Die Erstellung von Bewertungslisten ist ein entscheidender Schritt zur Optimierung der Suchergebnisse, kann aber eine komplizierte und schwierige Aufgabe sein. Eine Beurteilungsliste ist eine zusammengestellte Sammlung von Suchanfragen, denen Relevanzbewertungen für die entsprechenden Ergebnisse zugeordnet sind; sie wird auch als Testsammlung bezeichnet. Die anhand dieser Liste berechneten Kennzahlen dienen als Vergleichsmaßstab für die Leistungsfähigkeit einer Suchmaschine. Um den Prozess der Erstellung von Beurteilungslisten zu vereinfachen, entwickelte das OpenSource Connections- Team Quepid. Die Beurteilung kann entweder explizit erfolgen oder auf implizitem Feedback von Nutzern basieren. Dieser Blog führt Sie durch die Einrichtung einer kollaborativen Umgebung in Quepid, um menschlichen Bewertern die Möglichkeit zu geben, explizite Beurteilungen vorzunehmen, was die Grundlage jeder Beurteilungsliste bildet.
Quepid unterstützt Suchteams im Prozess der Bewertung der Suchqualität:
- Abfragesätze erstellen
- Erstellen Sie Beurteilungslisten
- Suchqualitätsmetriken berechnen
- Vergleichen Sie verschiedene Suchalgorithmen/Ranking-Systeme anhand berechneter Suchqualitätsmetriken.
Nehmen wir für unseren Blog an, wir betreiben eine Videothek und haben das Ziel, die Qualität unserer Suchergebnisse zu verbessern.
Voraussetzungen
Dieser Blog verwendet die Daten und Zuordnungen aus dem es-tmdb-Repository. Die Daten stammen von The Movie Database. Um dem Beispiel zu folgen, erstellen Sie einen Index namens tmdb mit den entsprechenden Zuordnungen und indizieren Sie die Daten. Ob Sie hierfür eine lokale Instanz einrichten oder eine Elastic Cloud-Bereitstellung verwenden, spielt keine Rolle – beides funktioniert einwandfrei. Für diesen Blog gehen wir von einer Elastic Cloud-Bereitstellung aus. Informationen zur Indizierung der Daten finden Sie in der README-Datei des es-tmdb-Repositorys.
Führen Sie eine einfache Suchabfrage im Titelfeld nach rocky durch, um zu bestätigen, dass Daten zum Durchsuchen vorhanden sind:
Es sollten 8 Ergebnisse angezeigt werden.
Melden Sie sich bei Quepid an.
Quepid ist ein Tool, mit dem Benutzer die Qualität von Suchergebnissen messen und Offline-Experimente durchführen können, um diese zu verbessern.
Sie können Quepid auf zwei Arten nutzen: entweder die kostenlose, öffentlich verfügbare Version unter https://app.quepid.com, oder richten Sie Quepid auf einem Rechner ein, auf den Sie Zugriff haben. Dieser Beitrag geht davon aus, dass Sie die kostenlose gehostete Version verwenden. Wenn Sie eine Quepid-Instanz in Ihrer Umgebung einrichten möchten, folgen Sie der Installationsanleitung.
Egal für welche Variante Sie sich entscheiden, Sie müssen ein Konto erstellen, falls Sie noch keins besitzen.
So richten Sie ein Quepid-Ticket ein
Quepid ist nach dem Prinzip „Fälle“ organisiert. Ein Case speichert Suchanfragen zusammen mit Relevanzeinstellungen und Informationen zur Herstellung einer Verbindung zu Ihrer Suchmaschine.
- Für Erstnutzer: Wählen Sie „Ersten Relevanzfall erstellen“.
- Wiederkehrende Benutzer können im Hauptmenü „Relevanzfälle“ auswählen und auf „+ Fall erstellen“ klicken.
Geben Sie Ihrem Fall einen beschreibenden Namen, z. B. „Filmsuche-Baseline“, da wir mit der Messung und Verbesserung unserer Baseline-Suche beginnen möchten.
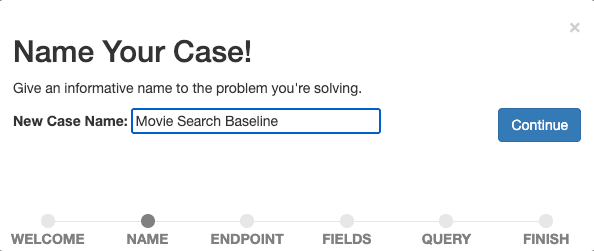
Bestätigen Sie den Namen, indem Sie „Weiter“ auswählen.
Als nächstes stellen wir eine Verbindung von Quepid zur Suchmaschine her. Quepid kann Verbindungen zu einer Vielzahl von Suchmaschinen herstellen, darunter Elasticsearch.
Die Konfiguration hängt von Ihrer Elasticsearch- und Quepid-Konfiguration ab. Um Quepid mit einer Elastic Cloud-Bereitstellung zu verbinden, müssen wir CORS für unsere Elastic Cloud-Bereitstellung aktivieren und konfigurieren und einen API-Schlüssel bereithalten. Eine detaillierte Anleitung finden Sie in der entsprechenden Anleitung in der Quepid-Dokumentation.
Geben Sie Ihre Elasticsearch-Endpunktinformationen (https://YOUR_ES_HOST:PORT/tmdb/_search) und alle weiteren Informationen ein, die für die Verbindung erforderlich sind (im Falle einer Elastic Cloud-Bereitstellung den API-Schlüssel in den erweiterten Konfigurationsoptionen), testen Sie die Verbindung, indem Sie auf „pingen“ klicken, und wählen Sie „Weiter“ , um zum nächsten Schritt zu gelangen.

