使用"学习-排名 "模型的一大挑战是创建一个高质量的判断列表来训练模型。传统上,这一过程需要对查询与文档的相关性进行人工评估,为每个文档分配一个等级。这是一个缓慢的过程,不能很好地扩展,也很难维护(想象一下要手工更新一个有数百个条目的列表)。
现在,如果我们可以使用真实用户与搜索应用程序的交互来创建这些训练数据,会怎样呢?使用UBI数据可以让我们做到这一点。创建一个自动系统,捕捉并利用我们的搜索、点击和其他互动来生成判断列表。与人工交互相比,这一过程更容易扩展和重复,而且往往会产生更好的结果。在本博客中,我们将探讨如何查询存储在 Elasticsearch 中的 UBI 数据,以计算有意义的信号,从而为LTR模型生成训练数据集。
您可以 在这里找到完整的实验 。
为什么 UBI 数据有助于训练 LTR 模型?
与人工标注相比,UBI 数据具有多项优势:
- 数量:鉴于 UBI 数据来自真实的互动,我们可以收集到比人工生成的数据多得多的数据。当然,前提是我们有足够的流量来生成这些数据。
- 真实用户意图:传统上,人工判断列表来自专家对可用数据的评估。另一方面,UBI 数据反映了真实的用户行为。这意味着我们可以生成更好的训练数据,从而提高搜索系统的准确性,因为这些数据是基于用户如何与您的内容进行实际互动并从中发现价值的,而不是对相关内容的理论假设。
- 不断更新:判断列表需要不断刷新。如果我们根据 UBI 数据创建它们,我们就可以获得最新的数据,从而更新判断列表。
- 成本效益高:无需手动创建判断列表,可多次高效重复这一过程。
- 自然查询分布:UBI 数据代表真实的用户查询,可推动更深层次的变化。例如,用户是否使用自然语言在我们的系统中进行搜索?如果是这样,我们可能需要采用语义搜索或混合搜索方法。
不过也有一些警告:
- 偏见放大: 热门内容更容易获得点击,因为它的曝光率更高。因此,这最终可能会放大热门项目,可能会淹没更好的选择。
- 覆盖面不全: 新内容缺乏互动,因此可能难以在结果中占据重要位置。罕见查询也可能缺乏足够的数据点来创建有意义的训练数据。
- 季节性变化:如果您预期用户行为会随时间发生巨大变化,那么历史数据可能无法告诉您什么是好结果。
- 任务模糊:点击并不总能保证用户找到想要的东西。
成绩计算
LTR 培训的成绩
为了训练 LTR 模型,我们需要提供一些数字来表示文档与查询的相关程度。在我们的实施过程中,这个数字是一个连续的分数,从 0.0 到 5.0+,分数越高表示相关性越高。
为了说明这个分级系统是如何运行的,请看这个手动创建的示例:
| 查询 | 文件内容 | 等级 | 说明 |
|---|---|---|---|
| "最佳比萨饼配方" | "正宗意大利比萨面团配方及步骤图片" | 4.0 | 高度相关,正是用户正在寻找的内容 |
| "最佳比萨饼配方" | "意大利比萨的历史" | 1.0 | 与主题有点吻合,是关于披萨的,但不是食谱 |
| "最佳比萨饼配方" | "适合初学者的 15 分钟快速比萨食谱" | 3.0 | 这是个不错的结果,但也许还达不到 "最佳 "配方的标准。 |
| "最佳比萨饼配方" | "汽车保养指南" | 0.0 | 完全不相关,与查询完全无关 |
正如我们在这里看到的,等级是一个数字,表示文档与我们的样本查询 "最佳披萨配方 "的相关程度。有了这些分数,我们的 LTR 模型就能知道哪些文档应该在结果中显示得更高。
如何计算等级是我们训练数据集的核心。有 多种方法 可以做到这一点,每种 方法 都有自己的优缺点。例如,我们可以分配一个二进制分数,1 表示相关 0 表示不相关,或者我们可以只计算每个查询结果文档中的点击次数。
在这篇博文中,我们将采用一种不同的方法,将用户行为作为我们的输入,并计算出一个等级数字作为输出。我们还将纠正可能出现的偏差,因为无论文件的相关性如何,结果越靠前,点击率越高。
计算成绩 - COEC 算法
COEC(点击量大于预期点击量)算法是一种根据用户点击量计算判断等级的方法。如前所述,用户倾向于点击位置较高的结果,即使该文档并非与查询最相关;这就是所谓的位置偏差。使用 COEC 算法的核心理念是,并非所有点击都具有同等意义;点击位置 10 的文档表明,该文档与查询的相关性远高于点击位置 1 的文档。引用有关 COEC 算法的研究论文(如上链接):
"众所周知,搜索结果或广告的点击率(CTR)会随着搜索结果的位置而显著降低"。
您可以在这里进一步了解位置偏差。
为了利用 COEC 算法解决这个问题,我们采取了以下步骤:
1.建立位置基线:我们计算每个搜索位置(从 1 到 10)的点击率(CTR)。这意味着我们要确定点击位置 1、位置 2 等的用户比例。这一步骤可捕捉用户的自然位置偏差。我们使用以下方法计算点击率:
在哪里?
