¿Todavía no conoces Elasticsearch? Únete a nuestro webinar de los Primeros pasos con Elasticsearch. También puedes iniciar una prueba gratuita en el cloud o prueba Elastic en tu máquina ahora mismo.
El tamaño del heap es la cantidad de RAM asignada a la Máquina Virtual Java de un nodo Elasticsearch.
A partir de la versión 7.11, Elasticsearch por defecto establece automáticamente el tamaño del montón de la JVM en función de los roles y la memoria total de un nodo. Se recomienda usar el tamaño por defecto para la mayoría de entornos de producción. Sin embargo, si quieres configurar manualmente el tamaño del montón de tu JVM, como regla general deberías poner -Xms y -Xmx al MISMO valor, que debería ser el 50% de tu RAM disponible total, sujeto a un máximo (aproximadamente) 31GB.
Un tamaño de heap mayor le dará a tu nodo más memoria para las operaciones de indexación y búsqueda. Sin embargo, tu nodo también requiere memoria para la caché, así que usar el 50% mantiene un equilibrio saludable entre ambos. Por esta misma razón, en producción deberías evitar usar otros procesos que consumen mucho memoria en el mismo nodo que Elasticsearch.
Normalmente, el uso del montón sigue un patrón de dientes de sierra, oscilando entre alrededor del 30 y el 70% del montón máximo empleado. Esto se debe a que la JVM aumenta de forma constante el porcentaje de uso del montón hasta que el proceso de recogida de basura libera memoria de nuevo. El alto uso del montón ocurre cuando el proceso de recogida de basura no puede seguir el ritmo. Un indicador de un alto uso del montón es cuando la recolección de basura no es capaz de reducir el uso del montón a alrededor del 30%.

