Elasticsearch te permite indexar datos de manera rápida y flexible. Pruébalo gratis en el cloud o ejecútalo localmente para ver lo fácil que puede ser indexar.
¿Qué es el Apache Airflow?
Apache Airflow es una plataforma diseñada para crear, programar y monitorizar flujos de trabajo. Se emplea para orquestar procesos ETL, pipelines de datos y otros flujos de trabajo complejos, ofreciendo flexibilidad y escalabilidad. Su interfaz visual y capacidades de monitorización en tiempo real hacen que la gestión de tuberías sea más accesible y eficiente, permitiéndote seguir el progreso y los resultados de tus ejecuciones. A continuación se presentan sus cuatro pilares principales:
- Dinámico: Las canalizaciones están definidas en Python, lo que permite una generación dinámica y flexible de flujos de trabajo.
- Extensible: Airflow puede integrar con una variedad de entornos, crear operadores personalizados y ejecutar código específico según sea necesario.
- Elegante: Los pipelines se escriben de manera limpia y explícita.
- Escalable: Su arquitectura modular emplea una cola de mensajes para orquestar un número arbitrario de trabajadores.
En la práctica, el flujo de aire puede emplear en escenarios como:
- Importación de datos: Orquestar la ingestión diaria de datos en una base de datos como Elasticsearch.
- Monitorización de registros: Gestionar la recopilación y procesamiento de archivos de registro, que luego se analizan en Elasticsearch para identificar errores o anomalías.
- Integración de múltiples fuentes de datos: Combina información de diferentes sistemas (APIs, bases de datos, archivos) en una sola capa en Elasticsearch, simplificando la búsqueda y la elaboración de reportes.
Comprendiendo los DAG (Grafos Acíclicos Dirigidos) en el flujo de aire
En Airflow, los flujos de trabajo se representan mediante DAGs (Grafos Acíclicos Dirigidos). Un DAG es una estructura que define la secuencia en la que se ejecutarán las tareas. Las principales características de los DAG son:
- Composición por tareas independientes: Cada tarea representa una unidad de trabajo y está diseñada para ejecutar de forma independiente.
- Secuenciación: La secuencia en la que se ejecutan las tareas está definida explícitamente en el DAG.
- Reusabilidad: Los DAG están diseñados para ejecutar repetidamente, facilitando la automatización de procesos.
Componentes de flujo de aire
El ecosistema Airflow está compuesto por varios componentes que trabajan juntos para orquestar tareas:
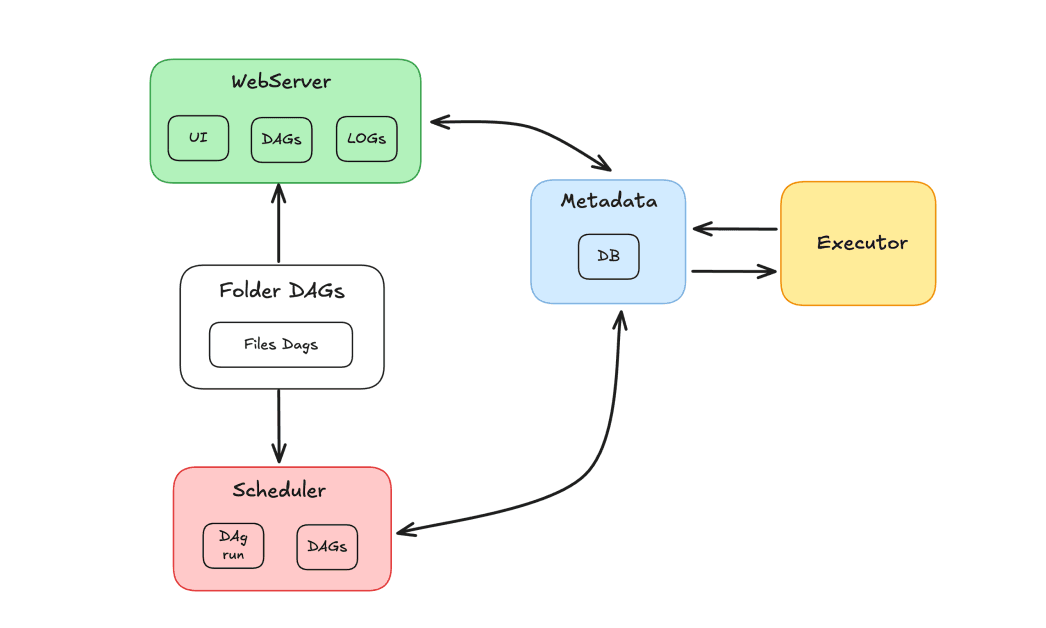
- Programador: Responsable de programar los DAGs y enviar tareas para su ejecución por parte de los trabajadores.
