Dieser Blogbeitrag befasst sich eingehend mit agentenbasierten RAG-Workflows und erläutert deren Hauptmerkmale und gängige Designmuster. Des Weiteren wird anhand eines praktischen Beispiels, das Elasticsearch als Vektorspeicher und LangChain zum Aufbau des agentenbasierten RAG-Frameworks verwendet, demonstriert, wie diese Arbeitsabläufe implementiert werden können. Abschließend werden in dem Artikel kurz bewährte Verfahren und Herausforderungen im Zusammenhang mit der Entwicklung und Implementierung solcher Architekturen erörtert. Sie können anhand dieses Jupyter-Notebooks eine einfache agentenbasierte RAG-Pipeline erstellen.
Einführung in agentische RAG
Retrieval Augmented Generation (RAG) hat sich zu einem Eckpfeiler in LLM-basierten Anwendungen entwickelt und ermöglicht es Modellen, optimale Antworten zu liefern, indem sie relevanten Kontext auf der Grundlage von Benutzeranfragen abrufen. RAG-Systeme verbessern die Genauigkeit und den Kontext von LLM-Antworten, indem sie auf externe Informationen aus APIs oder Datenspeichern zurückgreifen, anstatt sich auf vorab trainiertes LLM-Wissen zu beschränken. Die KI-Agenten hingegen agieren autonom, treffen Entscheidungen und ergreifen Maßnahmen, um ihre vorgegebenen Ziele zu erreichen.
Agentic RAG ist ein Framework, das die Stärken sowohl der abrufgestützten Generierung als auch des agentenbasierten Schließens vereint. Es integriert RAG in den Entscheidungsprozess des Agenten und ermöglicht dem System so, Datenquellen dynamisch auszuwählen, Abfragen für einen besseren Kontextabruf zu verfeinern, genauere Antworten zu generieren und eine Rückkopplungsschleife anzuwenden, um die Ausgabequalität kontinuierlich zu verbessern.
Hauptmerkmale von agentic RAG
Das agentenbasierte RAG-Framework stellt einen bedeutenden Fortschritt gegenüber traditionellen RAG-Systemen dar. Anstatt einem festgelegten Abrufprozess zu folgen, nutzt es dynamische Agenten, die in der Lage sind, Ergebnisse in Echtzeit zu planen, auszuführen und zu optimieren.
Betrachten wir einige der wichtigsten Merkmale, die agentenbasierte RAG-Pipelines auszeichnen:
- Dynamische Entscheidungsfindung: Agentic RAG verwendet einen Schlussfolgerungsmechanismus, um die Absicht des Benutzers zu verstehen und jede Anfrage an die relevanteste Datenquelle weiterzuleiten, wodurch genaue und kontextbezogene Antworten erzeugt werden.
- Umfassende Abfrageanalyse: Agentic RAG analysiert Benutzerabfragen eingehend, einschließlich Unterfragen und deren Gesamtabsicht. Es bewertet die Komplexität der Anfrage und wählt dynamisch die relevantesten Datenquellen aus, um Informationen abzurufen und so genaue und vollständige Antworten zu gewährleisten.
- Mehrstufige Zusammenarbeit: Dieses Framework ermöglicht eine mehrstufige Zusammenarbeit durch ein Netzwerk spezialisierter Agenten. Jeder Agent bearbeitet einen bestimmten Teil eines größeren Ziels und arbeitet dabei sequenziell oder gleichzeitig, um ein zusammenhängendes Ergebnis zu erzielen.
- Selbstbewertungsmechanismen: Die agentenbasierte RAG-Pipeline nutzt Selbstreflexion, um abgerufene Dokumente und generierte Antworten zu bewerten. Es kann prüfen, ob die abgerufenen Informationen die Anfrage vollständig beantworten, und anschließend die Ausgabe auf Richtigkeit, Vollständigkeit und sachliche Konsistenz überprüfen.
