In Elasticsearch ist das Verbinden zweier Indizes nicht so einfach wie in herkömmlichen relationalen SQL-Datenbanken. Mit bestimmten Techniken und Funktionen von Elasticsearch können jedoch ähnliche Ergebnisse erzielt werden.
In der Vergangenheit haben viele Leute den Feldtyp nestedals Mechanismus verwendet, um verschiedene Indizes miteinander zu verbinden. Allerdings war dies aufgrund teurer Abfragen und unvollständiger Unterstützung in Kibana, insbesondere bei Lens-Visualisierungen, eingeschränkt.
Dieser Artikel befasst sich eingehend mit dem Zusammenführen zweier Indizes in Elasticsearch und konzentriert sich dabei auf die folgenden Ansätze:
- Verwenden der
terms-Abfrage - Verwenden des
enrich-Prozessors in Aufnahmepipelines - Logstash
elasticsearchFilter-Plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Verwenden der Begriffsabfrage
Die Termabfrage ist eine der effektivsten Möglichkeiten, zwei Indizes in Elasticsearch zu verbinden. Mit dieser Abfrage können Sie Dokumente abrufen, die einen oder mehrere genaue Begriffe in einem bestimmten Feld enthalten. Hier besprechen wir, wie man es zum Verbinden zweier Indizes verwendet.
Zuerst müssen Sie die erforderlichen Daten aus dem ersten Index abrufen. Dies kann mithilfe einer einfachen GET-Anfrage und dem Abrufen der Werte aus dem Attribut _source erfolgen.
Sobald Sie die Daten aus dem ersten Index haben, können Sie diese zum Abfragen des zweiten Index verwenden. Dies geschieht mithilfe der terms -Abfrage, bei der Sie das Feld und die Werte angeben, die Sie abgleichen möchten.
Hier ist ein Beispiel:
In diesem Beispiel ist field_in_second_index das Feld im zweiten Index, das Sie mit den Werten aus dem ersten Index abgleichen möchten. value1_from_first_index und value2_from_first_index sind die Werte aus dem ersten Index, die im zweiten Index abgeglichen werden sollen.
Die Begriffsabfrage bietet außerdem Unterstützung bei der Ausführung der beiden oben genannten Schritte in einem Durchgang mithilfe einer Technik namens „Begriffssuche“. Elasticsearch kümmert sich um das transparente Abrufen der abzugleichenden Werte aus einem anderen Index. Wenn Sie beispielsweise einen Teamindex mit einer Spielerliste haben:
Es ist möglich, einen Personenindex für alle Personen abzufragen, die in Team1 spielen, wie unten gezeigt:
Im obigen Beispiel ruft Elasticsearch die Spielernamen transparent aus dem Dokument mit der ID team1 im Teamindex ab (d. h. „John“, „Bill“ und „Michael“) und suchen Sie alle Dokumente im Personenindex, die einen dieser Werte in ihrem Namensfeld enthalten.
Für alle, die es interessiert: Die entsprechende SQL-Abfrage wäre:
Verwenden des Anreicherungsprozessors
Der enrich -Prozessor ist ein weiteres leistungsstarkes Tool, mit dem zwei Indizes in Elasticsearch verbunden werden können. Dieser Prozessor bereichert die Daten eingehender Dokumente, indem er Daten aus einem vordefinierten Anreicherungsindex hinzufügt.
So können Sie den Anreicherungsprozessor verwenden, um zwei Indizes zu verknüpfen:
1. Zuerst müssen Sie eine Anreicherungsrichtlinie erstellen. Diese Richtlinie definiert, welcher Index für die Anreicherung verwendet werden soll, welches Feld abgeglichen werden soll und welche Felder für die Anreicherung eingehender Dokumente verwendet werden sollen.
Hier ist ein Beispiel:
2. Sobald die Richtlinie erstellt ist, müssen Sie sie ausführen, um den angereicherten Index aus Ihrer neu erstellten Richtlinie zu erstellen:
Dadurch wird ein neuer versteckter angereicherter Index erstellt, der während der Anreicherung verwendet wird. Abhängig von der Größe des Quellindex kann dieser Vorgang einige Zeit dauern. Stellen Sie sicher, dass die Anreicherungsrichtlinie vollständig erstellt ist, bevor Sie mit dem nächsten Schritt fortfahren.
3. Nachdem die Anreicherungsrichtlinie erstellt wurde, können Sie den Anreicherungsprozessor in einer Aufnahmepipeline verwenden, um die Daten eingehender Dokumente anzureichern:
In diesem Beispiel ist field_in_second_index das Feld im zweiten Index, das mit match_field aus dem ersten Index übereinstimmen muss. enriched_field ist das neue Feld im zweiten Index, das die angereicherten Daten aus enrich_fields im ersten Index enthalten wird.
Ein Nachteil dieses Ansatzes besteht darin, dass die Anreicherungsrichtlinie erneut ausgeführt werden muss, wenn sich die Daten in first_index ändern. Der angereicherte Index wird nicht automatisch mit dem Quellindex aktualisiert oder synchronisiert, aus dem er erstellt wurde. Wenn first_index jedoch relativ stabil ist, funktioniert dieser Ansatz gut.
Logstash Elasticsearch-Filter-Plugin
Wenn Sie Logstash verwenden, besteht eine weitere Option, die dem oben beschriebenen enrich -Prozessor ähnelt, darin, das elasticsearch -Filter-Plugin zu verwenden, um dem Ereignis basierend auf einer angegebenen Abfrage relevante Felder hinzuzufügen. Die Konfiguration für unsere Logstash-Pipeline würde sich in einer .conf -Datei befinden, beispielsweise my-pipeline.conf.
Stellen wir uns vor, unsere Pipeline zieht Protokolle aus Elasticsearch mithilfe des elasticsearch -Eingabe-Plugins und verwendet eine Abfrage, um die Auswahl einzugrenzen:
Wenn wir diese Nachrichten mit Informationen aus einem bestimmten Index anreichern möchten, können wir das Filter-Plugin elasticsearchim Abschnitt filter verwenden, um unsere Protokolle anzureichern:
Der obige Code findet die Dokumente ab Index index_name , wobei type der Start ist und das Operationsfeld mit dem angegebenen opid übereinstimmt, und kopiert dann den Wert des Felds @timestamp in ein neues Feld mit dem Namen started.
Die angereicherten Dokumente würden dann an die entsprechende Ausgabequelle gesendet, in diesem Fall an Elasticsearch unter Verwendung des elasticsearch -Ausgabe-Plugins:
Wenn Sie Logstash bereits verwenden, kann diese Option nützlich sein, um Ihre Anreicherungslogik an einem einzigen Ort zu konsolidieren und bei eingehenden neuen Ereignissen zu verarbeiten. Wenn dies jedoch nicht der Fall ist, wird Ihre Lösung komplexer und Sie müssen eine weitere Komponente ausführen und warten.
ES|QL ENRICH
Die Einführung von ES|QL, das in Version 8.14 allgemein verfügbar wurde, ist eine von Elasticsearch unterstützte Piped-Abfragesprache, die das Filtern, Transformieren und Analysieren von Daten ermöglicht. Mithilfe des Verarbeitungsbefehls ENRICH können wir mithilfe einer Anreicherungsrichtlinie Daten aus vorhandenen Indizes hinzufügen.
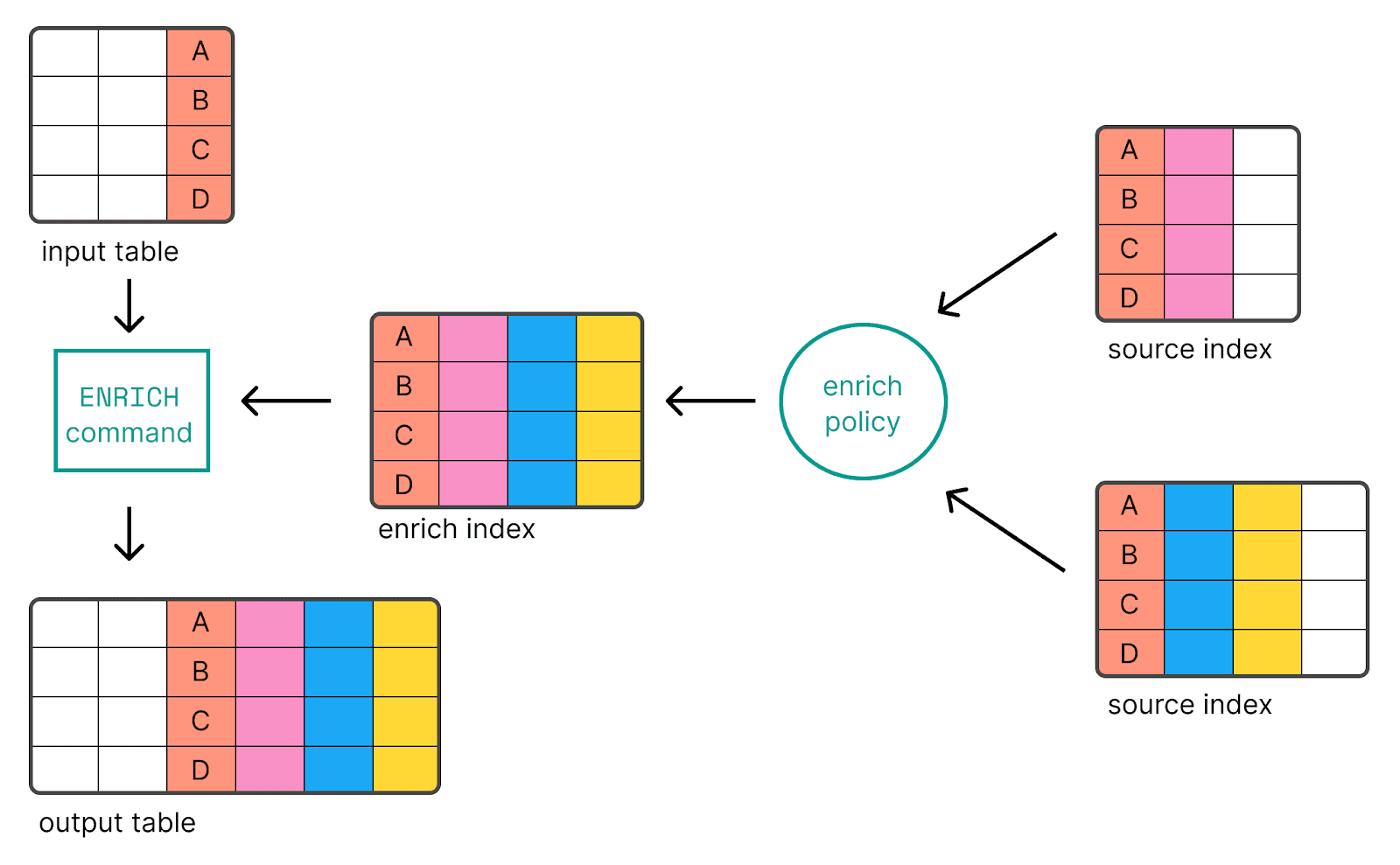
Wenn man dieselbe Richtlinie my_enrich_policy aus dem ursprünglichen Beispiel des Anreicherungsprozessors verwendet, würde das ES|QL-Beispiel folgendermaßen aussehen:
Es ist auch möglich, die Übereinstimmungs- und Anreicherungsfelder zu überschreiben, die in unserem Beispiel field_in_first_index bzw. field_to_enrich sind:
Die offensichtliche Einschränkung besteht darin, dass Sie zuerst eine Anreicherungsrichtlinie angeben müssen, ES|QL bietet jedoch die Flexibilität, die Felder nach Bedarf anzupassen.
ES|QL LOOKUP JOIN
Elasticsearch 8.18 führt eine neue Möglichkeit zum Verbinden von Indizes in Elasticsearch ein, nämlich den Befehl LOOKUP JOIN . Dieser Befehl funktioniert als LEFT OUTER JOIN im SQL-Stil und verwendet den neuen Lookup-Indexmodus auf der rechten Seite des Joins.