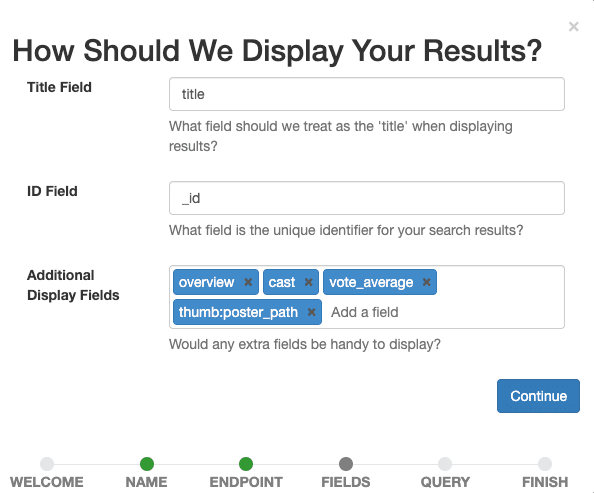
Nun legen wir fest, welche Felder im Fall angezeigt werden sollen. Wählen Sie alle Optionen aus, die unseren menschlichen Gutachtern später helfen, die Relevanz eines Dokuments für eine bestimmte Suchanfrage zu beurteilen.
Setzen Sie title als Titelfeld, lassen Sie _id als ID-Feld und fügen Sie overview, tagline, cast, vote_average, thumb:poster_path als zusätzliches Anzeigefeld hinzu. Im letzten Eintrag werden kleine Vorschaubilder der Filme in unseren Ergebnissen angezeigt, um uns und den menschlichen Gutachtern eine visuelle Orientierung zu geben.
Bestätigen Sie die Anzeigeeinstellungen durch Auswahl der Schaltfläche „Weiter“ .
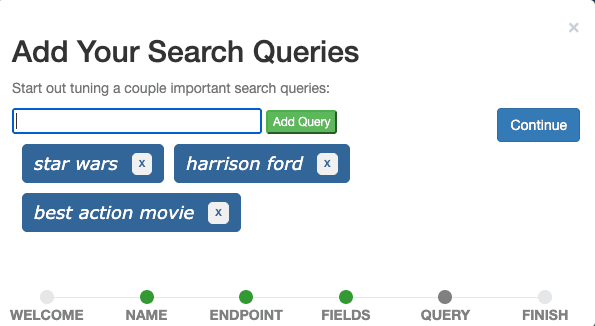
Der letzte Schritt besteht darin, Suchanfragen zum Fall hinzuzufügen. Fügen Sie die drei Suchbegriffe „Star Wars“, „Harrison Ford“ und „Bester Actionfilm“ nacheinander über das Eingabefeld hinzu und klicken Sie auf „Weiter“.
Idealerweise enthält ein Fallbeispiel Abfragen, die reale Benutzerabfragen repräsentieren und verschiedene Abfragetypen veranschaulichen. Fürs Erste können wir uns vorstellen, dass „Star Wars“ eine Suchanfrage ist, die alle Suchanfragen nach Filmtiteln repräsentiert, „Harrison Ford“ eine Suchanfrage, die alle Suchanfragen nach Darstellern repräsentiert, und „Bester Actionfilm“ eine Suchanfrage, die alle Suchanfragen repräsentiert, die nach Filmen eines bestimmten Genres suchen. Dies wird üblicherweise als Query-Set bezeichnet.
In einem Produktionsszenario würden wir Anfragen aus Ereignisverfolgungsdaten stichprobenartig entnehmen, indem wir statistische Verfahren wie die Wahrscheinlichkeits-proportional-zur-Größe-Stichprobe anwenden, und diese Stichprobenanfragen in Quepid importieren, um Anfragen vom Anfang (häufige Anfragen) und vom Ende (seltene Anfragen) relativ zu ihrer Häufigkeit einzubeziehen, was bedeutet, dass wir häufigere Anfragen bevorzugen, ohne seltene auszuschließen.
Wählen Sie abschließend „Fertigstellen“ aus. Sie werden dann zur Falloberfläche weitergeleitet, wo Sie die drei definierten Abfragen sehen.
Anfragen und Informationsbedarf
Um zu unserem übergeordneten Ziel einer Bewertungsliste zu gelangen, müssen menschliche Gutachter ein Suchergebnis (in der Regel ein Dokument) für eine bestimmte Suchanfrage bewerten. Dies wird als Abfrage-/Dokumentpaar bezeichnet.
Manchmal scheint es einfach zu sein, anhand der Suchanfrage zu erkennen, was ein Benutzer wollte. Die Anfrage harrison ford zielt darauf ab, Filme zu finden, in denen der Schauspieler Harrison Ford die Hauptrolle spielt. Und die Anfrage action? Ich weiß, ich wäre versucht zu sagen, dass der Nutzer Filme aus dem Action-Genre sucht. Aber welche? Die neuesten, die beliebtesten, die laut Nutzerbewertungen besten? Oder möchte der Nutzer vielleicht alle Filme finden, die als „Action“ bezeichnet werden? In der Movie Database gibt es mindestens 12 (!) Filme mit dem Titel „Action“ , die sich hauptsächlich durch die Anzahl der Ausrufezeichen im Titel unterscheiden.