- Ejecutor: Gestiona la ejecución de las tareas, delegándolas a los trabajadores.
- Servidor sitio web: Proporciona una interfaz gráfica para interactuar con DAGs y tareas.
- Carpeta Dags: Carpeta donde almacenamos los DAGs escritos en Python.
- Metadatos: Base de datos que sirve como repositorio para la herramienta, empleada por el planificador y el ejecutor para almacenar el estado de ejecución.
Apache Airflow y Elasticsearch
Demostraremos el uso de Apache Airflow y Elasticsearch para orquestar tareas e indexar resultados en Elasticsearch. El objetivo de esta demostración es crear una cadena de tareas para actualizar registros en un índice de Elasticsearch. Este índice contiene una base de datos de películas, donde los usuarios pueden valorar y asignar valoraciones. Imaginando un escenario con cientos de audiencias diarias, es necesario mantener actualizado el registro de audiencias. Para ello, se desarrollará un DAG que se ejecutará diariamente, responsable de recuperar las nuevas calificaciones consolidadas y actualizar los registros en el índice.
En el flujo del DAG, tendremos una tarea para obtener las valoraciones, seguida de otra tarea para validar los resultados. Si los datos no existen, el DAG será dirigido a una tarea de fallo. De lo contrario, los datos se indexarán en Elasticsearch. El objetivo es actualizar el campo de calificación de las películas en un índice recuperando las calificaciones mediante un método con el mecanismo responsable de calcular los puntajes.
Usando Apache Airflow y Elasticsearch con Docker
Para crear un entorno contenedorizado, usaremos Apache Airflow con Docker. Sigue las instrucciones de la guía "Running Airflow en Docker" para configurar Airflow de forma práctica.
En cuanto a Elasticsearch, usaré un clúster en Elastic Cloud, pero si prefieres, también puedes configurar Elasticsearch con Docker. Ya se creó un índice que contiene un catálogo de películas, con los datos de las películas indexados. El campo de 'calificación' de estas películas se actualizará.
Creación del DAG
Tras instalarla mediante Docker, se creará una estructura de carpetas, incluyendo la carpeta dags, donde debemos colocar nuestros archivos DAG para que Airflow los reconozca.
Antes de eso, debemos cerciorarnos de que las dependencias necesarias estén instaladas. Estas son las dependencias de este proyecto:
Crearemos el archivo update_ratings_movies.py y empezaremos a programar las tareas.
Ahora, importemos las bibliotecas necesarias:
Emplearemos el ElasticsearchPythonHook, un componente que simplifica la integración entre Airflow y un clúster de Elasticsearch al abstraer la conexión y el uso de APIs externas.
A continuación, definimos el DAG, especificando sus argumentos principales:
dag_id: el nombre del DAG.start_date: cuando empezará el DAG.schedule: define la periodicidad (diaria en nuestro caso).doc_md: documentación que se importará y mostrará en la interfaz Airflow.
Definición de las tareas
Ahora, definamos las tareas del DAG. La primera tarea será la de recuperar los datos de valoración de la película. Usaremos el PythonOperator con la task_id configurada en 'get_movie_ratings'. El parámetro python_callable llamará a la función responsable de obtener las valoraciones.
