Ejecuta el archivo para abrir el servidor:
node server.js
La respuesta debería ser la siguiente:
Y ahora, consultemos el /ping endpoint para comprobar el estado de nuestro clúster de Elasticsearch.
Indexación de documentos
Una vez conectados, podemos indexar documentos usando mapeos como semantic_text para búsqueda semántica y texto para consultas de texto completo. Con estos dos tipos de campos, también podemos hacer búsqueda híbrida.
Crearemos un nuevo archivo load.js para generar los mapeos y subir los documentos.
Cliente Elasticsearch
Primero necesitamos instanciar y autenticar al cliente:
Aplicaciones semánticas
Crearemos un índice con datos sobre un hospital veterinario. Almacenaremos la información del dueño, la mascota y los detalles de la visita.
Los datos sobre los que queremos realizar la búsqueda en texto completo, como nombres y descripciones, se almacenarán como texto. Los datos de categorías, como la especie o raza del animal, se almacenarán como palabras clave.
Además, copiaremos los valores de todos los campos en un campo semantic_text para poder ejecutar una búsqueda semántica también con esa información.
Ayudante a granel
Otro beneficio del cliente es que podemos usar el helper de mayor volumen para indexar en lotes. El helper en bulk nos permite gestionar fácilmente cosas como la concurrencia, los intentos y qué hacer con cada documento que pasa por la función y que tiene éxito o fracasa.
Una característica atractiva de este asistente es que puedes trabajar con streams. Esta función te permite enviar un archivo línea por línea en lugar de almacenar el archivo completo en la memoria y enviarlo a Elasticsearch de una sola vez.
Para subir los datos a Elasticsearch, crea un archivo llamado data.ndjson en la raíz del proyecto y agrega la información que aparece a continuación (alternativamente, puedes descargar el archivo con el conjunto de datos desde aquí):
Usamos split2 para transmitir las líneas de archivo mientras el asistente masivo las envía a Elasticsearch.
El código anterior dice un .ndjson archivo línea por línea y en volumen indexa cada objeto JSON en un índice Elasticsearch especificado usando el método helpers.bulk . Transmite el archivo usando createReadStream y split2, establece metadatos de indexación para cada documento y registra cualquier documento que no se procese. Una vez completado, registra el número de elementos indexados con éxito.
Alternativamente a la función indexData , puedes subir el archivo directamente a través de la interfaz usando Kibana y usar la interfaz de archivos de datos de subida.
Ejecutamos el archivo para subir los documentos a nuestro clúster de Elasticsearch.
node load.js
Búsqueda de datos en Elasticsearch
Volviendo a nuestro archivo server.js , crearemos diferentes endpoints para realizar búsquedas léxicas, semánticas o híbridas.
En resumen, este tipo de búsquedas no son mutuamente excluyentes, sino que dependerán del tipo de pregunta que necesites responder.
| Tipo de consulta | Caso de uso | Pregunta de ejemplo |
|---|---|---|
| Consulta léxica | Las palabras o raíces de palabras en la pregunta probablemente aparecerán en los documentos del índice. Similitud de token entre la pregunta y los documentos. | Busco una camiseta deportiva azul. |
| Consulta semántica | Las palabras de la pregunta probablemente no aparecerán en los documentos. Similitud conceptual entre la pregunta y los documentos. | Busco ropa para el frío. |
| Búsqueda híbrida | La pregunta contiene componentes léxicos y/o semánticos. Similitud de tokens y semántica entre la pregunta y los documentos. | Estoy buscando un vestido talla S para una boda en la playa. |
Las partes léxicas de la pregunta probablemente formarán parte de títulos y descripciones, o nombres de categorías, mientras que las partes semánticas son conceptos relacionados con esos campos. El azul probablemente será un nombre de categoría o parte de una descripción, y la boda en la playa probablemente no lo sea, pero puede estar semánticamente relacionada con la ropa de lino.
Consulta léxica (/search/lexic?q=<query_term>)
La búsqueda léxica, también llamada búsqueda de texto completo, significa búsqueda basada en la similitud de los tokens; es decir, tras un análisis, se devolverán los documentos que incluyan los tokens en la búsqueda.
Puedes consultar nuestro tutorial práctico de búsqueda léxica aquí.
Probamos con: corte de uñas
Respuesta:
Consulta semántica (/search/semantic?q=<query_term>)
La búsqueda semántica, a diferencia de la búsqueda léxica, encuentra resultados similares al significado de los términos de búsqueda mediante la búsqueda vectorial.
Puedes consultar nuestro tutorial práctico de búsqueda semántica aquí.
Hacemos la prueba con: ¿Quién se hizo una pedicura?
Respuesta:
Consulta híbrida (/search/hybrid?q=<query_term>)
La búsqueda híbrida nos permite combinar la búsqueda semántica y léxica, obteniendo así lo mejor de ambos mundos: se obtiene la precisión de buscar por token, junto con la proximidad de significado de la búsqueda semántica.
Hacemos pruebas con "¿Quién se hizo pedicura o tratamiento dental?"
Respuesta:
Conclusión
En esta primera parte de nuestro serial, explicamos cómo configurar nuestro entorno y crear un servidor con diferentes endpoints de búsqueda para consultar los documentos de Elasticsearch siguiendo las mejores prácticas cliente/servidor. Consulta la segunda parte de nuestro serial, en la que aprenderás las mejores prácticas de producción y cómo ejecutar el cliente de Node.js Elasticsearch en entornos serverless.
Preguntas frecuentes
¿Qué es el cliente de Node.js?
El cliente Node.js es una biblioteca de JavaScript que introduce las llamadas HTTP REST de la API Elasticsearch a JavaScript. Facilita contar con ayudantes que simplifican tareas como indexar documentos en batch.
¿Por qué deberías usar un entorno Node.js del lado del servidor en lugar de llamar a Elasticsearch desde la interfaz?
La seguridad es el principal beneficio. Ejecutar el cliente en un entorno backend (como Node.js con Express) previene que información sensible (como claves de API del clúster, URLs de host y lógica interna de consultas) sea expuesta al navegador.
¿Cuáles son las ventajas de usar Elasticsearch "Bulk Helper" en Node.js?
Las principales ventajas de utilizar "Bulk Helper" de Elasticsearch en Node.js son: Indexación batch: Maneja automáticamente la complejidad de indexar documentos en grupos en lugar de uno por uno. Soporte para transmisión: Usando herramientas como split2, puedes transmitir archivos (como .ndjson) línea por línea. Esto te permite procesar archivos masivos sin cargar el set de datos completo en la memoria de tu servidor.
Contenido relacionado