Zwei menschliche Gutachter können bei der Interpretation einer Anfrage, deren Intention unklar ist, zu unterschiedlichen Ergebnissen kommen. Das Informationsbedürfnis: Ein Informationsbedürfnis ist ein bewusstes oder unbewusstes Verlangen nach Informationen. Die Definition eines Informationsbedarfs hilft menschlichen Gutachtern bei der Beurteilung von Dokumenten im Hinblick auf eine Anfrage und spielt daher eine wichtige Rolle beim Aufbau von Beurteilungslisten. Erfahrene Anwender oder Fachexperten eignen sich gut zur Spezifizierung des Informationsbedarfs. Es ist eine gute Praxis, Informationsbedürfnisse aus der Perspektive des Nutzers zu definieren, da die Suchergebnisse dessen Bedürfnisse erfüllen sollten.
Informationsbedarf für die Suchanfragen unseres „Filmsuche-Baseline“-Szenarios:
- Star Wars: Der Nutzer möchte Filme oder Serien aus dem Star Wars-Franchise finden. Möglicherweise relevant sind Dokumentarfilme über Star Wars.
- Harrison Ford: Der Nutzer möchte Filme finden, in denen der Schauspieler Harrison Ford mitspielt. Möglicherweise relevant sind Filme, in denen Harrison Ford eine andere Rolle spielt, zum Beispiel die des Erzählers.
- bester Actionfilm: Der Nutzer möchte Actionfilme finden, vorzugsweise solche mit einer hohen durchschnittlichen Nutzerbewertung.
So legen Sie den Informationsbedarf in Quepid fest
Um einen Informationsbedarf in Quepid zu definieren, greifen Sie auf die Fallschnittstelle zu:
1. Öffnen Sie eine Abfrage (z. B. Star Wars) und wählen Sie „Notizen umschalten“.
2. Tragen Sie im ersten Feld den Informationsbedarf und im zweiten Feld etwaige zusätzliche Anmerkungen ein:
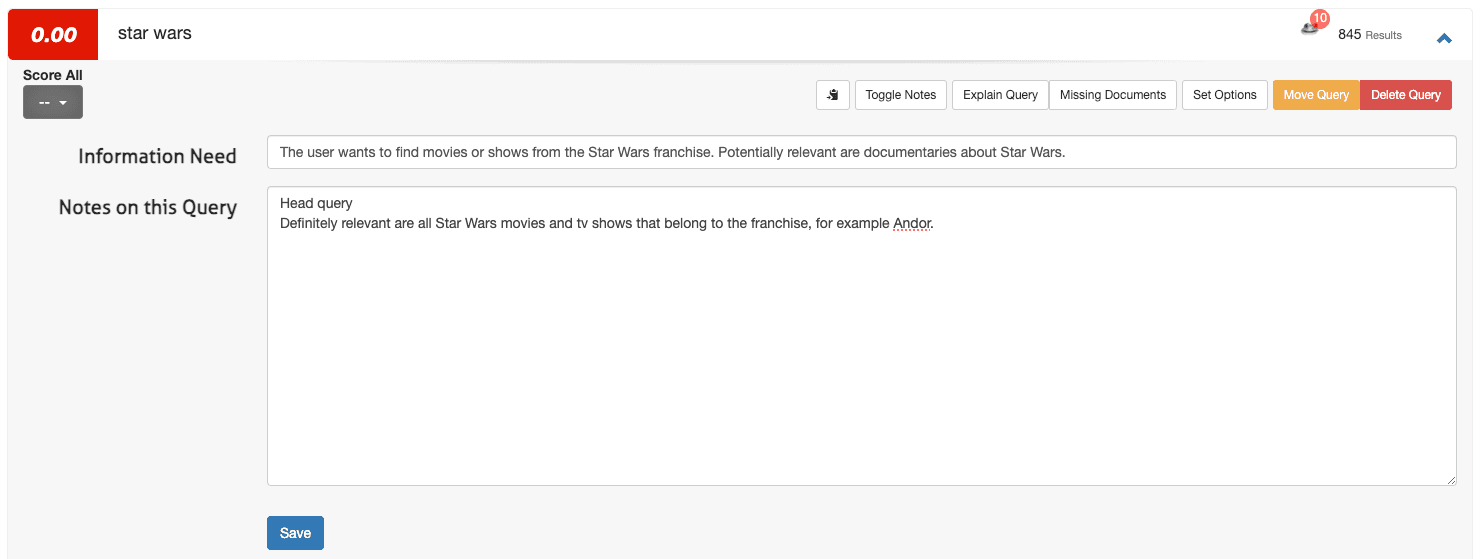
3. Klicken Sie auf Speichern.
Für eine Handvoll Anfragen ist dieses Vorgehen in Ordnung. Wenn Sie Ihren Fall jedoch von drei auf 100 Anfragen erweitern (Quepid-Fälle liegen oft im Bereich von 50 bis 100 Anfragen), sollten Sie die Informationsbedürfnisse außerhalb von Quepid definieren (z. B. in einer Tabellenkalkulation) und diese dann über Import hochladen und Informationsbedürfnisse auswählen.
Erstellen Sie ein Team in Quepid und teilen Sie Ihr Ticket mit anderen
Gemeinsame Beurteilungen verbessern die Qualität von Relevanzbewertungen. So stellen Sie ein Team zusammen:
1. Navigieren Sie im Hauptmenü zu Teams .

2. Klicken Sie auf + Neu hinzufügen, geben Sie einen Teamnamen ein (z. B. "Suchrelevanzbewerter") und klicken Sie auf Erstellen.
