Elasticsearch te permite indexar datos de manera rápida y flexible. Pruébalo gratis en el cloud o ejecútalo localmente para ver lo fácil que puede ser indexar.
En este artículo, mostramos cómo integrar Apache Kafka con Elasticsearch para la ingestión e indexación de datos. Proporcionaremos una visión general de Kafka, su concepto de productores y consumidores, y crearemos un índice de registros donde los mensajes serán recibidos e indexados a través de Apache Kafka. El proyecto está implementado en Python y el código está disponible en GitHub.
Prerrequisitos
- Docker y Docker Compose: Cerciórate de tener Docker y Docker Compose instalados en tu máquina.
- Python 3.x: Para ejecutar los scripts de productor y consumidor.
Introducción a Apache Kafka
Apache Kafka es una plataforma de streaming distribuida que permite una alta escalabilidad y disponibilidad, así como tolerancia a fallos. En Kafka, la gestión de datos se realiza a través de los componentes principales:
- Intermediario: responsable de almacenar y distribuir mensajes entre productores y consumidores.
- Zookeeper: gestiona y coordina los corredores Kafka, controlando el estado del clúster, los líderes de partición y la información del consumidor.
- Temas: canales donde se publican y almacenan datos para su consumo.
- Consumidores y productores: mientras los productores envían datos a los temas, los consumidores recuperan esos datos.
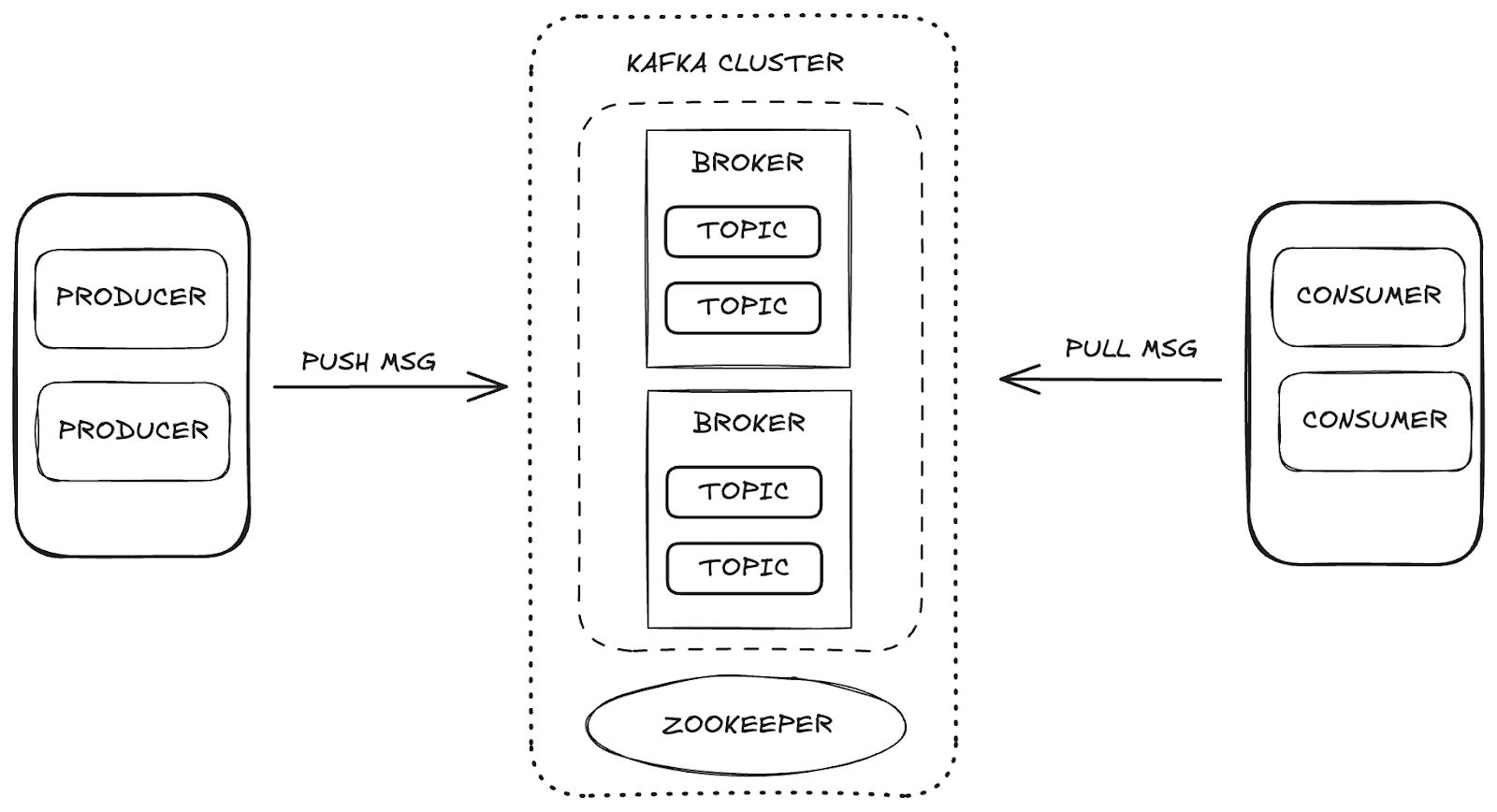
Estos componentes trabajan juntos para formar el ecosistema Kafka, proporcionando un marco robusto para el flujo de datos.
Estructura del proyecto
Para entender el proceso de ingesta de datos, lo dividimos en etapas:
- Aprovisionamiento de infraestructura: configurar el entorno Docker para soportar Kafka, Elasticsearch y Kibana.
- Creación de productores: implementando el Productor Kafka, que envía datos al tema de registros.
- Creación de Consumidores: desarrollar el Consumidor Kafka para leer e indexar mensajes en Elasticsearch.
- Validación de ingestión: verificar y validar los datos enviados y consumidos.
Configuración de infraestructura con Docker Compose