p = 位置。从 1 到 10
Cp = 在所有查询中,任何文档在位置 p 上的总点击次数
Ip = 总印象次数:在所有查询中,任何文档在位置 p 上出现的次数
在这里,我们希望位置越高,点击越多。
2. 计算预期点击量 (EC):
该指标根据文档出现的位置和这些位置的点击率,确定文档 "本应 "获得的点击量:
在哪里?
Qd = 文档 d 出现的所有查询
pos(d,q)= 文档 d 在查询结果 q 中的位置
3.统计实际点击量: 我们统计文档在所有查询中实际获得的总点击量,以下称为A(d)。
4.计算 COEC 分数:这是实际点击量(A(d))与预期点击量(EC(d))之比:
该指标对位置偏差进行了这样的归一化处理:
- 得分 1.0 表示文档在出现的位置上表现完全符合预期。
- 得分高于 1.0 表示该文件的位置表现优于预期。因此,这份文件与查询更相关。
- 如果得分低于 1.0,则表示该文件的表现不如预期。因此,该文件与查询的相关性较低。
最终结果是一个等级数字,它能反映用户正在寻找什么,并考虑到从与我们搜索系统的实际互动中提取的基于位置的期望值。
技术实施
我们将创建一个脚本来创建判断列表,以训练 LTR 模型。
该脚本的输入是 Elastic 中索引的 UBI 数据(查询和事件)。
输出结果是使用 COEC 算法从这些 UBI 文档生成的 CSV 文件中的判断列表。该判断列表可与Eland结合使用,以提取相关特征并训练 LTR 模型。
快速启动
要根据本博客中的样本数据生成判断列表,可以按照以下步骤操作:
1.克隆版本库:
2.安装所需程序库
对于这个脚本,我们需要以下库:
- 熊猫:保存判断列表
- elasticsearch:从我们的弹性部署中获取 UBI 数据
我们还需要 Python 3.11
3.在.env 文件中更新弹性部署的环境变量
- ES_HOST
- API_KEY
要添加环境变量,请使用
4.创建 ubi_queries、ubi_events 索引,并上传样本数据。运行 setup.py 文件:
5.运行 Python 脚本:
如果按照这些步骤操作,你应该会看到一个名为 judgment_list.csv 的新文件,它看起来像这样:
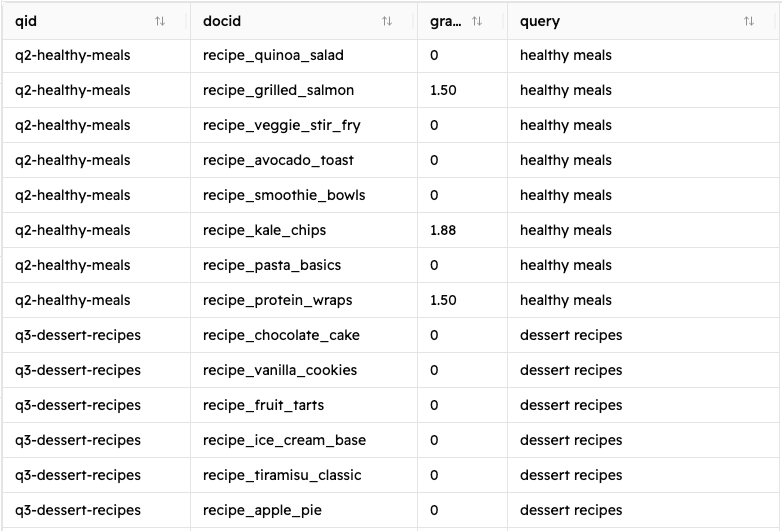
该脚本将使用下图所示的calculate_relevance_grade()函数,应用之前讨论过的 COEC 算法计算等级。
数据架构
乌比查询
我们的 UBI 查询索引包含在搜索系统中执行的查询信息。这是一份样本文件:
在这里,我们可以看到来自用户(client_id)、查询结果(query_response_object_ids)和查询本身(时间戳、user_query)的数据。
Ubi 点击事件
我们的 ubi_events 索引拥有用户每次点击结果中的文档时产生的数据。这是一份样本文件:
判断列表生成脚本
脚本概述
该脚本使用存储在 Elasticsearch 中的来自查询和点击事件的 UBI 数据自动生成判断列表。它执行这些任务:
- 获取并处理 Elasticsearch 中的 UBI 数据。
- 将 UBI 事件与其查询相关联。
- 计算每个位置的点击率。
- 计算每份文档的预期点击量 (EC)。
- 计算每份文档的实际点击次数。
- 计算每个查询-文档配对的 COEC 分数。
- 生成判断列表并将其写入 CSV 文件。
让我们逐一了解这些功能:
connect_too_elasticsearch()
该函数使用主机和 api 密钥返回 Elasticsearch 客户端对象。
fetch_ubi_data()