3. Fügen Sie Mitglieder hinzu, indem Sie deren E-Mail-Adressen eingeben und auf Benutzer hinzufügen klicken.
4. Wählen Sie in der Falloberfläche die Option „Fall teilen“.
5. Wählen Sie das passende Team aus und bestätigen Sie die Auswahl.
Erstellen Sie ein Bewertungsbuch in Quepid
Ein Buch in Quepid ermöglicht es mehreren Bewertern, Anfrage-/Dokumentpaare systematisch zu bewerten. Um einen zu erstellen:
1. Gehen Sie in der Falloberfläche zu „Urteile“ und klicken Sie auf „+ Buch erstellen“.
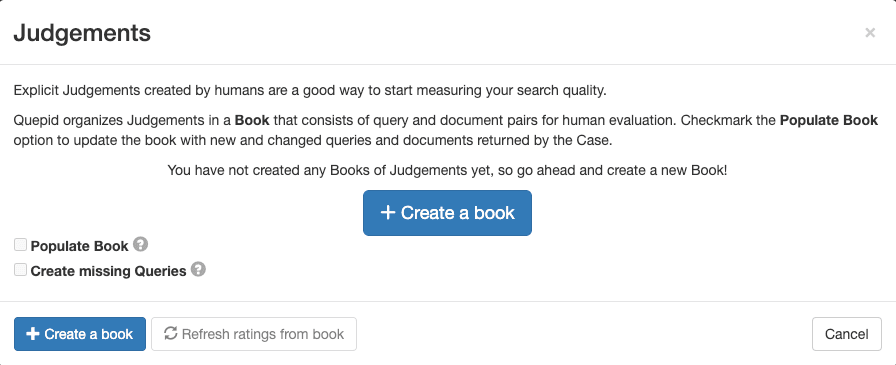
2. Konfigurieren Sie das Buch mit einem aussagekräftigen Namen, weisen Sie es Ihrem Team zu, wählen Sie eine Bewertungsmethode (z. B. DCG@10) und legen Sie die Auswahlstrategie fest (einzelner oder mehrere Bewerter). Verwenden Sie für das Buch die folgenden Einstellungen:
- Name: „Filmsuche Skala 0-3“
- Teams, mit denen Sie dieses Buch teilen möchten: Markieren Sie das Kästchen neben dem Team, das Sie erstellt haben.
- Torschütze: DCG@10
3. Klicken Sie auf „Buch erstellen“.
Der Name ist beschreibend und enthält Informationen darüber, wonach gesucht wird („Filme“) sowie über die Skala der Bewertungen („0-3“). Der ausgewählte Scorer DCG@10 definiert die Berechnungsmethode der Suchmetrik. „DCG“ ist die Abkürzung für Discounted Cumulative Gain (diskontierter kumulativer Gewinn) und „@10“ ist die Anzahl der Ergebnisse von oben, die bei der Berechnung der Kennzahl berücksichtigt werden.
In diesem Fall verwenden wir eine Metrik, die den Informationsgewinn misst und ihn mit der Positionsgewichtung kombiniert. Möglicherweise gibt es andere Suchmetriken, die für Ihren Anwendungsfall besser geeignet sind, und die Auswahl der richtigen Metrik ist schon eine Herausforderung für sich.
Füllen Sie das Buch mit Abfrage-/Dokumentpaaren.
Um Abfrage-/Dokumentpaare für die Relevanzbewertung hinzuzufügen, befolgen Sie diese Schritte:
1. Navigieren Sie in der Fallübersicht zu „Urteile“.

2. Wählen Sie Ihr erstelltes Buch aus.
3. Klicken Sie auf „Buch füllen“ und bestätigen Sie mit der Auswahl von „Abfrage-/Dokumentpaare für Buch aktualisieren“.
Diese Aktion generiert Paare basierend auf den Top-Suchergebnissen für jede Suchanfrage, die dann von Ihrem Team ausgewertet werden können.
Lassen Sie Ihr Team aus menschlichen Bewertern urteilen
Die bisher abgeschlossenen Schritte waren überwiegend technischer und administrativer Natur. Nachdem diese notwendigen Vorbereitungen nun abgeschlossen sind, können wir unser Richterteam seine Arbeit machen lassen. Im Wesentlichen besteht die Aufgabe des Richters darin, die Relevanz eines bestimmten Dokuments für eine gegebene Anfrage zu bewerten. Das Ergebnis dieses Prozesses ist die Bewertungsliste, die alle Relevanzbezeichnungen für die bewerteten Abfragedokumentpaare enthält. Im Folgenden werden dieser Prozess und die zugehörige Benutzeroberfläche genauer erläutert.
Übersicht über die Schnittstelle von Human Rating

Die Human Rating-Schnittstelle von Quepid ist für effiziente Bewertungen konzipiert:
- Suchanfrage: Zeigt den Suchbegriff an.
- Informationsbedarf: Zeigt die Absicht des Nutzers.
- Bewertungsrichtlinien: Enthält Anweisungen für eine einheitliche Bewertung.
- Dokumentmetadaten: Enthält relevante Details zum Dokument.
- Bewertungsbuttons: Ermöglicht es den Bewertenden, Beurteilungen mithilfe entsprechender Tastenkombinationen zuzuweisen.
