Mit Elasticsearch können Sie Daten schnell und flexibel indexieren. Testen Sie es kostenlos in der Cloud oder führen Sie es lokal aus, um zu erfahren, wie einfach die Indizierung sein kann.
In diesem Artikel zeigen wir, wie man Apache Kafka mit Elasticsearch zur Datenerfassung und -indizierung integriert. Wir geben einen Überblick über Kafka, sein Konzept von Produzenten und Konsumenten und erstellen einen Log-Index, in dem Nachrichten über Apache Kafka empfangen und indexiert werden. Das Projekt wurde in Python implementiert, und der Code ist auf GitHub verfügbar.
Voraussetzungen
- Docker und Docker Compose: Stellen Sie sicher, dass Docker und Docker Compose auf Ihrem Rechner installiert sind.
- Python 3.x: Zum Ausführen der Producer- und Consumer-Skripte.
Einführung in Apache Kafka
Apache Kafka ist eine verteilte Streaming-Plattform, die hohe Skalierbarkeit und Verfügbarkeit sowie Fehlertoleranz ermöglicht. In Kafka erfolgt die Datenverwaltung über die Hauptkomponenten:
- Broker: zuständig für die Speicherung und Verteilung von Nachrichten zwischen Produzenten und Konsumenten.
- Zookeeper: verwaltet und koordiniert die Kafka-Broker und kontrolliert den Zustand des Clusters, die Partitionsleiter und die Verbraucherinformationen.
- Themen: Kanäle, auf denen Daten veröffentlicht und zur Nutzung gespeichert werden.
- Konsumenten und Produzenten: Während Produzenten Daten an die Themen senden, rufen Konsumenten diese Daten ab.
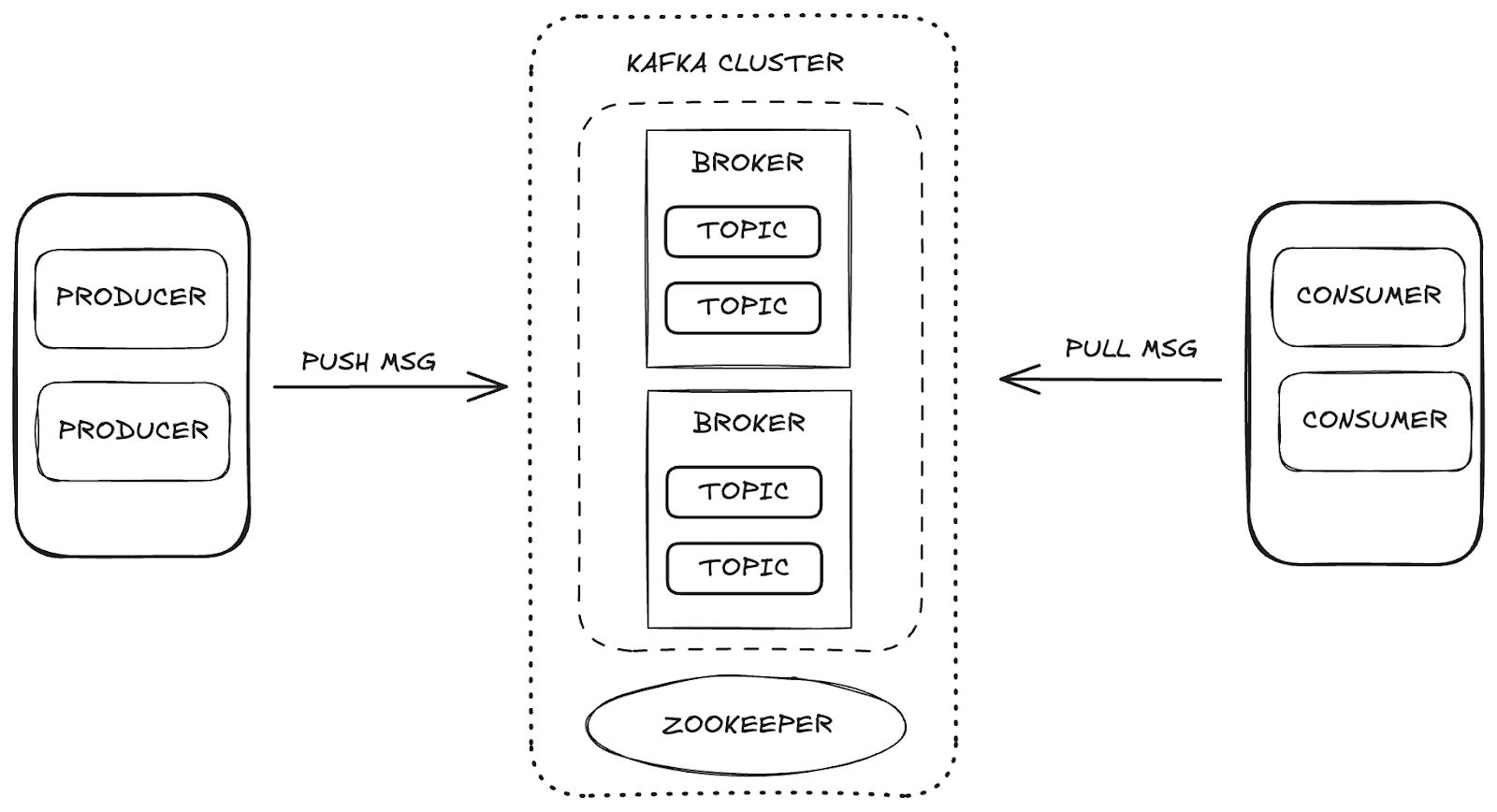
Diese Komponenten arbeiten zusammen und bilden das Kafka-Ökosystem, das ein robustes Framework für das Datenstreaming bietet.
Projektstruktur
Um den Datenerfassungsprozess zu verstehen, haben wir ihn in Phasen unterteilt:
- Infrastrukturbereitstellung: Einrichtung der Docker-Umgebung zur Unterstützung von Kafka, Elasticsearch und Kibana.
- Producer-Erstellung: Implementierung des Kafka-Producers, der Daten an das Logs-Topic sendet.
- Consumer Creation: Entwicklung des Kafka-Consumers zum Lesen und Indizieren von Nachrichten in Elasticsearch.
- Aufnahmevalidierung: Überprüfung und Validierung der gesendeten und empfangenen Daten.
Infrastrukturkonfiguration mit Docker Compose