En la imagen de arriba, puedes ver un diente de sierra normal del montón de JVM.
También verás que hay dos tipos de recogida de basura: GC joven y vieja.
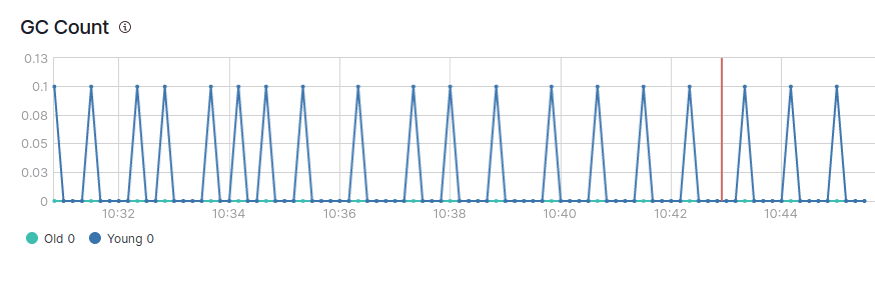
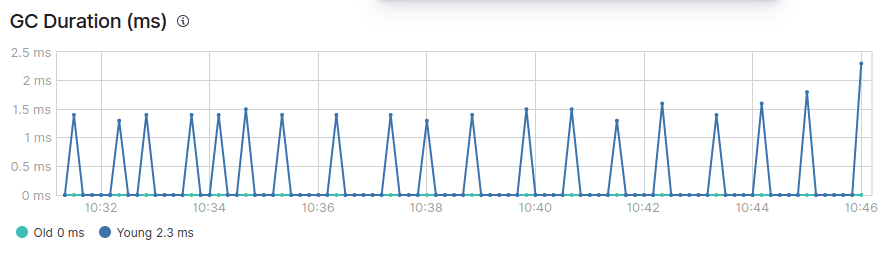
En una JVM saludable, la recogida de basura debería cumplir idealmente las siguientes condiciones:
- El GC joven se procesa rápidamente (en menos de 50 ms).
- La GC joven no se ejecuta con frecuencia (unos 10 segundos).
- El GC antiguo se procesa rápidamente (en menos de 1 segundo).
- El GC antiguo no se ejecuta con frecuencia (una vez cada 10 minutos o más).
Cómo resolver cuando el uso de memoria del heap es demasiado alto o cuando el rendimiento de la JVM no es óptimo
Puede haber varias razones por las que el uso de memoria heap puede aumentar:
Fragmentación de fragmentos
Por favor, consulta el documento sobre sobrefragmentación aquí.
Grandes tamaños de agregación
Para evitar grandes tamaños de agregación, mantén al mínimo el número de cubos de agregación (tamaño) en tus consultas.
Puedes usar el registro lento de consultas (registros lentos) e implementarlo en un índice específico usando lo siguiente.
Las consultas que tardan mucho en devolver los resultados suelen ser las que requieren muchos recursos.
Tamaño excesivo del índice de volumen
Si envías peticiones grandes, esto puede ser una causa de un alto consumo de heaps. Prueba a reducir el tamaño de las solicitudes de índice masivo.
Problemas de cartografía
En individuo, si usas "fielddata: true", entonces puede ser un usuario importante de tu montón JVM.
Tamaño del montón incorrectamente configurado
El tamaño del heap puede definir manualmente por:
Establecer la variable de entorno:
Editar el archivo jvm.options en tu directorio de configuración de Elasticsearch:
La configuración de la variable ambiental tiene prioridad sobre la configuración de archivo.
Es necesario resetear el nodo para tener en cuenta la configuración.
Nuevo ratio de JVM configurado incorrectamente
Generalmente NO es necesario establecer esto, ya que Elasticsearch establece este valor por defecto. Este parámetro define la proporción de espacio disponible para objetos de "nueva generación" y "generación antigua" en la JVM.
Si ves que el antiguo GC se está volviendo muy frecuente, puedes probar a establecer específicamente este valor en el archivo jvm.options de tu directorio de configuración de Elasticsearch.
¿Cuáles son las mejores prácticas para gestionar el uso del tamaño del heap y la recogida de basura de la JVM en un gran clúster de Elasticsearch?
Las mejores prácticas para gestionar el uso del tamaño del heap y la recolección de basura de la JVM en un gran clúster de Elasticsearch son cerciorar que el tamaño del heap esté fijado en un máximo del 50% de la RAM disponible, y que la configuración de recogida de basura de la JVM esté optimizada para el caso de uso específico. Es importante monitorizar el tamaño del montón y las métricas de recogida de basura para cerciorar de que el clúster funciona de forma óptima. En concreto, es importante monitorizar el tamaño del montón de la JVM, el tiempo de recogida de basura y las pausas en la recogida. Además, es importante controlar el número de ciclos de recogida de basura y el tiempo dedicado a la recogida. Al monitorizar estas métricas, es posible identificar posibles problemas con el tamaño del montón o la configuración de recogida de basura y tomar medidas correctivas si es necesario.
Contenido relacionado

14 de noviembre de 2025
Cómo desplegar Elasticsearch en Azure AKS Automatic
Aprende cómo desplegar Elasticsearch con Kibana en Azure usando AKS Automatic y ECK para una configuración parcialmente gestionada de Elasticsearch.

11 de noviembre de 2025
Configuración del fragmento recursivo para documentos estructurados en Elasticsearch
Aprende a configurar el chunking recursivo en Elasticsearch con tamaño de bloque, grupos de separadores y listas de separadores personalizadas para una indexación óptima de documentos estructurados.

7 de noviembre de 2025
Introducción de la interfaz de reglas de consulta Elasticsearch en Kibana
Aprende a usar la interfaz de Reglas de Consulta de Elasticsearch para agregar o excluir documentos de consultas de búsqueda usando conjuntos de reglas personalizables en Kibana, sin afectar al ranking orgánico.

3 de octubre de 2025
Cómo desplegar Elasticsearch en AWS Marketplace
Aprende a configurar y ejecutar Elasticsearch utilizando Elastic Cloud Service en AWS Marketplace con esta guía paso a paso.

14 de agosto de 2025
Fragmentos y réplicas de Elasticsearch: Una guía práctica
Domina los conceptos de fragmentos y réplicas de Elasticsearch y aprende a optimizarlos.