Verwendung der Human Rating-Schnittstelle
Als menschlicher Bewerter greife ich über die Buchübersicht auf die Benutzeroberfläche zu:
1. Navigieren Sie zur Falloberfläche und klicken Sie auf Urteile.
2. Klicken Sie auf „Weitere Urteile sind erforderlich!“.
Das System präsentiert ein Anfrage-/Dokumentpaar, das noch nicht bewertet wurde und weitere Beurteilungen erfordert. Dies wird durch die Auswahlstrategie des Buches bestimmt:
- Einzelbewerter: Eine einzige Bewertung pro Anfrage/Dokumentenpaar.
- Mehrere Gutachter: Bis zu drei Beurteilungen pro Anfrage/Dokumentenpaar.
Bewertungsanfrage/Dokumentpaare
Schauen wir uns ein paar Beispiele an. Wenn Sie dieser Anleitung folgen, werden Ihnen höchstwahrscheinlich verschiedene Filme angezeigt. Die Bewertungsgrundsätze bleiben jedoch unverändert.
Unser erstes Beispiel ist der Film „Heroes“ für die Suchanfrage Harrison Ford:
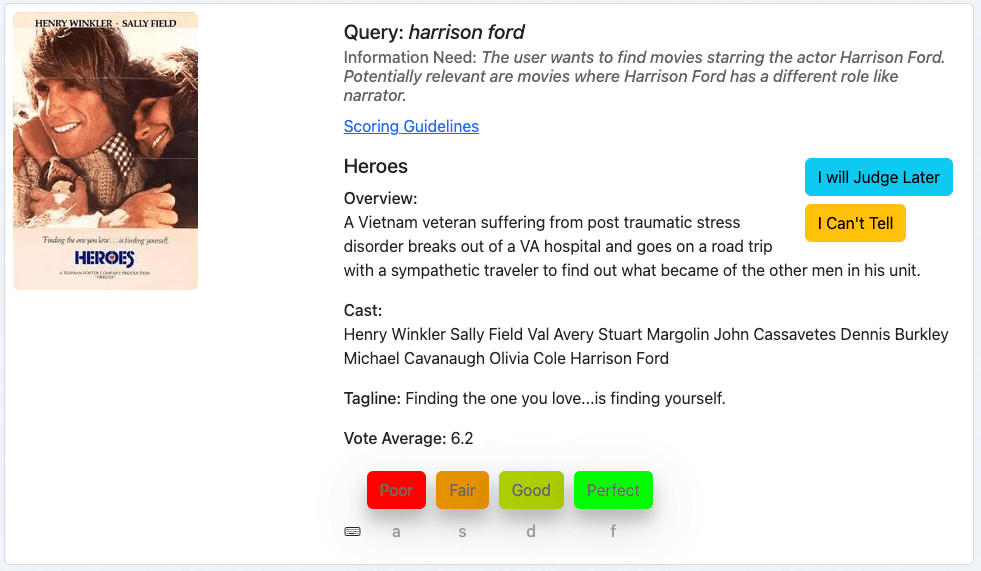
Wir betrachten zunächst die Suchanfrage, dann den Informationsbedarf und beurteilen anschließend den Film anhand der angegebenen Metadaten.
Dieser Film ist ein relevantes Ergebnis für unsere Suchanfrage, da Harrison Ford zur Besetzung gehört. Wir mögen neuere Filme subjektiv als relevanter einstufen, aber dies entspricht nicht unserem Informationsbedürfnis. Daher bewerten wir dieses Dokument mit „Perfekt“, was einer 3 auf unserer Bewertungsskala entspricht.
Unser nächstes Beispiel ist der Film „Ford v Ferrari“ für die Suchanfrage Harrison Ford:

In Anlehnung an diese Vorgehensweise beurteilen wir diese Anfrage/dieses Dokument, indem wir die Anfrage, den Informationsbedarf und anschließend prüfen, wie gut die Metadaten des Dokuments dem Informationsbedarf entsprechen.
Das ist ein schlechtes Ergebnis. Dieses Ergebnis sehen wir wahrscheinlich deshalb, weil einer unserer Suchbegriffe, „ford“, im Titel vorkommt. Harrison Ford spielt jedoch weder in diesem Film noch in irgendeiner anderen Rolle eine Rolle. Daher bewerten wir dieses Dokument mit „Mangelhaft“, was einer 0 auf unserer Bewertungsskala entspricht.