- Integration mit externen Tools: Dieser Workflow kann mit externen APIs, Datenbanken und Echtzeit-Informationsquellen interagieren, aktuelle Informationen einbeziehen und sich dynamisch an sich verändernde Daten anpassen.
Workflow-Muster von agentischen RAG
Die Workflow-Muster definieren, wie agentenbasierte KI LLM-basierte Anwendungen zuverlässig und effizient strukturiert, verwaltet und orchestriert. Zur Implementierung dieser agentenbasierten Arbeitsabläufe können verschiedene Frameworks und Plattformen wie LangChain, LangGraph, CrewAI und LlamaIndex verwendet werden.
- Sequenzielle Abrufkette: Sequenzielle Arbeitsabläufe unterteilen komplexe Aufgaben in einfache, geordnete Schritte. Jeder Schritt verbessert die Ausgangslage für den nächsten, was zu besseren Ergebnissen führt. Wenn beispielsweise ein Kundenprofil erstellt wird, ruft ein Mitarbeiter grundlegende Daten aus einem CRM-System ab, ein anderer die Kaufhistorie aus einer Transaktionsdatenbank, und ein letzter Mitarbeiter kombiniert diese Informationen, um ein vollständiges Profil für Empfehlungen oder Berichte zu erstellen.
- Routing-Abrufkette: In diesem Workflow-Muster analysiert ein Router-Agent die Eingabe und leitet sie an den am besten geeigneten Prozess oder die am besten geeignete Datenquelle weiter. Dieser Ansatz ist besonders effektiv, wenn mehrere unterschiedliche Datenquellen mit minimaler Überschneidung vorliegen. In einem Kundenservicesystem kategorisiert beispielsweise der Router-Agent eingehende Anfragen wie technische Probleme, Rückerstattungen oder Beschwerden und leitet sie zur effizienten Bearbeitung an die zuständige Abteilung weiter.
- Parallele Abrufkette: Bei diesem Workflow-Muster werden mehrere unabhängige Teilaufgaben gleichzeitig ausgeführt, und ihre Ergebnisse werden später zusammengeführt, um eine endgültige Antwort zu generieren. Dieser Ansatz reduziert die Bearbeitungszeit erheblich und erhöht die Effizienz des Arbeitsablaufs. In einem parallelen Arbeitsablauf im Kundenservice ruft beispielsweise ein Mitarbeiter ähnliche, frühere Anfragen ab, während ein anderer Mitarbeiter relevante Artikel in der Wissensdatenbank konsultiert. Ein Aggregator kombiniert diese Ausgaben dann zu einer umfassenden Auflösung.
- Orchestrator-Worker-Kette: Dieser Workflow weist aufgrund der Verwendung unabhängiger Teilaufgaben Ähnlichkeiten mit der Parallelisierung auf. Ein wesentlicher Unterschied besteht jedoch in der Integration eines Orchestrator-Agenten. Dieser Agent ist dafür zuständig, Benutzeranfragen zu analysieren, sie während der Laufzeit dynamisch in Teilaufgaben zu unterteilen und die geeigneten Prozesse oder Werkzeuge zu identifizieren, die zur Formulierung einer genauen Antwort erforderlich sind.

Aufbau einer agentenbasierten RAG-Pipeline von Grund auf
Um die Prinzipien von agentic RAG zu veranschaulichen, entwerfen wir einen Workflow mit LangChain und Elasticsearch. Dieser Workflow verwendet eine routingbasierte Architektur, bei der mehrere Agenten zusammenarbeiten, um Anfragen zu analysieren, relevante Informationen abzurufen, Ergebnisse auszuwerten und kohärente Antworten zu generieren. Sie können dieses Jupyter-Notebook als Referenz verwenden, um diesem Beispiel zu folgen.