Wenn wir unser vorheriges Beispiel noch einmal betrachten, lautet die neue Abfrage wie folgt, wobei match_field sowohl in first_index als auch in second_index vorhanden sein muss:
Der Vorteil von LOOKUP JOIN gegenüber den anderen Ansätzen besteht darin, dass keine enrich -Richtlinie erforderlich ist und daher auch keine zusätzliche Verarbeitung im Zusammenhang mit der Einrichtung der Richtlinie erforderlich ist. Im Gegensatz zu den anderen in diesem Artikel besprochenen Ansätzen ist es nützlich, wenn mit sich häufig ändernden Anreicherungsdaten gearbeitet wird.
Fazit
Zusammenfassend lässt sich sagen, dass Elasticsearch zwar keine herkömmlichen Join-Operationen unterstützt, aber verschiedene Funktionen bietet, mit denen ähnliche Ergebnisse erzielt werden können. Insbesondere haben wir erläutert, wie Sie Join-Operationen mithilfe der folgenden Methoden durchführen können:
- Die
terms-Abfrage - Der
enrich-Prozessor in Ingest-Pipelines - Logstash
elasticsearchFilter-Plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Es ist wichtig zu beachten, dass diese Methoden ihre Grenzen haben und je nach den spezifischen Anforderungen und der Art der Daten mit Bedacht eingesetzt werden sollten.
Zugehörige Inhalte