A continuación, necesitamos validar si los resultados son válidos. Para esto, usaremos un condicional con un operador BranchPython. La task_id será 'validate_result', y la python_callable llamará a la función de validación. El parámetro op_args se empleará para pasar el resultado de la tarea anterior, 'get_movie_ratings', a la función de validación.
Si la validación tiene éxito, tomaremos los datos de la tarea 'get_movie_ratings' e los indexaremos en Elasticsearch. Para lograrlo, crearemos una nueva tarea, 'index_movie_ratings', que empleará el PythonOperator. El parámetro op_args pasará los resultados de la tarea 'get_movie_ratings' a la función de indexación.
Si la validación indica un fallo, el DAG procederá a una tarea de notificación de fallo. En este ejemplo, simplemente imprimimos un mensaje, pero en un escenario real podríamos configurar alertas para notificar sobre los fallos.
Finalmente, definimos las dependencias de las tareas, cerciorándonos de que se ejecuten en el orden correcto:
Ahora sigue el código completo de nuestro DAG:
Visualización de la ejecución del DAG
En la interfaz Apache Airflow, podemos visualizar la ejecución de los DAGs. Simplemente ve a la pestaña "DAGs" y localiza el DAG que creaste.
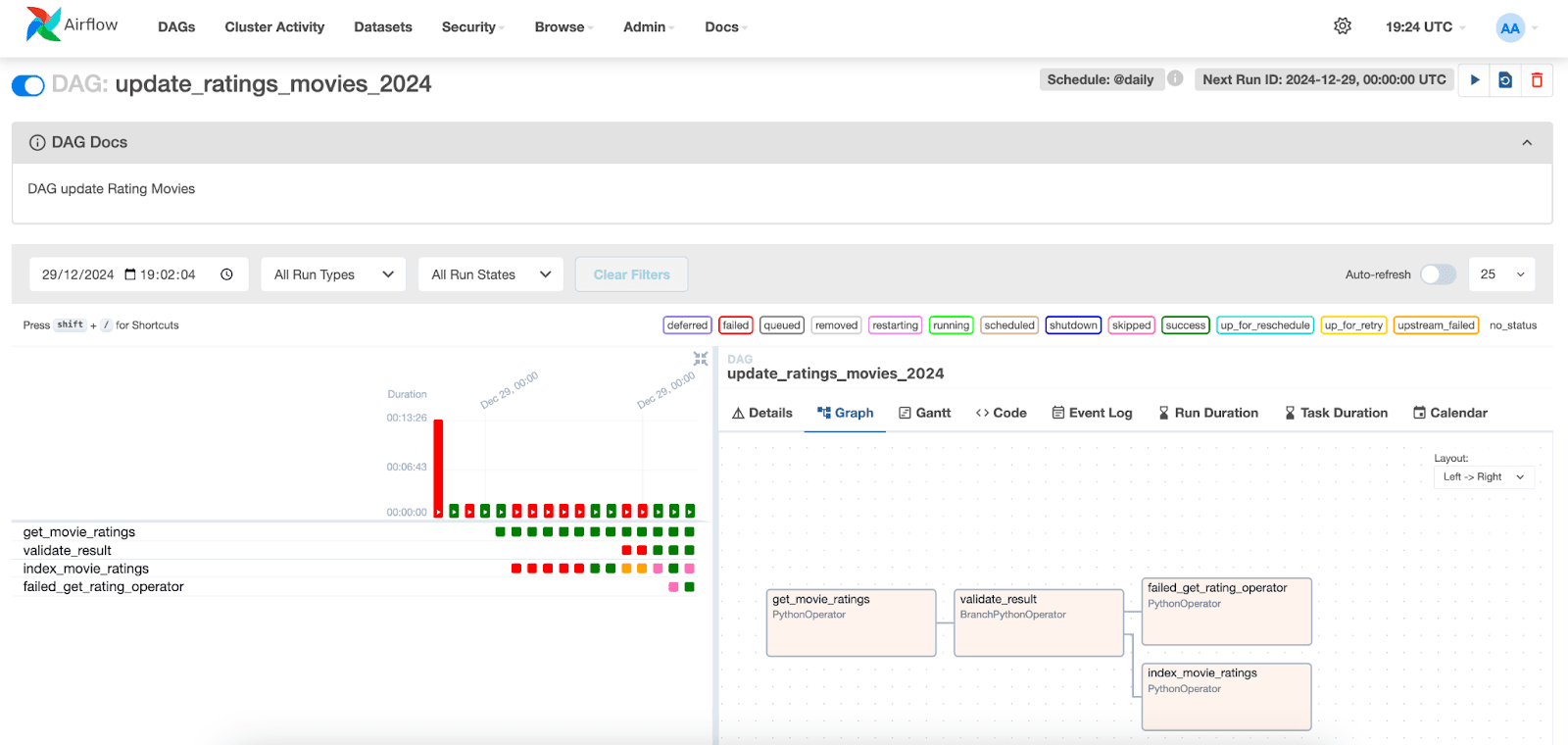
A continuación, podemos visualizar las ejecuciones de las tareas y sus respectivos estados. Al seleccionar una ejecución para una fecha específica, podemos acceder a los registros de cada tarea. Ten en cuenta que en la tarea index_movie_ratings podemos ver los resultados de indexación en el índice y que se completó con éxito.