该函数是数据提取层;它连接 Elasticsearch,使用 match_all 查询获取 UBI 查询,并过滤 UBI 事件,只获取 "CLICK_THROUGH "事件。
process_ubi_data()
该函数处理判断列表的生成。它通过关联 UBI 事件和查询,开始处理 UBI 数据。然后,它会调用每个文档-查询对的 calculate_relevance_grade() 函数来获取判断列表的条目。最后,它会以 pandas 数据帧的形式返回结果列表。
计算相关性等级()
这是实现 COEC 算法的函数。它先计算每个位置的点击率,然后比较文档-查询配对的实际点击率,最后计算每个位置的实际 COEC 分数。
generate_judgment_statistics()
它能从判断列表中生成有用的统计数据,如查询总数、唯一文档总数或等级分布。这纯粹是为了提供信息,不会改变最终的判断列表。
成果和影响
如果您按照快速入门部分的说明进行操作,您应该会看到一个 CSV 文件,其中包含一个有 320 个条目的判断列表(您可以在软件仓库中看到输出示例)。有了这些字段:
- qid:查询的唯一 ID
- docid:生成文件的唯一标识符
- 等级:查询文件对的计算等级
- 查询:用户查询
让我们看看 "意大利菜谱 "的查询结果:
| qid | docid | 职级 | 查询 |
|---|---|---|---|
| Q1 意大利食谱 | 基本食谱 | 0.0 | 意大利食谱 |
| Q1 意大利食谱 | 菜谱_比萨_玛格丽塔 | 3.333333 | 意大利食谱 |
| Q1 意大利食谱 | 菜谱指南 | 10.0 | 意大利食谱 |
| Q1 意大利食谱 | 法式羊角面包食谱 | 0.0 | 意大利食谱 |
| Q1 意大利食谱 | 西班牙海鲜饭食谱 | 0.0 | 意大利食谱 |
| Q1 意大利食谱 | 希腊穆萨卡菜谱 | 1.875 | 意大利食谱 |
我们可以从结果中看到,查询 "意大利菜谱":
- 烩饭食谱无疑是该查询的最佳结果,其点击率比预期高出 10 倍
- 玛格丽塔比萨也是不错的选择。
- 希腊 Mousaka(令人吃惊)也取得了不错的成绩,其表现要好于它在比赛中的位置。这意味着一些寻找意大利食谱的用户转而对这一食谱感兴趣。也许这些用户普遍对地中海菜肴感兴趣。最后,这告诉我们,在我们上面讨论的另外两场 "更好 "的比赛中,这可能是一个很好的结果。
结论
利用 UBI 数据,我们可以自动训练 LTR 模型,从自己的用户中创建高质量的判断列表。UBI 数据提供了一个大数据集,反映了我们的搜索系统是如何被使用的。通过使用 COEC 算法来生成等级,我们可以考虑到固有的偏差,同时,它也反映了用户认为更好的结果。本文概述的方法可应用于实际使用案例,以提供更好的搜索体验,并随着实际使用趋势的变化而变化。
相关内容

利用 Elasticsearch 和 SigLIP-2 对山峰进行多模式搜索
了解如何使用 SigLIP-2 嵌入和 Elasticsearch kNN 向量搜索实现文本到图像和图像到图像的多模态搜索。项目重点:寻找珠峰徒步旅行中拍摄的阿玛达布拉姆峰照片。

使用 ES|QL 进行 Elasticsearch 地理空间搜索
Elasticsearch 查询语言 (ES|QL) 中的地理空间搜索。Elasticsearch 具有强大的地理空间搜索功能,ES|QL 将大幅提高易用性和 OGC 熟悉度。


人工智能剽窃利用 Elasticsearch 检测剽窃行为
以下是如何使用 Elasticsearch 检查人工智能剽窃,重点是使用 NLP 模型和矢量搜索的用例。
