In diesem Artikel lernen wir, wie Elasticsearch mithilfe von Autopilot auf Google Cloud Kubernetes (GKE) bereitgestellt wird.
Für Elasticsearch werden wir Elastic Cloud on Kubernetes (ECK) verwenden, den offiziellen Elasticsearch Kubernetes-Operator, der die Orchestrierung von Kubernetes-Deployments aller Elastic Stack-Komponenten vereinfacht.
Um mehr darüber zu erfahren, wie man Elasticsearch-Cluster auf verschiedenen Google-Cloud-Platform-Infrastrukturen bereitstellt, können Sie unsere Einstiegsartikel für Google Cloud Compute und Google Cloud Marketplace lesen.
Aufwand für die Bereitstellung von Elasticsearch

Was ist GKE Autopilot?
Google Kubernetes Engine (GKE) Autopilot bietet ein vollständig verwaltetes Kubernetes-Erlebnis, bei dem Google die Clusterkonfiguration, das Node-Management, die Security und das Skalieren übernimmt, während Entwickler sich auf die Bereitstellung von Anwendungen konzentrieren, sodass Teams mit integrierten Best Practices in wenigen Minuten vom Code zur Produktion gelangen können.
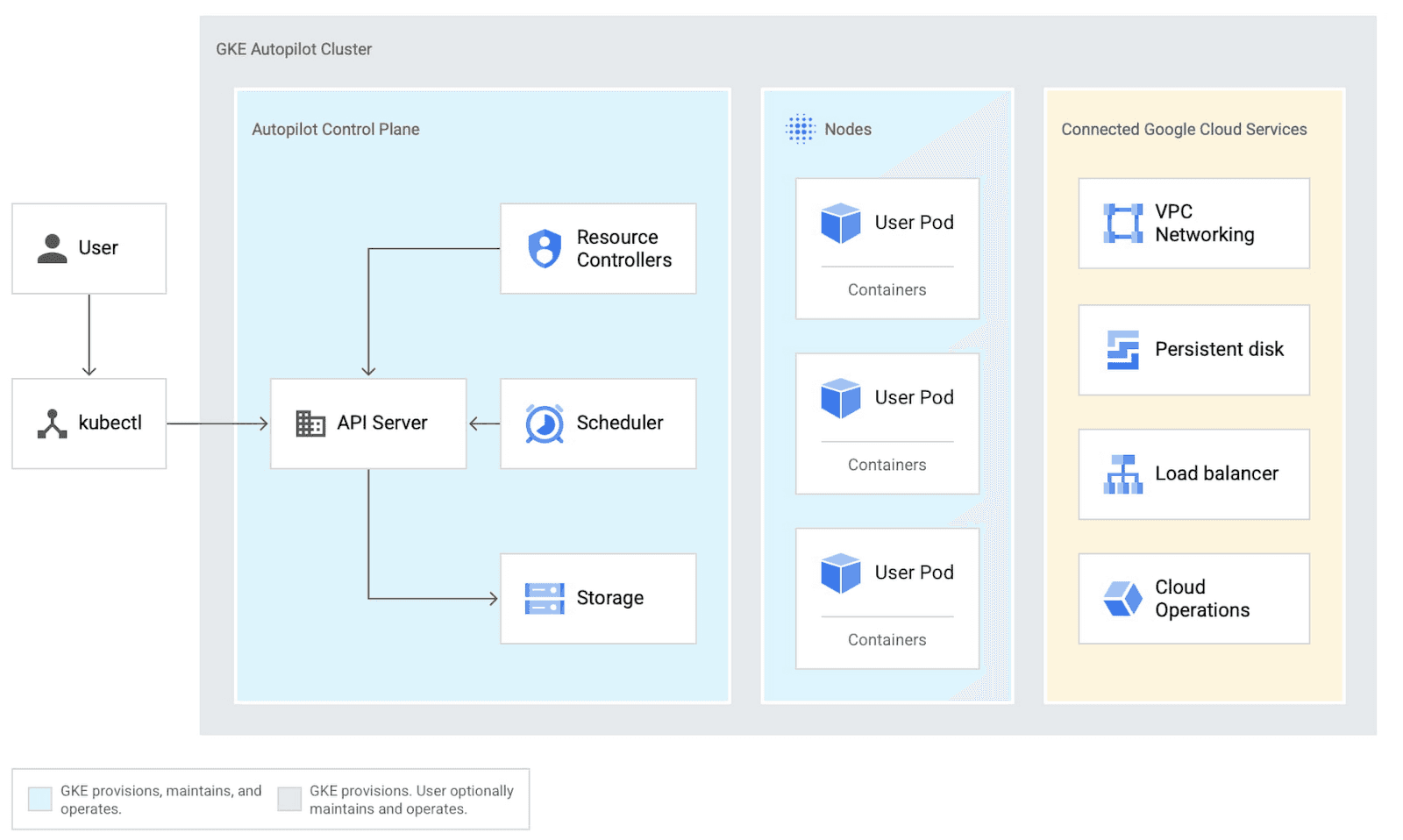
Wann sollte man ECK in Google Cloud nutzen?
Elastic Cloud on Kubernetes (ECK) eignet sich besonders für Unternehmen mit einer bestehenden Kubernetes-Infrastruktur, die Elasticsearch mit erweiterten Funktionen wie dedizierten Knotenrollen, hoher Verfügbarkeit und Automatisierung bereitstellen möchten.
Wie richtet man ECK in Google Cloud ein?
1. Melden Sie sich in der Google Cloud Console an.
2. Klicken Sie oben rechts auf die Cloud-Shell-Taste, um auf die Konsole zuzugreifen, und stellen Sie von dort aus den GKE-Cluster bereit. Alternativ können Sie auch gcloud CLI verwenden.
Denken Sie daran, die Projekt-ID während des Tutorials durch Ihre eigene zu ersetzen.
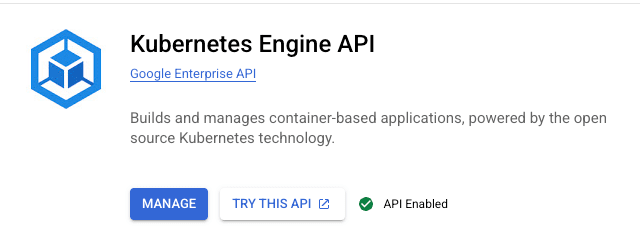
3. Aktivieren Sie die Google Kubernetes Engine API.