14. November 2025
So stellen Sie Elasticsearch auf Azure AKS Automated bereit
Erfahren Sie, wie Sie Elasticsearch mit Kibana auf Azure mithilfe von AKS Automatic und ECK für eine teilweise verwaltete Elasticsearch-Setup-Konfiguration bereitstellen.

11. November 2025
Konfiguration der rekursiven Segmentierung für strukturierte Dokumente in Elasticsearch
Erfahren Sie, wie Sie rekursives Chunking in Elasticsearch mit Chunk-Größe, Trenngruppen und benutzerdefinierten Trennlisten für eine optimale strukturierte Dokumentenindizierung konfigurieren.

7. November 2025
Einführung der Elasticsearch-Abfrageregeln-Benutzeroberfläche in Kibana
Erfahren Sie, wie Sie mit der Elasticsearch Query Rules UI Dokumente mithilfe anpassbarer Regelsätze in Kibana zu Suchanfragen hinzufügen oder ausschließen können, ohne das organische Ranking zu beeinträchtigen.

3. Oktober 2025
So stellen Sie Elasticsearch auf dem AWS Marketplace bereit
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie Elasticsearch mithilfe des Elastic Cloud Service auf dem AWS Marketplace einrichten und ausführen.

14. August 2025
Elasticsearch-Shards und -Replikate: Ein praktischer Leitfaden
Machen Sie sich mit den Konzepten von Elasticsearch-Shards und -Replikaten vertraut und lernen Sie, wie Sie diese optimieren können.