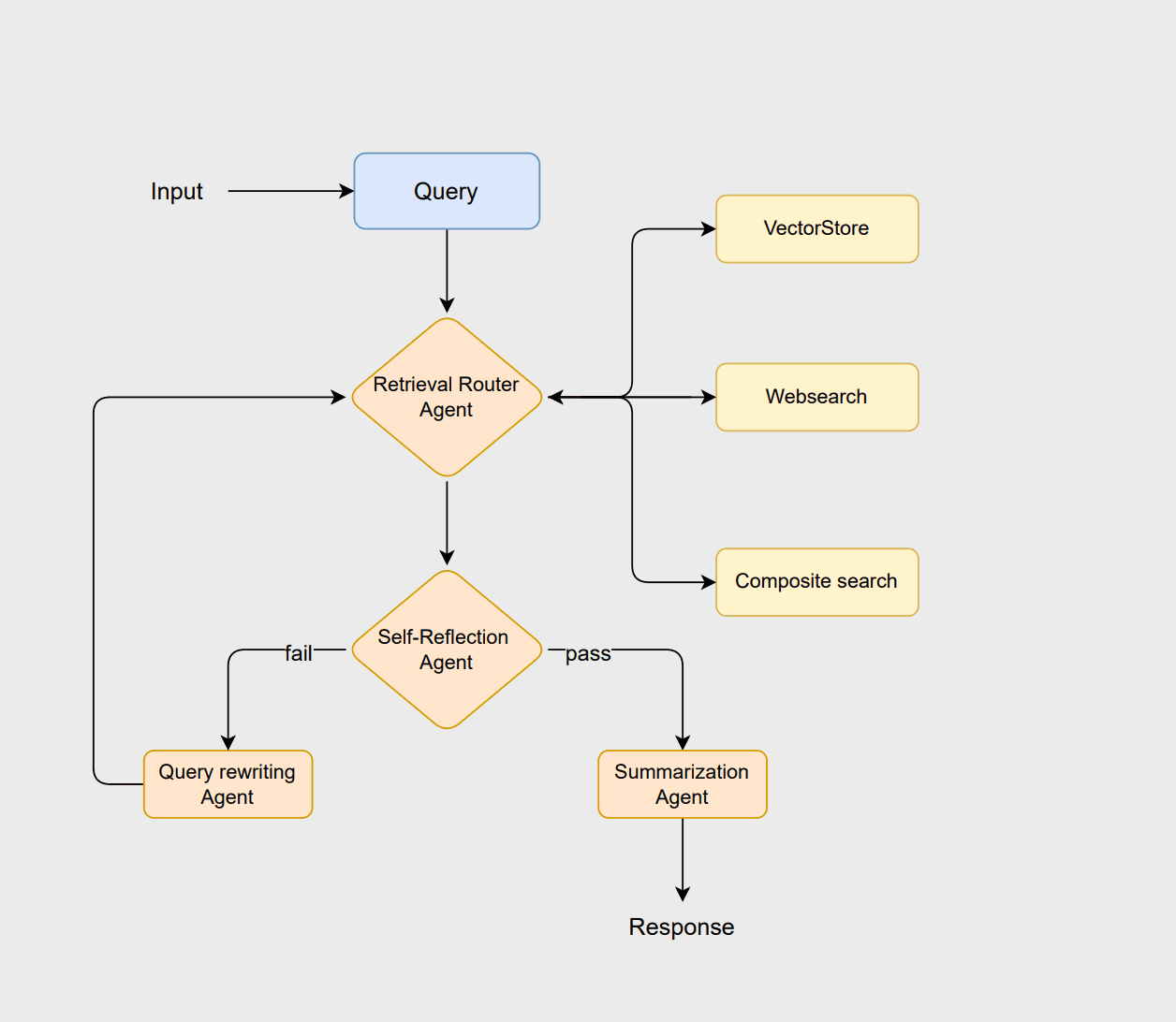
Der Workflow beginnt mit dem Router-Agenten, der die Anfrage des Benutzers analysiert, um die optimale Abrufmethode auszuwählen, d. h. entweder einen vectorstore, websearch, oder einen composite Ansatz. Der Vektorspeicher übernimmt die traditionelle RAG-basierte Dokumentenabfrage, die Websuche ruft die aktuellsten Informationen ab, die nicht im Vektorspeicher gespeichert sind, und der kombinierte Ansatz vereint beide, wenn Informationen aus mehreren Quellen benötigt werden.