Klicken Sie auf Next (Weiter).
Nun sollte die Kubernetes Engine API als aktiviert angezeigt werden, wenn nach der Kubernetes Engine API gesucht wird.
4. In der Cloud Shell einen Autopilot-Cluster erstellen. Wir werden es „autopilot-cluster-1“ benennen und außerdem „autopilot-test“ durch die ID Ihres Projekts ersetzen.
5. Warten Sie, bis es bereit ist. Die Erstellung dauert etwa 10 Minuten.

Nach der korrekten Einrichtung des Clusters wird eine Bestätigungsmeldung angezeigt.
6. Konfigurieren Sie den Zugriff auf die „kubectl“-Befehlszeile.
Sie sollten sehen:

Für autopilot-cluster-1 wurde ein „kubeconfig“-Eintrag generiert.
7. Installieren Sie den Elastic Cloud on Kubernetes (ECK)-Operator.
8. Lassen Sie uns eine Elasticsearch-Instanz mit einem einzelnen Knoten und den Standardwerten erstellen.
Wenn Sie einige Rezepte für verschiedene Setups prüfen möchten, können Sie diesen Link besuchen.
Bitte beachten Sie, dass ECK, wenn Sie kein storageClass angeben, den standardmäßig festgelegten Wert verwendet, der für GKE standard-rwo ist und den Compute Engine Persistent Disk CSI Driver nutzt, und damit ein 1-GB-Volume erstellt.
Wir haben nmap deaktiviert, da die Standard-GKE-Maschine einen zu niedrigen Wert für vm.max_map_count hat. Für den Produktivbetrieb wird von einer Deaktivierung abgeraten; stattdessen sollte der Wert von vm.max_map_count erhöht werden. Mehr darüber, wie Sie das machen, können Sie hier lesen.
9. Lassen Sie uns außerdem einen Kibana-Cluster mit einem einzelnen Knoten bereitstellen. Für Kibana fügen wir einen LoadBalancer hinzu, der uns eine externe IP-Adresse bereitstellt, über die wir Kibana von unserem Gerät aus erreichen können.
Beachten Sie die Anmerkung:
cloud.google.com/l4-rbs: "enabled"
Das ist sehr wichtig, weil es Autopilot anweist, einen öffentlich zugänglichen LoadBalancer bereitzustellen. Falls nicht festgelegt, wird der LoadBalancer intern verwendet.
10. Prüfen Sie, ob Ihre Pods laufen