Unser drittes Beispiel ist der Film „Action Jackson“ für die Suchanfrage „bester Actionfilm“:
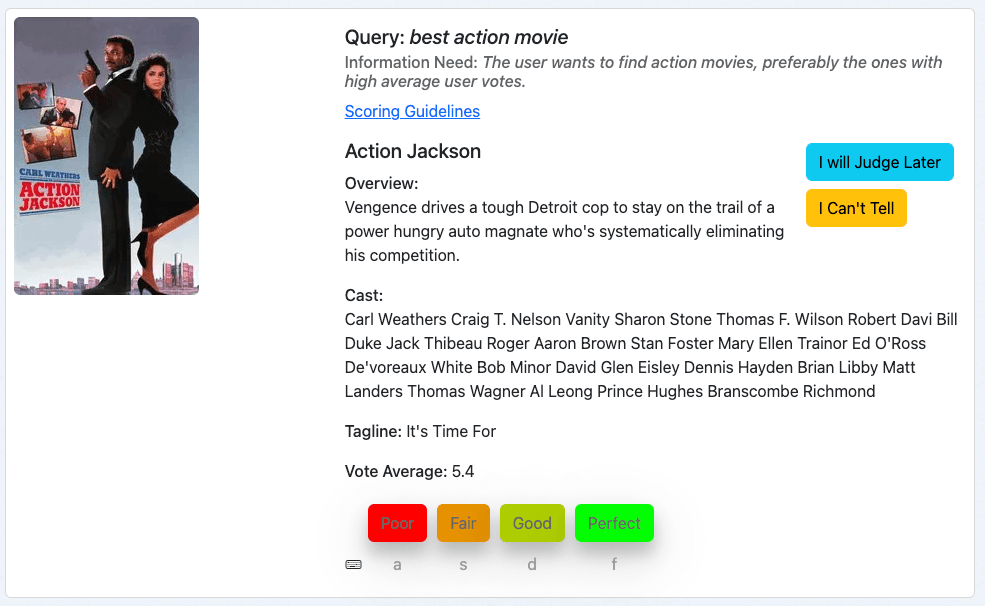
Das sieht nach einem Actionfilm aus, das Informationsbedürfnis ist also zumindest teilweise befriedigt. Der durchschnittliche Stimmenanteil liegt jedoch bei 5,4 von 10 Punkten. Und das macht diesen Film wahrscheinlich nicht zum besten Actionfilm unserer Sammlung. Dies würde mich als Richter dazu veranlassen, dieses Dokument mit „Mittelmäßig“ zu bewerten, was einer 1 auf unserer Bewertungsskala entspricht.
Diese Beispiele veranschaulichen den Prozess der Bewertung von Anfrage-/Dokumentpaaren mit Quepid im Besonderen, auf einer hohen Ebene und auch im Allgemeinen.
Best Practices für menschliche Bewerter
Die gezeigten Beispiele könnten den Eindruck erwecken, es sei unkompliziert, zu eindeutigen Urteilen zu gelangen. Doch die Einrichtung eines zuverlässigen menschlichen Bewertungsprogramms ist keine leichte Aufgabe. Es handelt sich um einen Prozess voller Herausforderungen, die die Qualität Ihrer Daten leicht beeinträchtigen können:
- Menschliche Bewerter können durch sich wiederholende Aufgaben ermüden.
- Persönliche Vorlieben können Urteile verzerren.
- Der Grad an Fachwissen variiert von Richter zu Richter.
- Bewerter jonglieren oft mit mehreren Aufgaben gleichzeitig.
- Die wahrgenommene Relevanz eines Dokuments entspricht möglicherweise nicht seiner tatsächlichen Relevanz für eine Suchanfrage.
Diese Faktoren können zu uneinheitlichen und qualitativ minderwertigen Beurteilungen führen. Aber keine Sorge – es gibt bewährte Best Practices, die Ihnen helfen können, diese Probleme zu minimieren und einen robusteren und zuverlässigeren Evaluierungsprozess aufzubauen:
- Konsequente Bewertung: Überprüfen Sie die Anfrage, den Informationsbedarf und die Dokumentenmetadaten der Reihe nach.
- Beachten Sie die Richtlinien: Verwenden Sie die Bewertungsrichtlinien, um eine einheitliche Bewertung zu gewährleisten. Die Bewertungsrichtlinien können Beispiele enthalten, wann welche Note zu vergeben ist, wodurch der Beurteilungsprozess veranschaulicht wird. Die Rücksprache mit menschlichen Gutachtern nach der ersten Bewertungsrunde erwies sich als gute Vorgehensweise, um schwierige Grenzfälle zu erkennen und herauszufinden, wo zusätzliche Unterstützung benötigt wird.
- Nutzen Sie die Antwortmöglichkeiten: Wenn Sie unsicher sind, verwenden Sie „Ich werde später urteilen“ oder „Ich kann es nicht sagen“ und geben Sie gegebenenfalls Erklärungen an.
- Machen Sie Pausen: Regelmäßige Pausen tragen dazu bei, die Urteilsfähigkeit aufrechtzuerhalten. Quepid sorgt für regelmäßige Pausen, indem es Konfetti knallen lässt, sobald ein menschlicher Bewerter eine Reihe von Beurteilungen abgeschlossen hat.
Durch Befolgen dieser Schritte etablieren Sie einen strukturierten und kollaborativen Ansatz zur Erstellung von Beurteilungslisten in Quepid und steigern so die Effektivität Ihrer Bemühungen zur Optimierung der Suchrelevanz.
Wie geht es weiter?
Wie geht es nun weiter? Bewertungslisten sind nur ein grundlegender Schritt zur Verbesserung der Qualität der Suchergebnisse. Hier die nächsten Schritte:
Berechnen Sie Metriken und beginnen Sie mit dem Experimentieren
Sobald die Bewertungslisten verfügbar sind, ist die Nutzung der Bewertungen und die Berechnung von Kennzahlen zur Suchqualität ein logischer nächster Schritt. Quepid berechnet die konfigurierte Metrik für den aktuellen Fall automatisch, sobald Urteile vorliegen. Metriken werden als „Scorer“ implementiert, und Sie können Ihre eigenen angeben, wenn die unterstützten Metriken Ihre bevorzugten nicht enthalten!
Gehen Sie zur Falloberfläche, navigieren Sie zu „Scorer auswählen“, wählen Sie DCG@10 und bestätigen Sie mit einem Klick auf „Scorer auswählen“. Quepid berechnet nun DCG@10 pro Abfrage und mittelt außerdem die Gesamtzahl der Abfragen, um die Qualität der Suchergebnisse für Ihren Fall zu quantifizieren.