Wenn die Dokumente als geeignet erachtet werden, generiert der Zusammenfassungsagent eine klare und kontextbezogene Antwort. Sind die Dokumente jedoch unzureichend oder irrelevant, formuliert der Abfrageumschreibungsagent die Abfrage neu, um die Suche zu verbessern. Diese überarbeitete Abfrage initiiert dann den Routing-Prozess erneut, wodurch das System seine Suche verfeinern und das Endergebnis verbessern kann.
Voraussetzungen
Dieser Workflow benötigt zur effektiven Ausführung des Beispiels die folgenden Kernkomponenten:
- Python 3.10
- Jupyter Notebook
- Azure OpenAI
- Elasticsearch
- LangChain
Bevor Sie fortfahren, werden Sie aufgefordert, die folgenden erforderlichen Umgebungsvariablen für dieses Beispiel zu konfigurieren.
Datenquellen
Dieser Arbeitsablauf wird anhand eines Teildatensatzes von AG News veranschaulicht. Der Datensatz umfasst Nachrichtenartikel aus verschiedenen Kategorien, wie etwa Internationales, Sport, Wirtschaft und Wissenschaft/Technologie.
Das ElasticsearchStore-Modul wird ab langchain_elasticsearch als unser Vektorspeicher verwendet. Für den Datenabruf implementieren wir die SparseVectorStrategy unter Verwendung von ELSER, dem proprietären Einbettungsmodell von Elastic. Es ist unerlässlich, sicherzustellen, dass das ELSER-Modell in Ihrer Elasticsearch-Umgebung korrekt installiert und bereitgestellt ist, bevor Sie den Vektorspeicher initialisieren.
Die Web-Suchfunktion wird mithilfe von DuckDuckGoSearchRun aus den LangChain-Community-Tools implementiert, wodurch das System effizient Live-Informationen aus dem Web abrufen kann. Sie können auch die Verwendung anderer Such-APIs in Betracht ziehen, die möglicherweise relevantere Ergebnisse liefern. Dieses Tool wurde gewählt, da es Suchvorgänge ohne API-Schlüssel ermöglicht.
Der Composite Retriever ist für Abfragen konzipiert, die eine Kombination von Datenquellen erfordern. Es dient dazu, eine umfassende und kontextbezogene Antwort zu liefern, indem gleichzeitig Echtzeitdaten aus dem Web abgerufen und historische Nachrichten aus dem Vektorspeicher konsultiert werden.
Einrichtung der Agenten
Im nächsten Schritt werden die LLM-Agenten so definiert, dass sie innerhalb dieses Arbeitsablaufs Denk- und Entscheidungsfähigkeiten bereitstellen. Die von uns erstellten LLM-Ketten umfassen: router_chain, grade_docs_chain, rewrite_query_chain, und summary_chain.
Der Router-Agent verwendet einen LLM-Assistenten, um zur Laufzeit die am besten geeignete Datenquelle für eine gegebene Abfrage zu ermitteln. Der Bewertungsagent prüft die abgerufenen Dokumente auf Relevanz. Werden die Dokumente als relevant erachtet, werden sie an den Zusammenfassungsagenten weitergeleitet, um eine Zusammenfassung zu erstellen. Andernfalls formuliert der Rewrite-Abfrageagent die Abfrage neu und sendet sie zur erneuten Abfrage an den Routing-Prozess zurück. Die Anweisungen für alle Agenten finden Sie im Abschnitt „LLM-Ketten“ des Notizbuchs.
