New to Elasticsearch? Join our getting started with Elasticsearch webinar. You can also start a free cloud trial or try Elastic on your machine now.
When I first started working with Elasticsearch, I knew that documents were distributed across shards and I knew there was some kind of hash involved. The documentation even shows you the formula:
But that hash() call? Completely opaque. Click through to the routing field documentation, and you won’t find the name of the function. Ask around, and you get told it’s an implementation detail, deliberately abstracted so the team can swap it out without updating docs.
That answer is technically defensible. It didn’t help me or my customers understand uneven document distribution.
This post is the explanation I wish I’d found.
What is MurmurHash3, and why does Elasticsearch use it?
The function behind hash() is MurmurHash3. It’s a non-cryptographic hash function designed by Austin Appleby in 2008. Unlike cryptographic hash functions (SHA-256, MD5), it isn’t built for security; it doesn’t need to be irreversible or resistant to deliberate collision attacks. It’s built for one thing: spreading input values as evenly as possible across an output space, fast.
That makes it a good fit for shard routing. Elasticsearch needs to take a document ID, produce a number, and use that number to decide which shard the document lives on. The requirements are exactly what Murmur3 delivers:
| Property | Why it matters for shard routing |
|---|---|
| Uniform distribution | Documents spread evenly across shards without manual intervention. |
| Determinism | The same document ID always routes to the same shard. |
| Speed | Runs on every index and get operation (latency cost must be negligible). |
A brief overview of the algorithm is on Wikipedia, if you want to go deeper. The short version: Murmur3 operates on blocks of bytes, mixing in a series of multiply-rotate-XOR steps to produce avalanche effects (small input changes cause large, unpredictable output changes). The result is a 32-bit or 128-bit integer. Elasticsearch uses the 32-bit variant.
How Elasticsearch calculates shard numbers: A worked example
For a six-shard index, Elasticsearch uses 768 routing shards and a routing factor of 128. Here's how to verify that with a real document.
Create an index with six primary shards:
Check the default settings, paying attention to index.number_of_routing_shards:
With six primary shards, the response will show index.number_of_routing_shards = 768. The docs describe this setting as:
The default is designed to allow you to split by factors of 2 up to a maximum of 1024 shards.
What it means in practice: Elasticsearch starts with your primary shard count and keeps doubling it until doubling again would exceed 1024. For six primary shards:
This gives you enough routing space to double the index's primary shard count up to seven times without reindexing.
For our index:
Now index a document:
Check which shard it landed on:
It ends up on shard 4. Let's verify why.
Computing the MurmurHash3 shard routing formula step by step
Using the values established above (num_routing_shards = 768, routing_factor = 128, document ID 654321), the shard calculation is:
At this point, we finally need to answer the question that the docs leave open: What is hash()? In Elasticsearch, it’s MurmurHash3. For the string "654321", it returns 1424940152.
Shard 4, exactly where Elasticsearch put it.
If you want to verify this with your own IDs, here’s a small Java script that computes the same shard number externally using Lucene's Murmur3 implementation. Index a document into Elasticsearch, check which shard it lands on, and then run the same ID through this script and confirm the result matches.
Save this as Murmur3Demo.java:
To run it:
This prints:
Which matches the shard assignment above.
If your index was created with an explicit index.number_of_routing_shards, use that value directly instead of deriving it from number_of_shards.
The Elasticsearch source code: How hash() encodes routing values
The Elasticsearch source encodes the routing value as UTF-16LE before passing it to MurmurHash3. Here’s the relevant method:
Two things worth noting here:
First, the routing value is a string, and each character is written as a little-endian two-byte sequence before hashing. This is why you cannot reproduce the hash by treating the ID as ASCII: "654321" is encoded as 12 bytes, not 6.
Second, the function returns a signed 32-bit integer, but Elasticsearch takes Math.floorMod of the result to avoid negative shard numbers. If you’re trying to reproduce the routing calculation in another language, watch out for signed/unsigned integer differences.
When MurmurHash3 routing causes hot shards and how to check
For most workloads, you never need to think about this. Index documents with auto-generated IDs, and Murmur3's uniform distribution will spread them evenly across shards. Where it causes issues is with custom IDs or routing values with poor effective distribution. Sequential integers, timestamp-derived values, or heavily patterned identifiers aren’t guaranteed to cause skew, but they’re worth checking if you’re seeing hot shards. The hash function itself is not at fault: Murmur3 is designed to distribute inputs evenly. But if shard distribution looks wrong, your choice of IDs or routing values is one of the first things to test.