11. Sie können auch run kubectl get elasticsearch und kubectl get kibana für spezifischere Statistiken wie Elasticsearch-Version, Nodes und Health verwenden.


12. Greifen Sie auf Ihre Dienste zu.

Hier wird Ihnen die externe URL für Kibana unter EXTERNAL-IP angezeigt. Es kann einige Minuten dauern, bis der LoadBalancer bereitgestellt wird. Kopieren Sie den Wert von EXTERNAL-IP.
13. Ermitteln Sie das Elasticsearch-Passwort für den Nutzer „elastic“:

14. Greifen Sie über Ihren Browser auf Kibana zu:
- URL: https://<EXTERNAL_IP>:5601
- Benutzername:elastic
- Passwort: 28Pao50lr2GpyguX470L2uj5 (aus dem vorherigen Schritt)

15. Wenn Sie von Ihrem Browser aus zugreifen, wird der Willkommensbildschirm angezeigt.

Wenn Sie die Spezifikationen des Elasticsearch-Clusters ändern möchten, z. B. Knoten ändern oder die Größe anpassen, können Sie das yml-Manifest mit den neuen Einstellungen erneut anwenden:
In diesem Beispiel fügen wir einen weiteren Node hinzu und ändern RAM sowie CPU. Wie Sie sehen, zeigt kubectl get elasticsearch jetzt 2 Knoten:

Das Gleiche gilt für Kibana:
Wir können die CPU/RAM des Containers sowie die Speichernutzung von Node.js (max-old-space-size) anpassen.
Denken Sie daran, dass bestehende Volumenbehauptungen nicht verkleinert werden können. Nach der Installation des Updates wird der Betreiber die Änderungen mit minimaler Ausfallzeit vornehmen.
Denken Sie daran, den Cluster nach dem Testen zu löschen, um unnötige Kosten zu vermeiden.
Wie geht es weiter?
Wenn Sie mehr über Kubernetes und die Google Kubernetes Engine erfahren möchten, lesen Sie diese Artikel:
Zugehörige Inhalte

14. November 2025
So stellen Sie Elasticsearch auf Azure AKS Automated bereit
Erfahren Sie, wie Sie Elasticsearch mit Kibana auf Azure mithilfe von AKS Automatic und ECK für eine teilweise verwaltete Elasticsearch-Setup-Konfiguration bereitstellen.

11. November 2025
Konfiguration der rekursiven Segmentierung für strukturierte Dokumente in Elasticsearch
Erfahren Sie, wie Sie rekursives Chunking in Elasticsearch mit Chunk-Größe, Trenngruppen und benutzerdefinierten Trennlisten für eine optimale strukturierte Dokumentenindizierung konfigurieren.

7. November 2025
Einführung der Elasticsearch-Abfrageregeln-Benutzeroberfläche in Kibana
Erfahren Sie, wie Sie mit der Elasticsearch Query Rules UI Dokumente mithilfe anpassbarer Regelsätze in Kibana zu Suchanfragen hinzufügen oder ausschließen können, ohne das organische Ranking zu beeinträchtigen.

3. Oktober 2025
So stellen Sie Elasticsearch auf dem AWS Marketplace bereit
In dieser Schritt-für-Schritt-Anleitung erfahren Sie, wie Sie Elasticsearch mithilfe des Elastic Cloud Service auf dem AWS Marketplace einrichten und ausführen.

14. August 2025
Elasticsearch-Shards und -Replikate: Ein praktischer Leitfaden
Machen Sie sich mit den Konzepten von Elasticsearch-Shards und -Replikaten vertraut und lernen Sie, wie Sie diese optimieren können.