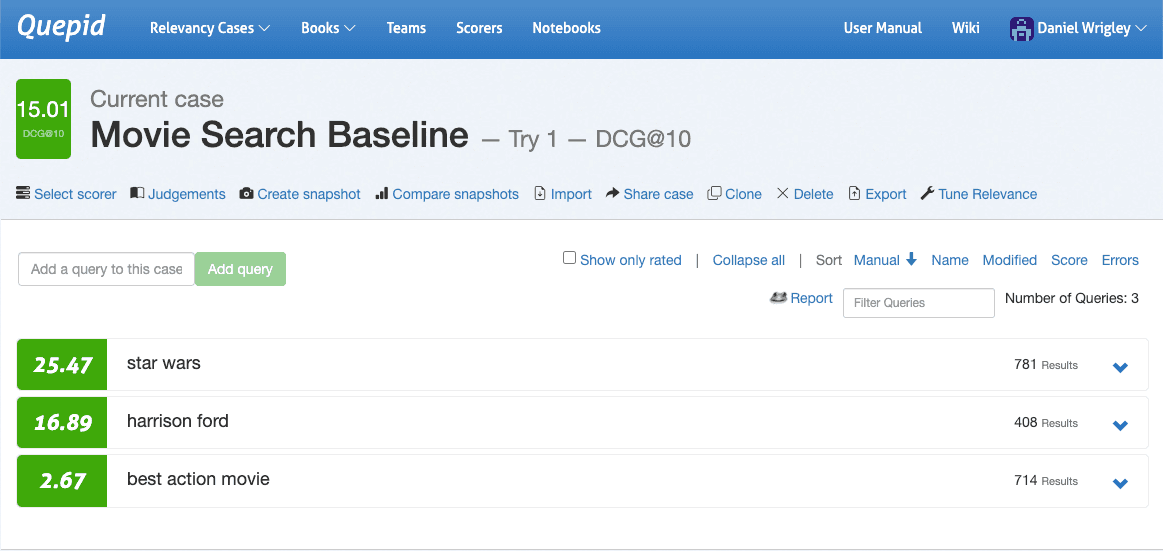
Nachdem die Qualität Ihrer Suchergebnisse nun quantifiziert wurde, können Sie erste Experimente durchführen. Experimente beginnen mit der Aufstellung von Hypothesen. Ein Blick auf die drei Suchanfragen im Screenshot nach der Bewertung macht deutlich, dass die drei Suchanfragen hinsichtlich ihrer Suchqualitätsmetrik sehr unterschiedlich abschneiden: Star Wars schneidet ziemlich gut ab, Harrison Ford sieht in Ordnung aus, aber das größte Potenzial liegt bei Best Action Movie.
Durch die Erweiterung dieser Abfrage sehen wir ihre Ergebnisse und können in die Details eintauchen und untersuchen, warum Dokumente übereinstimmten und was ihre Punktzahl beeinflusst:

Durch Klicken auf „Abfrage erläutern“ und Aufrufen der Registerkarte „Parsing“ sehen wir, dass es sich bei der Abfrage um eine DisjunctionMaxxQuery handelt, die drei Felder durchsucht: cast, overview und title:

Als Suchmaschinenentwickler kennen wir in der Regel einige domänenspezifische Details unserer Suchplattform. In diesem Fall wissen wir möglicherweise, dass wir ein Genre- Feld haben. Fügen wir das der Suchanfrage hinzu und schauen wir, ob sich die Suchqualität verbessert.
Wir verwenden die Abfrage-Sandbox , die sich öffnet, wenn man in der Fallschnittstelle „Relevanz optimieren“ auswählt. Probieren Sie es aus, indem Sie das Suchfeld „Genres“ hinzufügen:
Klicken Sie auf „Meine Suchanfragen erneut ausführen“! Und sehen Sie sich die Ergebnisse an. Haben sie sich verändert? Leider nein. Wir haben nun viele Möglichkeiten zur Erkundung, im Grunde alle Abfrageoptionen, die Elasticsearch bietet:
- Wir könnten die Gewichtung des Feldes „Genres“ erhöhen.
- Wir könnten eine Funktion hinzufügen, die Dokumente anhand ihres durchschnittlichen Abstimmungsergebnisses höher priorisiert.
- Wir könnten eine komplexere Abfrage erstellen, die Dokumente nur dann nach ihrem Stimmendurchschnitt priorisiert, wenn eine starke Übereinstimmung der Genres vorliegt.
- …
Das Beste daran, all diese Optionen zu haben und sie in Quepid zu erkunden, ist, dass wir die Möglichkeit haben, die Auswirkungen nicht nur auf die eine Abfrage zu quantifizieren, die wir verbessern wollen, sondern auf alle Abfragen in unserem Fall. Das hindert uns daran, eine leistungsschwache Suchanfrage zu verbessern, indem wir die Qualität der Suchergebnisse für andere opfern. Wir können schnell und kostengünstig iterieren und den Wert unserer Hypothese ohne Risiko validieren, wodurch Offline-Experimente zu einer grundlegenden Fähigkeit aller Suchteams werden.
Messung der Interrater-Zuverlässigkeit
Selbst bei Aufgabenbeschreibungen, Informationsbedarfsdefinitionen und einer Benutzeroberfläche für menschliche Bewerter, wie sie Quepid bietet, können menschliche Bewerter unterschiedlicher Meinung sein.