If you’re seeing hot shards and your documents have custom IDs, do the same calculation we just did for "654321" on a sample of your real IDs. Hash each ID with Murmur3, apply Math.floorMod(..., num_routing_shards), divide by the routing factor, and see how many land on each shard.
Why Elasticsearch doesn't document the hash function name
Hiding implementation details behind a stable interface is good software design. The routing formula is documented and guaranteed. The specific hash function underneath it is not, because it doesn’t need to be; for almost every use case, all that matters is that documents are distributed evenly and consistently, which Murmur3 delivers regardless of whether you know its name.
The exception is when things go wrong. If documents are clustered on the same shards and you don’t know how routing works, you have nowhere to start debugging. Once you know the formula and the function, the path from Why are these shards hot? to a concrete answer is a few lines of arithmetic.
For most users, that’s when knowing it’s Murmur3 matters. And now you know.
相关内容

2026年6月29日
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
2026年6月12日
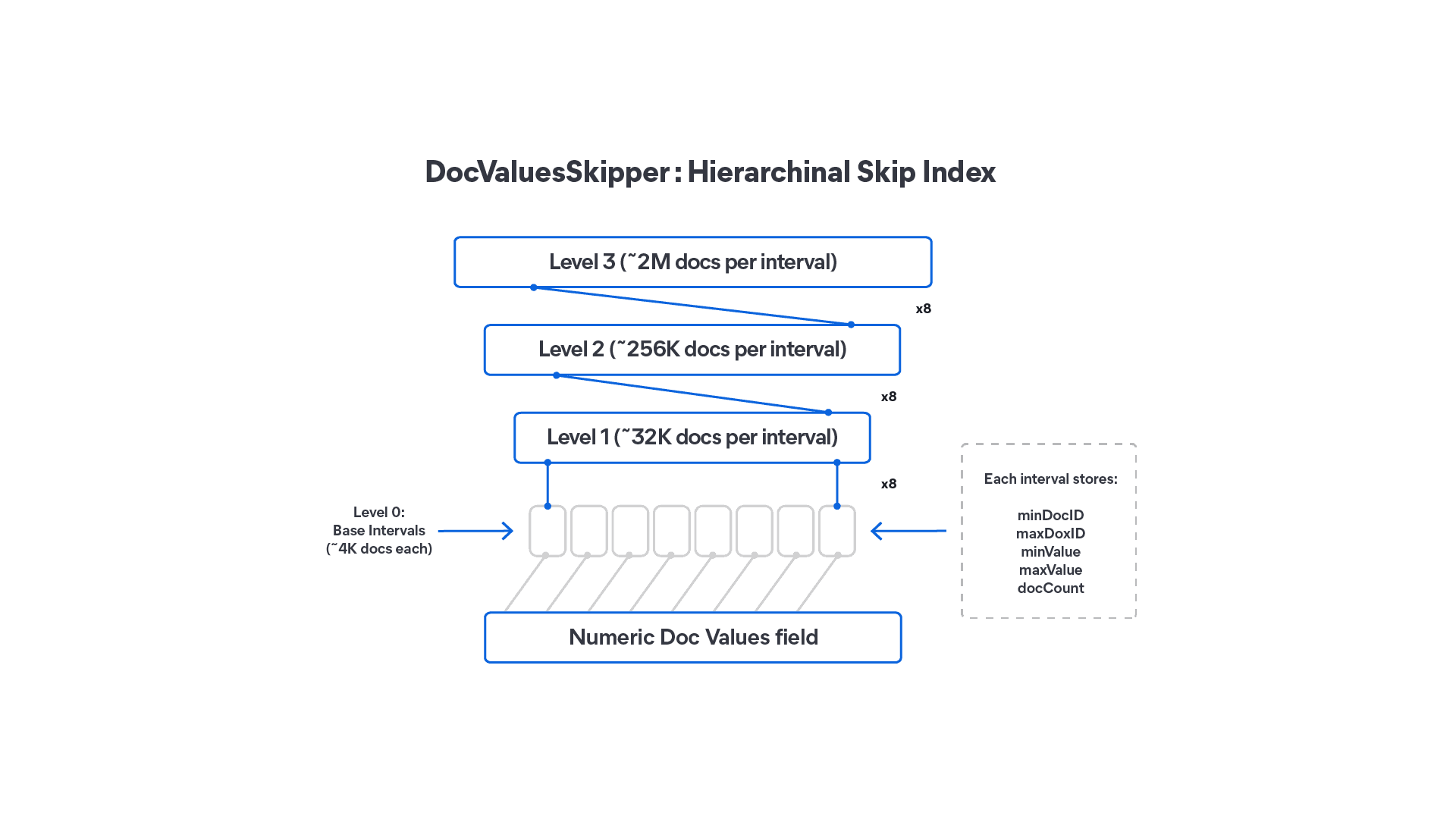
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.