Empleamos Docker Compose para configurar y gestionar los servicios necesarios. A continuación, encontrarás el código Docker Compose que configura cada servicio necesario para la integración de Apache Kafka, Elasticsearch y Kibana, cerciorando un proceso de ingestión de datos.
Puedes acceder al archivo directamente desde el repositorio de GitHub de Elasticsearch Labs.
Envío de datos con el productor Kafka
El productor es responsable de enviar mensajes al tema de los logs. Al enviar mensajes en lotes, aumenta la eficiencia del uso de la red, permitiendo optimizaciones con los ajustes de batch_size y linger_ms , que controlan la cantidad y latencia de los lotes, respectivamente. La acks='all' de configuración garantiza que los mensajes se almacenen de forma duradera, lo cual es esencial para los datos de registro importantes.
Al iniciar el productor, los mensajes se envían en lotes sobre el tema, como se muestra a continuación:
Consumo e indexación de datos con el Kafka Consumer
El consumidor está diseñado para procesar mensajes de forma eficiente, consumiendo lotes del tema de logs e indexándolos en Elasticsearch. Con auto_offset_reset='latest', se cerciora que el consumidor empiece a procesar los mensajes más recientes, ignorando los antiguos, y max_poll_records=10 limita el lote a 10 mensajes. Con fetch_max_wait_ms=2000, el consumidor espera hasta 2 segundos para acumular suficientes mensajes antes de procesar el lote.
En su bucle principal, el consumidor consume mensajes de registro, procesa e indexa cada lote en Elasticsearch, cerciorando la ingestión continua de datos.
Visualización de datos en Kibana
Con Kibana, podemos explorar y validar los datos ingeridos de Kafka e indexados en Elasticsearch. Accediendo a Dev Tools en Kibana, puedes ver los mensajes indexados y confirmar que los datos son los esperados. Por ejemplo, si nuestro productor Kafka enviara 5 lotes de 10 mensajes cada uno, deberíamos ver un total de 50 registros en el índice.
Para verificar los datos, puedes usar la siguiente consulta en la sección de Herramientas de desarrollo :
Respuesta:

Además, Kibana ofrece la capacidad de crear visualizaciones y paneles que pueden ayudar a que el análisis sea más intuitivo e interactivo. A continuación, podéis ver algunos ejemplos de los paneles y visualizaciones que creamos, que ilustran los datos en varios formatos, mejorando nuestra comprensión de la información procesada.

Ingesta de datos con Kafka Connect
Kafka Connect es un servicio diseñado para facilitar la integración entre fuentes de datos y destinos (sumideros), como bases de datos o sistemas de archivos. Opera con conectores predefinidos que gestionan el movimiento de datos automáticamente. En nuestro caso, Elasticsearch funciona como el sumidero de datos.

Con Kafka Connect, podemos simplificar el proceso de ingesta de datos, eliminando la necesidad de implementar manualmente el flujo de trabajo de ingestión de datos en Elasticsearch. Con el conector adecuado, Kafka Connect permite que los datos enviados a un tema Kafka se indexen directamente en Elasticsearch con una configuración mínima y sin necesidad de codificación adicional.
Trabajando con Kafka Connect
Para implementar Kafka Connect, agregaremos el servicio kafka-connect a nuestra configuración de Docker Compose. Una parte clave de esta configuración es la instalación del conector Elasticsearch, que gestionará la indexación de datos.
Tras configurar el servicio y crear el contenedor Kafka Connect, será necesario un archivo de configuración para el conector Elasticsearch. Este archivo define parámetros esenciales como:
connection.url: URL de conexión para Elasticsearch.topics: El tema de Kafka que el conector monitorizará (en este caso, "logs").type.name: Tipo de documento en Elasticsearch (normalmente _doc).value.converter: Convierte los mensajes Kafka a formato JSON.value.converter.schemas.enable: Especifica si el esquema debe incluir.schema.ignoreykey.ignore: Ajustes para ignorar esquemas y claves de Kafka durante la indexación.
A continuación se muestra el comando curl para crear el conector Elasticsearch en Kafka Connect:
Con esta configuración, Kafka Connect comenzará automáticamente a ingerir los datos enviados al tema de "logs" e indexarlos en Elasticsearch. Este enfoque permite la ingesta e indexación de datos totalmente automatizada sin necesidad de codificación adicional, simplificando así todo el proceso de integración.
Conclusión
Integrar Kafka y Elasticsearch crea una poderosa cadena de procesamiento y análisis de datos en tiempo real. Esta guía proporciona un enfoque fundamental para construir una arquitectura robusta de ingestión de datos, con visualización y análisis fluidos en Kibana, lista para adaptar a requisitos más complejos en el futuro.
Además, usar Kafka Connect hace que la integración entre Kafka y Elasticsearch sea aún más ágil, eliminando la necesidad de código adicional para procesar e indexar datos. Kafka Connect permite que los datos enviados a un tema específico se indexen automáticamente en Elasticsearch con una configuración mínima.
Contenido relacionado

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

22 de septiembre de 2025
Rastreador Elástico de Sitio web Abierto como código
Aprende a usar GitHub Actions para gestionar configuraciones de Elastic Open Crawler, de modo que cada vez que enviemos cambios al repositorio, los cambios se apliquen automáticamente a la instancia desplegada del rastreador.

6 de agosto de 2025
Cómo mostrar los campos de un índice de Elasticsearch
Aprende a mostrar campos de un índice de Elasticsearch usando las APIs _mapping y _search, subcampos, _source sintéticos y campos de ejecución.

24 de junio de 2025
Guion Ruby en Logstash
Infórmate sobre el plugin de filtro Ruby Logstash para transformar datos avanzados en tu pipeline Logstash.

26 de mayo de 2025
Visualización de campos en un índice de Elasticsearch
Explorando técnicas para mostrar campos en un índice de Elasticsearch.