Die llm.with_structured_output -Klausel sorgt dafür, dass die Ausgabe des Modells einem vordefinierten Schema folgt, das vom BaseModel unter der Klasse RouteQuery definiert wird, und gewährleistet so die Konsistenz der Ergebnisse. Die zweite Zeile bildet ein RunnableSequence , indem sie router_prompt mit router_structured verbindet und so eine Pipeline erzeugt, in der die Eingabeaufforderung vom Sprachmodell verarbeitet wird, um strukturierte, schemakonforme Ergebnisse zu erzeugen.
Graphknoten definieren
Dieser Teil beinhaltet die Definition der Zustände des Graphen, welche die Daten darstellen, die zwischen verschiedenen Komponenten des Systems fließen. Eine klare Spezifikation dieser Zustände stellt sicher, dass jeder Knoten im Workflow weiß, auf welche Informationen er zugreifen und welche er aktualisieren kann.
Sobald die Zustände definiert sind, besteht der nächste Schritt darin, die Knoten des Graphen zu definieren. Knoten sind wie die funktionalen Einheiten des Graphen, die spezifische Operationen an den Daten durchführen. Unsere Pipeline besteht aus 7 verschiedenen Knoten.
Der query_rewriter -Knoten erfüllt im Arbeitsablauf zwei Zwecke. Zunächst wird die Benutzeranfrage mithilfe von rewrite_query_chain umgeschrieben, um die Trefferquote zu verbessern, wenn die vom Selbstreflexionsagenten ausgewerteten Dokumente als unzureichend oder irrelevant erachtet werden. Zweitens fungiert es als Zähler, der verfolgt, wie oft die Abfrage neu geschrieben wurde.
Bei jedem Aufruf des Knotens wird der im Workflow-Status gespeicherte Wert retry_count erhöht. Dieser Mechanismus verhindert, dass der Arbeitsablauf in eine Endlosschleife gerät. Wenn der Wert retry_count einen vordefinierten Schwellenwert überschreitet, kann das System auf einen Fehlerzustand, eine Standardantwort oder eine andere von Ihnen gewählte vordefinierte Bedingung zurückgreifen.
Zusammenstellen des Graphen
Im letzten Schritt werden die Kanten des Graphen definiert und gegebenenfalls notwendige Bedingungen hinzugefügt, bevor er kompiliert wird. Jeder Graph muss von einem festgelegten Startknoten ausgehen, der als Einstiegspunkt für den Workflow dient. Die Kanten im Graphen stellen den Datenfluss zwischen den Knoten dar und können zweierlei Art sein:
- Gerade Kanten: Diese definieren einen direkten, bedingungslosen Fluss von einem Knoten zum anderen. Sobald der erste Knoten seine Aufgabe abgeschlossen hat, fährt der Workflow automatisch mit dem nächsten Knoten entlang der geraden Kante fort.
- Bedingte Kanten: Diese ermöglichen es dem Workflow, sich basierend auf dem aktuellen Zustand oder den Ergebnissen der Berechnung eines Knotens zu verzweigen. Der nächste Knoten wird dynamisch anhand von Bedingungen wie Auswertungsergebnissen, Routing-Entscheidungen oder Wiederholungsanzahl ausgewählt.
Damit ist Ihre erste agentenbasierte RAG-Pipeline einsatzbereit und kann mithilfe des kompilierten Agenten getestet werden.
Testen der agentischen RAG-Pipeline
Wir werden diese Pipeline nun anhand von drei verschiedenen Abfragetypen testen, wie unten dargestellt. Beachten Sie, dass die Ergebnisse unterschiedlich ausfallen können und die unten aufgeführten Beispiele nur ein mögliches Ergebnis veranschaulichen.
Bei der ersten Abfrage wählt der Router websearch als Datenquelle aus. Die Anfrage besteht die Selbstreflexionsprüfung nicht und wird anschließend zur Anfrageumschreibungsphase weitergeleitet, wie in der Ausgabe gezeigt.