2026年5月12日
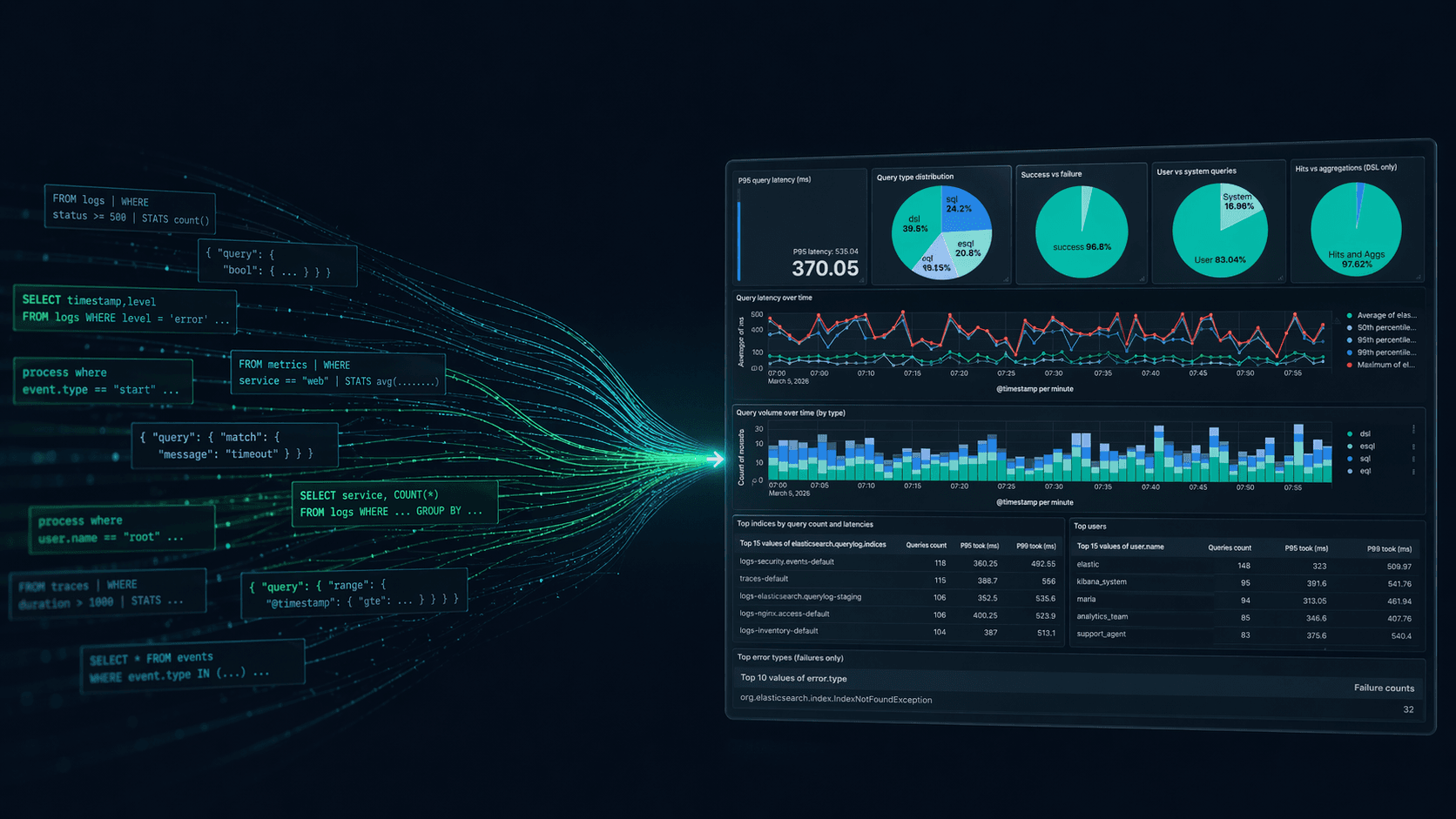
Elasticsearch query logs: One coordinator-level line per query for ES|QL, DSL, SQL, and EQL
Easily understand query impact on cluster performance with Elasticsearch query logs. One coordinator-level line records ES|QL, DSL, SQL, and EQL per request and provides full query text, tracing, optional user context, and CCS hints
2026年4月6日