14 de noviembre de 2025
Cómo desplegar Elasticsearch en Azure AKS Automatic
Aprende cómo desplegar Elasticsearch con Kibana en Azure usando AKS Automatic y ECK para una configuración parcialmente gestionada de Elasticsearch.

11 de noviembre de 2025
Configuración del fragmento recursivo para documentos estructurados en Elasticsearch
Aprende a configurar el chunking recursivo en Elasticsearch con tamaño de bloque, grupos de separadores y listas de separadores personalizadas para una indexación óptima de documentos estructurados.

7 de noviembre de 2025
Introducción de la interfaz de reglas de consulta Elasticsearch en Kibana
Aprende a usar la interfaz de Reglas de Consulta de Elasticsearch para agregar o excluir documentos de consultas de búsqueda usando conjuntos de reglas personalizables en Kibana, sin afectar al ranking orgánico.

3 de octubre de 2025
Cómo desplegar Elasticsearch en AWS Marketplace
Aprende a configurar y ejecutar Elasticsearch utilizando Elastic Cloud Service en AWS Marketplace con esta guía paso a paso.

14 de agosto de 2025
Fragmentos y réplicas de Elasticsearch: Una guía práctica
Domina los conceptos de fragmentos y réplicas de Elasticsearch y aprende a optimizarlos.