En las otras pestañas, es posible acceder a información adicional sobre las tareas y el DAG, ayudando en el análisis y resolución de posibles problemas.
Conclusión
En este artículo, demostramos cómo integrar Apache Airflow con Elasticsearch para crear una solución de ingestión de datos. Mostramos cómo configurar el DAG, definir las tareas responsables de recuperar, validar e indexar datos de video, así como monitorizar y visualizar la ejecución de estas tareas en la interfaz Airflow.
Este enfoque puede adaptar fácilmente a diferentes tipos de datos y flujos de trabajo, haciendo de Airflow una herramienta útil para orquestar pipelines de datos en diversos escenarios.
Referencias
Apache AirFlow
Instalar Apache Airflow con Docker
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
Elasticsearch Python Hook
Operador Python
https://airflow.apache.org/docs/apache-airflow/stable/howto/operator/python.html
Preguntas frecuentes
¿Qué es el Apache Airflow?
Apache Airflow es una plataforma diseñada para crear, programar y monitorizar flujos de trabajo.
¿Para qué se usa Apache Airflow?
Apache Airflow se emplea para orquestar procesos ETL, canalizaciones de datos y otros flujos de trabajo complejos, ofreciendo flexibilidad y escalabilidad.
¿Cuáles son los principales componentes de Apache Airflow?
Los componentes principales de Airflow son: Planificador, Ejecutor, Servidor Sitio web, Carpeta Dags y Metadatos.
¿Se puede integrar Apache Airflow con Elasticsearch?
Sí, Apache Airflow puede integrar con Elasticsearch, por ejemplo puedes usar Apache Airflow para orquestar tareas e indexar resultados en Elasticsearch.
¿Qué es un DAG en Apache Airflow?
En Airflow, los flujos de trabajo se representan mediante DAGs (Grafos Acíclicos Dirigidos). Un DAG es una estructura que define la secuencia en la que se ejecutarán las tareas.
Contenido relacionado

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

22 de septiembre de 2025
Rastreador Elástico de Sitio web Abierto como código
Aprende a usar GitHub Actions para gestionar configuraciones de Elastic Open Crawler, de modo que cada vez que enviemos cambios al repositorio, los cambios se apliquen automáticamente a la instancia desplegada del rastreador.

6 de agosto de 2025
Cómo mostrar los campos de un índice de Elasticsearch
Aprende a mostrar campos de un índice de Elasticsearch usando las APIs _mapping y _search, subcampos, _source sintéticos y campos de ejecución.

24 de junio de 2025
Guion Ruby en Logstash
Infórmate sobre el plugin de filtro Ruby Logstash para transformar datos avanzados en tu pipeline Logstash.

26 de mayo de 2025
Visualización de campos en un índice de Elasticsearch
Explorando técnicas para mostrar campos en un índice de Elasticsearch.