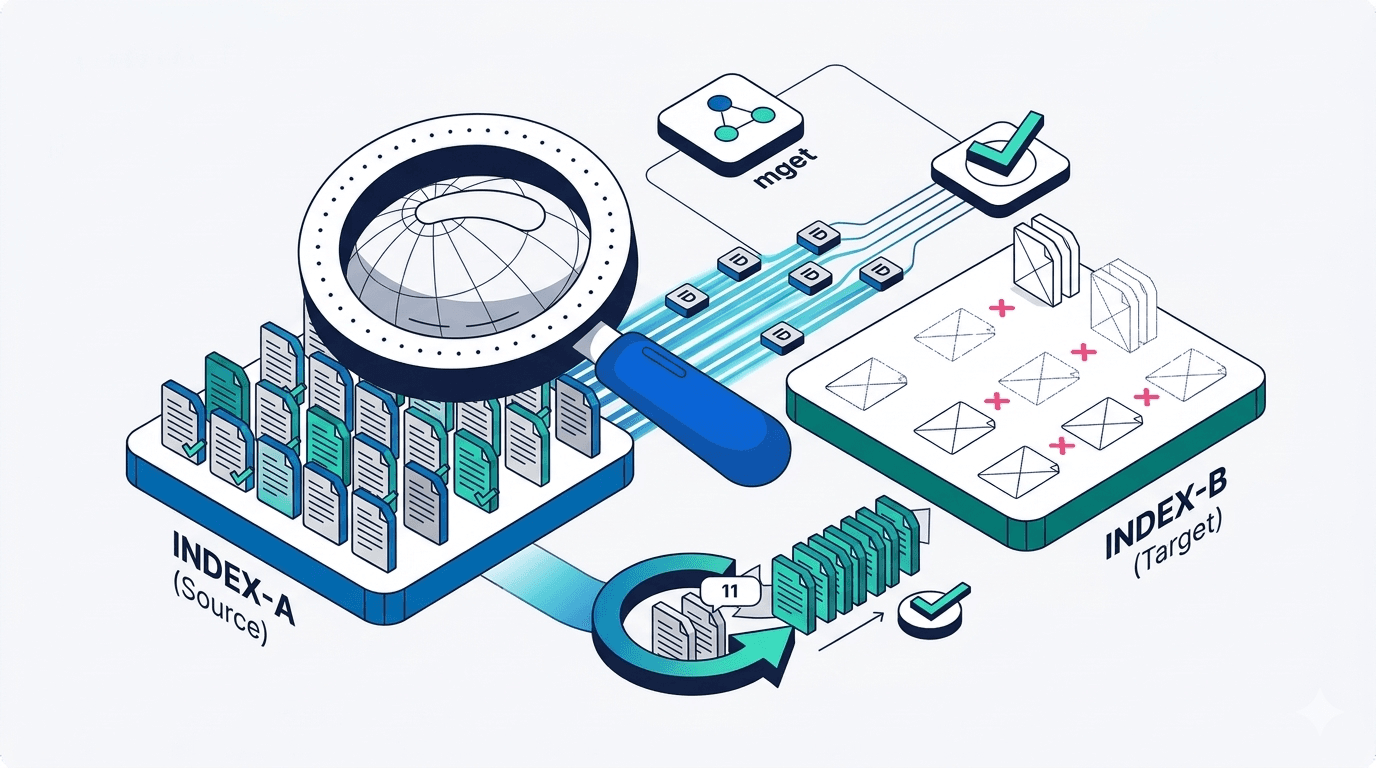
How to compare two Elasticsearch indices and find missing documents
Exploring approaches for comparing two Elasticsearch indices and finding missing documents.

Testing Elasticsearch. It just got simpler.
Explaining how Elasticsearch integration tests have become simpler thanks to improvements in Elasticsearch 9.x, the modern Java client, and Testcontainers 2.x.