Meinungsverschiedenheiten an sich sind nichts Schlechtes, ganz im Gegenteil: Die Messung von Meinungsverschiedenheiten kann Probleme aufdecken, die man angehen möchte. Relevanz kann subjektiv sein, Anfragen können mehrdeutig sein und Daten können unvollständig oder fehlerhaft sein. Fleiss' Kappa ist ein statistisches Maß für die Übereinstimmung zwischen Beurteilern. In Quepid gibt es ein Beispiel-Notebook, das Sie verwenden können. Um es zu finden, wählen Sie in der Hauptnavigation „Notebooks“ aus und wählen Sie das Notebook Fleiss Kappa.ipynb im Ordner „examples“ aus.

Fazit
Mit Quepid können Sie selbst die komplexesten Herausforderungen im Bereich der Suchrelevanz bewältigen und es wird ständig weiterentwickelt: Ab Version 8 unterstützt Quepid KI-generierte Beurteilungen, was besonders für Teams nützlich ist, die ihren Beurteilungsgenerierungsprozess skalieren möchten.
Mit Quepid-Workflows können Sie effizient skalierbare Beurteilungslisten erstellen – was letztendlich zu Suchergebnissen führt, die den Bedürfnissen der Nutzer wirklich gerecht werden. Mit den erstellten Bewertungslisten verfügen Sie über eine solide Grundlage, um die Relevanz der Suchergebnisse zu messen, Verbesserungen iterativ umzusetzen und ein besseres Nutzererlebnis zu schaffen.
Denken Sie bei Ihrem weiteren Vorgehen daran, dass die Relevanzoptimierung ein fortlaufender Prozess ist. Beurteilungslisten ermöglichen es Ihnen, Ihren Fortschritt systematisch zu bewerten, ihre größte Wirkung entfalten sie jedoch in Kombination mit Experimenten, Metrikanalysen und iterativen Verbesserungen.
Weitere Lektüre
- Quepid-Dokumentation:
- Quepid GitHub-Repository
- Lernen Sie Pete kennen, eine Blogserie zur Verbesserung der E-Commerce-Suche
- Relevanz Slack: Treten Sie dem Kanal #quepid bei
Arbeiten Sie mit Open Source Connections zusammen, um Ihre Such- und KI-Fähigkeiten zu transformieren und Ihr Team zu befähigen, diese kontinuierlich weiterzuentwickeln. Unsere Erfolgsbilanz erstreckt sich über den gesamten Globus, wobei unsere Kunden durchweg dramatische Verbesserungen in der Suchqualität, der Teamleistung und der Geschäftsperformance erzielen. Kontaktieren Sie uns noch heute, um mehr zu erfahren.
Häufige Fragen
Was ist Quepid?
Quepid ist ein Tool, mit dem Nutzer die Qualität von Suchergebnissen messen und Offline-Experimente durchführen können, um diese zu verbessern.
Welche Arten von Experimenten zur Qualität von Suchergebnissen können Sie in Quepid erstellen?
In Quepid können Sie viele Experimente durchführen, darunter das Erstellen von Abfragesätzen, das Erstellen von Bewertungslisten, das Berechnen von Suchqualitätsmetriken und das Vergleichen verschiedener Suchalgorithmen/Rankings auf der Grundlage der berechneten Suchqualitätsmetriken, um die Suchrelevanz zu verbessern.
Wie wird Quepid und Elasticsearch verwendet?
Mit der Query Sandbox können Sie schnell und kostengünstig iterieren. Sie können Feldgewichtungen hinzufügen, Bewertungen erhöhen oder die Abfragelogik ändern und sofort sehen, wie sich dies auf Ihre Suchqualitätsmetriken (wie nDCG oder DCG@10) für Ihre Daten in Elasticsearch auswirkt.
Zugehörige Inhalte

20. Februar 2026
Sicherstellung semantischer Präzision mit Mindestscore
Verbessern Sie die semantische Präzision durch die Verwendung von Schwellenwerten für die Mindestscore. Der Artikel enthält konkrete Beispiele für die semantische und hybride Suche.

11. Dezember 2025
Bewertung der Relevanz von Suchanfragen mit Bewertungslisten
Erfahren Sie, wie Sie Bewertungslisten erstellen, um die Relevanz von Suchanfragen objektiv zu bewerten und Leistungsmetriken wie den Recall zu verbessern – für skalierbare Suchtests in Elasticsearch.

27. November 2025
Hybride Suche ohne Probleme: Vereinfachte hybride Suche mit Retrievern
Erfahren Sie, wie Sie die hybride Suche in Elasticsearch mit einem mehrfeldrigen Abfrageformat für lineare und RRF-Retriever vereinfachen und Abfragen erstellen können, ohne vorher Kenntnisse über Ihren Elasticsearch-Index haben zu müssen.

12. November 2025
Sie wissen schon, Kontext – Teil I: Die Entwicklung von hybrider Suche und Kontextgestaltung
Erfahren Sie, wie sich hybride Suche und Kontextgestaltung von lexikalischen Grundlagen weiterentwickelt haben, um die nächste Generation agentenbasierter KI-Workflows zu ermöglichen.

28. Mai 2025
Hybride Suche neu betrachtet: Einführung des linearen Retrievers in Elasticsearch!
Entdecken Sie, wie der lineare Retriever die hybride Suche durch die Nutzung gewichteter Scores und MinMax-Normalisierung für präzisere und konsistentere Rangfolgen verbessert, und lernen Sie, wie Sie ihn verwenden.