Als nächstes betrachten wir ein Beispiel, bei dem die vectorstore -Suche verwendet wird, was anhand der zweiten Abfrage demonstriert wird.
Die letzte Anfrage wird an die zusammengesetzte Abfrage gerichtet, die sowohl den Vektorspeicher als auch die Websuche nutzt.
Im oben beschriebenen Workflow ermittelt agentic RAG intelligent, welche Datenquelle beim Abruf von Informationen für eine Benutzeranfrage verwendet werden soll, wodurch die Genauigkeit und Relevanz der Antwort verbessert wird. Sie können zusätzliche Beispiele erstellen, um den Agenten zu testen und die Ausgaben zu überprüfen, um zu sehen, ob sie interessante Ergebnisse liefern.
Bewährte Verfahren zum Erstellen agentenbasierter RAG-Workflows
Nachdem wir nun verstanden haben, wie agentic RAG funktioniert, schauen wir uns einige Best Practices für die Erstellung dieser Workflows an. Die Einhaltung dieser Richtlinien trägt dazu bei, dass das System effizient und wartungsfreundlich bleibt.
- Bereiten Sie sich auf Ausweichlösungen vor: Planen Sie im Voraus Ausweichstrategien für Szenarien, in denen ein Schritt des Arbeitsablaufs fehlschlägt. Dies kann die Rückgabe von Standardantworten, das Auslösen von Fehlerzuständen oder die Verwendung alternativer Tools umfassen. Dadurch wird sichergestellt, dass das System Fehler reibungslos behebt, ohne den Gesamt-Workflow zu unterbrechen.
- Implementieren Sie eine umfassende Protokollierung: Versuchen Sie, in jeder Phase des Workflows eine Protokollierung zu implementieren, z. B. bei Wiederholungsversuchen, generierten Ausgaben, Routing-Entscheidungen und Abfrageumschreibungen. Diese Protokolle tragen dazu bei, die Transparenz zu verbessern, das Debuggen zu vereinfachen und die Eingabeaufforderungen, das Verhalten der Agenten und die Abrufstrategien im Laufe der Zeit zu verfeinern.
- Wählen Sie das passende Workflow-Muster: Analysieren Sie Ihren Anwendungsfall und wählen Sie das Workflow-Muster, das Ihren Bedürfnissen am besten entspricht. Nutzen Sie sequentielle Arbeitsabläufe für schrittweise Schlussfolgerungen, parallele Arbeitsabläufe für unabhängige Datenquellen und Orchestrator-Worker-Muster für Abfragen mit mehreren Tools oder komplexen Abfragen.
- Evaluierungsstrategien einbeziehen: Evaluierungsmechanismen in verschiedenen Phasen des Arbeitsablaufs integrieren. Dies können Selbstreflexionsagenten, die Bewertung abgerufener Dokumente oder automatisierte Qualitätskontrollen sein. Die Auswertung hilft dabei zu überprüfen, ob die abgerufenen Dokumente relevant sind, die Antworten korrekt sind und alle Teile einer komplexen Anfrage berücksichtigt werden.
Herausforderungen
Während agentenbasierte RAG-Systeme hinsichtlich Anpassungsfähigkeit, Präzision und dynamischem Denken erhebliche Vorteile bieten, bringen sie auch gewisse Herausforderungen mit sich, die während ihrer Entwurfs- und Implementierungsphase bewältigt werden müssen. Zu den wichtigsten Herausforderungen gehören:
- Komplexe Arbeitsabläufe: Mit zunehmender Anzahl von Agenten und Entscheidungspunkten wird der gesamte Arbeitsablauf immer komplexer. Dies kann zu einer höheren Wahrscheinlichkeit von Fehlern oder Ausfällen zur Laufzeit führen. Priorisieren Sie nach Möglichkeit optimierte Arbeitsabläufe, indem Sie redundante Agenten und unnötige Entscheidungspunkte eliminieren.