Wir haben Docker Compose verwendet, um die notwendigen Dienste zu konfigurieren und zu verwalten. Nachfolgend finden Sie den Docker Compose-Code, der die für die Integration von Apache Kafka, Elasticsearch und Kibana erforderlichen Dienste einrichtet und so einen Datenaufnahmeprozess sicherstellt.
Sie können direkt über das Elasticsearch Labs GitHub- Repository auf die Datei zugreifen.
Datenübertragung mit dem Kafka Producer
Der Produzent ist für das Senden von Nachrichten an das Log-Thema verantwortlich. Durch das Senden von Nachrichten in Stapeln wird die Netzwerknutzungseffizienz gesteigert. Optimierungen sind mit den Einstellungen batch_size und linger_ms möglich, die die Anzahl bzw. die Latenz der Stapel steuern. Die Konfiguration acks='all' gewährleistet, dass Nachrichten dauerhaft gespeichert werden, was für wichtige Protokolldaten unerlässlich ist.
Beim Starten des Producers werden die Nachrichten in Batches an das Topic gesendet, wie unten dargestellt:
Konsum und Indizierung von Daten mit dem Kafka Consumer
Der Consumer ist so konzipiert, dass er Nachrichten effizient verarbeitet, indem er Batches aus dem Logs-Topic empfängt und diese in Elasticsearch indexiert. Mit auto_offset_reset='latest' wird sichergestellt, dass der Consumer mit der Verarbeitung der neuesten Nachrichten beginnt und die älteren ignoriert, und max_poll_records=10 begrenzt den Batch auf 10 Nachrichten. Bei fetch_max_wait_ms=2000 wartet der Konsument bis zu 2 Sekunden, um genügend Nachrichten zu sammeln, bevor er den Batch verarbeitet.
Im Hauptzyklus verarbeitet der Consumer die Logmeldungen, speichert sie in Elasticsearch und indexiert sie, um eine kontinuierliche Datenaufnahme zu gewährleisten.
Datenvisualisierung in Kibana
Mit Kibana können wir die von Kafka aufgenommenen und in Elasticsearch indexierten Daten untersuchen und validieren. Durch den Zugriff auf die Entwicklertools in Kibana können Sie die indizierten Nachrichten anzeigen und überprüfen, ob die Daten den Erwartungen entsprechen. Wenn beispielsweise unser Kafka-Producer 5 Batches mit jeweils 10 Nachrichten sendet, sollten wir insgesamt 50 Datensätze im Index sehen.
Um die Daten zu überprüfen, können Sie die folgende Abfrage im Abschnitt „Entwicklertools“ verwenden:
Abwehr:

Darüber hinaus bietet Kibana die Möglichkeit, Visualisierungen und Dashboards zu erstellen, die die Analyse intuitiver und interaktiver gestalten können. Nachfolgend sehen Sie einige Beispiele der von uns erstellten Dashboards und Visualisierungen, die die Daten in verschiedenen Formaten veranschaulichen und so unser Verständnis der verarbeiteten Informationen verbessern.

Datenaufnahme mit Kafka Connect
Kafka Connect ist ein Dienst, der die Integration zwischen Datenquellen und Zielen (Senken) wie Datenbanken oder Dateisystemen erleichtert. Es arbeitet mit vordefinierten Konnektoren, die den Datentransfer automatisch abwickeln. In unserem Fall fungiert Elasticsearch als Datensenke.

Mit Kafka Connect können wir den Datenaufnahmeprozess vereinfachen und die Notwendigkeit eliminieren, den Datenaufnahme-Workflow manuell in Elasticsearch zu implementieren. Mit dem passenden Konnektor ermöglicht Kafka Connect die direkte Indizierung von Daten, die an ein Kafka-Topic gesendet werden, in Elasticsearch – mit minimalem Einrichtungsaufwand und ohne zusätzliche Programmierung.
Arbeiten mit Kafka Connect
Um Kafka Connect zu implementieren, fügen wir den kafka-connect-Dienst zu unserem Docker Compose-Setup hinzu. Ein wichtiger Bestandteil dieser Konfiguration ist die Installation des Elasticsearch-Connectors, der für die Datenindizierung zuständig ist.
Nach der Konfiguration des Dienstes und der Erstellung des Kafka Connect-Containers wird eine Konfigurationsdatei für den Elasticsearch-Connector benötigt. Diese Datei definiert wichtige Parameter wie zum Beispiel:
connection.url: Verbindungs-URL für Elasticsearch.topics: Das Kafka-Thema, das der Connector überwachen wird (in diesem Fall "logs").type.name: Dokumenttyp in Elasticsearch (typischerweise _doc).value.converter: Konvertiert Kafka-Nachrichten in das JSON-Format.value.converter.schemas.enable: Gibt an, ob das Schema einbezogen werden soll.schema.ignoreundkey.ignore: Einstellungen zum Ignorieren von Kafka-Schemas und -Schlüsseln während der Indizierung.
Nachfolgend der Befehl curl zum Erstellen des Elasticsearch-Connectors in Kafka Connect:
Mit dieser Konfiguration beginnt Kafka Connect automatisch mit der Erfassung der an das Topic "logs" gesendeten Daten und deren Indizierung in Elasticsearch. Dieser Ansatz ermöglicht die vollautomatische Datenerfassung und -indizierung ohne zusätzlichen Programmieraufwand und vereinfacht so den gesamten Integrationsprozess.
Fazit
Durch die Integration von Kafka und Elasticsearch entsteht eine leistungsstarke Pipeline für die Datenerfassung und -analyse in Echtzeit. Dieser Leitfaden bietet einen grundlegenden Ansatz für den Aufbau einer robusten Datenerfassungsarchitektur mit nahtloser Visualisierung und Analyse in Kibana, die sich zukünftig an komplexere Anforderungen anpassen lässt.
Darüber hinaus vereinfacht die Verwendung von Kafka Connect die Integration zwischen Kafka und Elasticsearch zusätzlich, wodurch die Notwendigkeit von zusätzlichem Code zur Verarbeitung und Indizierung von Daten entfällt. Kafka Connect ermöglicht es, Daten, die an ein bestimmtes Thema gesendet werden, mit minimalem Konfigurationsaufwand automatisch in Elasticsearch zu indizieren.
Zugehörige Inhalte

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

22. September 2025
Elastic Open Web Crawler als Code
Erfahren Sie, wie Sie GitHub Actions verwenden, um Elastic Open Crawler-Konfigurationen zu verwalten, sodass Änderungen, die wir in das Repository übertragen, automatisch auf die bereitgestellte Instanz des Crawlers angewendet werden.

6. August 2025
Wie man Felder eines Elasticsearch-Index anzeigt
Lernen Sie, wie Sie Felder eines Elasticsearch-Index mithilfe der _mapping- und _search-APIs, Unterfeldern, synthetischen _source-Daten und Laufzeitfeldern anzeigen können.

24. Juni 2025
Ruby-Skripting in Logstash
Erfahren Sie mehr über das Logstash Ruby Filter-Plugin für die erweiterte Datentransformation in Ihrer Logstash-Pipeline.

26. Mai 2025
Anzeigen von Feldern in einem Elasticsearch-Index
Untersuchung von Techniken zur Darstellung von Feldern in einem Elasticsearch-Index.