- Skalierbarkeit: Die Skalierung agentenbasierter RAG-Systeme zur Bewältigung großer Datensätze und hoher Abfragevolumina kann eine Herausforderung darstellen. Um die Leistungsfähigkeit auch bei großem Umfang aufrechtzuerhalten, sollten effiziente Indexierungs-, Caching- und verteilte Verarbeitungsstrategien integriert werden.
- Orchestrierung und Rechenaufwand: Die Ausführung von Arbeitsabläufen mit mehreren Agenten erfordert eine fortgeschrittene Orchestrierung. Dies umfasst eine sorgfältige Terminplanung, das Management von Abhängigkeiten und die Koordination der Agenten, um Engpässe und Konflikte zu vermeiden, die alle zur Gesamtkomplexität des Systems beitragen.
- Evaluierungskomplexität: Die Evaluierung dieser Arbeitsabläufe birgt inhärente Herausforderungen, da jede Phase eine eigene Bewertungsstrategie erfordert. Beispielsweise muss die RAG-Phase hinsichtlich der Relevanz und Vollständigkeit der abgerufenen Dokumente bewertet werden, während die generierten Zusammenfassungen auf Qualität und Genauigkeit geprüft werden müssen. Ebenso erfordert die Effektivität der Abfrageumformulierung eine separate Auswertungslogik, um festzustellen, ob die umgeschriebene Abfrage die Suchergebnisse verbessert.
Fazit
In diesem Blogbeitrag haben wir das Konzept des agentischen RAG vorgestellt und hervorgehoben, wie es das traditionelle RAG-Framework durch die Einbeziehung autonomer Fähigkeiten aus der agentischen KI erweitert. Wir untersuchten die Kernfunktionen von agentic RAG und demonstrierten diese Funktionen anhand eines praktischen Beispiels, indem wir einen Nachrichtenassistenten mit Elasticsearch als Vektorspeicher und LangChain zur Erstellung des agentic Frameworks entwickelten.
Darüber hinaus erörterten wir bewährte Vorgehensweisen und wichtige Herausforderungen, die bei der Konzeption und Implementierung einer agentenbasierten RAG-Pipeline zu berücksichtigen sind. Diese Erkenntnisse sollen Entwicklern als Leitfaden dienen, um robuste, skalierbare und effiziente agentenbasierte Systeme zu erstellen, die Abruf, Schlussfolgerung und Entscheidungsfindung effektiv kombinieren.
Was kommt als Nächstes?
Der von uns entwickelte Workflow ist einfach gehalten und bietet viel Raum für Verbesserungen und Experimente. Dies lässt sich verbessern, indem wir mit verschiedenen Einbettungsmodellen experimentieren und die Abrufstrategien verfeinern. Darüber hinaus könnte die Integration eines Re-Ranking-Agenten zur Priorisierung der abgerufenen Dokumente von Vorteil sein. Ein weiteres Forschungsfeld umfasst die Entwicklung von Evaluierungsstrategien für agentenbasierte Frameworks, insbesondere die Identifizierung gemeinsamer und wiederverwendbarer Ansätze, die für verschiedene Framework-Typen anwendbar sind. Abschließend werden diese Frameworks an großen und komplexeren Datensätzen erprobt.
Sollten Sie in der Zwischenzeit ähnliche Experimente durchgeführt haben, würden wir uns freuen, davon zu hören! Geben Sie uns gerne Feedback oder treten Sie über unseren Community-Slack-Kanal oder unsere Diskussionsforen mit uns in Kontakt.
Ressourcen
Zugehörige Inhalte

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.
17. März 2026
Die Gemini CLI-Erweiterung für Elasticsearch mit Tools und Fähigkeiten
Wir stellen die Erweiterung von Elastic für Googles Gemini CLI vor, mit der Elasticsearch-Daten in Entwickler- und agentischen Workflows gesucht, abgerufen und analysiert werden können.